💡며칠 전부터 매일매일을 구독하면서 하루에 하나씩 기술 관련 이론을 공부하며 하루를 시작하고있습니다. 최근 데이터베이스 인덱스에 대한 질문에 대하여 공부를 하던 중 흥미로운 내용을 발견해서 함께 정리해보려 합니다.
인덱스?
인덱스는 데이터베이스를 사용하는 개발자라면 반드시 알아야 할 핵심 개념 중 하나입니다. 인덱스를 설명할 때 흔히 백과사전의 색인을 예로 들곤 하는데요. 수많은 페이지 중에서 특정 내용을 빠르게 찾고 싶을 때, 색인 페이지를 보면 해당 키워드가 몇 페이지에 있는지 바로 알 수 있습니다.
데이터베이스 인덱스도 이와 비슷합니다. 추가적인 저장 공간(페이지)을 사용해서 자료 검색에 특화된 새로운 자료 구조를 만들고, 이를 통해 조회 성능을 크게 향상시키는 것이 바로 인덱스의 목적입니다.
그렇다면 이 인덱스의 데이터는 어떤 형태로 저장되어 있길래 조회 성능을 이렇게까지 높일 수 있는 걸까요? 인덱스의 자료 구조를 검색해보면 B-Tree라는 단어를 자주 접할 수 있습니다. 실제로 현대 대부분의 관계형 데이터베이스(RDB)는 인덱스 자료 구조로 B-Tree (혹은 B-Tree의 변형인 B+Tree)를 채택하고 있습니다.
| DBMS | 기본 인덱스 구조 | 특수 인덱스 유형 | 비고 |
|---|---|---|---|
| MySQL (InnoDB) | B+Tree | Full-text, Spatial, Hash (MEMORY 엔진) | InnoDB는 클러스터형 인덱스를 사용해요. |
| PostgreSQL | B-Tree | Hash, GiST, GIN, BRIN, SP-GiST | 다양한 데이터 타입에 최적화된 인덱스를 제공해요. |
| Oracle | B-Tree | Bitmap, Hash, Clustered, Function-based | 병렬 처리와 옵티마이저 힌트와의 연동이 강력해요. |
| SQL Server | B+Tree | Full-text, XML, Spatial, Filtered | 클러스터형/비클러스터형 인덱스를 선택할 수 있어요. |
| MongoDB | B-Tree | Geospatial, Text, Hashed | 복합 인덱스와 다중 필드 인덱스를 지원해요. |
| Redis | 없음 (자료구조 기반) | ZSET(Range), HASH, SET, BITMAP | 검색용 인덱스가 아니라 데이터 구조 자체가 인덱스 역할을 해요. |
| Elasticsearch | Inverted Index | BKD Tree (for range), Term dictionary | 검색 엔진에 특화되어 있고, 텍스트 분석 기반이에요. |
하지만 사실 인덱스에는 B-Tree 형태 외에도 여러 가지 자료 구조가 사용될 수 있습니다.
| 자료구조 | 특징 | 사용 목적 |
|---|---|---|
| B-Tree / B+Tree | 정렬된 키를 저장하고, 범위 검색에 효율적이에요. | 대부분의 조건( =, <, >, BETWEEN, ORDER BY)에 사용되는 범용 인덱스입니다. |
| Hash Table | = (등가) 검색에 매우 빠르지만, 정렬/범위 검색은 불가능해요. | WHERE key = value와 같이 정확히 일치하는 값을 찾을 때만 빠르게 처리해요. |
| Bitmap | 공간 효율이 좋고, 카디널리티(중복도)가 낮은 데이터에 적합해요. | 성별 = 남 / 국가코드 = KR처럼 중복되는 값이 많은 경우에 유용해요. |
| GIN (Postgres) | 다중 키워드 검색에 특화되어 있어요. | 배열, JSONB, 전문 검색(Full-text search) 등에 사용돼요. |
| GiST (Postgres) | 범용 인덱스 프레임워크로, 다양한 데이터 타입과 연산자를 지원해요. | 위치 정보, 유사도 검색 등에 활용돼요. |
| ZSET (Redis) | 정렬된 Set 형태로, 스코어(score) 기반으로 정렬돼요. | 실시간 랭킹, 우선순위 큐 등에 사용돼요. |
| BKD Tree (Lucene) | 고차원 숫자 및 벡터 데이터 처리에 강해요. | Elasticsearch에서 범위/필터 검색에 사용돼요. |
오늘 우리는 이 중에서 인덱스 자료 구조의 핵심이라고 할 수 있는 B-Tree와 Hash Table의 개념을 자세히 알아보고, 왜 인덱스에 다른 자료 구조가 아닌 B-Tree가 주로 사용되는지(사용되어야 하는지)에 대해 이야기해보겠습니다.
인덱스 자료 구조 자세히 보기
앞서 살펴본 것처럼 인덱스에는 다양한 자료 구조가 사용될 수 있습니다. 이 중에서 Hash Table과 B-Tree 자료 구조에 대해 조금 더 자세히 알아볼겠습니다.
Hash Table (해시 테이블)
Hash Table은 (Key, Value) 쌍의 형태로 데이터를 저장하는 자료 구조입니다. Key 값으로 사용될 데이터를 해시 함수(Hash Function)를 통해 고유한 인덱스(주소)를 생성하고, 그 주소에 데이터를 저장합니다.
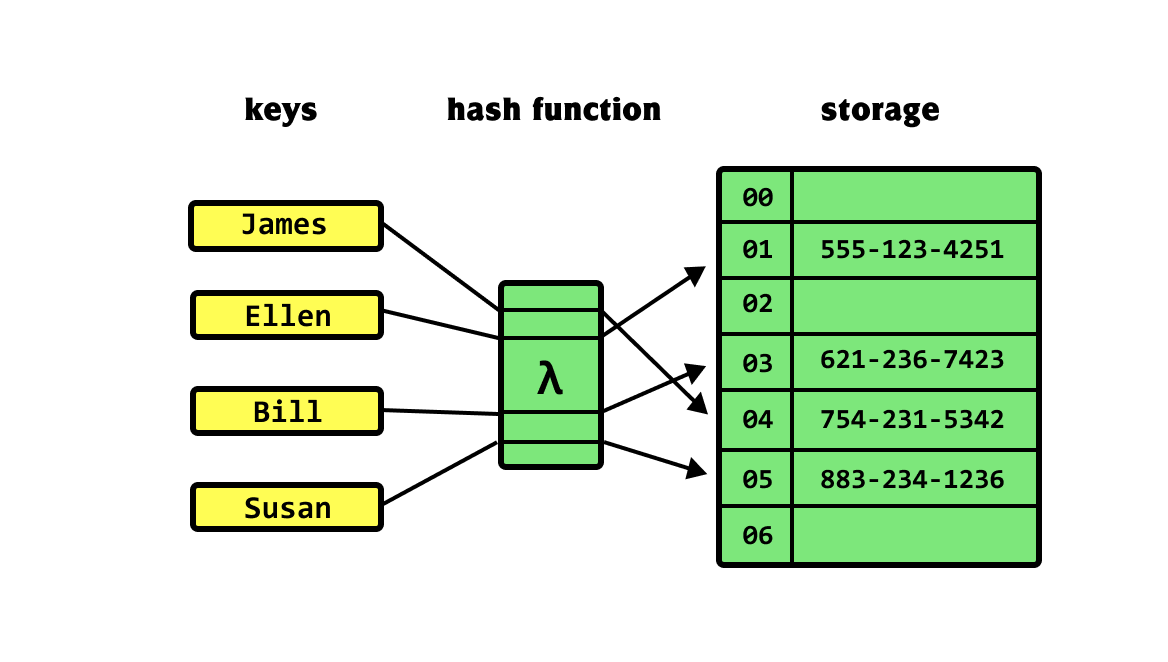
이러한 특성 때문에 Hash Table이 적용된 인덱스에서는 WHERE key = value와 같이 정확히 일치하는 값을 찾는 등가(Equal) 검색 시 데이터의 위치를 한 번에 계산할 수 있어 O(1)이라는 매우 빠른 시간 복잡도로 검색을 지원합니다. 말 그대로 찰나의 순간에 데이터를 찾아낼 수 있다는 뜻이죠.
하지만 인덱스 자료구조로 Hash Table을 사용하지 못하는 데에는 이유가 있습니다. where 조건으로 고유 번호에 해당하는 1:1 대응 데이터를 조회하는 것 외에 대부분 데이터 조회는 특정 범위에 해당하는 범위 연산을 필요로 합니다. 하지만 Hash Table은 부등호 (<, >, <=, >=)나 BETWEEN 등을 사용한 범위 연산을 지원하지 않습니다. 데이터가 해시 함수에 의해 무작위로 흩어져 저장되기 때문에, "A부터 Z까지"와 같은 범위의 데이터를 찾으려면 결국 전체 테이블을 스캔(Table Full Scan)해야 합니다. 또한, 데이터를 정렬하여 저장하지 않기 때문에 클러스터링(Clustering)을 지원하지 않는다는 단점도 있습니다. 그럼에도 불구하고 동등 비교 시 O(1)이라는 매력적인 성능 향상 효과 때문에 인덱스에 제한적으로 사용되기도 합니다.
📘 잠깐! 스캔 방식에 따른 성능 차이
데이터베이스는 데이터를 조회할 때 여러 방식의 스캔 전략을 사용합니다.
아래는 스캔 방식에 따른 성능 효율을 간단히 정리한 표입니다.
스캔 방식 설명 성능 효율 Full Table Scan 인덱스 없이 테이블 전체를 읽음 ❌ 매우 낮음 Index Full Scan 인덱스 전체를 순차적으로 읽음 ⚠️ 중간 Index Range Scan 인덱스 범위 조건에 해당하는 부분만 탐색 ✅ 효율적 Index Unique Scan PK 또는 Unique 조건으로 1건만 조회 ✅✅ 매우 효율적 Index Only Scan 인덱스만으로 모든 데이터 조회 ✅✅ 매우 효율적 Hash Table 자료구조를 사용하는 인덱스를 기준으로 범위 조회를 실행하게 된다면 가장 좋지 않은 성능의 Full Table Scan이 수행되는 것입니다.
B-Tree (비-트리)
B-Tree는 "Balanced Tree(균형 트리)"의 약자로, 이름처럼 균형이 잘 잡혀 있는 트리(Tree) 자료 구조를 의미합니다. 우리가 흔히 아는 이진 트리(Binary Tree)와 비슷하지만, B-Tree는 하나의 노드가 여러 개의 자식 노드를 가질 수 있는 다원 탐색 트리의 일종입니다.
B-Tree는 크게 루트 노드(Root Node), 내부 노드(Internal Node), 리프 노드(Leaf Node)로 구성되어 있으며, 각 노드에 데이터를 저장하고 있습니다.
B-Tree의 구조와 특징
B-Tree는 데이터베이스 인덱스의 표준이라고 할 수 있습니다. 그 이유는 바로 B-Tree가 인덱스의 핵심 목표인 빠른 검색과 더불어 범위 검색, 데이터 삽입/삭제 시의 효율성을 모두 만족시키기 때문입니다.
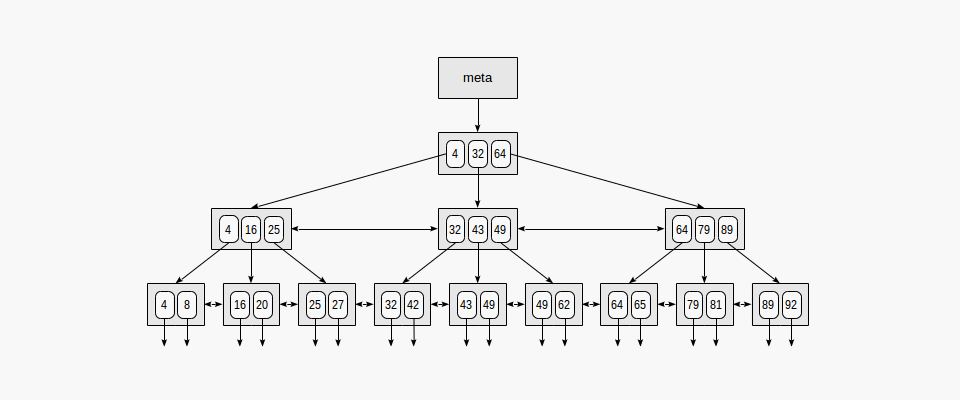
B-Tree의 구성 요소:
- 루트 노드 (Root Node): 트리의 가장 상위에 있는 노드입니다. 모든 검색은 루트 노드에서 시작됩니다.
- 내부 노드 (Internal Node): 루트 노드와 리프 노드 사이에 있는 노드들입니다. 내부 노드에는 다음 레벨의 자식 노드로 이동하기 위한 키(Key) 값과 해당 자식 노드의 주소(포인터)가 저장됩니다. 실제 데이터는 저장하지 않고, 검색 경로를 안내하는 역할을 합니다.
- 리프 노드 (Leaf Node): 트리의 가장 하위에 있는 노드들입니다. 리프 노드에는 실제 데이터 레코드의 키 값과 해당 레코드가 저장된 테이블의 주소(ROWID 또는 Primary Key)가 함께 저장됩니다. 리프 노드는 항상 같은 레벨에 위치하여 트리가 균형을 유지하도록 돕습니다.
B-Tree의 작동 원리 (검색):
B-Tree에서 데이터를 검색하는 과정은 매우 효율적입니다. 예를 들어, 특정 ID를 가진 레코드를 찾는다고 가정해봅시다.
- 루트 노드에서 시작하여 찾으려는
ID와 노드에 저장된 키 값들을 비교합니다. - 비교 결과에 따라 다음 레벨의 적절한 자식 노드로 이동합니다. (예: 찾으려는 ID가 노드의 키 값보다 작으면 왼쪽 자식, 크면 오른쪽 자식 등)
- 이 과정을 리프 노드에 도달할 때까지 반복합니다.
- 리프 노드에 도달하면 해당 키 값이 있는지 확인하고, 있다면 연결된 실제 데이터 레코드의 주소를 통해 데이터를 가져옵니다.
B-Tree는 노드에 저장되는 키의 개수가 많을수록 트리의 깊이가 얕아지므로, 디스크 I/O (데이터를 읽고 쓰는 작업) 횟수를 줄여 검색 속도를 향상시킵니다. 트리의 깊이가 얕다는 것은 데이터를 찾기 위해 거쳐야 하는 노드의 수가 적다는 의미이고, 이는 곧 디스크에서 데이터를 읽어와야 하는 횟수가 적다는 것을 뜻합니다.
B+Tree (비플러스-트리)와 B-Tree의 차이점
대부분의 현대 관계형 데이터베이스는 B-Tree보다는 B+Tree를 인덱스 자료 구조로 채택하고 있습니다. B+Tree는 B-Tree의 장점을 계승하면서, 특히 범위 검색 성능을 극대화하기 위해 고안된 자료 구조입니다.
B+Tree의 주요 특징 (B-Tree와의 차이점):
- 내부 노드에는 데이터가 저장되지 않는다: B-Tree는 모든 노드에 데이터를 저장할 수 있지만, B+Tree는 오직 리프 노드에만 데이터(또는 데이터 레코드의 포인터)를 저장합니다. 내부 노드는 오로지 자식 노드를 가리키는 키 값과 포인터만 가지고 있습니다.
- 장점: 내부 노드의 크기가 작아지므로, 한 블록(페이지)에 더 많은 키 값을 저장할 수 있습니다. 이는 트리의 높이를 더욱 낮춰 디스크 I/O를 줄이는 데 유리합니다.
- 리프 노드는 연결 리스트(Linked List)로 연결되어 있다: B+Tree의 모든 리프 노드는 좌우로 연결 리스트처럼 서로 연결되어 있습니다.
- 장점: 이 연결 덕분에 범위 검색(Range Search)이 매우 효율적입니다. 특정 범위의 데이터를 찾을 때, 시작 값을 가진 리프 노드를 찾은 후 연결된 리스트를 따라가면서 필요한 범위의 데이터를 순차적으로 읽어낼 수 있습니다. B-Tree에서는 범위 검색 시 여러 노드를 오가며 찾아야 할 수도 있어 비효율적입니다.
- 모든 키 값은 리프 노드에 존재한다: B+Tree에서는 모든 키 값이 리프 노드에 중복 저장됩니다. 내부 노드는 단지 검색 경로를 위한 키 값을 가지고 있을 뿐입니다.
- 장점: 어떤 종류의 검색(단일 값 검색이든 범위 검색이든)이든 항상 리프 노드까지 도달해야 하므로, 검색 시간이 예측 가능하고 일관적입니다.
왜 B-Tree 대신 B+Tree를 사용할까?
데이터베이스 인덱스의 주된 목적 중 하나는 범위 검색입니다. 사용자는 특정 값을 찾는 것 외에도 "나이가 20세에서 30세 사이인 사람들"이나 "날짜가 2025년 1월부터 3월까지인 데이터"와 같은 범위 조건을 자주 사용합니다. B+Tree는 리프 노드가 연결 리스트로 이어져 있어 이러한 범위 검색에 압도적으로 효율적입니다.
또한, 내부 노드에 데이터를 저장하지 않음으로써 한 노드에 더 많은 키를 담을 수 있어 트리의 높이가 더 낮아지고, 이는 디스크에서 데이터를 읽어오는 횟수를 줄여 전반적인 성능을 향상시킵니다. 따라서 B+Tree는 대용량 데이터를 처리하는 관계형 데이터베이스의 인덱스에 가장 적합한 자료 구조로 널리 사용됩니다.
결론: 왜 인덱스는 B-Tree (B+Tree)일까?
이제 왜 데이터베이스 인덱스에 B-Tree (정확히는 B+Tree)가 주로 사용되는지 명확해졌을 것입니다.
- 빠른 탐색 속도: 균형 잡힌 트리 구조로 어떤 데이터를 찾든 최악의 경우에도 트리의 깊이만큼만 탐색하면 되므로, 일관되고 빠른 검색 성능을 보장합니다. 이는 디스크 I/O를 최소화하는 데 핵심적입니다.
- 효율적인 범위 검색: 특히 B+Tree의 리프 노드 연결은
WHERE절에 부등호나BETWEEN을 사용하는 범위 검색을 매우 효율적으로 처리할 수 있게 합니다. - 삽입/삭제 시 성능 유지: 새로운 데이터가 삽입되거나 삭제될 때도 트리의 균형을 자동으로 조절하여 검색 성능 저하를 방지합니다. Hash Table과 달리 데이터의 추가/삭제가 빈번해도 충돌 문제를 걱정할 필요가 적습니다.
- 다양한 연산 지원:
=뿐만 아니라<,>,<=,>=,BETWEEN,ORDER BY등 다양한 조건절에 인덱스를 활용할 수 있어 활용도가 높습니다.
결론적으로 B-Tree와 B+Tree는 빠른 단일 검색, 효율적인 범위 검색, 그리고 데이터 변경에 강하다는 인덱스의 요구사항을 모두 만족시키기 때문에 현대 데이터베이스 인덱스의 핵심 자료 구조로 자리 잡았습니다.
인덱스는 단순히 빠른 조회를 위한 도구가 아니라, 데이터베이스의 성능을 좌우하는 중요한 요소입니다. 오늘 다룬 B-Tree와 Hash Table의 개념을 잘 이해하고 활용하여 더욱 효율적인 데이터베이스 설계와 쿼리 작성을 할 수 있기를 바랍니다!

종완님, 재밌게 잘읽었습니다.
덕분에 B-Tree와 B+Tree의 차이점에 대해 좀 더 명확하게 알게 됐어요 👍