[Review] Are Transformers Effective for Time Series Forecasting? (2023, AAAI)
This paper
- Questions the effectiveness of using Transformer-based architecture for LTSF
- Claims that the best solution for extracting temporal relations in an ordered set of continuous data might not be Transformer-based model
- Proposes simple linear model as a baseline to verify their claims
- Demonstrates why LTSF-Transformers are not as effective as claimed in previous research
I. Introduction
Almighty transformer
최근 ML/DL 분야에서 Transformer를 기반으로한 모델들은 많이 연구되고 있습니다.
Transformer는 multi-head self attention mechanism(이하 attention)을 이용해서 paired element 사이의 잠재적인 semantic correlation를 추출해 task를 수행합니다.
이러한 attention을 기반으로하는 model들은 최근 우수한 성능을 자주 보여주며 자연어를 넘어 컴퓨터 비전와 음성 인식 등 다양한 분야에 적용되고 있습니다.
이번 리뷰에서 주의 깊에 다룰 LTSF(Long-term Time Series Forecasting) 분야에서도 트랜스포머를 기반으로한 다양한 모델들이 연구됐습니다.
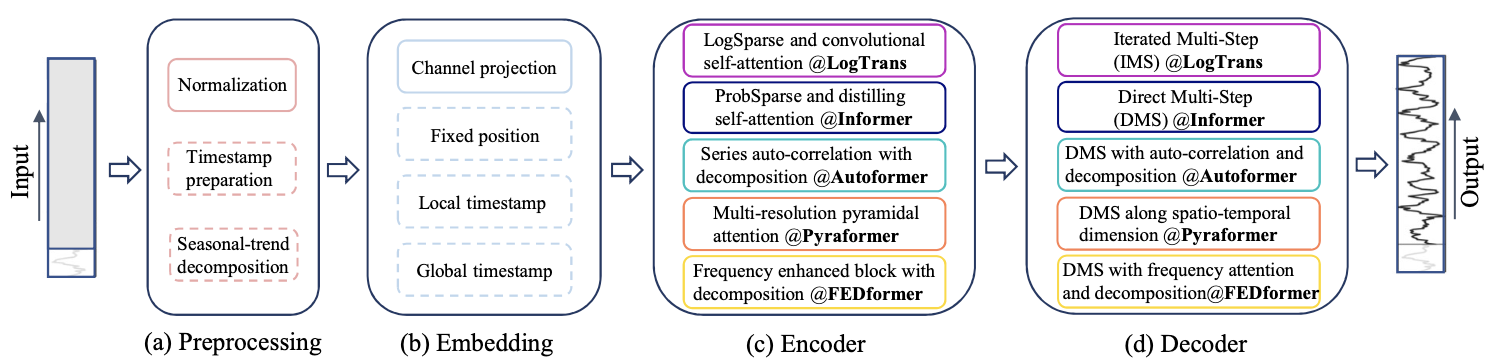
Transformer for LTSF
Transformer의 핵심은 방금 설명했듯이 attention에 있습니다.
Attention은 paired element 데이터 사이에서 잠재적인 semantic correlation를 추출해 좋은 성능을 보이지만, 이는 시간 순서를 고려하지 않습니다.(permutation-invariant, anti-order)
시계열 데이터 분석의 경우 연속적인 지점 사이에 존재하는 특징을(temporal dynamics) 발견하기 위해서 입력 데이터의 순서 그 자체도 매우 중요한 역할을 하는데, 이런 데이터의 순서를 고려하지 않은 task 처리 방식은 문제가 될 수 있습니다.
시간 순서를 고려하기 위해서 다양한 positional encoding 혹은 time stamp embedding 방식을 사용할 수 있지만, attention은 point-wise로 semantic correlation을 계산해 특징을 추출 및 학습할 것입니다.
땜문에, Attention이 정말 시계열 데이터의 특징을 잘 추출하는 지 궁금증을 자아냅니다.
Iterated multi step(IMS) prediction
이런 궁금증을 해소하기 위해 선행 연구들은 Transformer 기반 모델들의 정확도를 우수한 것처럼 소개했지만, 비교를 위한 실험에서 기존 베이스라인 모델들을 autoregressive한 model들을 사용했습니다.
autoregressive 예측이란 현 시점 k에서 k+T 값을 예측하기 위해 k+1 ~ k+T-1까지의 값들을 인수로 사용합니다.
k+T-1까지의 값을 구하기 위해서는 다시 k+T-2까지의 값을 구해야 하는데 이를, IMS prediction이라 합니다.
IMS prediction은 error accumulation effect를 잠재적으로 가지고 있기에 당연히 성능이 좋지 않을 수 밖에 없습니다.

Problem definition
저자는 과연 IMS prediction문제가 아닌 경우에서 Transformer-based model이 LTSF 문제를 해결하는데 적절한 것인 지에 대한 의문을 제기합니다.
이 의문을 해결하기 위해, 저자는 Transformer와 같이 복잡한 모델을 사용하지 않고 매우 단순한 model을(embarrassingly simple linear model) 사용해서 여러 LTSF 벤치마크 데이터셋에서 성능을 비교합니다.
또한, attention, positional encodding이나 temporal embedding 등 Transformer에서 사용하는 기법들이 LTSF에서 유용하게 작용하는 지를 다양한 실험을 통해서 확인합니다.
II. Transformer-based models
LogTrans (NeurIPS, 2019), https://proceedings.neurips.cc/paper/2019/hash/6775a0635c302542da2c32aa19d86be0-Abstract.html
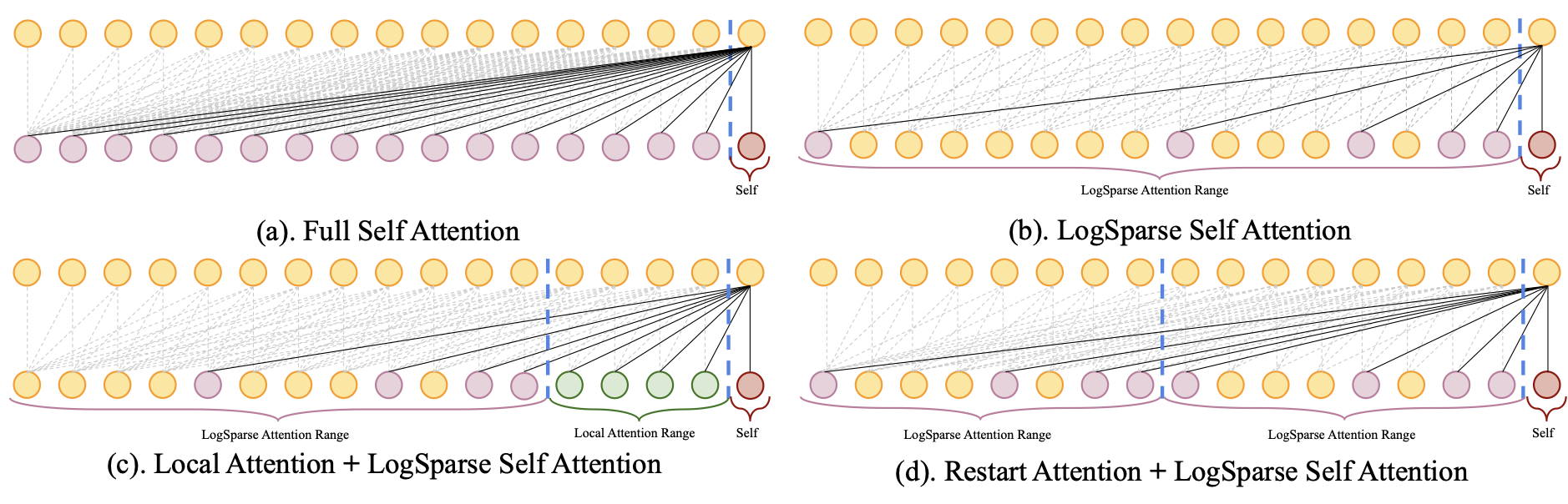
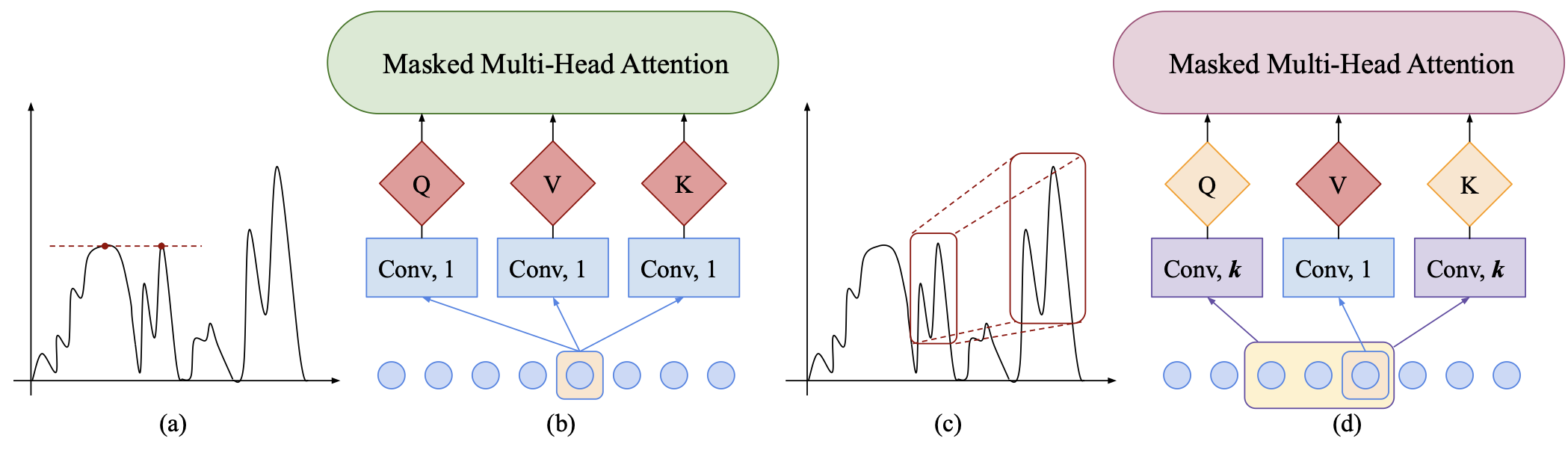
Informer (AAAI, 2021 Best Paper) https://ojs.aaai.org/index.php/AAAI/article/view/17325
Autoformer (NeurIPS, 2021) https://proceedings.neurips.cc/paper/2021/hash/bcc0d400288793e8bdcd7c19a8ac0c2b-Abstract.html
Pyraformer (ICLR, 2022 Oral) https://openreview.net/forum?id=0EXmFzUn5I
FEDformer (ICML, 2022) https://proceedings.mlr.press/v162/zhou22g.html
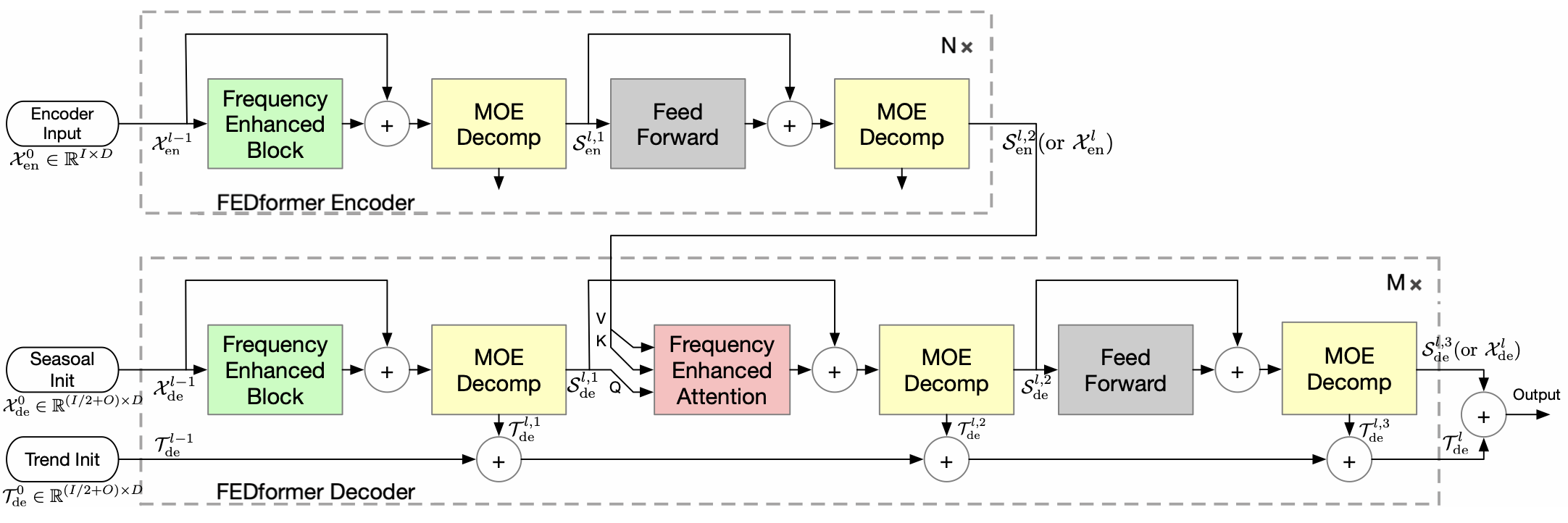
III. Experiment
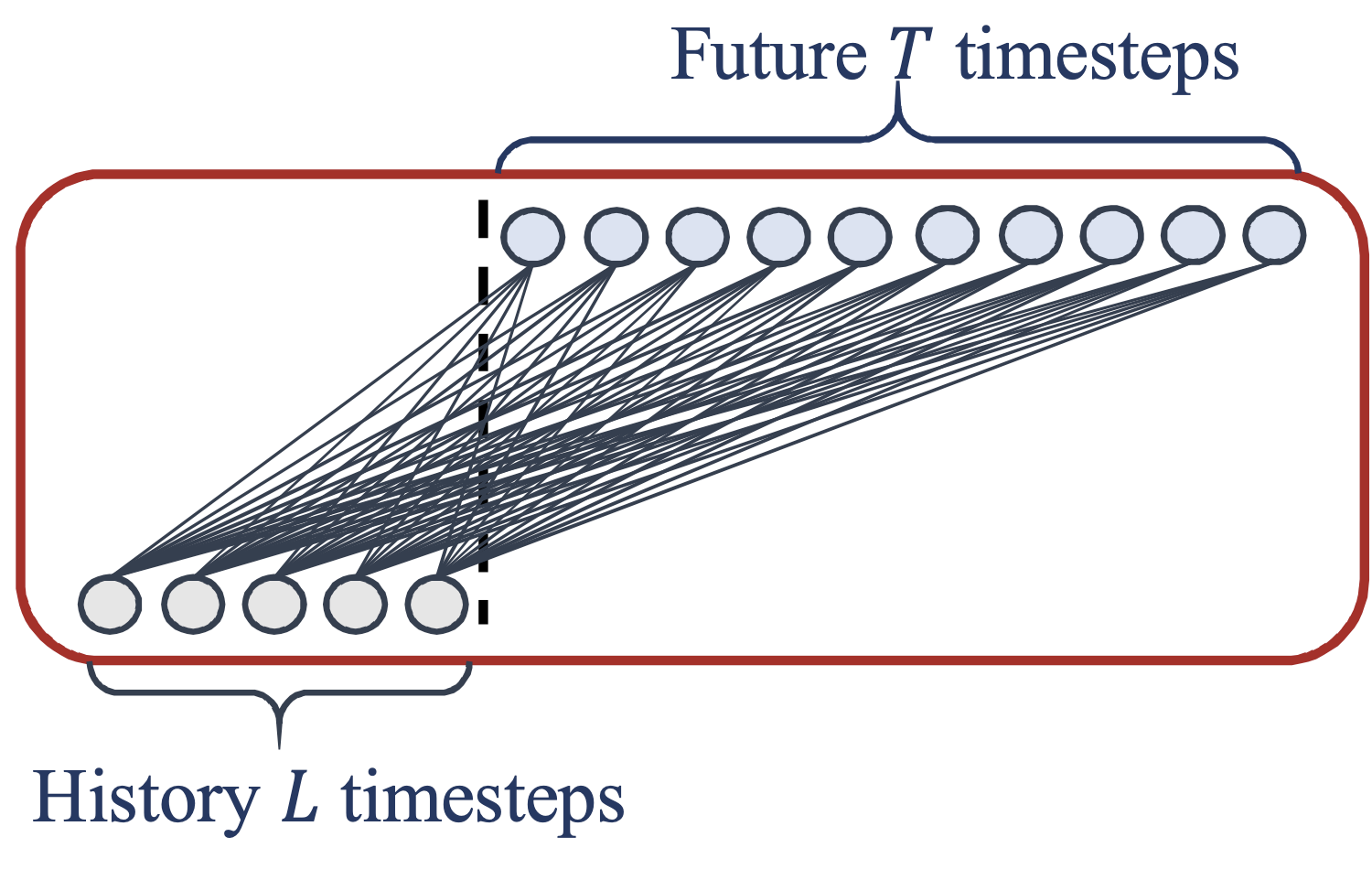
Direct multi-step(DMS) prediction
IMS 예측 방식은 예측할 time stamp(혹은 index)가 늘어남에 따라 confidence interval이 늘어나는 문제점이 있습니다.
본 논문에서는 이러한 오차 누적 문제로 인해서 모델 성능 평가가 공정하게 이루어지지 않았다고 주장합니다.
DMS 예측은 IMS 예측과 다르게 현 시점 k에서 k+T까지 값을 예측하기 위해서 k+T-1까지의 값을 예측할 필요가 없습니다.
아래 그림에서 보이는 것과 같이 DMS 방식은 이전 L(Lookback) 시점 데이터를 인풋으로 주어주면 T 이후 시점까지의 값들을 한 번에 아웃풋으로 예측합니다.
이는 다른 Transformer-based model들과 같은 방식(DMS)의 예측 방법이기 때문에 누적 오차로 인해 생기는 불공정성을 해소하고 성능을 비교할 수 있게 해줍니다.
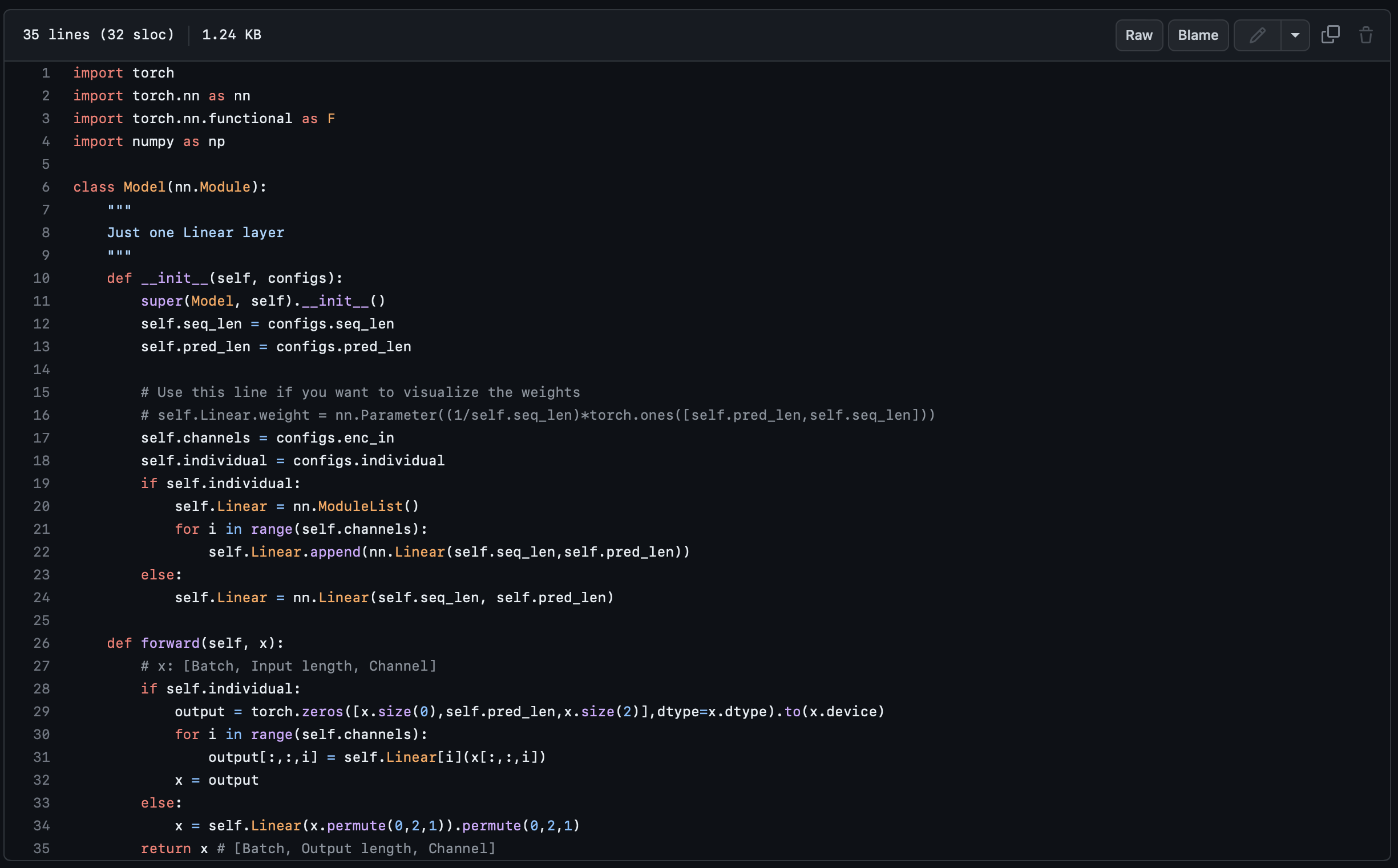
Embarrassingly simple linear model
 <출처> : https://github.com/cure-lab/LTSF-Linear
<출처> : https://github.com/cure-lab/LTSF-Linear
성능 비교를 위해 제안되는 model의 아키텍처는 매우 간단합니다.
L개의 인풋 시계열을 받아서 T개의 아웃풋 시계열을 배출하는 한 개의 linear layer를 사용합니다.
DLinear
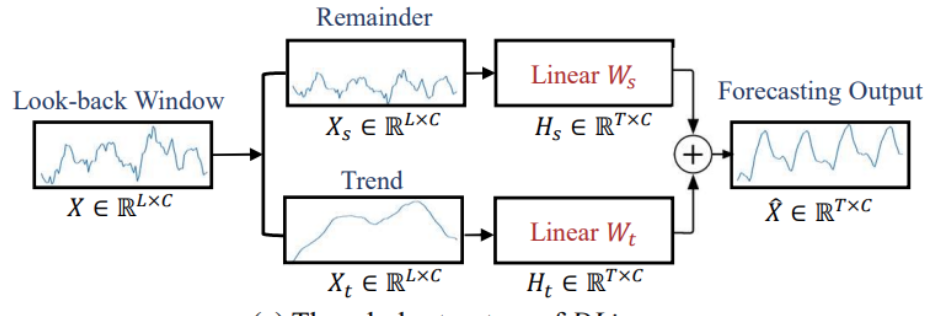
저자는 vanilla linear model 외에도 시계열 성분을 분해하는 전처리 과정을 거친 DLinear 또한 제안합니다.
DLinear는 vanilla linear model보다는 복잡한 아키텍처를 갖지만, 여전히 매우 단순한 형태를 갖고 있습니다.
DLinear는 먼저 시계열 데이터에서 moving average로 추세 성분 추출합니다.
Moving average로 trend 성분을 추출한 뒤, 남은 잔차를 추출합니다.
추세와 잔차를 분리하면 각각의 linear layer에 인풋 데이터로 사용돼 T시점 후까지의 값을 예측합니다.
NLinear
NLinear는 시계열 분해로 전처리를 하지 않습니다.
NLinear는 z-score를 이용해서 시계열 데이터를 정규화 하여 linear layer의 인풋 데이터로 사용합니다.
Dataset
 L = {96, 192, 336, 720}, T = 720
L = {96, 192, 336, 720}, T = 720
ETT dataset : https://github.com/zhouhaoyi/ETDataset
Traffic dataset : http://pems.dot.ca.gov
Electricity dataset : https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014
Exchange-Rate dataset : https://github.com/laiguokun/multivariate-time-series-data
Weather dataset : https://www.bgc-jena.mpg.de/wetter/
ILI dataset : https://gis.cdc.gov/grasp/fluview/fluportaldashboard.html
Evaluation index
본 실험은 회귀에 대한 성능 평가가 필요하기 때문에 평균 제곱 오차를 사용해서 성능을 비교했습니다.
IV. Result & discussion
Performance evaluation
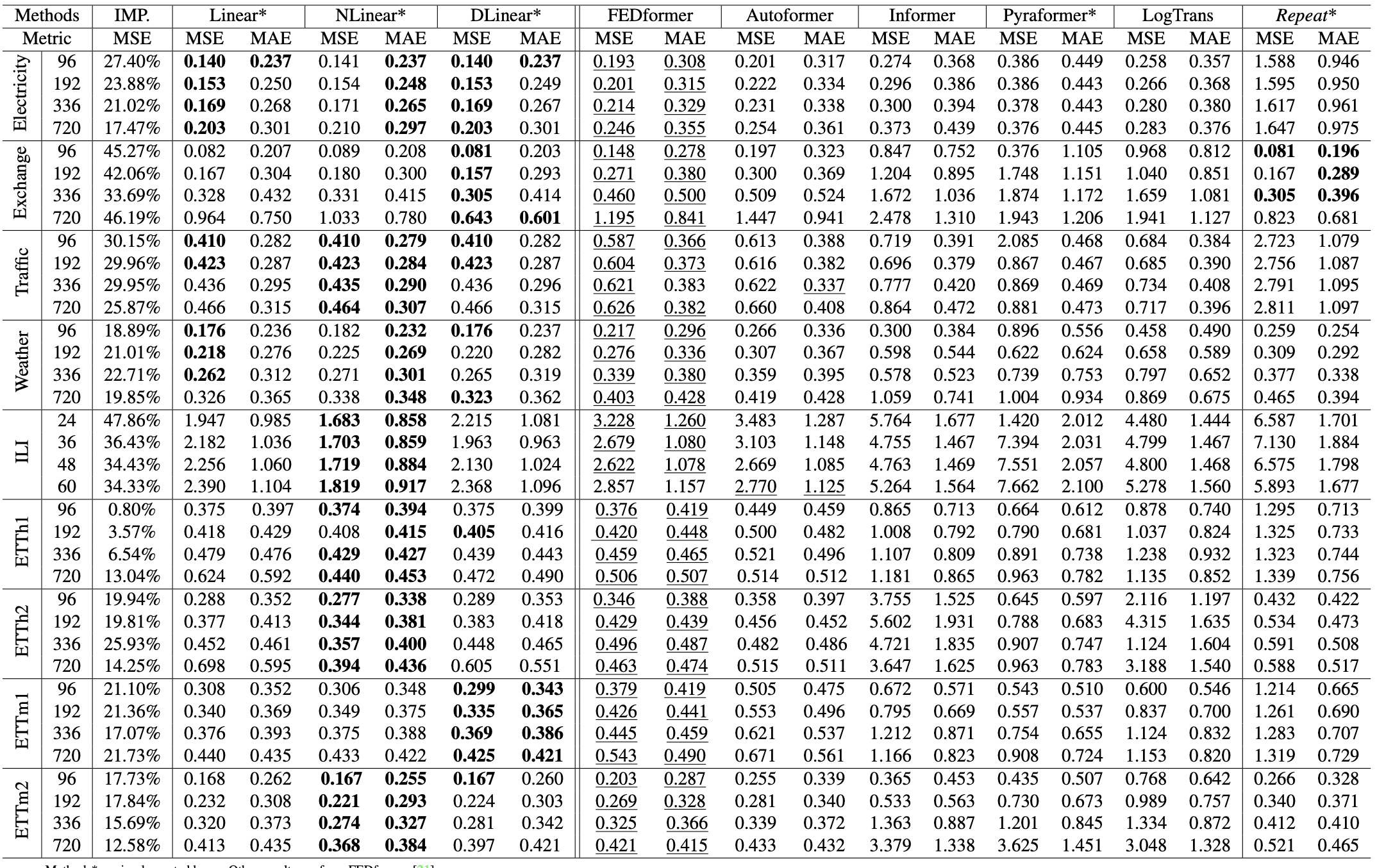
실험 결과는 놀랍게도 저자가 제안했던 아주아주 간단했던 모델들이 모든 데이터셋에 대해 더 좋은 성능을 보이고 있습니다.
심지어 더 놀라운 점은 저자가 제안했던 model들 중에서도 가장 간단했던 vanilla linear model은 몇몇 데이터셋에서는 가장 우수한 성능을 보인다는 점입니다.
매우 간단한 모델들과 비교했을 때 성능이 저조하기 때문에 Transformer는 LTSF에서 좋은 성능을 보이지 않는 것을 의미합니다.
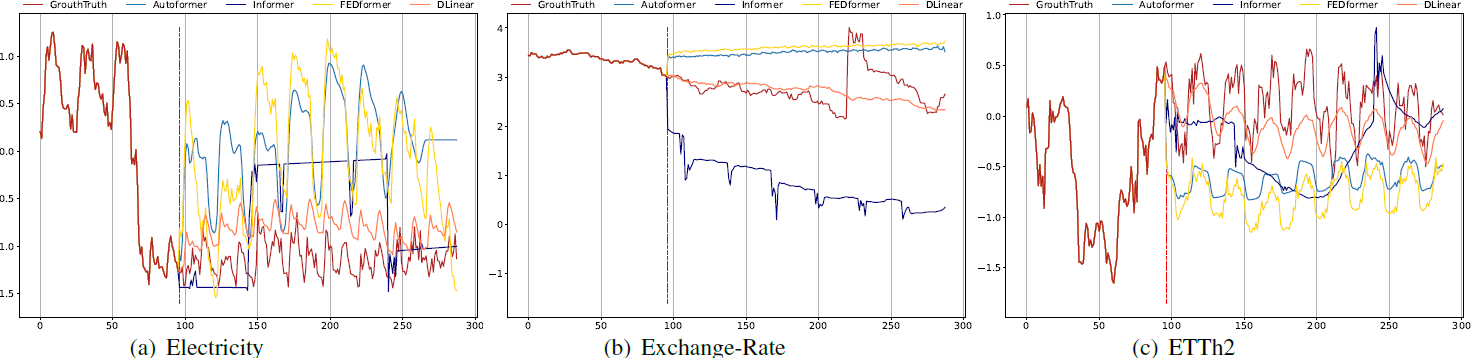
Can they extract more temporal information from LONGER inputs?
또한, 저자는 잘 설계된 LTSF model은 보다 긴 시계열 데이터를 받았을 때 더 우수한 성능을 보여야 한다고 주장합니다.
아래 그림에서 보이는 것처럼 저자가 제안했던 linear model들은 보다 긴 인풋 시계열로 학습을 했을 때 점차 성능이 증가하는 것을 확인할 수 있습니다.
반면에, Transforemer-based model들은 인풋 시계열의 길이에 상관 없는 학습 경향을 보이거나 반대로 오히려 성능이 떨어지는 것도 확인할 수 있습니다.
이 결과들은 Transformer는 LTSF에서 효과적으로 시계열 특성을 추출하지 못 하는 것을 의미합니다.
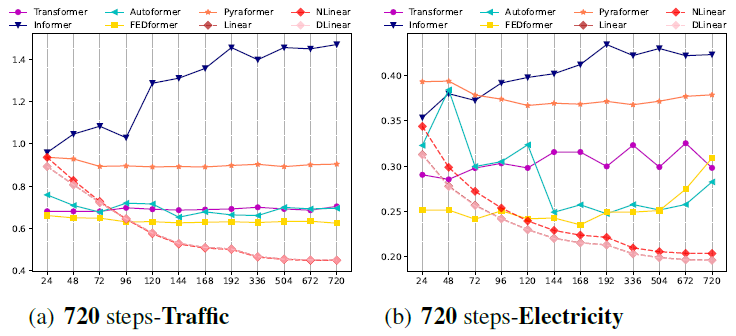
Can Trasnformer-based models preserve temporal order?
만약, 학습된 model이 temporal order를 정말 잘 추출한다면 raw data의 시계열 특성이 바뀌면 성능의 저하가 일어날 것입니다.
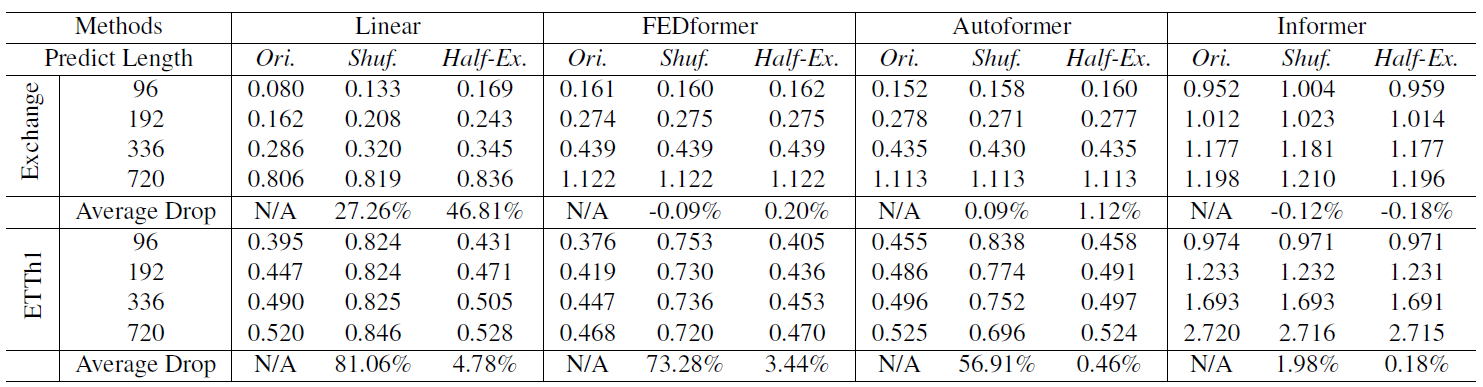
Transformer-based model이 temporal order를 정말 잘 추출하는 지 확인하기 위해서 저자는 test dataset의 raw data를 변형하여 실험합니다.
Shuf.는 raw data를 랜덤하게 섞는 전처리를 의미합니다.
Half-Ex.는 raw data의 절반으로 나누고 두 개의 순서를 바꾸는 전처리를 의미합니다.
실험 결과 vanilla linear의 경우 temporal order가 바뀌면 이에 따라 성능의 현저한 저하가 일어납니다.
반면에, Transformer-based models는 시계열의 순서에 상관 없이 성능의 저하가 크게 일어나지 않는 것을 확인할 수 있습니다.
이는 Transformer-based models가 LTSF task에서 시계열 순서를 추출하지 못 함을 의미합니다.
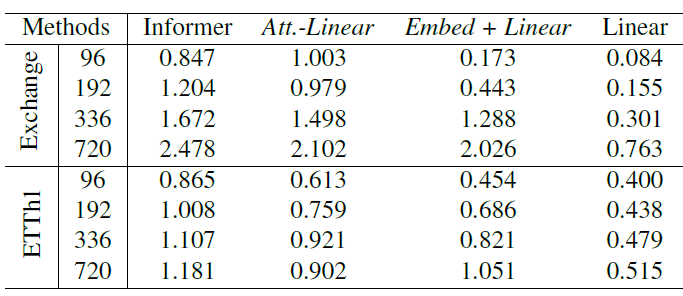
Are the self-attention scheme really effective for LTSF?
저자는 더 나아가 근본적으로 Transformer에 사용되는 기법이 LTSF에 효율적인 지 의문을 제기합니다.
Informer를 시작으로 저자는 model의 구성 요소들을 경량화하여 성능을 비교합니다.
Att.-Linear는 Informer의 모든 attention block을 FCL로 바꾼 네트워크입니다.
Embed + Linear는 바꾼 FCL마저도 없애고 temporal embedding layer와 linear layer만 남긴 model입니다.
결과는 놀랍게도 linear layer 하나만 있을 때 가장 좋은 성능을 보여줍니다.
이는 Transformer의 attention 기법들은 LTSF에 효과적이지 않음을 의미합니다.
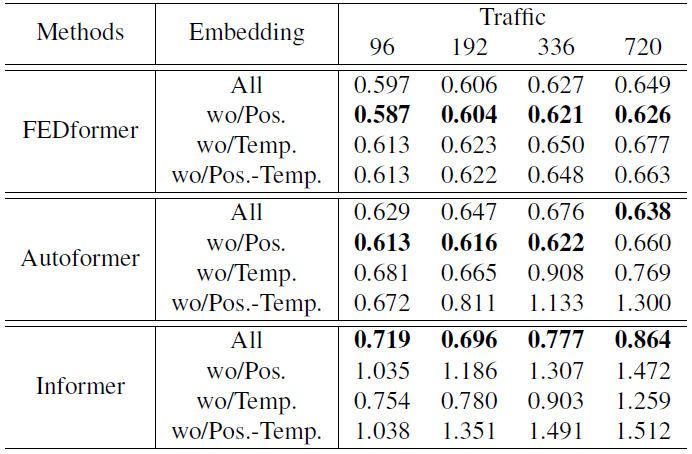
마지막으로, 저자는 positional encoding 혹은 temporal embedding가 LTSF에 효과적인 지를 실험합니다.
All은 positional encoding과 temporal embedding을 사용한 모델입니다.
wo/Pos는 positional encoding만 사용하지 않은 모델입니다.
wo/Temp.는 temporal embedding만 사용하지 않은 모델입니다.
wo/Pos.-Temp는 두 개 모두 사용하지 않은 모델입니다.
IIV. Conclusion
저자는 LTSF task에서 transformer-based 솔루션의 효과에 대한 의문을 제기합니다.
의문을 해소하기 위해 DMS 예측 베이스라인의 간단한 선형 모델인 LTSF-Linear을 사용하여 주장을 검증합니다.
제안된 선형 모델과의 성능을 비교함으로써, 다양한 관점에서 Transformer가 LTSF에 효과적이지 않은 이유를 설명했습니다.
