10. 비지도학습
지도기법이 적용되기 전에 파생변수 생성이나 데이터 시각화하거나 전처리하는데 사용되는 도구. 비지도학습은 보통 탐색적 자료분석의 일부로서 수행된다.
주성분분석 (PCA)
원래 집합의 대부분의 변동성을 총체적으로 설명할 수 있는 적은 수의 대표적인 변수들을 가지고 이 집합을 요약할 수 있게 해준다. 주성분회귀를 수행하기 위해서는 단순히 원래 변수들의 집합 대신에 주성분들을 회귀모델의 설명변수들로서 사용한다.
PCA는 가능한 한 관심도가 높은 작은 차원을 찾는 것이다. 관심있는이란 개념은 관측치들이 각 차원을 따라 변하는 정도에 의해 측정된다. PCA에 의해 발견된 각 차원은 p개 변수들의 선형결합이다.
첫 번째 주성분은 가장 큰 분산을 가지게 되는 변수들의 정규화된 선형결합이다.
두 번째 주성분은 첫 번째 주성분과 상관되지 않은 x1,...,xp의 모든 선형결합 중에서 분산을 최대로 하는 선형결합이다. 상관되지 않게 제한하는 것은 두 방향이 직교(수직)하게 제한하는 것과 같다.
- PCA는 평균 0, 분산 1이 되게 표준화한 후 수행된다. 변수들은 측정단위가 다르기 때문에, 단순히 변수들이 측정된 스케일의 영향으로 결과가 나타난다.
- 각 주성분로딩벡터는 부호는 다를 수 있지만 고유하다. 부호가 바뀌어도 방향에 아무영향이 없기 때문이다.
- 각 주성분에 의해 설명되는 분산의 비율(PVE), 양수이며 PVE들은 더하면 1이 된다.
몇 개의 주성분들을 사용할지 대한 결정
각 주성분에 의해 분산의 비율이 크게 떨어지는 지점을 눈대중으로 찾아라! 결국 주관적인 기법이며 PCA가 일반적으로 탐색적 자료분석을 위한 도구로 사용될 수 있다.
클러스터링
데이터의 알려지지않은 서브그룹들을 발견하기 위한 광범위한 기법. 각 그룹 내의 관측치는 유사하지만 다른 그룹들의 관측치들과는 상당히 다르게 나눠야한다.
관측치들이 다르다, 유사하다는 무엇을 의미하는지 정의하기 위해선 도메인, 고려 중인 데이터에 대한 지식을 기반으로 결정되어야한다.
K-평균 클러스터링과 계층적 클러스터링
K-평균 클러스터링 : 원하는 클러스터의 수 K를 정하고, 각 관측치를 이 K개 클러스터 중 정확하게 하나에 할당하는 것이다.
클러스터 내 변동(내의 관측치들이 서로다른 정도)이 가능한 작은 것이 좋은 클러스터링이다.
클러스터 내 변동은 내의 관측치들 사이의 모든 쌍별 유클리드 거리 제곱의 합을 k번째 클러스터 내의 총 관측치 수로 나눈 것이다.
k-평균 알고리즘 순서
- 각 관측치에 1에서 K까지의 숫자를 랜덤하게 할당한다. 이것은 관측치들에 대한 초기 클러스터 할당으로 작용한다.
- 클러스터 할당이 변하지 않을 때까지 반복한다.
2-1 k개 클러스터 각각에 대해 클러스터 무게중심을 계산한다. k번째 클러스터 무게중심은 k번째 클러스터 내 관측치들에 대한 p변수 평균들의 벡터이다.
2-2 각 관측치를 그 무게중심이 가장 가까운 클러스터에 할당한다.(가장 가까운 것은 유클리드 거리를 사용하여 정의한다.)
k-평균 알고리즘은 전역최적이 아니라 국소 최적을 찾기 때문에 초기의 랜덤 할당을 다르게 하여 알고리즘을 여러번 실행하는 것이 중요하다. 이 경우, 목적값이 제일 좋은 것을 찾는다(국소 최적 솔루션)
계층적 클러스터링
얼마나 많은 클러스터들이 필요한지 미리 알지 못하며 덴드로그램이라 불리는 나무 모양으로 된 시각적 표현을 보고 확인할 수 있다. k값을 미리 지정할 필요가 없는 기법으로 상향식 또는 응집 클러스터링이다. 잎에서 시작하여 줄기 까지 클러스터들을 결합하여 만든다. 트리의 위로 올라감에 따라 잎들은 가지로 합쳐진다. 덴드로그램은 유클리드 거리를 가지고 계층적으로 클러스터링하여 얻는다.
트리를 더 높이 올라가면, 가지들은 잎들 또는 다른 가지와 합쳐지는데, 융합이 일찍 일어날수록 관측치 그룹들의 유사성은 더 높다. 반면에, 거의 꼭대기에서 융합이 늦게 일어나는 관측치들은 서로 상당히 다를 수 있다.
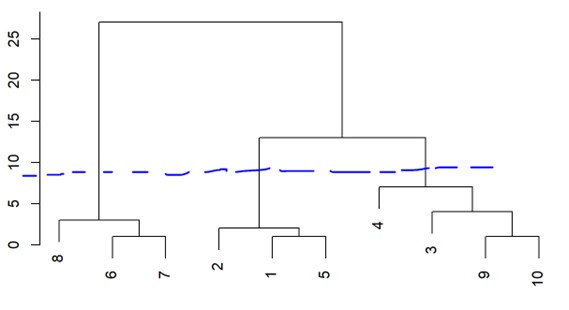
관측치 9와 10은 상당히 유사하다. 하지만 4와 3이 서로 가까이 있다고 유사하다는 결론을 내리는 것은 옳지 않다. 융합된 두가지의 위치들이 덴드로그램의 의미에 영향없이 교환될 수 있기 때문이다. 관측치 3,9,10은 모두 관측치 4와 같은 높이에서 융합되기 때문에 더 유사하다고 할 수 없다!
- 덴그로그램을 절단하는 높이는 k-평균 클러스터링에서 얻어지는 클러스터의 수를 제어하는 k와 같은 역할을 한다.
두 클러스 모두 다수의 관측치를 포함하는 경우 클러스터 사이의 비유사성을 어떻게 정의할까?
한 쌍의 관측치들 사이의 비유사성에 대한 개념이 한 쌍의 관측치 그룹들로 확장되어야한다. 비유사성을 정의하는 연결의 개념을 사용하면 된다. 덴드로그램은 연결유형에 의존적이다.
보통 단일연결보다 평균연결과 완전연결이 좀 더 균형잡힌 덴드로그램을 제공하기에 널리 사용한다.
연결유형
완전연결 : 최대 클러스터 간 비유사성. 클러스터 A내의 관측치들과 클러스터 B 내의 관측치들 사이의 모든 쌍별 비유사성을 계산하여 비유사성이 가장 큰 것을 기록한다.
단일연결 : 최소 클러스터 간 비유사성. 클러스터 A내의 관측치들과 클러스터 B 내의 관측치들 사이의 모든 쌍별 비유사성을 계산하여 비유사성이 가장 작은 것을 기록한다. 단일 연결은 단일 관측치들이 한번에 하나씩 융합되는 확장된 클러스터를 초래할 수 있다.
평균연결 : 평균 클러스터 간 비유사성. 클러스터 A내의 관측치들과 클러스터 B 내의 관측치들 사이의 모든 쌍별 비유사성을 계산하여 이들 비유사성의 평균을 기록한다.
무게중심 연결 : 클러스터 A에 대한 무게중심과 클러스터 B에 무게중심 사이의 비유사성. 무게중심연결은 바람직하지 않은 인버전을 초래할 수 있다. (두 클러스터들이 덴드로그램에서 개별 클러스터 중 어느 하나보다 낮은 높이에서 융합될 수 있는 주요 결점이 있다.)
비유사성 측도 선택
유클리드 거리를 비유사성 측도로 사용하였지만 때로는 상관기반 거리는 사용. 상관기반 거리는 두 관측치 변수들이 상관성이 높으면 관측된 값들이 유클리드 거리로는 멀리 떨어져 있더라도 유사하다고 간주한다.
변수들을 스케일링 할지 고려해야한다. 만약 관측치 간 비유사성이 계산되기 전에 변수들이 스케일링되어 표준편차가 1이 된다면, 계층적 클러스터링에서 각 변수에 주어진 중요도는 사실상 동일할 것이다. 스케일링하는 것이 좋은 결정인지는 적용되는 응용에 따라 다르다.
클러스터링에서 실질적 이슈
- 클러스터링 수행하기 위한 의사결정
관측치들 또는 변수들이 표준화되어야하는가?
계층적 클러스터링의 경우,
-어떤 비유사성 측도를 사용해야하는가?
-어떤 연결을 사용해야하는가?
-클러스터들을 얻기 위해 어디에서 덴드로그램을 절단해야하는가?
k-평균 클러스터링 경우, 데이터에서 몇 개의 클러스터들을 찾아야하는가?
--> 몇가지 다른 선택들을 시험해보고 가장 유용하거나 해석가능한 솔루션을 찾는다.
- 클러스터들에 대한 검증
우리가 찾은 클러스터들이 데이터 내의 실제 서브그룹들을 대표하는지 또는 단순히 잡음 클러스터링의 결과인지 알기 위해 새로운 어떤 독립적인 관측치들의 집합에도 동일한 클러스터들이 발견되는지 확인한다. 이를 평가하기 위해 클러스터들에 p값을 할당하는 기법들이 존재한다.
- 클러스터링은 각 관측치를 하나의 클러스터에 할당할 것이다. 하지만, 이것은 적절하지 않을 수 있다. 일부 소수 관측치들은 상당히 다르며 또한 다른 모든 관측치들과 상당히 다르다면, 어떤 클러스터에도 속하지 않는 특이점들의 존재로 심하게 왜곡될 수 있다.
혼합모델들은 이러한 특이점 존재를 수용하는 기법으로 k-평균 클러스터링의 소프트 버전이다.
또한, 클러스터링 방법들은 일반적으로 데이터의 작은 변동에 로버스트 하지 않다.
- 결과 해석
파라미터들을 다르게 선택하여 여러번의 클러스터링을 수행하고, 결과들을 모두 살펴서 어떤 패턴들이 지속적으로 드러나는지 알아보자. 또한 로버스트하지 않을 수 있으므로 클러스터들이 어느정도 로버스트한지 감을 얻기 위해 데이터 부분집합에 대해 클러스터링을 수행하는 방법이 있다.
거즘 반년동안 수업을 들으면서 이 책에 대해 몇번이고 주의깊게 읽으며 공부했다.
이전에는 공모전에서 데이터분석을 할 때 일단 랜덤포레스트 돌려보자 생각 했을텐데 여러 알고리즘의 원리에 대해 이해하게 되고 어떤 데이터에 적합한 방법일까 여러 알고리즘들을 비교하면서 공부해나가 분석결과를 얘기할 때 더욱 구체적으로 설명할 수 있는 힘?이 생긴 느낌이랄까!! 하하!
아직 헷갈리는 부분도 있으니 다음 포스팅할 땐 알고리즘의 장단점과 어떤 데이터에서 사용할 때 적합할지 정리해봐야겠다.
