1. 탐욕 알고리즘을 사용하기 위해 성립해야하는 조건
탐욕 알고리즘이란?
탐욕 알고리즘은 동적 프로그래밍 사용 시 지나치게 많은 일을 한다는 것에서 착안하여 고안된 알고리즘이다. 동적 프로그래밍을 대체하는 것은 아니고 같이 쓰이며 서로 보완하는 개념이다.
선택의 순간마다 당장 눈앞에 보이는 최적의 상황만을 쫓아 최종적인 해답에 도달
순간마다 하는 선택은 그 순간에 대해 지역적으로는 최적이지만, 그 선택들을 계속 수집하여 최종적(전역적)인 해답을 만들었다고해서, 그것이 최적이라는 보장은 없다.
탐욕 알고리즘을 적용할 수 있는 문제들은 지역적으로 최적이면서 전역적으로 최적인 문제들이다.
탐욕 알고리즘 문제를 해결하는 방법
- 선택 절차 : 현재 상태에서 최적의 해답을 선택한다.
- 적절성 검사 : 선택된 해가 문제의 조건을 만족하는지 검사한다.
- 해답 검사 : 원래의 문제가 해결되었는지 검사하고, 해결되지 않았다면 선택 절차로 돌아가 위의 과정을 반복한다.
탐욕 알고리즘 적용하려면 문제가 2가지 조건을 성립
- 탐욕 알고리즘이 잘 작동하는 문제는 대부분 탐욕스런 선택 조건과 최적 부분 구조 조건이라는 두 가지 조건이 만족된다.
- 탐욕스런 선택 조건은 앞의 선택이 이후의 선택에 영향을 주지 않는다는 것이며, 최적 부분 구조 조건은 문제에 대한 최적해가 부분문제에 대해서도 역시 최적해라는 것이다.
- 탐욕적 선택 속성 : 앞의 선택이 이후의 선택에 영향을 주지 않는다.
- 최적 부분 구조 : 문제에 대한 최종 해결 방법은 부분 문제에 대한 최적 문제 해결 방법으로 구성된다.
이러한 조건이 성립하지 않는 경우에는 탐욕 알고리즘은 최적해를 구하지 못한다.
하지만 이러한 경우에도 탐욕 알고리즘은 근사 알고리즘으로 사용이 가능할 수 있으며, 대부분의 경우 계산 속도가 빠르기 때문에 실용적으로 사용할 수 있다.
매트로이드가 있는 문제에 대해서는 탐욕 알고리즘이 언제나 최적해를 찾아낼 수 있다.
근사 알고리즘이란?
어떤 최적화 문제에 대한 해의 근사값을 구하는 알고리즘
이 알고리즘은 가장 최적화되는 답을 구할 수는 없지만, 비교적 빠른 시간에 계산이 가능하며 어느 정도 보장된 근사해를 계산할 수 있다.
ex> 거스름돈
2. IoC에 대해 & 3. DI에 대해
IoC란?
제어의 역전, Inversion of Control
스프링 애플리케이션에서는 오브젝트(빈)의 생성과 의존 관계 설정, 사용, 제거 등의 작업을 애플리케이션 코드 대신 스프링 컨테이너가 담당한다.
이를 스프링 컨테이너가 코드 대신 오ㅡ젝트에 대한 제어권을 갖고 있다고 해서 IoC라고 부른다.
따라서, 스프링 컨테이너를 IoC 컨테이너라고도 부른다.
DI란?
의존관계를 외부에서 결정하고 주입하는 것
- 클래스 모델이나 코드에는 런타임 시점의 의존관계가 드러나지 않는다. 그러기 위해서는 인터페이스만 의존하고 있어야 한다.
- 런타임 시점의 의존관계는 컨테이너나 팩토리 같은 제 3의 존재가 결정한다.
- 의존관계는 사용할 오브젝트에 대한 레퍼런스를 외부에서 제공(주입)해줌으로써 만들어진다.
DI 구현 방법
- 생성자를 이용
- 메소드를 이용(대표적으로 Setter)
- 어노테이션을 이용(@Autowird)
지향하는 방법은 생성자를 이용하는 방법이다.
장점
- 의존성이 줄어든다.
- 재사용성이 높은 코드가 된다.
- 테스트하기 좋은 코드가 된다.
- 가독성이 높아진다.
4. 스프링 컨테이너
스프링에서 자바 객체들을 관리하는 공간을 말한다. 자바 객체의 생성 주기를 관리한다.
컨테이너는 크게 두 종류로 나뉜다.
1. BeanFactory
2. ApplicationContext
ApplicationContext 컨테이너가 Beanfactory의 기능을 포괄하면서 추가적인 기능을 제공하기 때문에 대부분의 경우에는 ApplicationContext를 사용한다.
그럼 어떤 기능을 추가했을까?
- 메시지 소스를 활용한 국제화 기능
- 한국에서 들어오면 한국어로, 영어권에서 들어오면 영어로 출력
- 환경 변수
- 로컬, 개발, 운영 등을 구분해서 처리
- 애플리케이션 이벤트
- 이벤트를 발행하고 구독하는 모델을 편리하게 지원
- 편리한 리소스 조회
- 파일, 클래스 패스, 외부 등에서 리소스를 편리하게 조회
스프링 컨테이너의 가장 기초적인 역할, 오브젝트를 생성하고 이를 관리하는 것이다.
스프링 컨테이너는 자바코드, XML, Groovy등 다양한 형식의 설정 정보를 받아들일 수 있도록 유연하게 설계되어 있다.
5. 스프링에서 AOP
어떤 로직을 기준으로 핵심적인 관점, 부가적인 관점으로 나누어서 보고 그 관점을 기준으로 각각 모듈화하겠다는 것이다.
모듈화 : 어떤 공통된 로직이나 기능을 하나의 단위로 묶는 것
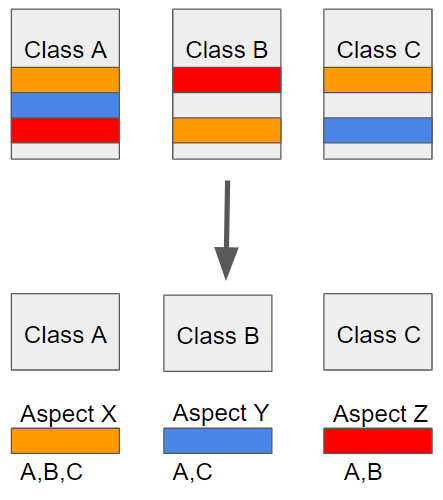
흩어진 관심사를 Aspect로 모듈화하고 핵심적인 비즈니스 로직에서 분리하여 재사용하겠다는것이 AOP의 취지다.
AOP 적용 방법
- 컴파일 타임 적용
- 로드 타임 적용
- 런타임 적용
스프링 AOP가 주로 사용하는 방법은 런타임 적용이다.
A라는 클래스 타입의 Bean을 만들 때 A 타입의 Proxy Bean을 만들어 Proxy Bean이 Aspect 코드를 추가하여 동작하는 방법.
스프링 AOP
- 스프링에서 제공하는 스프링 AOP는 프록시 기반의 AOP 구현체이다.
- 프록시 객체를 사용하는 것은 접근 제어 및 부가 기능을 추가하기 위해서이다.
- 스프링 AOP는 스프링 Bean에만 적용할 수 있다.
- 모든 AOP 기능을 제공하는 것이 목적이 아닌, 중복 코드, 프록시 클래스 작성의 번거로움 등 흔한 문제를 해결하기 위한 솔루션을 제공하는 것이 목적이다.
- 스프링 AOP는 순수 자바로 구현되었기 때문에 특별한 컴파일 과정이 필요하지 않다.
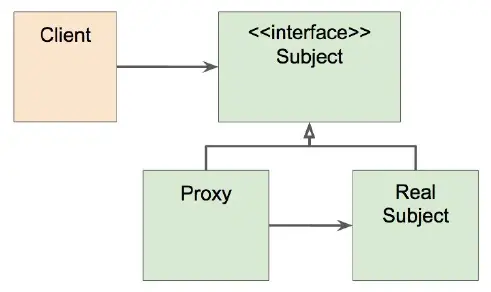
프록시 패턴에서는 interface가 존재하고 Client는 이 interface 타입으로 Proxy 객체를 사용한다. Proxy 객체는 기존의 타겟 객체(Real Subject)를 참조한다. Proxy 객체와 기존의 타겟 객체의 타입은 같고, Proxy는 원래 할 일을 가지고 있는 Real Subject를 감싸서 Client의 요청을 처리한다.
참조:
https://hanamon.kr/%ec%95%8c%ea%b3%a0%eb%a6%ac%ec%a6%98-%ed%83%90%ec%9a%95%ec%95%8c%ea%b3%a0%eb%a6%ac%ec%a6%98-greedy-algorithm/, https://steady-coding.tistory.com/600, https://tecoble.techcourse.co.kr/post/2021-04-27-dependency-injection/, https://velog.io/@tank3a/%EC%8A%A4%ED%94%84%EB%A7%81-%EC%BB%A8%ED%85%8C%EC%9D%B4%EB%84%88%EC%99%80-%EC%8A%A4%ED%94%84%EB%A7%81-%EB%B9%88, https://code-lab1.tistory.com/193

화이팅 김준영~~