Statistic
1.[책 정리] 선형 회귀
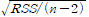
기계학습의 근간은 컴퓨터가 스스로 복잡하고 다양한 자료에서 상관관계를 분석하고 학습하여 유의미한 결과를 도출하는 통계적 학습이다. 다양한 통계학습 방법들에 기본적 이해는 알고리즘의 구현 및 적용, 결과에 대한 이해, 해석능력을 높여주는데 중요한 자산이 될 것이다옹 따라
2.[책 정리] 분류, 재표본추출, 선형모델 선택 및 regularization

반응변수의 클래스가 두 개일 때, 로지스틱 모델을 사용한다.로지스틱 모델은 적합을 위해 최대가능도 방법을 사용한다. 계수 추정치는 가능도함수를 최대화하도록 선택한다.계수 추정치의 정확도는 표준오차를 계산해서 측정할 수 있다. 일반적으로 레벨(수준)이 3이상인 질적 반응
3.[책 정리] 선형성을 넘어서(스플라인)
선형모델들은 설명과 실현이 비교적 단순하고, 해석과 추론 측면에서 다른 기법에 비해 장점이 있다.하지만 선형이랑 가정은 거의 항상 근사적인 것이고 잘 맞지도 않을 수 있기에 예측능력면에서 상당히 제한적이다. 따라서 이전에 능형회귀, lasso, 주성분회귀 등의 기법을
4.[책 정리]트리기반의 방법, 서포트벡터머신
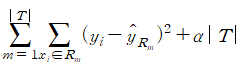
트리기반의 방법들은 해석하기 쉽고 유용하다. 하지만 처음 분할된 이후 바꿀 수 없기에 최고의지도학습기법들에 비해 예측 정확도가 떨어진다. 트리는 맨 위에서 시작하는 일련의 분할규칙으로 구성된다. 재귀이진분할을 수행하기 위해, 설명변수와 절단점(s)를 선택한다. 이 절단
5.[책 정리] 비지도학습
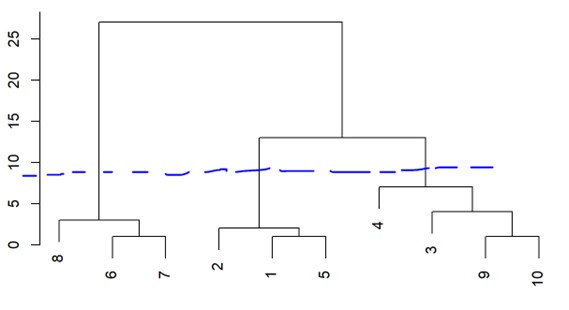
지도기법이 적용되기 전에 파생변수 생성이나 데이터 시각화하거나 전처리하는데 사용되는 도구. 비지도학습은 보통 탐색적 자료분석의 일부로서 수행된다. 원래 집합의 대부분의 변동성을 총체적으로 설명할 수 있는 적은 수의 대표적인 변수들을 가지고 이 집합을 요약할 수 있게 해