정규화 정의 및 목적
정규화란?
업무 요건에 필요한 속성을 묶어서 엔터티를 설계하는 것
그렇다면 유사한 속성을 묶는 방법은? -> 함수종속
함수 종속의 결정자와 종속자
- 결정자(식별자) : 속성 간의 종속성을 분석할 때 기준이 되는 값
- 종속자(비식별자) : 결정자의 값에 의해 정해질 수 있는 값
-> 함수 종속의 결정자가 키가 되도록 릴레이션을 분해하고 키가 아닌 속성은 키에 직접 종속되도록 분해한다.
그렇다면 릴레이션의 속성 중 키를 구하는 방법은? -> 폐포
Ex) X 폐포 : X에 종속됐다고 추론할 수 있는 모든 속성의 집합
식별자가 명확하지 않다면 폐포로 설계할 수 있고, 식별자가 있다면 정확한지 검증하는 도구로 활용할 수 있다.
정규화 목적
: 데이터 정체성 분명해진다. 엔터티간 관계가 명확해진다.
-
완전성
: 중복 데이터를 제거 -> 아노말리 발생x -> 데이터 무결성이 높아진다. -> 데이터와 DB의 안정성과 신뢰성 높아진다. -
확장성
: 함수 종속을 기반으로 결정자와 종속자를 구분해 모델 구조를 정의하기 때문에 모델을 이해하고 식별하기 쉽다 -> 확장해서 사용하기도 쉽다.
Ex) 이카운트 고객이 품목 입, 출고단가 말고도 세트여부를 추가적으로 입력해 관리하고 싶을 때
정규화 안하면 당장 문제될게 뭔데!!!
A. 아노말리 현상 발생
: 중복 데이터 때문에 데이터가 서로 맞지 않는 이상현상

정규화 하지 않은 테이블 예시)

정규형의 종류
제 1 정규형
모든 속성은 반드시 하나의 값을 가져야한다.
- 다가속성 : 같은 종류 값 여러 개
- 복합속성 : 하나 속성이 여러 개 속성으로 분리
업무와 유관하되, 의미가 존재하도록 쪼개기 + 반복형태의 속성이 있어선 안된다. 전사적으로 동일한 성격의 속성은 한 번만 존재하는 것
제 1정규화의 대상
- 다가 속성이 사용된 릴레이션
- 복합 속성이 사용된 릴레이션 : 업무와 관련되고, 의미가 존재하도록 쪼개기
- 유사한 속성이 반복된 릴레이션
- 중첩 릴레이션
- 동일 속성이 여러 릴레이션에 사용된 경우
제 1정규화 순서
-
제거해야 하는 속성을 엔터티에서 제거한다.
-
제거한 속성이 포함된 새로운 엔터티를 만든다.
-
기존 엔터티에서 새로운 엔터티로 관계를 상속한다
다가속성 예시)

유사속성 반복 예시)

제 2정규형
주 식별자가 두개 이상인 릴레이션에서 수행할 수 있다.
릴레이션의 모든 속성이 후보 식별자 전체에 종속적이면 2정규형이다. (완전 함수 종속=부분종속 제거)
제 2정규화 순서
-
제거해야 하는 속성을 엔터티에서 제거한다.
-
그 속성의 결정자를 주 식별자로 하는 새로운 엔터티를 생성한다.
-
새로 만든 엔터티에서 기존 엔터티로 관계를 상속한다(식별관계)
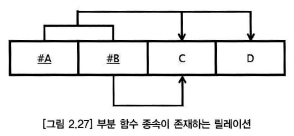
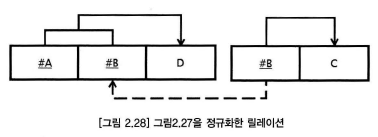
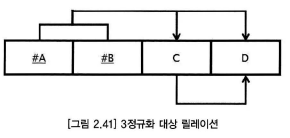
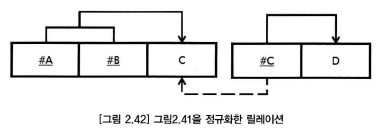
제 3정규형
제 1정규형, 제 2정규형을 만족하고, 이행적함수종속관계를 갖지 않는 것
이행종속이란? A->C / C ->D => A -> D
제 3정규화 순서
-
제거해야 하는 속성을 엔터티에서 제거한다.
-
제거한 속성이 포함된 새로운 엔터티를 만든다.
-
새로 만든 엔터티에서 기존 엔터티로 관계를 상속한다(비식별관계)
정규형의 장, 단점
성능측면
1. 조회성능
((조인 작업이 많다면))
엔터티를 분해해서 엔터티 개수가 증가했기에 작업이 많아지고 그만큼 조회가 느려질 수 있다.
((여러 건 or 특정 속성 조회할 때))
정규화를 통해 중복 데이터가 최소화되고 인스턴스의 크기가 작아진다. 따라서 한 블록에 저장하는 인스턴스는 많아져 조회 성능이 좋아질 수 있다.
데이터 유사성 측면에서 종속성, 의존성이 같은 데이터는 업무에서 같이 조회될 가능성도 켜져서 최소의 블록을 사용하는 효과가 있다. -> 조회 성능 높인다.
2. 쓰기성능
중복 속성이 없어서 여러 군데 동시에 입력하지 않아도 된다. -> 시간 오래 안걸린다.
-> 정규화를 수행한 데이터 모델이 성능을 개선하기도 수월하다. 데이터 간의 관계가 명확하지 않으면 데이터 접근, 갱신 등의 작업이 더 어렵다.
** 주의
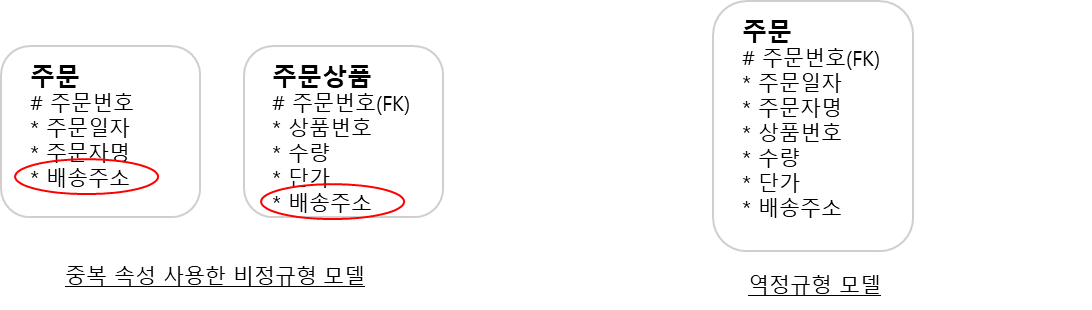
정규형 위반한 모델인 것처럼 보여도, 단순히 조인을 피하기 위해 하나의 속성을 중복시킨 비정규형 모델일 수 있다.
-> 다른 엔터티가 존재하고 관계 연결되어 있으니 중복 속성을 사용한 모델인지 판별할 수 있다.
비정규화 정의 및 목적
비정규화란?
개념 : 조회 성능을 향상시키기 위해 중복 데이터를 허용하는 것
방법
-
정규화를 거꾸로 적용
-
정규형 모델에 중복 속성을 채택
(중복 데이터는 원천 데이터와 정합성을 맞춰야 해서 사용하기 편하지 않다.)
비정규화 원칙
-
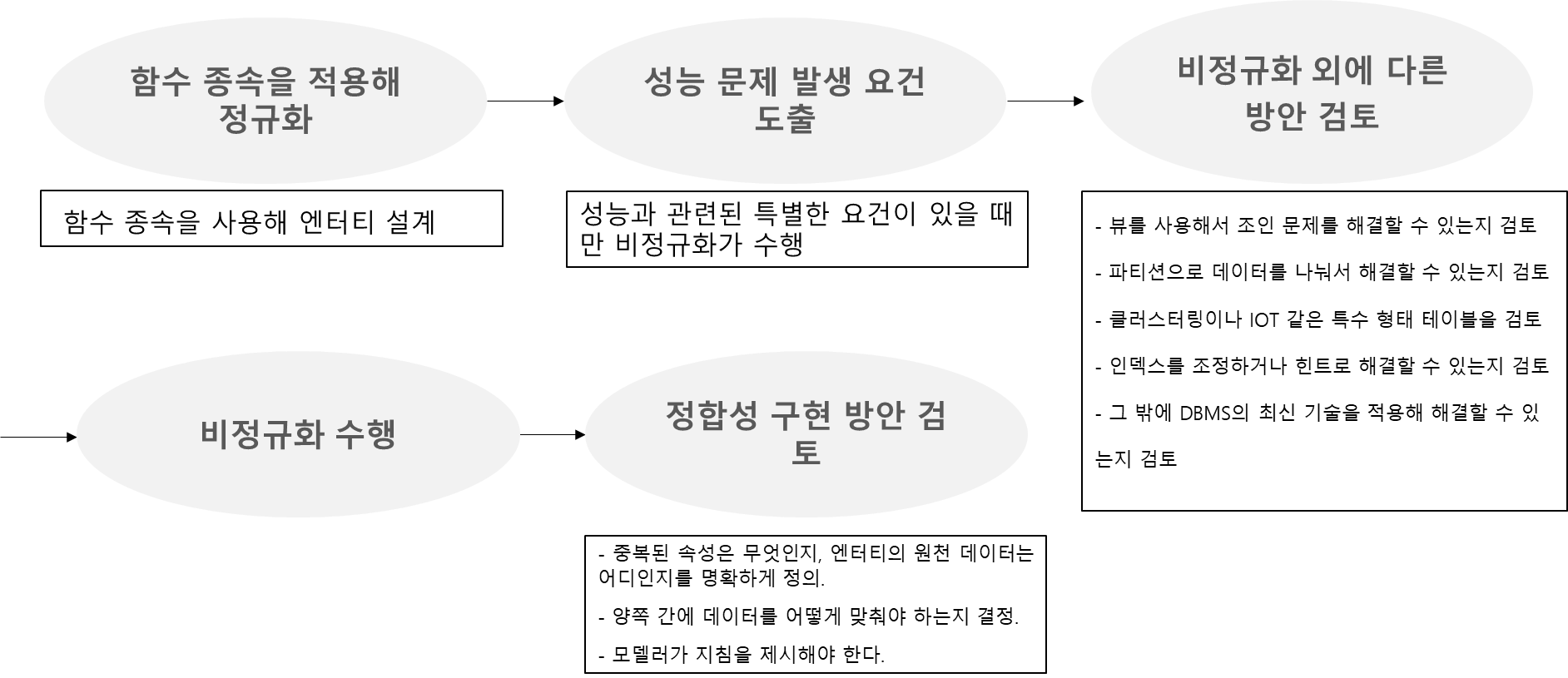
최우선적으로 고려할 요소는 데이터 무결성.
-
정규형은 필수이며, 조회 성능에 중대한 문제가 발생하는 특별한 요건이 있을 때만 비정규형을 고려한다.
-
중복 속성은 가능한 사용하지 않으며, 추출 속성은 일부 사용할 수 있다.
-> 비정규형 : 정규화 과정을 통해 생성된 정규형에 성능 요구 사항에 의해서 중복을 허용하는 것
-> 비정규형도 함수 종속을 적용해야 한다.
비정규화 과정
비정규형 장/ 단점
장점
조회 성능 문제가 발생했을 때 (예를 들어 조인 작업이 많다면) 조회 성능이 향상될 수 있다
단점
-
정합성 : 중복된 데이터는 일치하지 않을 수 있다.
-
쓰기 성능 저하 : 중복된 값을 일치시켜야 하므로
-
데이터 성격이 불명확 : 중복 속성 때문에 엔터티 성격이 명확하지 않다 -> 엔터티 간 관계도 모호해진다 -> 담당자 바뀌면 엔터티 오용될 가능성 커진다 -> 이해하기 어려운 모델은 사용할수록 결국 조잡한 모델이 된다.
-
모델 확장성 저하, 개발 어려움 : 어디를 수정해야 할지 정확히 모르기에 유지, 보수가 어렵다
-
공간차지
-
일부 조회 성능 저하 : 한 엔터티에 많은 중복 속성이 존재 -> 인스턴스의 길이가 늘어난다 -> 여러 블록에 존재한다 -> 조회 속도가 느려진다
