pandas로 my_data.csv를 수정하여 저장하기
<요구사항>
-Unnamed:0라고 표기되는 열을 지운다. 단 Unnamed:0라 쓰지말고 새롭게 컬럼 이름을 만들어서 지운다.
-0,1,2,3,4로 보여지는 index 부분을 지운다.
-name에 해당되는 영문 이름을 한글로 바꾼다.
-salary에 해당되는 숫자를 000 세자리 단위로 콤마를 넣어서 값을 바꿔 넣는다.
-1~4를 처리하고 나서 csv파일로 저장한다./
my_data.csv/
,name,age,salary
0,Alice,25,50000
1,Bob,30,60000
2,Charlie,35,70000
3,james,30,400000
4,Alice,25,50000
5,Bob,30,60000
6,Charlie,35,70000
7,james,30,400000
1) pandas 패키지 불러오기
import pandas as pd
import pandas as pd 2) .csv 파일을 데이터 프레임으로 불러오기
data = pd.read_csv("my_data.csv", sep=",")
data = pd.read_csv("my_data.csv", sep=",") 3) Unnamed:0을 대체할 새롭게 컬럼 이름을 만들어서 지운다.
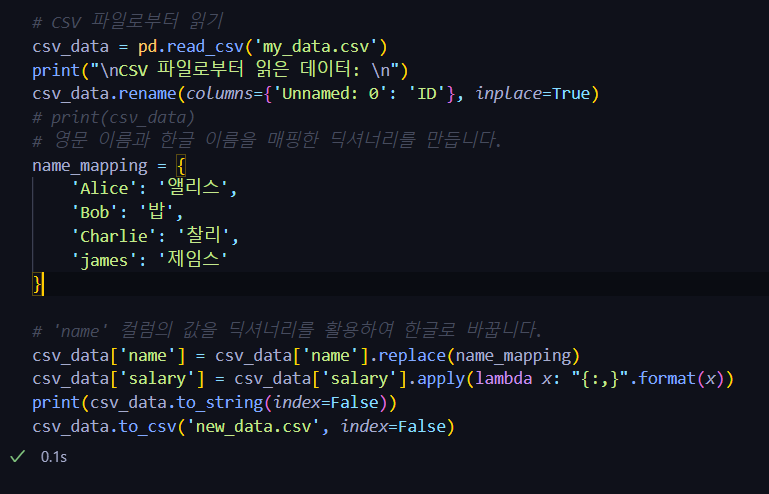
# 'Unnamed: 0' 컬럼을 'ID'로 이름을 변경합니다.
csv_data.rename(columns={'Unnamed: 0': 'ID'}, inplace=True)
# 'Unnamed: 0' 컬럼을 'ID'로 이름을 변경합니다.
csv_data.rename(columns={'Unnamed: 0': 'ID'}, inplace=True)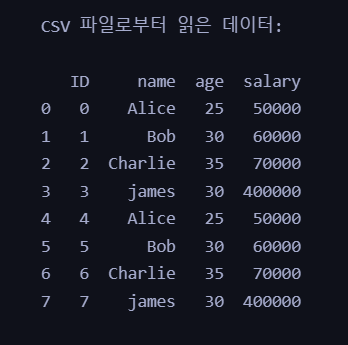
4) 0,1,2,3,4로 보여지는 index 부분을 지운다.
print(csv_data.to_string(index=False))
print(csv_data.to_string(index=False))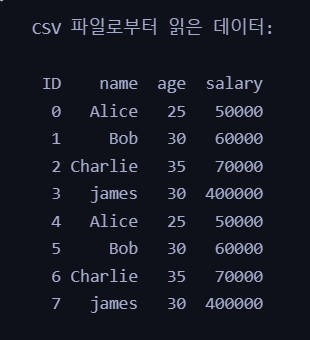
5) name에 해당되는 영문 이름을 한글로 바꾼다.
>>딕셔너리나 매핑을 활용하여 영문 이름과 한글 이름을 매칭해야 합니다. 이후에 replace() 메서드를 사용하여 데이터프레임의 특정 컬럼 값을 매핑된 값으로 변경할 수 있습니다.
# 영문 이름과 한글 이름을 매핑한 딕셔너리를 만듭니다.
name_mapping = {
'Alice': '앨리스',
'Bob': '밥',
'Charlie': '찰리',
'james': '제임스'
}
# 'name' 컬럼의 값을 딕셔너리를 활용하여 한글로 바꿉니다.
csv_data['name'] = csv_data['name'].replace(name_mapping)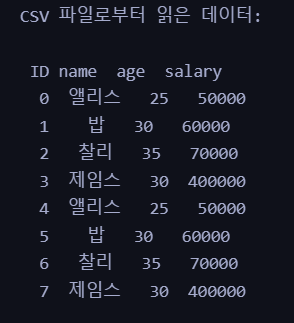
6) salary에 해당되는 숫자를 000 세자리 단위로 콤마를 넣어서 값을 바꿔 넣는다.
# 'salary' 컬럼의 값을 세 자리 단위로 콤마를 넣어서 변경합니다.
csv_data['salary'] = csv_data['salary'].apply(lambda x: "{:,}".format(x))
# 'salary' 컬럼의 값을 세 자리 단위로 콤마를 넣어서 변경합니다.
csv_data['salary'] = csv_data['salary'].apply(lambda x: "{:,}".format(x))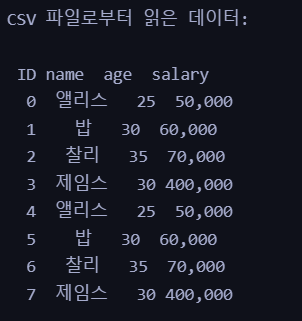
# 변경된 데이터프레임을 CSV 파일로 저장합니다. 파일명은 'new_data.csv'로 설정합니다.
csv_data.to_csv('new_data.csv', index=False)💻 전체코드
*본 후기는 정보통신산업진흥원(NIPA)에서 주관하는 과제 기록으로 작성 되었습니다.
