
Middleware'21 논문
저자 : Giorgos Kappes, Stergios V. Anastasiadis
Abstract
컨테이너는 영구적인 스토리지를 통해 stateful 워크로드를 실행하는 데 일반적으로 사용되는
가상화 기술이다. 활용률이 높은 multi-tenent 호스트에서는 시스템 커널에서 리소스 경합으로 인해
종종 컨테이너 I/O 를 비효율적으로 처리한다. 확장성을 위해 분산 스토리지 아키텍처를 가정할 경우
리소스 공유는 경쟁 테넌트의 어플리케이션을 지원하는 클라이언트 호스트에서 특히 문제가 된다.
시스템 커널의 확장성을 높이면 리소스 효율성이 향상될 수 있지만
시스템 서비스에 대한 공정한 접근을 위해 커널을 리팩토링하는 것은 매우 어렵다.
현실적인 대안으로 user-level 에서 실행되는 개별 클라이언트와 함께 서비스를 제공하여
서로 다른 테넌트의 스토리지 IO 경로를 격리 한다.
각 테넌트가 개인 호스트 경로를 통해 컨테이너 루트 및 어플리케이션 파일 시스템에 접근
할 수 있도록 Danaus 클라이언트 아키텍처를 도입한다.
우리는 Union 파일 시스템을 Ceph 분산 파일 시스템 클라이언트 및
구성 가능한 공유 캐시와 통합하는 Danaus 프로토타입을 개발했다.
Ceph : 오픈소스 SDS (Software Defined Storage) 프레임워크
다양한 호스트 구성, 워크로드 및 시스템에서 Danaus 는 예약된 테넌트별 리소스로
I/O 를 처리하고 커널 locking 이 많이 발생하지 않기 때문에 성능 안정성을 향상시킨다.
Danaus 는 널리 사용되는 커널 기반 클라이언트보다 I/O 경합 조건에서
최대 14.4 배 더 높은 처리량을 제공한다.
FUSE 기반 user-level 클라이언트에 비해 Danaus 는
256개의 고성능 웹 서버를 시작하는 시간도 14.2배 단축했다.
Danaus 를 구축하고 평가한 광범위한 경험을 바탕으로
리소스 경합, 파일 관리, 서비스 분리 및 성능 안정성에 대해 배운 몇 가지 귀중한 교훈을 공유한다.
CCS Concepts
- 소프트웨어 및 해당 엔지니어링 → 커뮤니케이션 프로세스 협력
- 정보 시스템 → 스토리지 가상화, 분산 스토리지
- 컴퓨팅 방법론 → 분산 컴퓨팅 방법론
- 일반 및 참조 → 성능
1. Instruction
컨테이너는 낮은 오버헤드로 유연한 가상화를 제공하기 때문에 클라우드 환경에서 인기가 있다.
이러한 이점은 운영체제의 기본 리소스 관리에서 비롯되지만 컨테이너 실행의 향상된 격리를 위해서는
종종 하드웨어 레벨 가상화 또는 룰 기반 제어가 필요하다.
특히 시스템 커널을 통한 컨테이너 이미지 및 데이터의 영구 저장은
몇 가지 격리 및 효율성 문제를 야기한다.
그 예로는 최적이 아닌 성능, 보안 및 장애 방지, 처리,
메모리 및 스토리지 리소스의 과도한 사용 이 있다.
컨테이너는 요청 라우팅 (예: VFS), 페이지 캐시, 파일, 장치 스케줄링의 중요한 I/O 작업을 위한
공통 커널 경로를 공유하기 때문에 경쟁 워크로드 (예: noisy neighbor) 의 I/O 성능을 분리할 수 없다.
또한, 공유 운영체제의 잠재적 취약성으로 인해,
colocated 컨테이너의 보안 격리 및 장애 억제가 제한된다.
표준 인터페이스 (예: POSIX) 와의 역호환성을 위해 기존 파일 시스템은 일반적으로
커널 내부에서 부분적으로, 또는 완전히 실행된다.
결과적으로 다음과 같은 여러 가지 이유로 비효율성을 경험한다.
- 메모리 복사 작업으로 인한 프로세서 캐시 pollution
- mode 및 컨텍스트 스위치에서 발생하는 직접 및 간접 비용 (예: TLB flushes)
- 커널 내부 및 외부의 이중 캐싱 (예: FUSE)
- 공유 커널 자원 (예: 페이지 캐시) 의 부정확한 계산
동일한 호스트에서 실행되는 복제된 컨테이너에서는 추가적인 비효율성이 발생한다.
실제로 이러한 동시 실행은 사용된 메모리 및 스토리지 공간,
즉 메모리 및 I/O 대역폭에 중복이 발생 한다.
멀티 레이어 Union 파일 시스템과 블록 기반 Copy-on-Write 스냅샷은
스토리지 공간의 낭비를 줄여준다.
그러나 호스트에서 메모리 공간 및 메모리 또는 I/O 대역폭의 복제를 항상 방지하는 것은 아니다.
따라서 리소스 경합과 시스템 커널의 유연하지 않은 공유는
컨테이너 I/O 분리를 줄이고 리소스 중복을 증가시킨다.
현재 시스템은 user-level 에서의 실행을 위해 리소스를 명시적으로 예약하지만
커널 리소스의 할당 및 공정한 액세스에 모호하다.
바람직하지 않은 가변성 결과를 고려할 때,
효과적인 컨테이너 격리는 두 가지 유형의 시스템 지원을 필요로 한다고 주장한다.
- user 와 커널 레벨 모두에서 활용되는 하드웨어 자원의 명시적 할당
- 커널 운영과 data structure 에 대한 공정한 접근
이다.
라이브러리 운영체제 (libOS) 는 커널에서 user-level 로 기능을 이동시키기 때문에
커널 자원 관리로부터의 분리 의존성을 감소 시킨다.
그러나, 단일 프로세스에 대한 libOS 의 일반적인 링크는
일반적인 어플리케이션의 다중 처리 상태 공유를 복잡하게 한다.
마찬가지로 파일 시스템은 커널을 통해 액세스 되지만
user-level 에서 실행될 때 유연한 리소스 관리를 제공한다.
그러나 추가 데이터 복사 및 모드 또는 컨텍스트 전환 (예: FUSE) 으로 인해
성능과 효율성이 저하된다.
컨테이너 격리 및 리소스 효율성은 시스템 커널의 상태 관리에서
향상된 확장성을 통해 해결할 수 있다.
그럼에도 불구하고 확장성을 위해 커널을 리팩토링하는 것은 오랫동안 어려운 문제였다.
실용적인 대안으로, 우리는 시스템 기능과 프로세스 간 커뮤니케이션 모두를
user-level 로 재배치한다.
따라서 각 프로세스 그룹이 예약된 하드웨어 리소스를 고수하고
user-level 에서 자체 시스템 서비스를 실행할 수 있다.
우리의 접근 방식은 다양한 유형의 데이터 스토리지에 대한 로컬 및 원격 액세스 또는
네트워크 통신을 포함한 광범위한 시스템 구성요소에 도움이 될 수 있다.
네트워크 스토리지 클라이언트는 확장 가능한 스토리지 시스템이 클라우드 인프라를 지원하는 데
사용하는 end-to-end 경로의 중요한 구성 요소이다.
결과적으로, 우리의 현재 초점은 함께 배치된 여러 테넌트의 컨테이너에서
I/O 격리 및 효율성을 제공하는 네트워크 스토리지 클라이언트를 설계하는 것이다.
우리는 네트워크 자체 또는 스토리지 서버의 다중 테넌트 격리에 대해 설명하지 않는다.
현재 작업의 범위를 넘어서는 자체적인 문제를 소개하기 때문이다.
Danaus 의 핵심 아이디어는 호스트에서 테넌트당 고유한 user-level 파일 시스템 클라이언트를
프로비저닝하는 것이다.
우리는 libservices 의 추상화에 기초한 user-level 기능의 개인 스택으로부터
각 클라이언트를 구성한다.
클라이언트는 테넌트의 예약된 리소스에서 자체 코드 경로와 데이터 캐시를 비공개로 실행한다.
클라이언트 스레드를 예약된 코어에 고정하고 user-level 에서 실행하여
모드 및 컨텍스트 스위치를 줄인다.
또한 복제되거나 협업하는 컨테이너는 구성 가능한 파일 시스템 공유를 활용하여
메모리 및 스토리지 리소스의 중복을 방지한다.
Union 파일 시스템과 분산 파일 시스템 클라이언트를 실행하는 두 개의 libservices 에서
Danaus 프로토타입을 구축했다.
우리는 mature 커널 기반 클라이언트 및 Union 파일 시스템이,
예약된 자원을 초과하는 리소스를 사용하여 커널 내부의 lock 경합 및
I/O 처리로 인해 성능이 저하된다는 것을 실험적으로 입증한다.
이와 대조적으로 Danaus 는 특히 쓰기 집약적인 워크로드나 scaleout 워크로드에서
낮은 메모리 및 CPU 활용률과 함께 더 높은 성능을 보여준다.
Danaus 는 캐시된 읽기 속도가 느리지만
user-level 분산 파일 시스템 클라이언트의 동시성 최적화를 통해
성능 향상을 위한 잠재적 솔루션을 확인했다.
우리의 기여는 다음과 같다.
-
I/O 격리 및 효율성의 중요한 문제에 대한 동기를 제공한다.
커널이 제공하는 I/O 작업에서 발생하는 소프트웨어 및 하드웨어 경합 을 보여준다.
-
멀티테넌트 컨테이너 스토리지의 통합 클라이언트 아키텍처에 대한 설계 목표와 원칙 을 설정한다.
-
시스템 인터페이스, 클라이언트 아키텍처에 대한 설계 결정을 정당화한다.
-
공간 및 대역폭 효율성을 위해 구성 가능한 캐시와 결합 및 클라이언트 libservices 를 통합 하는
Danaus 프로토타입 구성요소를 설명한다.
-
Danaus 목표의 실현을 분석하고 정당화한다.
-
production 어플리케이션 및 microbenchmark 를 사용, 대표적인 시스템과 비교하여
Danaus 의 향상된 격리, 고성능 및 낮은 자원 소비를 실험적으로 정량화한다.
-
Danaus 의 설계, 구현 및 평가에 대한 경험에서 얻은 통찰력 있는 교훈을 제시한다.
다음으로 실험 동기 및 연구 배경 제공, Danaus 의 설계 및 구현 설명,
정성적 분석 수행 및 비교 성능 평가, 관련 개요 및 차별화 작업, 제한사항 논의가 있다.
2. Motivation and Background
이 섹션에서는 커널 I/O 경합에 대한 어플리케이션 성능 민감도를 실험적으로 시연하고
기존 컨테이너 스토리지 옵션을 간략히 설명한다.
2.1 Sensitivity to kernel I/O contention
동일한 호스트에 배치된 여러 데이터 집약적 워크로드의 성능 변동을 조사한다.
CephFS 커널 기반 클라이언트를 통해 액세스 하는, 스토리지 클러스터를 통해
Filebench 의 Fileserver (FLS) 를 실행한다.
또는 Stress-ng RandomIO (RND) 벤치마크를 사용하여 직접 연결 장치에서
로컬 커널 기반 파일 시스템을 통해 임의의 I/O 를 생성한다.
각 워크로드 인스턴스는 2개의 코어와 8GB RAM 의 고유한 예약 (컨테이너 풀) 에서 실행된다.
호스트의 4개 또는 16개 코어를 활성화하여 각각 1개 또는 7개의 FLS (1FLS, 7FLS) 인스턴스를
단독으로, 또는 1개의 RND 옆에서 실행된다.
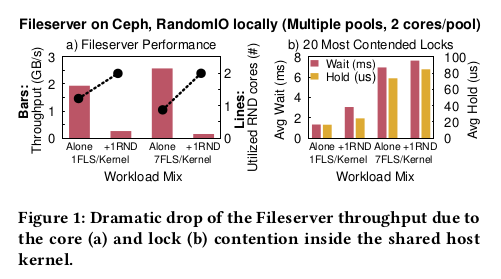
그림 1a 의 막대 도표에서, 우리는 FLS 가 RND 와 같은 위치에 있을 때
극적인 성능 저하를 관찰할 수 있다.
FLS 처리량은 1FLS 에서 1FLS + 1RND 로 7.4배, 7FLS 에서 7FLS + 1RND 로 16.5배 감소한다.
우리는 이 행동을 두 가지 이유에 기인한다.
-
시스템 커널은 전체 호스트의 활성화된 코어를 활용하여 durty page 를 flush 한다.
그림 1a 의 꺾은선형 차트는 RND 의 코어가 단독으로 실행될 때
1FLS 에 의해 122%, 7FLS 에 의해 87% 사용함을 확인한다.
RND 도 실행 중이면 커널이 FLS 를 제공하기 위해 더 이상 RND 의 코어를 “훔칠” 수 없기 때문에
FLS 처리량이 급감한다.
-
커널 내부의 lock 활동이다. 그림 1b 에서는 lock 요청 당 커널이 소비하는
평균 대기 시간을 보여준다.
1FLS 의 lock 대기 시간이 1FLS + 1RND 에서 2.3 배, 7FLS 에서 5.2배 증가하는 것을 볼 수 있다.
따라서 1개의 RND 또는 6개의 추가 FLS 인스턴스가 있는 1FLS 의 공동 배치는
여러 요인에 의해 lock 오버헤드를 증가시킨다.
우리의 결론은 함께 배치된 워크로드는 I/O 활동과 성능을 분리하기 위해 자체 재사용 가능
(하드웨어) 및 소모성 (소프트웨어) 리소스를 사용해야 한다는 것이다.
2.2 Containers and existing storage options
컨테이너는 프로세스 그룹을 격리하기 위해 호스트의 운영체제에서 제공하는
가벼운 가상화 추상화이다.
일반적으로 user 공간 런타임과 리소스 할당 (예: CPU, 메모리, 네트워크 블록 I/O) 및
분리 (예: 프로세스 ID, user ID, 마운트 지점, 네트워크, IPC) 를 위한
커널 제어 메커니즘에 의해 지원된다.
이미지는 일련의 파일 아카이브 (레이어) 로 구성된 어플리케이션 바이너리 및
시스템 패키지의 읽기 전용 set 이다.
독립된 머신에서 실행되는 레지스트리에서 사용할 수 있다.
일반적으로 새 컨테이너는 호스트의 로컬 스토리지에 생성된다.
루트 파일 시스템은 이미지를 복사하여 개인 디렉토리 아래의 파일 트리로 확장함으로써 준비된다.
컨테이너 실행에 의한 파일 수정이 가능하도록 확장된 이미지 위에 쓰기 가능한 레이어가 추가된다.
컨테이너 런타임의 스토리지 드라이버를 사용하면 Union 파일 시스템 또는 스냅샷 스토리지를 통해
서로 다른 컨테이너 간에 이미지 레이어를 공유할 수 있다.
Union 파일 시스템은 파일 레벨에서 copy-on-write 를 지원하는 여러 스택 디렉토리(브랜치)의
단일 논리 뷰를 제공한다.
상위 브랜치는 쓰기 가능하고 나머지 브랜치는 읽기 전용 및 공유 가능하다.
위에서 파일 조회는 파일 또는 파일을 삭제한 것으로 표시하는 whiteout 항목이 포함된
첫 번째 브랜치에서 중지된다.
브랜치는 확장성을 위해 로컬 파일 시스템 또는 분산 파일 시스템에 저장된다.
Snapshot 스토리지는 블록 레벨 Copy-on-Write 를 제공한다.
이는 로컬 파일 시스템, 로컬 블록 장치 관리자 또는
네트워크 연결 스토리지의 원격 블록 볼륨에 의해 구현된다.
어플리케이션 데이터 저장을 위해 컨테이너는 호스트 (예: bind mount) 또는
네트워크 (예: 볼륨 플러그인) 에서 추가 파일 시스템을 마운트할 수 있다.
호스트는 로컬 또는 분산 파일 시스템에 대한 지속성을 제공한다.
또는 볼륨 플러그인은 로컬 파일 시스템 (예: MS Azure, Amazon EFS, EBS) 으로 포맷된
블록 볼륨 또는 파일 시스템 중 하나로 네트워크 스토리지에서 마운트할 수 있다.
볼륨 플러그인은 커널 (예: NFS 커널 모듈) 의 필수 지원으로 컨테이너 런타임에 의해 실행된다.
마지막으로 컨테이너 어플리케이션은 RESTful API 를 통해
클라우드 객체 스토리지 (예: Amazon S3) 에 액세스할 수 있다.
분산 파일 시스템은 호스트에서 실행 중인 클라이언트를 통해 영구적인 스토리지를 제공한다.
클라이언트 메모리는 파일 데이터 캐시, inode 캐시, 디렉토리 entry 캐시를 관리한다.
durty 페이지는 durty 페이지의 양 또는 수명 또는 캐싱된 개체 수를 제한하는 임계값을 초과할 경우
네트워크 스토리지로 flush 된다.
어플리케이션은 I/O 를 직접 (예: open) 또는 간접 (예: exec) 적으로 포함하는
시스템 호출을 사용하여 파일 시스템에 액세스한다.
I/O 요청은 커널 내부에서 제공되거나 커널에서 user-level 프로세스 (예: FUSE) 로 리다이렉션된다.
또 다른 옵션은 어플리케이션을 라이브러리에 연결하고 어플리케이션의 일부로
또는 IPC 를 통해 다른 프로세스에서 user-level 에서 I/O 기능을 구현하는 것이다.
3. Design
아래에 우리는 Danaus 의 중요한 부분을 설명하고 대안에 대한 우리의 선택을 정당화한다.
우리의 발표는 목표와 원칙, 기본 구조, 인터페이스, 캐시, 일관성 및 프로세스 간 통신을 포함한다.
3.1 System structure
시스템 설계에서 다음 목표를 설정했다.
-
호환성 : 이전 버전과 호환되는 POSIX 와 유사한 인터페이스 (예: open, fork, exec) 를 통해
확장 가능한 영구 저장소에 대한 기본 컨테이너 액세스를 제공한다.
-
격리 : 동일한 클라이언트 시스템에 함께 배치된 데이터 집약적인 테넌트의 성능 격리 및
장애 억제를 개선한다.
-
효율성 : 프로세서, 메모리 및 스토리지 리소스의 효과적인 활용을 통해
루트 및 어플리케이션 파일 시스템을 제공한다.
-
유연성 : 공유 및 캐싱 정책 (예: files, consistency) 의 유연한 테넌트 구성을 가능하게 한다.
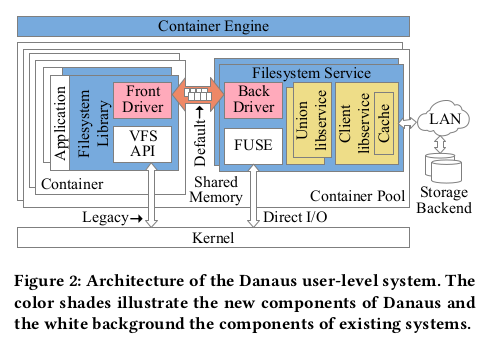
컨테이너 풀은 호스트에 있는 테넌트의 어플리케이션 및 서비스 컨테이너로 구성된다. (그림 2)
클라우드 provider 가 배포한 호스트별 컨테이너 엔진으로 함께 배치된 컨테이너 풀을 관리한다.
컨테이너 루트와 어플리케이션 파일 시스템을 공유 분산 파일 시스템에 직접 저장한다.
우리는 다음 두 가지 이유로 파일 기반 네트워크 스토리지에 중점을 둔다.
- 호스트 간에 유연한 데이터 공유 가 가능하다.
- 블록 기반 스토리지의 multi-layer 가상화 오버헤드를 방지 한다.
스토리지 백엔드는 분산 파일 시스템의 데이터와 메타데이터를 저장하는 서버 노드로 구성된다.
우리의 아키텍처는 블록 기반 네트워크 스토리지의 클라이언트도 지원할 수 있지만
그 방향에 대한 탐구는 향후 연구로 남겨둔다.
Danaus 아키텍처는 테넌트의 컨테이너 풀을 지원하는 파일 시스템 기능 모음을 통합한다.
백엔드 클라이언트는 컨테이너가 스토리지 백엔드에 액세스하는 데 사용하는
분산 파일 시스템 클라이언트이다.
Union 파일 시스템은 컨테이너 clone 또는 데이터set 복제본 전반에 걸쳐
I/O 중복 제거 기능 을 제공한다.
캐시는 configurable sharing 과 consistency semantic 을 통해 루트 및 어플리케이션 파일 시스템에
caching 기능을 제공한다.
Danaus 아키텍쳐는 각 어플리케이션에 연결된 파일 시스템 라이브러리,
스토리지 I/O 를 처리하는 파일 시스템 서비스 및 어플리케이션과 서비스를 연결하는
프로세스 간 통신 으로 구성된다. (그림 2)
파일 시스템 라이브러리의 프론트 드라이버는 user-level 에서 수신 요청을
공유 메모리를 통해 파일 시스템 서비스의 백 드라이버로 전달한다.
파일 시스템 서비스는 컨테이너에 마운트된 파일 시스템 인스턴스를 실행하는
독립형 user-level 프로세스이다.
파일 시스템 인스턴스는 libservices 스택으로 구현된다.
libservices 는 POSIX 와 같은 인터페이스를 통해 액세스하는 user-level 의 스토리지 서브시스템이다.
우리의 프로토타입 구현은 현재 Union 파일 시스템의 Union libservice 와
백엔드 클라이언트의 클라이언트 libservice 를 지원한다.
Union libservice 는 클라이언트 libservice 를 직접 호출하여
추가적인 컨텍스트 스위칭이나 데이터 복사 없이 분기 요청을 처리한다.
우리의 목표를 달성하기 위해, 우리의 설계는 다음의 네 가지 원칙을 기반으로 한다.
-
이중 인터페이스 : 파일 시스템 라이브러리를 통해 공통 어플리케이션 I/O 호출을 지원하고
암시적 I/O 가 있는 레거시 소프트웨어나 시스템 호출에만 커널을 사용한다.
-
파일시스템 통합 : 파일 시스템 인스턴스의 libservice 는 속도와 효율성을 위한 함수 호출을 통해
서로 직접 상호작용한다.
-
user-level 실행 : 파일 시스템 서비스와 기본 통신 경로는 모두 격리,
유연성 및 커널 오버헤드 감소를 위해 user-level 에서 실행된다.
-
경로 격리 : 파일 시스템 서비스는 동일하거나 다른 테넌트의 colocation 풀 간의 간섭을 줄이고
유연성을 향상시키기 위해 클라이언트 측에서 컨테이너 풀의 스토리지 I/O 를 격리한다.
아래에서 우리는 디자인의 중요한 부분을 설명하고 고려된 대안과 관련하여
우리의 선택을 정당화한다.
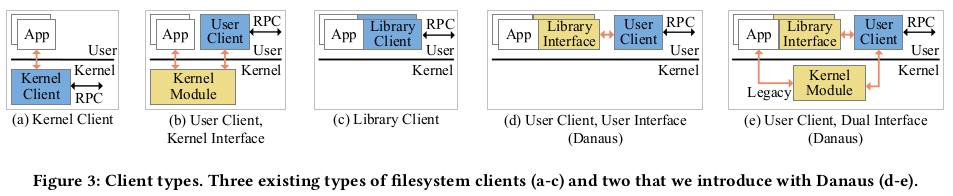
3.2 Interface
백엔드 클라이언트의 인터페이스는 다음 5가지 옵션을 고려하여 지정한 중요한 부분이다.
-
Full Kernel : 성능을 위해 커널(예: Ceph, NFS) 내부에서 클라이언트를 실행하고
호환성(그림 3a)을 위해 커널(예: VFS)을 통해 액세스한다.
-
User Execution : 간편한 프로토타이핑을 위해 user-level 에서 클라이언트를 실행하고 (예: FUSE)
커널을 통해 액세스한다. (그림 3b)
-
Linked Library : 멀티프로세스 캐시 공유의 추가적인 복잡성을 감수하고 효율성 향상을 위해
라이브러리 클라이언트를 각 어플리케이션 (예: Ceph, Gluster, NFS, Hare) 에
직접 연결한다. (그림 3c)
-
Full User : 클라이언트를 user-level 에서 독립 실행형 프로세스로 실행하고
어플리케이션 라이브러리를 통해 공유 메모리를 통해 액세스할 수 있도록 한다. (그림 3d)
이 접근 방식은 테넌트 내 캐시 공유와 격리 및 효율성을 결합한다.
-
Dual Interface : 레거시 어플리케이션의 하위 호환성을 개선하기 위해
커널을 통과하는 두 번째 선택적 인터페이스 (그림 3e) 로
전체 user 인터페이스를 보완한다.
Danaus 는 듀얼 인터페이스를 지원한다. 기본 경로는 user-level 을 통해
어플리케이션과 파일 시스템 서비스를 연결한다.
어플리케이션은 파일 시스템 라이브러리를 사전 로드하여 libc 의 I/O 기능을 재정의한다.
소스 코드를 다시 컴파일 할 수 있는 경우 어플리케이션은 danaus_ 가 앞에 붙은
Danaus 파일 I/O 함수를 직접 호출한다.
어플리케이션과 파일 시스템 서비스 간의 공유 메모리는
컨테이너 풀의 개인 IPC 네임스페이스에서 분리된다.
커널 I/O 경로를 가로지르는 mmap POSIX 인터페이스 (예: VFS 를 통해 shm_open) 대신
system V IPC 인터페이스를 적용하여 공유 메모리를 관리한다.
사전 로드가 있는 동적 링커는 정적 링크 기호를 재정의할 수 없다.
따라서 어플리케이션 바이너리가 커널 시작 I/O (예: exec) 와 함께
정적으로 연결된 기호나 시스템 호출을 포함하는 경우 Danaus 는 I/O 요청이
VFS 를 통해 커널에 자동으로 입력되도록 허용한다.
이후에 요청이 파일 시스템 서비스에 다시 user-level 로 도착한다.
우리는 전용 FUSE 스레드를 통해 이러한 요청을 처리하기 위해 FUSE 의 고급 API 를 사용한다.
(그림 2)
3.3 Client cache
클라이언트 캐시를 파일 시스템 라이브러리 또는 파일 시스템 서비스에 배치해야 하는
딜레마에 직면했다.
라이브러리 측에서 캐시를 관리하면 테넌트의 컨테이너 프로세스 전반에 걸친
캐시 공유 조정 작업이 복잡해진다. 이러한 복잡성은 테넌트의 스레드가 캐시에 직접 액세스하고
서로 동기화하여 캐시 구조를 일관되게 유지하기 때문에 발생한다.
반대로 파일 시스템 서비스는 자체 스레드를 사용하여
Union 파일 시스템 또는 백엔드 클라이언트 내에서 네이티브 공유 캐시를 실행할 수 있다.
세 번째 가능성은 캐시를 백엔드 클라이언트 위에 있는 별개의 libservice로 실행하는 것이다.
백엔드 클라이언트가 스토리지 백엔드와의 일관성을 유지하면서
자체 로컬 캐시를 이미 운영하고 있다.
따라서 user-level 에서 백엔드 클라이언트 내에서 클라이언트 캐시를 운영하고
백엔드 클라이언트 상단에서 캐시 없이 Union 중복제거를 실행하기로 결정했다 (그림 2).
Union 파일 시스템은 파일 수준의 함수 호출을 통해 백엔드 클라이언트와 상호 작용하기 때문에
별도의 파일 데이터 구조(예: inode)를 만들지 않는다.
백엔드 클라이언트는 경로 이름에서 공유 파일을 인식하고
각 공유 분기의 단일 복사본을 클라이언트 캐시에 보관한다.
3.4 Consistency
클라이언트 캐시는 어플리케이션에서 스토리지 백엔드로 이어지는
I/O 경로의 첫 번째 상태 저장 부분이다.
어플리케이션 write 가 반환되면 클라이언트 캐시 및 스토리지 백엔드에 도달한 것이 확실하다.
따라서 동일한 백엔드 클라이언트로의 후속 읽기에서 볼 수 있다.
파일 시스템 consistency 정책은 쓰기를 동일하거나 다른
호스트의 다른 백엔드 클라이언트로 전파한다.
동기 요청은 파일 시스템 서비스에 의해 스레드 프로그램 순서로 처리된다.
대신, 동시 또는 비동기 요청은 응용 프로그램 레벨 동기화를 통해
특정 순서 요구 사항을 충족할 수 있다.
클라이언트 충돌 시 캐시된 상태의 손실은 분산 파일 시스템의 consistency 정책에 따라 달라진다.
완료 알림이 표시되지 않거나 충돌 중에 요청이 손실되면 어플리케이션에서 요청을 반복해야 한다.
3.5 Interprocess communication
파일 시스템 라이브러리는 공유 메모리의 고정 크기 원형 큐를 사용하여
파일 시스템 서비스와 통신한다.
각 큐는 각각 앞 드라이버와 뒷 드라이버의 여러 생산자와 소비자 스레드에 의해 동시에 액세스된다.
프로세서 하드웨어는 일반적으로 코어를 동일한 수준의 캐시(예: L2를 통한 페어)로
그룹별로 정리한다.
따라서, 우리는 애플리케이션 컨테이너와 동일한 코어 그룹에서 실행되는 파일 시스템 서비스 간의
효율적인 통신을 촉진하기 위해 코어 그룹별로 별도의 요청 대기열을 유지한다.
각 대기열 항목은 요청 descriptor 와 항목이 현재 비어 있는지, 수정 중인지 또는
유효한 요청을 전달하는지 여부를 추적하는 상태 필드를 포함한다.
요청 descriptor 는 호출 식별자, 작은 인수 배열, 요청 버퍼에 대한 포인터를 포함한다.
각 어플리케이션 스레드에는 별도의 요청 버퍼가 있으며,
프론트 드라이버와 백 드라이버가 공유 메모리를 통해
대용량 데이터 항목을 교환하기 위해 사용한다.
어플리케이션의 각 새로운 스레드는 먼저 시스템 스케줄러가 선택한 코어에서 실행된다.
이후, 프론트 드라이버는 스레드에서 첫 번째 I/O 요청을 수신하는 요청 대기열의 코어에
스레드를 고정한다. 따라서 가능한 thread migrations 및 cache-line bouncing 을 최소화한다.
백 드라이버는 요청 대기열 수와 동일한 기본 서비스 스레드 수를 시작한다.
각 서비스 스레드는 서비스하는 요청 대기열의 코어에 고정된다.
요청 대기열에서 보류 중인 I/O 요청 수가 임계값을 초과할 경우 추가 서비스 스레드가 추가된다.
4. Implementation
Danaus 프로토타입은 파일 시스템 라이브러리, 파일 시스템 서비스,
프로세스 간 통신 및 컨테이너 엔진으로 구성된다.
우리는 Ceph(v10.2.7)의 libcefs 클라이언트와 unionfs-fuse 파일 시스템의 일부를 기반으로
C 코드에서 Danaus 프로토타입의 libservices를 개발했다.
총 개발 effort 에는 다음이 추가되었다.
19,484개의 새로운 코드 라인, 2,115개의 수정, 1,175개의 제거.
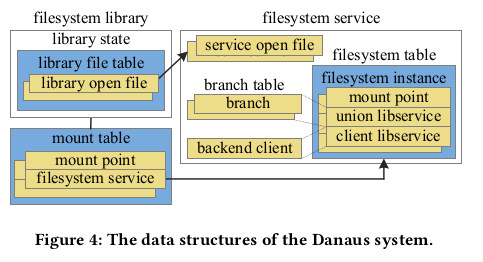
4.1 Data structures
컨테이너당 고유한 루트 파일 시스템을 실행하고
개인 또는 공유 파일 시스템에서 애플리케이션 데이터에 액세스한다.
컨테이너 파일 시스템은 시스템 커널의 마운트 네임스페이스 또는
Danaus의 파일 시스템 서비스에 의해 제공된다 (그림 4).
마운트된 파일 시스템은 호스트의 루트 파일 시스템(마운트 지점)에서 고유한 경로로 식별된다.
컨테이너 풀의 마운트 테이블은 마운트 지점을 파일 시스템 서비스에 매핑한다.
해당 파일 시스템 서비스의 파일 시스템 테이블은 마운트 지점을 파일 시스템 인스턴스에 매핑한다.
파일 시스템 인스턴스는 Union 파일 시스템 및 백엔드 클라이언트의 libservices를 지정한다.
Union libservice의 분기 테이블은 각 분기에 대해
상위 디렉터리(경로, 액세스 모드, 파일 descriptor)의 속성을 지정한다.
파일 시스템 서비스의 열린 각 파일에 대해 백 드라이버는 서비스 열린 파일 개체를 생성한다.
개체의 메모리 주소는 서비스 파일 descriptor 로 프론트 드라이버에 반환된다.
파일 시스템 라이브러리의 라이브러리 상태는
프로세스의 개인 파일 시스템 상태(예: 루트 디렉토리)를 저장한다.
Danaus와 커널은 프로세스의 열린 파일에 독립적으로 파일 descriptro 를 할당한다.
열려 있는 파일마다 고유한 파일 descriptro 를 지정하여 발생할 수 있는 충돌을 방지한다.
이러한 각 파일 descriptor 에 대해 자료 구조에는
라이브러리 파일 테이블이라고 불리는 고유한 항목이 있다.
프로세스에 개인 파일 descriptor 로 entry 인덱스를 반환한다.
라이브러리 파일 테이블에서 파일 descriptro 가 없거나 마운트 테이블에서 경로가 누락된 경우
라이브러리는 시스템 호출로 커널에 요청을 전달한다.
위와 유사한 메커니즘을 사용하여 네트워크 소켓과 디렉터리 스트림에 접근하기 위해
라이브러리 오픈 파일에 오버로드한다.
4.2 Filesystem library and service
파일 시스템 라이브러리는 프로세스, 스레드, 소켓 및 파이프에 대한 여러 관리 호출과 함께
대부분의 동기 및 비동기 파일 입출력 호출을 구현한다.
unionfs-fuse 파일 시스템에서 파생된 라이브러리로 union libservice를 구현했다.
unionfs-fuse의 I/O 함수를 수정하여 파일 시스템 인스턴스를 매개 변수로 받아들이고
로컬 파일 시스템 대신 클라이언트 libservice를 호출했다.
클라이언트 libservice는 메모리의 데이터 및 메타데이터 캐싱을 위한
user-level 객체 캐시를 지원하는 libcephfs 라이브러리에서 파생되었다.
우리는 파일 시스템 인스턴스를 매개 변수로 받아들이는 기능 래퍼를 통해
Union 과 클라이언트 libservice의 인터페이스를 통합한다.
정의되지 않은 Union 파일 시스템의 경우 어플리케이션은 함수 래퍼를 사용하여
클라이언트 libservice에 직접 액세스한다.
4.3 Container engine
Danaus 컨테이너 엔진은 호스트의 컨테이너 풀을 관리하는 user-level 데몬이다.
cgroup은 리소스 사용을 제한하고 네임스페이스는
컨테이너 풀이나 개별 컨테이너의 프로세스를 분리한다.
CPUet(cgroup v1)은 프로세스 그룹이 실행되는 프로세서 코어 및
메모리 노드를 지정하는 반면 메모리 하위 시스템(cgroup v2)은 해당 메모리 사용량을 제한한다.
컨테이너 엔진은 user 또는 커널 레벨에서 실행되는 Union 파일 시스템과
백엔드 클라이언트의 조합을 지원한다.
Danaus user-level 파일 시스템과는 별도로, 우리는 선택적으로 다음과 같이 지원한다.
- 백엔드 클라이언트로서 커널 기반 CephFS 클라이언트와 FUSE 기반 Ceph-fuse
- Union 파일 시스템으로서 커널 기반 AUFS 및 FUSE 기반 Unionfs-fuse (둘 다 Unionfs에서 파생된 것이기 때문에 상당히 유사함).
각 커널 기반 마운트(예: VFS를 통해)는 FUSE의 경우 다른 user-level 프로세스와 함께
다른 커널 파일 시스템 인스턴스에 해당한다.
커널 기반 파일 시스템은 기본적으로 시스템 페이지 캐시를 사용하며,
Direct I/O를 통한 사용 안 함(예: FUSE에서 이중 캐시를 사용하지 않음)을 선택한다.
5. Discussion
우리는 Danaus 의 설계와 구현이 우리의 원칙에 따라
우리의 목표를 어떻게 실현하는지 정성적으로 분석한다.
Compatibility
컨테이너는 공유 분산 파일 시스템에서 Danaus의 루트 및 애플리케이션 파일 시스템을 마운트하고
POSIX 유사 인터페이스를 통해 직접 액세스한다.
Isolation
컨테이너 풀은 호스트의 네임스페이스와 잠재적으로 구별되는 일련의 네임스페이스를 얻는다.
따라서 파일 시스템 서비스는 공유 커널이 아닌 컨테이너 풀의 하드웨어 리소스에서 실행된다.
user-level 실행을 통해 Danaus는 멀티테넌트 I/O 분리를 개선하고 프로세서 코어,
커널 lock 및 메모리 캐시에서의 경합을 줄인다.
호스트 커널은 colocation 된 모든 컨테이너에 상속되는 attack surface 를 가진 단일 장애 지점이다.
그러나 user-level 에서 파일 시스템과 캐시의 실행은 더 얇은 커널 인터페이스를 포함하며
결과적으로 더 작은 신뢰할 수 있는 computing base 가 된다.
장애 억제를 위해 Danaus는 파일 시스템을 호스트 커널에 의해 고정되지 않고
풀마다 구별되는 구현을 통해 별도의 user-level 서비스로 분해한다.
실패한 파일 시스템 서비스는 단일 풀의 프로세스에는 영향을 미치지만
시스템 커널이나 호스트 루트 파일 시스템에는 영향을 미치지 않는다.
Efficiency
서버 측에서 공유 네트워크 파일 시스템은 공유 어플리케이션 및 시스템 파일의
스토리지 공간 중복을 자연스럽게 방지한다.
클라이언트 측에서 클라이언트 캐시는 메모리 공간 및 네트워크 대역폭의 중복 없이
공유 파일을 제공한다.
Union 파일 시스템을 백엔드 클라이언트와 통합하면
상호 작용을 위한 리소스 중복 및 페이지 캐시 교차가 방지된다.
Union 파일 시스템은 복제된 컨테이너에서 공통 I/O 요청을 처리할 때
메모리 공간과 대역폭을 제거한다.
어플리케이션과 파일 시스템 서비스의 user-level 상호 작용은
커널을 통한 메모리 복사 및 모드 전환을 방지한다.
Mode switch 란 ?
커널 기반 파일 시스템에서 일반적인 호출은 커널에 한 번 또는 여러 번 입력된다.
반대로 Danaus는 일반적인 경우 네트워크 처리와 스레드 스케줄링에 커널만 관여한다.
Flexibility
테넌트는 호스트에서 Danaus 백엔드 클라이언트를 사용하여
컨테이너가 읽기 전용 또는 쓰기 가능 모드에서 파일 또는 분기를 공유할 수 있도록 한다.
테넌트는 리소스 이름 지정, 메모리 예약, 페이지 교체(예: swappiness)
또는 데이터 일관성(예: writeback)에서 서로 다른 설정을 가진 여러 파일 시스템 서비스를
사용할 수 있다. 여러 테넌트가 공유 풀을 통해 협업할 수 있다.
일상적인 관리 작업(예: 소프트웨어 업데이트, 멀웨어 검색, 컨테이너 마이그레이션)은
개별 컨테이너 내에서가 아니라 백엔드 스토리지를 통해 중앙에서 편리하게 실행될 수 있다.
6. Experimental evaluation
우리는 다양한 파일 시스템 클라이언트의 능력을 정량화한다
-
동종 또는 이기종 리소스 요구 워크로드 간의 I/O 경합 방지
-
스케일업의 마이크로벤치마크 및 실제 어플리케이션 전반에 걸쳐
낮은 리소스 소비로 고성능 달성 읽기 또는 쓰기 및 순차 또는 임의 I/O 요청이 있는 확장 설정
6.1 Experimentation Environment
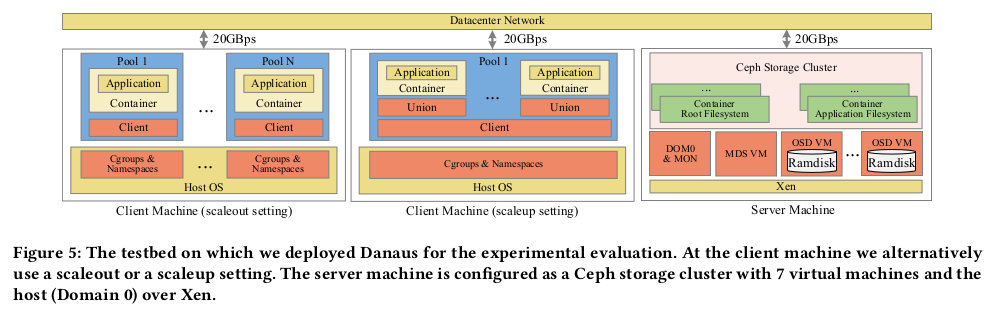
Machines
클라이언트와 서버는 2.4로 클럭이 지정된 4개의 소켓으로 구성된 동일한 두 x86-64 시스템이다.
시스템에는 4개의 16-코어 프로세서(AMD Opteron 6378),
256GB RAM 및 24포트 10GbE 스위치에 대한 20Gbps 연결이 있다.
코어 쌍은 64KB L1 데이터 캐시와 2MB L2 캐시를 공유한다.
각 시스템에는 6개의 로컬 디스크(125-204MB/s)가 있으며,
그 중 2개(RAID1)에 루트 시스템이 설치되어 있다.
두 시스템 모두 Debian 9 Linux(커널 v4.9)를 실행한다.
최신 Linux 커널(v5.4.0)에 대한 몇 가지 실험을 반복했지만 유사한 결과를 얻었다.
클라이언트 시스템은 Linux cgroup(v1,v2) 및 네임스페이스로 구성된 컨테이너를 실행한다.
서버 시스템은 8개의 노드로 구성되며, 각 노드는 8개의 코어 및 32GB RAM으로 구성된다.
우리는 호스트 시스템을 실행하기 위해 노드 하나를 사용한다.
나머지 노드는 6개의 OSD(객체 스토리지 디바이스)와 1개의 MDS(메타데이터 서버)로 구성된
Ceph(v10.2.7) 클러스터를 실행하는 7개의 VM(Xen v4.8)으로 구성된다.
각 OSD에서 기본 메모리는 8GB RAM을 사용하고,
나머지 24GB는 XFS를 사용하여 OSD 데이터와 저널을 빠르게 저장한다.
모든 Ceph 클라이언트는 스토리지 서버의 램디스크에서 저장된 이미지와 데이터에 액세스한다.
클라이언트와 서버 머신의 하드 디스크만 사용하여 운영 체제를 저장하거나
로컬 I/O 에서 Ceph 클라이언트에 경합을 발생시킨다.
그림 5에서는 왼쪽(scaleout)과 중간(scaleup)에 대한 두 가지 대체 구성과
오른쪽에 서버 시스템 구성이 포함된 테스트베드 환경을 보여 준다.
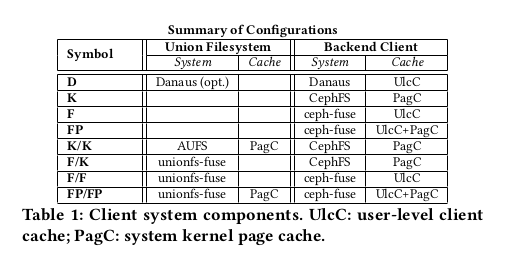
Filesystems
우리는 Danaus (D)를 Union 파일 시스템 및 Ceph 클라이언트의 여러 조합과 비교한다.
-
대표적인 mature 시스템으로서 커널 기반 Ceph 클라이언트(CephFS)를 검사한다.
Union 과 클라이언트가 모두 사용하는 페이지 캐시를 사용하여 독립 실행형(K) 또는
커널 기반 AUFS(K/K) 이하를 실행한다.
-
user-level 기준으로는 페이지 캐시(FP) 또는 바이패스(F)를 사용하는
FUSE 기반 Ceph 클라이언트(ceph-fuse)를 사용한다.
FUSE 기반 클라이언트를 통해 선택적으로 Union 과 클라이언트(FP/FP)에서 모두 사용되는
페이지 캐시 또는 없음(F/F)으로 FUSE 기반 Unionfs (Unionfs-fuse)를 실행한다.
FUSE 기반 Ceph 클라이언트는 user-level 객체 캐시만 사용하고
Union 도 클라이언트도 커널 페이지 캐시를 사용하지 않기 때문에
F/F는 최소 메모리 공간을 차지한다.
-
마지막으로 페이지 캐시(F/K)로 CephFS를 통해 캐시가 없는 FUSE 기반 Unionfs를 검사한다.
FUSE에서, 우리는 이전 연구에서 알려진 몇 가지 최적화를 활성화한다.
페이지 캐시(F, F/K 또는 F/F)를 바이패스하기 위해 direct I/O 마운트 옵션을 사용한다.
표 1에는 이러한 구성이 요약되어 있다.
Workloads
다음 워크로드를 사용하여 광범위한 실험 평가를 수행한다.
-
단순 파일 서버 읽기/쓰기 I/O를 에뮬레이트하는 Filebench 파일 서버(FLS)
-
로컬 읽기 집약적 I/O를 위한 Filebench Webserver(WBS)
-
Filebench Singlestreamwrite 및 Singlestreamread(간단히 Seqwrite 및 Seqread)
순차 쓰기 및 읽기를 생성하기 위한 micro-workload
-
로컬 랜덤 읽기/쓰기 I/O 생성을 위한 Stress-ng(RND)
-
CPU 집약적 처리를 위한 Sysbench(SSB)의 CPU 벤치마크
-
쓰기 및 코어 외 읽기를 위한 RocksDB 영구 키 값 저장소
-
Lighttpd 표준 호환 고성능 웹 서버 컨테이너 시작 시 읽기 집약적인 I/O의 경우
-
메타데이터 활동이 적은 단일 파일의 순차 쓰기 및 읽기를 위한
자체 파일 추가(Fileappend) 및 읽기(Fileread).
기본 Debian 9 Linux가 있는 별도의 컨테이너에서 각 워크로드 인스턴스를 실행한다.
Methodology
동일한 플랫폼에서 서로 다른 시스템의 비교는 Danaus 의 상대적 이익과 잠재력에 대한
중요한 직관을 제공한다.
커널 기반 Ceph, user-level libcephfs, FUSE 기반 Ceph-fuse는 기능적으로는 유사하지만
Ceph 클라이언트의 구현은 상당히 다르다.
AUFS는 신뢰성과 성능을 향상시키기 위해 커널 기반 Unionfs 를 다시 쓴 것이며
Unionfs-fuse 는 Unionfs 의 FUSE 기반 버전이다.
durty page flushing 시 만료 간격은 5초, 다시 쓰기 간격은 1초의 기본 설정을 유지한다.
메모리 부족(OOM) 종료를 방지하기 위해 user-level 클라이언트 캐시 크기는
달리 지정되지 않는 한 풀 메모리의 50%로 설정된다.
우리는 최대 durty bytes 를 커널 기반 Ceph에서 풀 RAM의 50%로 설정하고
Danaus 및 FUSE 기반 Ceph에서 클라이언트 캐시의 50%로 설정한다.
필요에 따라(최대 10회) 실험을 반복하여 측정된 평균의 5% 이내에서
1차 메트릭의 95% 신뢰 구간(예: 처리량)의 절반 길이를 구한다.
우리는 대부분 대기 시간, 처리량 또는 시간 범위를 보여주지만,
꼬리 통계를 포함한 다른 메트릭에서도 비슷한 결론에 도달했다.

6.2 Isolation
표 2에 요약된 것처럼 1 또는 7 파일 서버(FLS) 인스턴스와
I/O 또는 CPU 바운드인 다른 워크로드 간의 성능 간섭을 조사한다.
각 워크로드 인스턴스는 코어 2개와 8GB RAM으로 구성된 전용 컨테이너 풀에서 실행된다.
워크로드는 클라이언트 시스템에서 실행 중인 인스턴스 수(2-8개)의 2배에 해당하는
활성화된 코어 수(4-16)로 실행된다.
우리는 5MB의 평균 파일 크기, 1000개의 파일, 120초 지속시간의 FLS를 실행한다.
데이터 세트는 Danaus (D) 또는 커널 CephFS 클라이언트(K)를 통해 Ceph(결합 없음)에 저장된다.
Danaus 는 전체 데이터셋을 보관하기 위해 5GB 클라이언트 캐시가 포함된
프라이빗 파일 시스템 서비스를 사용하여 컨테이너의 루트 파일 시스템을 마운트한다.
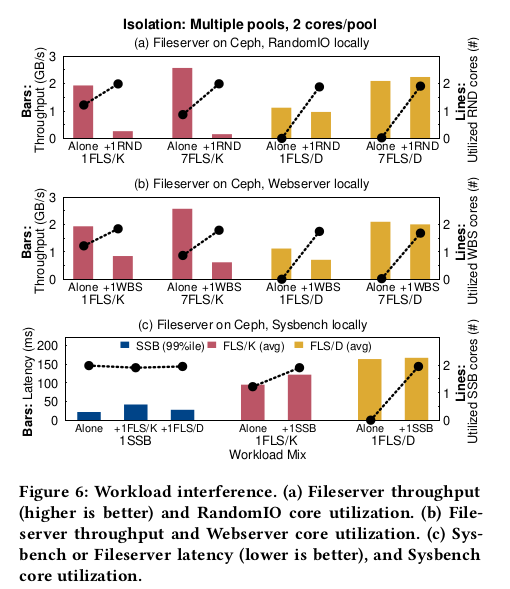
RandomIO
그림 6a는 커널의 성능 변동을 방지하기 위해 Danaus에서 실행되는 FLS의 결과로
그림 1a를 확장한다.
RND(RandomIO)는 2개의 스레드를 사용하여 사전 읽기와 함께 랜덤 512B 읽기/쓰기를 수행한다.
4개의 로컬 디스크(RAID0)에서 ext4를 통해 저장된 1GB 파일에 액세스한다.
D 또는 K에서만 또는 1개의 RND 인스턴스에 병렬로 1개 또는 7개의 FLS 인스턴스를 실행한다.
막대 차트에서 1FLS/D는 1FLS/K보다 처리량이 41% 낮다.
RND의 실행으로 FLS 처리량이 1FLS/K+1RND에서 7.4배,
7FLS/K+1RND에서 16.5배 감소한다는 것을 상기한다.
반대로 1FLS/D+1RND에서는 16% 하락에 그치고 7FLS/D+1RND에서는 더 빠르다.
다르게 말하면, FLS를 RND와 함께 배치했을 때 D가 K보다 3.7배-14.4배 더 빠르다.
Danaus는 각각의 FLS 인스턴스를 실행하는 풀의 코어로 FLS I/O를 처리함으로써
RND의 압력을 피한다.
이는 1FLS/D 또는 7FLS/D를 단독으로 실행할 때
RND 풀의 코어가 2.5% 미만으로 활용된다는 것을 보여주는 꺽은선형 차트를 통해 확인된다.
또한 Danaus는 컨테이너당 별도의 user-level 파일 시스템 서비스를 실행하여
커널 lock 경합을 줄인다.
특히 커널 프로파일링에 따르면 1FLS/K+1RND 및 7FLS/K+1RND는
슈퍼블록 구조의 i_mutex_key 커널 lock 에서 현저하게 지연된다.
또한 코어 및 lock 경합으로 인해 7FLS/K+1RND가 단독으로 실행되는 7FLS/K보다
durty page 를 32% 적게 flush 한다.
Webserver
우리는 웹서버 벤치마크(WBS) 옆에서 FLS를 실행하여 비슷한 결과를 얻었다.
4개 이상의 로컬 Disk(RAID0)에서 평균 크기가 16KB인 50개의 스레드 및
200K 파일로 WBS를 구성한다.
K 또는 D를 통해 단독으로 또는 WBS 인스턴스와 병렬로 FLS 인스턴스 1개 또는 7개를 실행한다.
그림 6b의 막대 차트에서 WBS의 동시 실행은 커널 FLS 처리량을
1FLS/K+1WBS에서 2.3배, 7FLS/K+1WBS에서 4.2배 감소시킨다.
7FLS/D만 해도 7FLS/K보다 18% 느리지만 7FLS/D+1WBS는 7FLS/K+1WBS보다 3.2배 빠르다.
WBS가 비활성일 때 1FLS/K 및 7FLS/K는 WBS 코어를 87-122% 활용하는 반면,
1FLS/D 및 7FLS/D는 0.5-2.5%에 불과하다(그림 6b의 라인).
RND와 마찬가지로, 커널이 WBS의 코어를 더 이상 활용하여 FLS를 지원할 수 없기 때문에
WBS가 실행 중일 때 커널 FLS 성능이 저하된다는 결론을 내린다.
Sysbench
Danaus는 또한 동일 장소에 배치된 이기종 워크로드의 지연 시간 증가를 제한한다.
64비트 정수를 사용한 소수 계산에서 2개의 스레드가 있는
Sysbench CPU 벤치마크(SSB)를 고려한다.
그림 6c의 막대 도표에서, 우리는 SSB 지연 시간의 99%와 Ceph에 대한
평균 FLS 지연 시간을 보여준다.
우리는 하나의 FLS 인스턴스를 K 또는 D에 단독으로 또는 하나의 SSB 인스턴스에 병렬로 실행한다.
워크로드 간섭으로 인해 1FLS/K+1SSB에서는 SSB 및 FLS 지연 시간이
각각 93%와 28%씩 증가하지만
1FLS/D+1SSB에서는 27%와 2%(3.4배 및 14배 감소)에 불과하다.
FLS를 단독으로 실행할 경우 K는 예약된 SSB 코어도 사용하기 때문에
K보다 대기 시간이 짧다(그림 6c 꺽은선형 차트).
RND 및 WBS에 비해 SSB는 user-level 계산만 실행하므로 1FLS/K에 미치는 영향이 적다.
요약하자면 Danaus는 하드웨어 및 커널 경합이 적은 I/O를 제공하기 때문에
경쟁 워크로드에서 처리량과 대기 시간의 안정성을 달성한다.
반대로 커널 기반 클라이언트는 최대 16.5배까지 성능을 저하시킨다.
6.3 Performance and Efficiency
Danaus 또는 FUSE와 커널의 다른 조합에 대한 I/O 바인딩 어플리케이션과
microbench mark 를 고려한다.
컨테이너당 워크로드를 실행하고 측정된 성능과 사용된 리소스를 보고한다.
각 컨테이너는 고유한 시스템 이미지(2.7GB)에서 독립적으로 실행되거나
공유 읽기 전용 하위 분기와 개인 쓰기 가능한 상위 분기에 복제된다.
섹션 6.2에서 경쟁 컨테이너 풀 간의 격리를 줄이는 커널 기반 클라이언트를 발견했지만,
mature 커널 기반 시스템(K/K)의 관점에서 성능 기준으로 AUFS와 결합되어 있다.
6.3.1 Applications
대표적인 I/O 집약적 어플리케이션으로 RocksDB(v4.5) 및 Lighttpd(v1.4.45)를 연구한다.
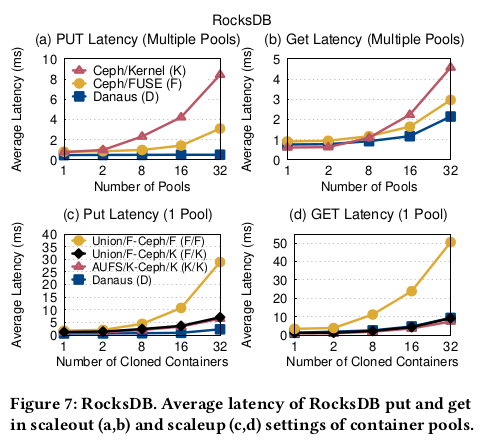
RocksDB (scaleout/scaleup)
우리는 RocksDB 스토리지 엔진을 동일한 기계의 32개 컨테이너 풀에서 독립적으로 가동한다.
각 풀은 2코어 및 8GB RAM을 통해 하나의 컨테이너로 구성된다.
컨테이너는 64MB 메모리 버퍼와 2개의 압축 스레드로 RocksDB를 실행한다.
풀은 전용 Ceph 클라이언트를 사용하여 컨테이너와 RocksDB의 파일을 모두 보유하는
개인 루트 파일 시스템을 마운트한다.
put 워크로드는 1개의 스레드를 사용하여 9B 키와 128KB 값의 1GB 임의 쌍을 삽입한다.
우리는 1-32개의 풀에 대해 D, F 또는 K 클라이언트에 대한 RocksDB의 평균 put latency 를 측정했다.
그림 7a에서 D는 최대 5.9x 및 16.2x(32개 풀)까지 F 및 K보다 빠르다.
주된 이유는 총 커널 lock 대기 시간(표시되지 않음)이 D(1 풀)에 비해
최대 5배 및 152배 더 높은 것으로 나타나는 F 및 K의 강렬한 커널 경합이다.
다른 실험에서는 풀당 코어 외 읽기 집약적 워크로드를 실행한다.
각 컨테이너는 임의 가져오기로 8GB를 다시 읽기 전에 임의의 128KB put 을 사용하여
RocksDB를 8GB로 채운다.
그림 7b에서 D는 최대 1.4배 및 2.2배 (32개 풀)까지 F 및 K보다 빠르다.
이에 따라 F 및 K(표시되지 않음)의 총 커널 lcok 대기 시간은 D(32개 풀)의 최대 2.8배 및 17.8배이다.
또한 D는 CPU 활동(IO 대기 포함)과 K의 메모리 소비를 최대 9.5배 및 2.6배까지 줄인다.
scale out 에서 Danaus는 컨테이너별로 고유한 클라이언트를
user-level 에서 실행하고 액세스하여 lock 경합 및 리소스 소비를 줄인다.
또한 단일 풀에서 복제된 여러 컨테이너를 실행하는 확장 설정을 살펴보았다.
각 컨테이너는 프라이빗 RocksDB 인스턴스를 실행한다.
컨테이너는 고유한 통합 파일 시스템과 공유 Ceph 클라이언트로 구성된
개인 파일 시스템 인스턴스를 통해
루트 파일 시스템을 마운트한다.
Ceph 클라이언트를 사용하면 컨테이너가 루트 파일 시스템의 하위 읽기 전용 계층을
공유할 수 있다.
D, F/F, F/K 및 K/K에서 RocksDB 지연 시간을 측정했다(표 1).
put latency 와 관련하여 D는 F/F, F/K 및 K/K보다 각각 최대 12.6배, 3.9배 및 3.6배 빠르다(그림 7c).
대조적으로, get 워크로드(그림 7d)는 32개 클론에서 F/F보다 최대 5.4배 빠르지만
2개 클론에서 K/K보다 최대 2배 느린 D의 혼합 결과로 이어진다.
스케일업에서 단일 클라이언트에 모든 클론을 제공하면 scaleout 분산 및 동시성이 취소된다.
그러나 D는 투입된 다른 시스템 및 유입된 F/F에 비해 상당한 지연 시간 이점을 얻는다.
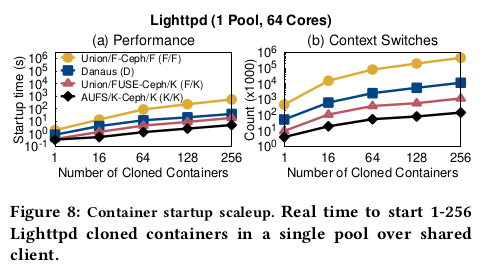
Lighttpd (scaleup)
단일 풀에서 요청을 기다리는 Lighttpd로 여러 복제된 컨테이너를 시작하는 시간을 측정한다.
I/O 트래픽은 초기 명령을 시작하기 위한 Exec 호출,
동적 라이브러리를 가져오기 위한 mmap 호출 및
어플리케이션 파일을 준비하기 위한 user-level 호출에 의해 생성된다.
Danaus에서 이 scaleup 워크로드는 대부분 데이터를 읽기 위해 (레거시) 커널 경로를 사용하고
데이터를 쓰기 위해 (기본) user-level 경로를 적게 사용한다.
CephFS(K/K 및 F/K)를 사용하는 커널 기반 AUFS(K/K)는
cefs-fuse(F/F) 또는 libcefs(D)를 사용하는 user-level 의 unionfs-fuse에 비해
더 높은 성능을 제공한다.
1-256 인스턴스를 시작하는 실시간 시간과 관련하여
D는 K/K보다 최대 8.8배, F/K보다 2.9배 느리다(그림 8a).
커널 프로파일링을 통해 워크로드가 읽기 집약적이며
D는 (레거시) FUSE 경로를 사용하여 동적 라이브러리를 가져오는 것을 확인했다.
비슷한 Uinon 과 Ceph 클라이언트 코드를 사용하는 F/F에 비해
D는 시작 시간(2.3-14.2배)과 CPU 활동(최대 10.5배)을 상당히 줄여준다.
F/F에 비해 D의 성능과 효율성이 개선된 것은 부분적으로 9-39배 적은 컨텍스트 스위치 때문이다
(그림 8b의 상단 두 라인).
검사된 실제 애플리케이션에서 Danaus는 scaleout 또는 put scaleup 및 get scaleup 에서
다른 시스템보다 대기 시간과 리소스 소비량이 낮다.
레거시 중심의 I/O에서는 성숙도가 높은 K가 시작 시간을 단축하는 반면
D는 F/F보다 최대 14.2배 빠르다.
6.3.2 Microbenchmarks
2개의 Filebench 워크로드와 1개의 맞춤형 개발 워크로드의 성능 및 리소스 소비량을 측정한다.
Ceph 네트워크 스토리지에서 Danaus, FUSE 또는
커널 기반 구성 요소를 통해 마운트된 루트 파일 시스템이 제공하는
데이터의 scaleout 및 scaleup 설정을 고려한다.
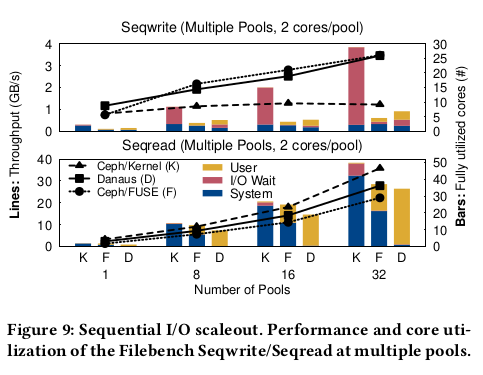
Seqwrite/Seqread (scaleout)
Seqwrite를 사용하여 1~32개의 풀에서 순차 쓰기를 생성한다.
2개의 코어와 8GB RAM으로 구성된 각 풀은 Ceph에서 D, F 또는 K에 이르는
개인 루트 파일 시스템을 마운트한다.
Seqwrite는 파일 크기 1GB, 스레드 16개, 지속 시간 120초로 구성한다.
Seqwrite는 어플리케이션에서 백엔드 서버에 이르는 전체 경로에서 I/O 활동을 생성한다.
그림 9(위)에서 D와 F의 처리량은 K보다 최대 2.8배 높은 반면,
K의 I/O 대기 CPU 시간은 F의 최대 90배이다.
한 가지 이유는 K가 커널 lock 대기(특히 i_mutex_dir_key 와 i_mutex_key)를 위해
세 자릿수의 시간을 더 소비하기 때문이다.
또한 K는 더 많은 풀에서 수가 감소하는, 할당되지 않은 코어로 I/O를 처리한다는 것을 발견했다.
다른 실험에서 Seqwrite와 유사하게 구성된 Seqread를 사용하여 순차 읽기를 생성한다.
워크로드는 클라이언트 캐시에 대한 로컬 경로를 강조한다.
그림 9(하단), K가 D보다 최대 37%, D가 F보다 최대 75%(1풀) 빠르다.
F와 K와 달리 D는 주로 user-level 에서 실행되며 커널(바 차트)을 무시해도 될 정도로 사용한다.
user-level 프로파일링을 통해 D의 동시성이 client_lock에 의해 제한된다는 것을 발견했다.
이것은 D에 의해 사용되는 libcephf의 전역 lock 이지만 K의 커널 lock 에는 사용되지 않는다.
예비 실험에서 전역 lock 을 제거하면 Danaus 동시성이 향상되지만
현재 범위를 벗어난 libcephfs 리팩토링이 필요하다.
요약하면 풀 scaleout 에서 D는 순차 쓰기에서는 F 및 K보다 빠르지만
캐시된 순차 읽기에서는 K보다 느리다.
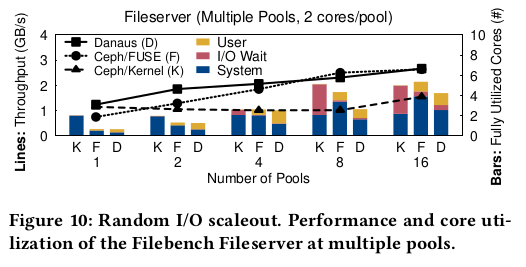
Fileserver (scaleout)
우리는 여러 풀의 스케일 아웃에서 파일 서버를 실험한다.
코어 2개와 8GB RAM으로 구성된 각 풀은 개인 D, F 또는 K 클라이언트를 통해
루트 파일 시스템을 마운트한다.
Ceph에서 실행되는 파일 서버는 백엔드 스토리지의 전체 경로를 강조하는
랜덤 읽기/쓰기 워크로드를 생성합니다.
클라이언트 호스트에서 1-16개의 풀을 실행하고 풀의 총 처리량을 측정한다.
그림 10(선형 차트)에서 D는 2.7을 달성한다.
16개 풀에서 GB/s로 1개 풀에서 F보다 1.7배, 8개 풀에서 K보다 2.3배 더 유리하다.
서버 측에서 3개의 클라이언트가 소비하는 리소스 양은 비슷하지만(표시되지 않음),
K는 클라이언트 측에서 최대 22배 더 높은 I/O 대기 CPU 시간을 생성한다(그림 10, 막대 차트).
따라서 풀 scaleout 시 랜덤 읽기/쓰기 워크로드에서 D는 풀 수를 늘릴 때 K에 비해
성능이 크게 향상되고 작은 규모에서는 F에 비해 성능이 크게 향상된다.
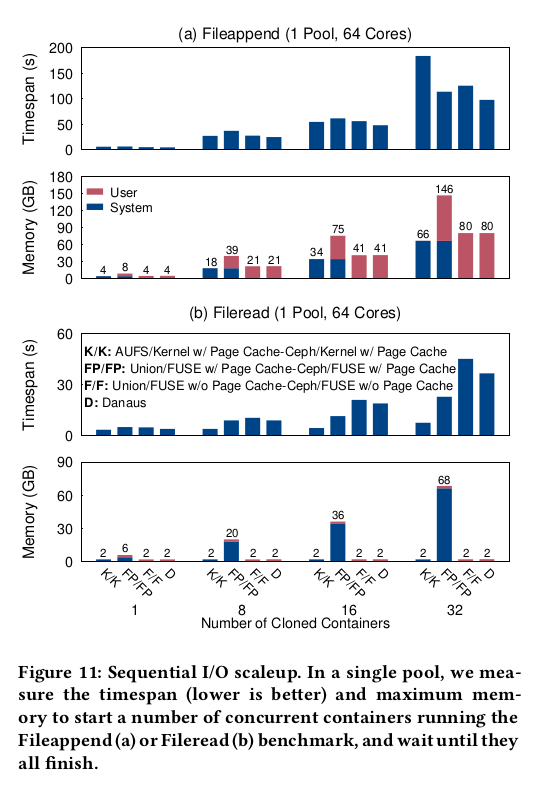
Fileappend/Fileread (scaleup)
64개 코어 및 200GB 메모리의 단일 풀 내에서 여러 개의 복제된 컨테이너를 실행하고
64GB RAM을 호스트 시스템에 남겨둔다.
각 컨테이너의 루트 파일 시스템은 공통 읽기 전용 하부 브랜치를 제공하기 위해
사설 Union 파일 시스템과 공유 Ceph 클라이언트를 통해 마운트된다.
컨테이너를 시작하고, 높은 데이터/낮은 메타데이터 워크로드를 실행하고,
모든 컨테이너가 완료될 때까지 대기하는 시간을 측정한다.
FileAppend는 O_WRONLY|O_APPEND 모드에서 단일 2GB 파일을 열고 1MB를 기록한 후 닫는다.
파일이 Copy-on-write union 에 의해 상위 계층에 복사되기 때문에
생성된 I/O는 약 50/50 읽기/쓰기이다.
그림 11a (상단)에서, D는 다른 시스템, 특히 32개의 컨테이너에서
최대 46%의 시간 범위 (낮은 것이 더 낫다)를 달성하는 경향이 있다.
그림 11a(하단)에서 K/K, F/F 및 D에 필요한 최대 메모리는 컨테이너 수에 따라
선형적으로 증가하는 반면,
FUSE 기반 Ceph 클라이언트의 페이지 캐시 사용은 FP/FP에서 거의 두 배로 증가한다.
다른 실험에서 Fileread는 2GB 파일을 O_RDONLY 모드로 열고
전체 파일을 1MB 블록으로 읽은 다음 닫는다.
그림 11b(위)에서 K/K는 D보다 1.2-4.9배 짧은 시간대를 달성하지만
클라이언트 CPU 활동량은 최대 7.4배 더 높습니다(표시되지 않음).
그림 11b(하단)에서 F/F는 D와 동일한 메모리 크기를 요구하지만 시간 범위가 11-23% 더 길다.
FP/FP는 D보다 짧은 시간대를 달성하지만 최대 30배 더 많은 메모리를 차지한다.
FP/FP의 과도한 메모리 사용은 페이지 캐시에서 Union 및 Ceph 클라이언트,
user-level 에서 Ceph 클라이언트의 캐싱으로 인해 발생한다.
FUSE Union 또는 FUSE 클라이언트에서 페이지 캐시를 바이패스해도
메모리 사용량이 F/F의 2배 이상 유지된다.
따라서 Union 및 공유 클라이언트를 통해 복제된 컨테이너를 사용하는 풀 scaleup 에서
Danaus와 FUSE는 혼합 읽기/쓰기에서는 커널보다 빠르지만 순차 읽기에서는 느리다.
7. Related work
Libservices 는 클라우드 환경에서 컨테이너 이미지 레지스트리와
루트 또는 어플리케이션 파일 시스템을 프로비저닝하는 데 사용할 수 있는
테넌트별 user-level 공유 서비스의 추상화이다.
libservices를 기반으로 하는 Polytropon user-level 툴킷은
API 라이브러리, 메시지 대기열, 데이터 전송 및 파일 시스템 서비스를 포함한
멀티테넌트 호스트의 스토리지 구성 요소를 구현하기 위해 이전에 도입되었다.
현재 작업에서는 libservices와 Polytropon을 기반으로 Danaus를 빌드한다.
우리는 현재 컨테이너 스토리지 시스템의 비효율성에서 우리의 작업에 동기를 부여한다.
그 후 우리는 원칙과 목표를 지정하고 Danaus의 인터페이스, 캐시 및 일관성 속성을 정당화하고
복제 또는 독립 컨테이너의 격리, 효율성 및 성능을 평가한다.
다음으로 파일 시스템, 가상화, user-level I/O 및 microkernel 에서
관련 작업을 요약하고 차별화한다.
Filesystems
IceFS는 로컬 파일 시스템의 물리적 구조를 분리하고
동일한 로컬 파일 시스템에서 실행되는 가상 머신과
분산 파일 시스템의 동일한 스토리지 서버를 공유하는 어플리케이션에서
독립적인 성능과 안정성을 보여준다.
Danaus는 함께 배치된 컨테이너의 분산 파일 시스템 클라이언트를 격리하는 문제를 해결합니다.
Slacker는 NFS 공유 네트워크 파일 시스템의 스냅샷/복제 작업에 의존하여
Docker 데몬을 통해 컨테이너 이미지를 효율적으로 제공하고
호스트 커널 내부의 비트맵을 사용하여 클라이언트 캐시를 중복 제거한다.
TotalCOW는 블록 주소 캐싱 및 데이터 비교를 사용하여
컨테이너 이미지의 I/O 및 캐시 비효율성을 방지한다.
두 시스템 모두 컨테이너 격리 또는 파일 수준 공유에 대한 기본 지원이 부족한 블록 기반 볼륨에서
컨테이너 클론의 효율적인 공유 이미지 중복 제거를 목표로 한다.
PolarFS 분산 파일 시스템은 경량 네트워크 및 I/O 스택을 사용하는 클라우드 데이터베이스에서
짧은 대기 시간을 달성한다.
Docker 스토리지 드라이버는 작업 부하 I/O에 따라 성능 차이가 나타난다.
레지스트리 서비스는 컨테이너 이미지 캐싱의 이점을 제공하는 풀 집약적인 워크로드를 처리한다.
Wharp는 이미지 계층을 공유 NFS 스토리지 백엔드에 배치하여 이미지 레지스트리를 제거한다.
Danaus는 클라이언트 호스트와 스토리지 백엔드 모두에서 데이터 공유를 활용하여
컨테이너 I/O 효율성을 개선한다.
Virtualization
운영 체제 및 하이퍼바이저는 데이터 집약적 컨테이너 또는 가상 머신(VM) 간의
성능 간섭을 극복하기 위해 상당한 튜닝(예: swappiness, cgroup)이 필요하다.
serverless function 은 서버 관리를 숨기기 위해 컨테이너에서 실행되지만
동일한 VM에 배치될 경우 I/O 성능이 저하된다.
네트워크 처리는 새로운 커널 리소스 어카운팅(Iron)을 통해 컨테이너 간에 분리되거나
메시지 큐를 전용 코어의 커널 스레드로 오프로드(IsoStack)한다.
하이퍼바이저(LightVM) 또는 커널(VirtuOS)의 복잡한 구성요소 파티셔닝으로
시스템 분리가 개선되었다.
FlexSC는 시스템 집약적인 워크로드에서 멀티 코어 프로세서 효율성을 개선하기 위해
예외 없는 시스템 호출을 도입했다.
MultiLanes는 파일 백업 가상화 블록 장치를 사용하고 VFS 데이터 구조를 분할하여
공유 로컬 파일 시스템에 대한 컨테이너 경합을 줄인다.
Heracles는 프로세서 하드웨어 및 Linux 커널 방법을 사용하여
대기 시간에 중요한 작업 및 최선의 작업을 일괄 처리한다.
위의 접근 방식은 Danaus의 컨테이너 풀당 user-level 기능 대신
하드웨어 기반 또는 커널 기반 파티셔닝으로 격리를 개선한다.
gVisor 샌드박스는 분리된 user space 커널로 시스템 API 공격 벡터를 제한하지만,
현재 상당한 I/O 성능 비용이 소요된다.
User-level I/O
라이브러리는 어플리케이션 I/O 호출을 가로채고 컨테이너 네트워크를 가상화하기 위해
user-level 라우터와 통신한다(SlimSocket, FreeFlow).
캐시 일관성이 없는 멀티코어에서 어플리케이션은 RPC를 통해 Hare 로컬 파일 시스템과 통신하지만
공유 메모리를 통해 버퍼 캐시에 액세스한다.
에어리와 스플릿FS는 user-level 라이브러리와 함께
스토리지 클래스 메모리를 위한 로컬 파일 시스템을 구현한다.
Arakis는 하드웨어 가상화를 통해 어플리케이션에 대한 직접 장치 액세스를 제공한다.
Graphene은 libOS를 통한 공유 POSIX 추상화를 사용하여 다중 프로세스 애플리케이션을 실행한다.
DAFS는 user-level 의 비 POSIX API를 통해 RDMA를 통한 로컬 파일 공유를 가능하게 했다.
SFS 툴킷은 커널 내 NFS 클라이언트가 액세스하는 user-level 루프백 서버를 구성했다.
Danaus는 빠른 로컬 I/O 디바이스를 가상화하는 대신
클라이언트 호스트에서 여러 테넌트의 컨테이너 파일 시스템 I/O를 격리한다.
Microkernels
Fault isolation 는 신뢰되지 않는 모듈을 주소 공간의
논리적으로 분리된 부분에 로딩함으로써 이루어진다.
Raven 커널은 커널 데이터 복사 없이 user-level 에서 스레드, IPC, 장치 관리를 구현했다.
캐시 커널은 커널 객체를 관리하기 위해 user 모드 어플리케이션 커널에 의존했다.
exocernel은 신뢰할 수 없는 라이브러리 운영 체제에서 물리적 리소스 관리를 가능하게 하기 위해
모든 하드웨어 리소스를 안전하게 내보냈다.
Danaus는 microkernel 단위의 I/O 관리가 아닌 공유 스토리지의 컨테이너 I/O 격리를 대상으로 한다.
8. Lessons learned
Danaus를 구축하고 평가한 경험은 관리 가능한 복잡성으로 목표를 달성하고
기존의 대표 시스템에 비해 향상된 격리, 효율성 및 성능을 입증하는 데 매우 긍정적이다.
Kernel contention
호스트의 운영 체제 커널은 colocation 된 컨테이너의 핫스팟이 될 수 있다.
이러한 잘못된 동작의 두 가지 주요 원천은
공유 데이터 구조의 lock 경합과 colocation 된 테넌트의 요청을 처리하기 위한
커널에 의한 공격적인 하드웨어 자원 할당이다.
Images and data on shared filesystem
Danaus는 컨테이너 및 공통 클라이언트당 Union 파일 시스템을 통해 활성화된
공유 구성 옵션을 통해 루트 이미지와 어플리케이션 데이터를 모두 제공하는
통합 접근 방식을 제공한다.
분산 파일 시스템에서 직접 컨테이너의 루트 이미지를 제공하면
호스트에 대한 값비싼 이미지 다운로드가 런타임 동안 on-demand 파일 전송으로 대체된다.
Union 파일 시스템은 복제된 이미지를 중복 제거하여
스토리지 클라이언트와 서버에서 공간과 대역폭을 절약한다.
공유 분산 파일 시스템에서 어플리케이션 데이터를 가져오면
협업 컨테이너 간에 네이티브 데이터를 공유할 수 있다.
동일한 테넌트의 여러 컨테이너가 호스트에서 동일한 파일 시스템 클라이언트를 공유하면
메모리 및 대역폭 리소스가 절약된다.
Functionality and execution separation
호스트에서 각 테넌트에 별도의 기능을 제공하여 성능 및 장애 분리를 개선할 수 있다.
파일 시스템 클라이언트의 user-level 실행과 프로세스 간 통신을 통해
각 테넌트에 예약된 메모리 및 프로세서 리소스를 독점적으로 제공할 수 있다.
Client implementation
user-level 클라이언트는 여러 컨테이너에 의해 액세스되는 coarse-grain lock 으로 구현될 경우
경합이 발생할 수 있다.
같은 장소에 배치된 각 tenent 가 자신의 클라이언트를 사용할 때 문제는 덜 심각하다.
복잡한 커널 의존성을 피하기 때문에 user-level 클라이언트는 동시성을 높이기 위해
세밀한 lock 으로 리팩토링되는 데 더 적은 노력이 필요할 것으로 예상된다.
Throughput and latency stability
user-level 에서 제공되는 I/O 집약적 워크로드의 처리량과 대기 시간이
경쟁 리소스 요구 워크로드에 비해 상대적으로 둔하다는 것을 실험적으로 확인했다.
커널 서비스 워크로드의 성능은 단독으로 실행할 경우 더 높을 수 있지만
경쟁업체 다음으로 크게 저하된다.
Scaleout and scaleup
랜덤 I/O 또는 순차 쓰기를 사용하는 scaleout 워크로드에서 Danaus는
서로 다른 테넌트에 걸친 클라이언트의 분산으로 인해 커널 기반 시스템(FUSE 포함)에 비해
성능이 우수하고 효율성이 비슷하거나 향상되었다.
scaleup 워크로드에서 Danaus는 쓰기 또는 혼합 요청에서 커널 기반 시스템에 비해
성능 우위를 유지하는 반면, 읽기 요청에서 Danaus는
FUSE 기반 시스템에 비해 더 빠르거나 더 효율적이다.
9. Limitations and Future work
컨테이너 런타임은 이미 컨테이너 루트 및 어플리케이션 파일 시스템을 위한
수많은 스토리지 드라이버 및 볼륨 플러그인을 지원한다.
Danaus는 단일 프레임워크에서 이러한 유형의 컨테이너 파일 시스템 모두에 대해
격리 및 효율성을 제공하는 user-level 클라이언트 아키텍처를 도입했다.
향후 작업에서는 프로덕션 오케스트레이션 시스템에 Danaus를 이식할 계획이다.
또한 serverless function 계산을 위한 테넌트별 스토리지 프로비저닝에서
Danaus 클라이언트의 적용 가능성에 대해서도 알아보려고 한다.
호스트 리소스를 서로 다른 풀로 분할하면 리소스 활용률이 향상된 분리를 위해 거래된다.
향후 프레임워크 확장을 위해 서비스 품질 보증과 결합된
활용도가 낮은 리소스(예: 메모리)의 동적 재할당을 남겨둔다.
호스트, 네트워크 및 스토리지 백엔드에서
기본 end-to-end 멀티테넌트 격리를 제공하는 것이 이상적이다.
이러한 확장은 테넌트 단위로 데이터 센터 및 스토리지 프로토콜의 최신 개발을 채택하고
내결함성을 더욱 강화하는 데 도움이 될 수 있다.
스토리지 서버의 재구성 및 파일 시스템 서비스와 user-level 네트워크 스택의 통합을
향후 작업에 남겨두는 것은 흥미로운 문제이다.
Danaus 프로토타입은 커널과 user-level 에서 Ceph의 오픈 소스 클라이언트에 의해 만들어졌다.
그러나 제안된 아키텍처는 일반적으로 확장 가능한 파일 시스템(예: Gluster, Lustre)에 적용된다.
Danaus는 파일이 수정될 때 전체 파일의 쓰기 시 복사를 방지하지 않는다.
향후의 작업에서는 백엔드 서버와 클라이언트 캐쉬가
블록 레벨에서 파일 중복 제거를 지원해야 한다
(슬래커는 커널 기반 클라이언트에서 이미지 블록 레벨 중복 제거를 채택함).
Danaus는 공유 네트워크 파일 시스템을 통한 호스트 간의 컨테이너 마이그레이션을
편리하게 할 수 있었다.
10. Conclusions
커널 I/O 처리는 하드웨어 및 소프트웨어 리소스에서 경합을 일으키기 때문에
컨테이너 성능을 저하시킨다.
Danaus는 Union 파일 시스템을 분산 파일 시스템 클라이언트 및 로컬 캐싱과 통합하는
user-level 의 파일 시스템 서비스를 통해 각 테넌트를 별도로 제공한다.
컨테이너 풀의 개인 리소스로 I/O를 처리하고 공유 커널의 값비싼 lock 을 방지한다.
따라서 scaleup 에서 user-level lock 경합은
부분적으로 테넌트별 파일 시스템 서비스를 실행하여 해결된다.
메모리 및 CPU 사용률이 감소하면 Danaus는 mature 커널 기반 클라이언트보다
성능(14.4배)이 더 높고 대기 시간이 16.2배 더 짧으며,
특히 scaleout 이나 쓰기 집약적인 scaleup 에서 두드러진다.
전반적으로 user-level 클라이언트 아키텍처는 수정되지 않은 스톡 시스템 커널을 통해
다중 테넌트 호스트에서 컨테이너 I/O의 격리 및 효율성을 개선한다.
