
USENIX ATC'20 논문
저자 : Simon Shillaker, Peter Pietzuch
Abstract
서버리스 컴퓨팅은 수천 개의 병렬 기능으로 빠르고 저렴하게 확장할 수 있기 때문에
빅데이터 처리에 매우 적합하다.
기존 서버리스 플랫폼은 function 을 임시 stateless 컨테이너로 분리하여
메모리를 직접 공유하는 것을 방지한다.
이로 인해 사용자는 데이터를 반복적으로 복제하고 직렬화해야 하므로
불필요한 성능 및 리소스 비용이 추가된다.
우리는 function 간에 직접 메모리 공유를 지원하고 리소스 오버헤드를 줄이는
새로운 경량 격리 접근 방식이 필요하다고 생각한다.
고성능 서버리스 컴퓨팅을 위한 새로운 격리 추상화인 Faaslets를 소개한다.
Faaslet 은 WebAssembly 에서 제공하는 SFI(software-fault isolation)를 사용하여
실행된 function 의 메모리를 격리하는 동시에
동일한 주소 공간의 function 간에 메모리 영역을 공유할 수 있다.
따라서 Faaslet은 function 이 동일한 시스템에 공존할 때 값비싼 데이터 이동을 피할 수 있다.
Faaslet의 런타임인 Faasm 은 표준 Linux cgroup 을 사용하여 CPU 및 네트워크와 같은
다른 리소스를 격리하고 네트워킹, 파일 시스템 액세스 및 동적 로드를 위한
낮은 수준의 POSIX 호스트 인터페이스를 제공한다.
초기화 시간을 줄이기 위해 Faasm은 이미 초기화된 스냅샷에서 Faaslet을 복원한다.
우리는 Faasm 을 표준 컨테이너 기반 플랫폼과 비교하고
머신러닝 모델을 훈련할 때 10배 적은 메모리로 2배 속도 향상을 달성한다는 것을 보여준다.
머신러닝 추론을 제공하기 위해 Faasm 은 처리량을 두 배로 늘리고 tail latency 를 90% 줄인다.
1. Introduction
서버리스 컴퓨팅은 데이터 집약적인 어플리케이션을 배포하는 대중적인 방법이 되고 있다.
FaaS (Function-as-a-Service) 모델은 컴퓨팅을 많은 function 으로 분해하여
클라우드의 대규모 병렬화를 효과적으로 활용할 수 있다.
이전 연구는 serverless 가 map/reduce-style 작업, 머신러닝 훈련 및 추론,
선형 대수 계산을 지원하는 방법을 보여주었다.
그 결과, 다양한 프로그래밍 언어로 구현된 점점 더 많은 어플리케이션이
serverless 플랫폼으로 마이그레이션되고 있다.
Google Cloud Functions , IBM Cloud Functions , Azure Functions 및 AWS Lamda 와 같은
기존 플랫폼은 일회성, stateless 컨테이너에서 function 을 격리한다.
컨테이너를 격리 메커니즘으로 사용하면 데이터 집약적인 어플리케이션에
데이터 액세스 오버헤드 와 컨테이너 리소스 Footprint 이라는 두 가지 문제가 발생한다.
데이터 액세스 오버헤드 는 컨테이너 기반 접근 방식의 stateless 특성으로 인해 발생하며,
이는 state 를 외부에서 유지하거나(예: Amazon S3) function 호출 간에 전달하도록 강제한다.
두 옵션 모두 각 function 에서 데이터 중복, 반복적인 직렬화,
정기적인 네트워크 전송으로 인해 비용이 발생한다.
그 결과, 현재의 어플리케이션들은 비효율적인 "data-shipping 아키텍처"를 채택하게 된다.
즉, 데이터를 컴퓨팅으로 이동시키고 그 반대로는 이동하지 않는다.
이러한 아키텍처들은 수십 년 전에 데이터 관리 커뮤니티에 의해 버려졌다.
이러한 오버헤드는 function 의 수가 증가함에 따라 복잡해져
severless 컴퓨팅의 매력적 요소인 무제한 병렬화의 이점이 줄어든다.
serverless 워크로드의 high-volume 과 short-lived 때문에 컨테이너 리소스 Footprint 가 특히 중요하다.
컨테이너는 가상 머신(VM)과 같은 다른 메커니즘보다 메모리 및 CPU 오버헤드가 작음에도 불구하고
개별 short-running function 의 실행과 컨테이너의 프로세스 기반 격리 사이에는
impedance 불일치가 남아 있다.
impedance : 교류회로에서 전압과 전류의 비
컨테이너는 수백 밀리초에서 몇 초의 start-up latency 를 가지므로,
오늘날의 serverless 플랫폼에서는 cold start 문제가 발생한다.
컨테이너의 메모리 Footprint 가 크기 때문에 확장성이 제한된다.
기술적으로는 시스템의 프로세스 제한에 따라 제한되지만,
최대 컨테이너 수는 일반적으로 사용 가능한 메모리의 양에 의해 제한되며,
16GB RAM 이 있는 시스템에서 지원되는 컨테이너는 수천 개에 불과하다.
데이터 집약적인 현재의 serverless 어플리케이션은 이러한 문제를 개별적으로 해결했지만
두 가지 문제를 모두 해결하지는 못했다. 대신 컨테이너 리소스 오버헤드를 악화시키거나
serverless 모델을 중단했다.
일부 시스템은 ExCamera, Shredder 및 Cirrus 와 같이 수명이 긴 VM 또는 서비스에서
상태를 유지하여 데이터 이동 비용을 방지하여 serverless 구성요소를 도입한다.
컨테이너의 성능 오버헤드를 해결하기 위해 시스템은 일반적으로 사용자 코드에 대한 신뢰 수준을 높이고
격리 보장을 약화시킨다.
PyWren 은 컨테이너를 재사용하여 여러 function 을 실행한다.
Crucial 은 function 간에 Java 가상 머신(JVM)의 단일 인스턴스를 공유한다.
SAND 는 수명이 긴 컨테이너에서 여러 function 을 실행하며 추가 message-passing 서비스도 실행한다.
Cloud-burst 는 유사한 접근 방식을 사용하여 로컬 key-value 저장 캐시를 도입한다.
컨테이너를 프로비저닝하여 여러 function 과 추가 서비스를 실행하면
리소스 오버헤드가 증폭되고 serverless 에 내재된 세분화된 탄력적 확장이 깨진다.
이러한 시스템 중 몇 개는 로컬 스토리지의 데이터 액세스 오버헤드를 줄이지만
function 간 공유 메모리를 제공하지 않으므로 별도의 프로세스 메모리에 데이터를 복제해야 한다.
다른 시스템은 컨테이너와 VM에서 벗어나 컨테이너 리소스 설치 공간을 줄인다.
Terarium 과 Cloudflare Workers 는 각각 WebAssembly와 V8 Isolates 를 사용하여
소프트웨어 기반 격리를 사용하고,
Krustlet 은 메모리 안전을 위해 WebAssembly를 사용하여 컨테이너를 복제하며,
SEUS 는 serverless unikernels 을 시연한다.
이러한 접근 방식은 리소스 설치 공간이 줄어들지만
데이터 액세스 오버헤드를 해결하지 않으며 소프트웨어 기반 격리만 사용해도 리소스가 격리되지 않는다.
우리는 서버리스 컴퓨팅이
-
function 간에 강력한 메모리 및 리소스 격리 를 제공하면서도
-
효율적인 상태 공유를 지원하는 새로운 격리 추상화 를 통해
데이터 집약적인 어플리케이션을 더 잘 지원할 수 있다는 것을 관찰한다.
데이터는 function 과 함께 배치 되고 데이터 전송을 최소화하면서 직접 액세스 해야 한다.
또한, 이 새로운 격리 추상화는
-
여러 호스트에 걸쳐 상태 확장 을 허용해야 하며,
-
메모리 footprint 가 적어 한 머신에 많은 인스턴스 를 허용해야 하며,
-
빠른 인스턴스화 시간 을 나타내며,
-
기존 어플리케이션의 포팅을 용이하게 하기 위해 여러 프로그래밍 언어를 지원 해야 한다.
본 논문에서는 데이터 집약적인 serverless 컴퓨팅을 위한 새로운 경량 격리 추상화인
Faaslet 에 대해 설명한다. Faaslet 은 효율적인 공유 메모리 액세스로 상태 저장 기능을 지원하며,
Faasm 분산 serverless 런타임에 의해 실행된다.
Faaslet은 우리의 기여를 요약한 다음과 같은 특성을 가지고 있다
-
Faaslets achieve lightweight isolation
Faaslets 은 경량 격리를 달성한다. Faaslet 은 SFI (software fault isolation) 에 의존하며,
이는 function 을 자신의 메모리에 대한 접근으로 제한한다.
Faaslet 과 관련된 function 은 라이브러리 및 언어 런타임 의존성과 함께
WebAssembly 로 컴파일된다.
그리고 나서 Faasm 런타임은 각각 전용 스레드가 있는 여러 개의 Faaslet 을
단일 주소 공간 내에서 실행한다.
리소스 격리의 경우 각 스레드의 CPU cycle 은 Linux cgroup 을 사용하여 제한되고
네트워크 네임스페이스 및 traffic shaping 을 사용하여 네트워크 액세스가 제한된다.
많은 Faaslet 들이 하나의 컴퓨터에서 효율적이고 안전하게 실행될 수 있다.
-
Faaslets support efficient local/global state access
Faaslet 은 효율적인 local/global 상태 액세스를 지원한다.
Faaslet은 동일한 주소 공간을 공유하기 때문에 공유 메모리 영역에 효율적으로 접근할 수 있다.
이를 통해 데이터 및 function 을 함께 배치하고 직렬화 오버헤드를 방지할 수 있다.
Faaslet은 two-tier state 아키텍처를 사용하며, local 계층은 메모리 내 공유를 제공하며,
global 계층은 호스트 전체에 걸쳐 상태에 대한 분산 액세스를 지원한다.
Faasm 런타임은 Faaslets 에 상태 관리 API를 제공하여
두 계층에서 상태를 세부적으로 제어할 수 있게 한다.
또한 Faaslet 은 두 계층 간에 일관성 요구사항이 다른 상태 저장 어플리케이션을 지원한다.
-
Faaslets have fast initialisation times
Faaslet 은 초기화 시간이 빠르다.
Faaslet 이 처음으로 실행될 때 cold start 시간을 줄이기 위해 suspended state 에서 실행된다.
Faasm 런타임은 미리 Faaslet 을 초기화하고 그 메모리를 snapshot 하여 Proto-Faaslet 을 얻고,
이것은 수백 마이크로초 안에 복원될 수 있다.
Proto-Faaslet 은 언어 런타임을 초기화하는 시간을 줄이는 등
새로운 Faaslet 인스턴스를 빠르게 만드는 데 사용된다.
serverless 용 snapshot 에 대한 기존 작업은 단일 머신 방식을 사용하지만
Proto-Faaslets 는 cross-host 복원을 지원하며 OS에 독립적이다.
-
Faaslets support a flexible host interface
Faaslet 은 유연한 호스트 인터페이스를 지원한다.
Faaslet 은 네트워킹, 파일 I/O, global state 접근,
라이브러리 로딩/링크에 대한 POSIX와 같은 호출을 통해 호스트 환경과 상호 작용한다.
이를 통해 동적 언어 런타임을 지원할 수 있으며
10줄 미만의 코드를 변경하여 Cython과 같은 기존 어플리케이션의 포팅을 용이하게 한다.
호스트 인터페이스는 최소한의 오버헤드를 추가하는 동시에
격리를 보장할 수 있는 충분한 가상화 기능을 제공한다.
Faasm 런타임은 LLVM 컴파일러 툴체인을 사용하여
어플리케이션을 WebAssembly로 변환하며 C/C++, 파이썬, 타입스크립트, 자바스크립트를 포함한
다양한 프로그래밍 언어로 작성된 function 을 지원한다.
기존 serverless 플랫폼과 통합되며, Kubernetes를 기반으로 하는 최첨단 플랫폼인
Knative 와의 사용에 대해 설명한다.
Faasm 의 성능을 평가하기 위해 여러 워크로드를 고려하고 컨테이너 기반 serverless 배포와 비교한다.
SGD 로 머신러닝 모델을 훈련할 때, Faasm 은 실행 시간 60%, 네트워크 전송 70%,
메모리 사용량 90% 감소를 달성한다.
TensorFlow Lite 및 MobileNet 을 사용한 머신러닝 추론의 경우
Faasm 은 최대 처리량 200% 이상 증가시키고 tail latency 를 90% 감소시켰다.
또한 Faasm 은 Python/Numpy를 사용하여 행렬 곱셈을 위해 분산 선형 대수학 작업을 실행할 때,
성능 오버헤드는 무시할 만한 수준이며, 네트워크 전송은 13% 감소한다는 것을 보여준다.
2. Isolation vs. Sharing in Serverless
격리 vs serverless 에서 공유
메모리 공유는 격리라는 목표와 근본적으로 상충되므로
멀티 테넌트 serverless 환경에서 메모리 내 상태에 대한 공유 액세스를 제공하는 것은 어려운 과제이다.

표 1은 컨테이너와 VM을 다른 잠재적인 serverless 격리 옵션,
즉 최소한의 VM 이미지를 사용하여 하이퍼바이저 및 software fault isolation(SFI)에서
작업을 촘촘하게 packing 하는 unikernel 과 비교하여
정적 분석, 계측 및 런타임 트랩을 통해 경량 메모리 안전성을 제공한다.
이 표에는 각각 메모리 안전, 리소스 격리 및 메모리 내 상태의 공유라는
세 가지 주요 기능 요구 사항을 충족하는지 여부가 나와 있다.
네 번째 요구사항은 function 간에 파일 시스템을 공유하는 기능으로,
레거시 코드에 중요하며 공유 파일과의 중복을 줄이는 것이다.
이 표는 또한 non-functional 요구사항 집합에서 다음과 같은 옵션을 비교한다.
빠른 탄력성을 위한 짧은 초기화 시간, 확장성 및 효율성을 위한 작은 메모리 공간,
다양한 프로그래밍 언어 지원.
컨테이너는 효율적인 상태 공유를 희생할 경우 허용 가능한 특성의 balance 를 제공한다.
따라서 많은 serverless 플랫폼에서 사용된다.
Amazon은 컨테이너와 유사한 속성 (예: 수백 밀리초 단위의 초기화 시간 및
메가바이트 단위의 메모리 오버헤드) 을 가진 KVM 기반 "마이크로 VM"인
Firecracker 을 사용한다.
컨테이너와 VM은 가상화 수준 때문에 초기화 시간 및 메모리 설치 공간에서
Unikernel 및 SFI에 비해 성능이 떨어진다.
둘 다 완벽한 가상화 POSIX 환경을 제공하며 VM은 하드웨어도 가상화한다.
Unikernel 은 가상화 수준을 최소화하지만, SFI는 가상화 수준을 제공하지 않는다.
그러나 많은 Unikernel 구현에는 production serverless 플랫폼에 필요한 maturity 가 부족하다.
예를 들어, 필요한 도구 및 비전문가가 사용자 지정 이미지를 배포할 수 있는 방법이 없다.
메모리 안전에 초점을 맞추고 있기 때문에 SFI만으로는 자원 격리를 제공할 수 없다.
또한 기본 호스트와 격리된 상호 작용을 수행하는 방법도 정의하지 않는다.
결정적으로 컨테이너 및 VM과 마찬가지로 Unikernel 과 SFI 모두 region 간에 공유 메모리 영역을
표현할 방법이 없기 때문에 상태를 효율적으로 공유할 수 없다.
2.1 Improving on Containers
컨테이너 개선
컨테이너의 serverless function 은 일반적으로 외부 스토리지를 통해 상태를 공유하고
function 인스턴스 간에 데이터를 복제한다.
데이터 액세스 및 직렬화는 네트워크 및 컴퓨팅 오버헤드를 초래한다.
중복은 이미 컨테이너의 메모리 공간을 메가바이트 정도 증가시킨다.
컨테이너는 초기 요청 및 확장 시 발생하는 cold start latency 에 수백 밀리 초에서 최대 수 초를 기여한다.
기존 작업에서는 function 간에 컨테이너를 재활용하고, 정적 VM을 도입하고, 스토리지 지연 시간을 줄이고,
초기화를 최적화하여 이러한 단점을 완화하려고 노력했다.
컨테이너를 재활용하면 초기화 오버헤드가 방지되고 데이터 캐싱이 가능하지만
격리 및 멀티 테넌시(Multi-tenancy)가 희생된다.
PyWren 과 그 후손인 Numpywren, IBMPywren 및 Locus 는
Python function 을 동적으로 로드하고 실행하는 수명이 긴 AWS Lambda function 과 함께
재활용 컨테이너를 사용한다.
Crucial 은 동일한 JVM에서 여러 function 을 실행하는 유사한 접근 방식을 취한다.
SAND 및 Cloudburst 는 동일한 어플리케이션의 function 간에만 프로세스 격리를 제공하고
적어도 하나의 추가 백그라운드 스토리지 프로세스와 함께 공유 장기 실행 컨테이너에 배치한다.
여러 function 과 추가 장기 실행 서비스에 컨테이너를 사용하려면
동시 실행과 최대 사용량 모두에 대한 용량을 보장하기 위해 과도하게 프로비저닝된 메모리가 필요하다.
이것은 serverless 에서 fine-grained scaling 이라는 아이디어와 상반된다.
외부 저장소를 처리하기 위해 정적 VM을 추가하면 성능이 향상되지만 serverless 패러다임은 깨진다.
Cirrus 는 대규모 VM 인스턴스를 사용하여 맞춤형 스토리지 백엔드를 실행한다.
Shredder 는 저장 및 function 실행 모두에 단일 장기 실행 VM을 사용한다.
ExCamera 는 function poll 을 조정하기 위해 장기 실행 VM을 사용한다.
사용자나 공급자는 function 의 탄력성과 병렬성에 맞게 이러한 VM을 확장해야 하므로
복잡성과 비용이 추가된다.
auto-scaled 저장소의 대기 시간을 줄이면 serverless 패러다임 내에서 성능이 향상될 수 있다.
Pocket 은 임시 serverless 스토리지를 제공한다.
AWS Step Functions, Azure Durable Functions 및 IBM Composer 와 같은 다른 클라우드 공급자는
managed external state 를 제공한다.
그러나 이러한 접근 방식은 데이터 전달 문제와 관련 네트워크 및 메모리 오버헤드를 해결하지 못한다.
표준 컨테이너에서 몇 초의 대기 시간을 유발할 수 있는 cold start 문제를 완화하기 위해
컨테이너 초기화 시간이 단축되었다.
SOCK 은 수백 밀리초의 짧은 시간에 cold start 를 달성하기 위해 컨테이너 부팅 프로세스를 개선한다.
Catalyzer 및 SEUSS 는 밀리초 serverless cold start 를 달성하기 위해
VM 및 unikernel 에서 스냅샷 및 복원을 보여준다.
이러한 감소가 유망하긴 하지만 기본 메커니즘에서 리소스 오버헤드와 메모리 공유에 대한 제한은
여전히 남아 있다.
2.2 Potential of Software-based Isolation
소프트웨어 기반 격리의 가능성
소프트웨어 기반 격리 는 컨테이너 및 VM보다 최대 2배 낮은 초기화 시간과 메모리 오버헤드로
메모리 안전을 제공한다. 이러한 이유로 serverless 격리를 위한 매력적인 출발점이다.
그러나 소프트웨어 기반 격리만으로는 리소스 격리 또는 효율적인 메모리 내 상태 공유를 지원하지 않는다.
기존의 여러 edge 및 serverless 컴퓨팅 시스템에서 사용되었지만 이러한 단점을 해결한 제품은 없다.
Fastly의 Terrarium 및 Cloudflare Workers 는 각각 WebAssembly 및 V8 Isolates 로
메모리 안전을 제공하지만 CPU 또는 네트워크 사용을 분리하지 않으며 둘 다 상태 액세스를 위해
데이터 전달에 의존한다.
Shredder 는 또한 V8 격리를 사용하여 스토리지 서버에서 코드를 실행하지만
리소스 격리를 처리하지 않으며 단일 호스트에서 상태와 function 을 함께 배치하는 데 의존한다.
이로 인해 serverless 플랫폼에 필요한 규모 수준에는 부적합하다.
Boucher et al 등은 Rust 마이크로서비스에 대한 마이크로초 초기화 시간을 보여주지만
격리 또는 상태 공유는 다루지 않는다.
Krustlet 은 Knative 와 통합될 수 있는 Kubernetes 의 Docker 를 대체하기 위해
WebAssembly를 사용하는 최근 프로토타입이다.
그러나 컨테이너 기반 격리 복제에 중점을 두므로 메모리 내 공유에 대한 요구 사항을 충족하지 못한다.
우리의 최종 non-functional 요구사항은 multi-language support 에 대한 것인데,
이는 소프트웨어 기반 격리에 대한 언어별 접근법으로는 충족되지 않는다.
Portable Native Client 는 portable intermediate representation 인 LLVM IR 을 대상으로 하여
multi-language 소프트웨어 기반 격리를 제공하므로 이 요구 사항을 충족한다.
Portable Native Client는 이제 WebAssembly를 후속으로 하여 더 이상 사용되지 않는다.
WebAssembly는 0부터 오프셋으로 참조되는 단일 선형 바이트 배열에 대한 메모리 액세스를 제한함으로써
강력한 메모리 안전 보장을 제공한다.
이렇게 하면 trap 을 통해 지원되는 런타임 검사와 함께 컴파일 및 런타임 모두에서
효율적인 bound 검사가 가능하다.
이러한 트랩(및 잘못된 function 을 참조하기 위한 기타)은 WebAssembly 런타임의 일부로 구현된다.
WebAssembly의 보안 보장은 formal verification, taint tracking, 동적 분석을 다루는
기존 문헌에 잘 확립되어 있다.
WebAssembly 는 C, C++, C#, Go 및 Rust 와 같은 LLVM 프런트엔드가 있는 언어에 대한
mature 한 지원을 제공하는 반면 Typescript 및 Swift 에 대한 툴체인이 존재한다.
Java 바이트 코드는 변환이 가능하며, Python, JavaScript 및 Ruby와 같은
WebAssembly에 대한 언어 런타임을 컴파일하여 추가 언어 지원이 가능하다.
WebAssembly는 32비트 주소 공간으로 제한되지만 64비트 지원은 개발 중이다.
WebAssembly 사양에는 메모리 공유를 위한 메커니즘이 아직 포함되어 있지 않으므로,
이것만으로는 요구사항을 충족할 수 없다.
WebAssembly 에 동기화된 공유 메모리의 형태를 추가하자는 제안이 있지만,
모든 공유 영역에 대한 컴파일 타임 지식이 필요하기 때문에
serverless 상태를 동적으로 공유하기에는 적합하지 않다.
또한 관련 프로그래밍 모델이 없으며 로컬 메모리 동기화만 제공한다.
소프트웨어 기반 격리의 속성은 컨테이너, VM 및 unikernel 에 대한 강력한 대안을 강조하지만
이러한 접근 방식은 모든 요구사항을 충족하지 못한다.
따라서 빅데이터를 위한 효율적인 serverless 컴퓨팅을 지원하는 새로운 격리 방식을 제안한다.
3. Faaslets
효율적인 데이터 집약적인 serverless 컴퓨팅에 대한 모든 요구 사항을 충족하는 새로운 격리 메커니즘인
Faaslets 를 제안한다.
Tab. 1은 Faaslet 의 강력한 메모리 및 리소스 격리 보장과 효율적인 메모리 내 공유 상태를 강조한다.
Faaslet은 serverless 작업, 메모리 관리, 제한된 파일 시스템 및 네트워크 액세스를 지원하는
Host interface 를 통해 최소 수준의 경량 가상화를 제공한다.
non-functional 요구사항 측면에서 Faaslet은 메모리 footprint 가 200KB 미만이고
cold start 초기화 시간이 10ms 미만이기 때문에 컨테이너 및 VM을 개선한다.
Faaslet은 IR 보안을 위해 컴파일된 function 을 실행하여 여러 프로그래밍 언어를 지원할 수 있다.
Faaslet은 순수한 SFI만큼 빠르게 초기화할 수는 없지만 Pro-Faaslets 라는 스냅샷에서 미리 초기화를 통해
cold start 문제를 완화한다.
Proto-Faaslet 은 초기화 시간을 수백 마이크로초로 단축하고 호스트 전체에서 단일 스냅샷을 복원하여
클러스터에서 수평으로 빠르게 확장할 수 있다.
3.1 Overview
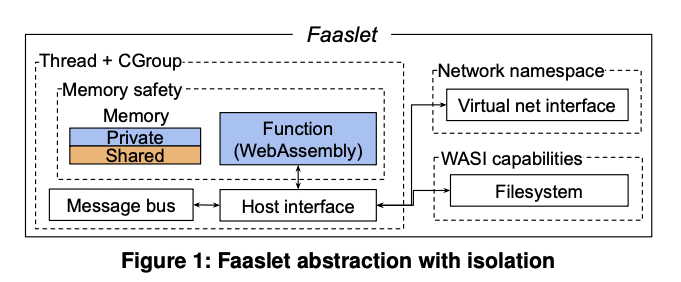
그림 1은 Faaslet 내부에서 격리된 function 을 보여준다.
function 자체는 WebAssembly 로 컴파일되어 메모리 안전 및 제어 흐름 무결성을 보장한다.
기본적으로 function 은 자체적인 연속 메모리 영역에 배치되지만,
Faaslet 은 메모리의 공유 영역도 지원한다.
이를 통해 Faaslet 은 WebAssembly 의 메모리 안전 보장의 제약 내에서 공유 메모리 상태에 접근할 수 있다.
Faaslet은 또한 공정한 자원 접근을 보장한다. CPU 격리의 경우 Linux cgroup 의 CPU subset 을 사용한다.
각 function 은 공유 런타임 프로세스의 전용 스레드에 의해 실행된다.
이 스레드는 모든 Faaslet 과 동일한 CPU 공유를 가진 cgroup 에 할당된다.
Linux CFS 는 이러한 스레드가 동일한 CPU time 으로 스케줄되도록 보장한다.
Faaslet은 네트워크 네임스페이스, 가상 네트워크 인터페이스 및 트래픽 쉐이핑을 사용하여
안전하고 공정한 네트워크 액세스를 달성한다.
각 Faaslet은 iptables 규칙을 사용하여 구성된 별도의 네임스페이스에 자체 네트워크 인터페이스를 가지고 있다.
colocation 된 테넌트 간의 공정성을 보장하기 위해 각 Faaslet은 tc를 사용하여
가상 네트워크 인터페이스에 트래픽 쉐이핑을 적용하여 송수신 트래픽 속도 제한을 적용한다.
메모리 관리와 입출력 작업을 수행하기 위해 표준 system call 을 호출하는 것이 허용되어야 하기 때문에,
Faaslet 은 기본 호스트와 상호 작용할 수 있는 인터페이스를 제공한다.
컨테이너나 VM과 달리 Faaslet은 완전히 가상화된 POSIX 환경을 제공하지 않고
대신 최소한의 serverless 전용 호스트 인터페이스를 지원한다(그림 1 참조).
Faaslet은 아래에 설명된 대로 기본 호스트와 상호 작용하고
다양한 기능을 노출하는 system call 을 가상화한다.
호스트 인터페이스는 메시지 버스를 통해 serverless 런타임과 통합된다(그림 1 참조).
메시지 버스는 Faaslets 가 부모 프로세스 및 서로 통신하고, function call 을 수신하고,
작업을 공유하고, 다른 function 을 call 하고, 대기하고,
생성 및 종료 시점을 상위 프로세스에 알리는 데 사용된다.
Faaslet은 global object store(§5)에서 파일을 읽고 로컬에 캐시된 파일 버전에 쓸 수 있는
read-global wirte-local 파일 시스템을 지원한다.
이것은 주로 레거시 어플리케이션,
특히 라이브러리 코드를 로드하고 중간 바이트코드를 저장하기 위한 파일 시스템이 필요한 CPython 과 같은
언어 런타임을 지원하는 데 사용된다.
파일 시스템은 WASI 기능 기반 보안 모델을 구현하는 POSIX 와 유사한 API functions set 을 통해
액세스할 수 있으며, 이는 위조 불가능한 파일 핸들을 통해 효율적인 격리를 제공한다.
따라서 계층화된 파일 시스템 또는 chroot 와 같은 리소스 집약적인 파일 시스템을 격리할 필요가 없으며,
그렇지 않으면 cold start 대기 시간이 추가된다.
3.2 Host Interface
Faaslet 호스트 인터페이스는 기존 POSIX 어플리케이션뿐만 아니라
다양한 serverless 빅데이터 어플리케이션을 실행할 수 있는 가상화 계층을 제공해야 한다.
이 인터페이스는 반드시 메모리 안전 bound 밖에서 작동하므로
호스트와 상호 작용할 때 격리를 유지하도록 신뢰될 수 있다.
컨테이너 및 VM 기반의 기존 serverless 플랫폼에서 이 가상화 계층은 표준 POSIX 환경이며
HTTP를 통해 언어 및 공급자별 API를 통해 serverless 작업이 실행된다.
관련된 격리 메커니즘으로 전체 POSIX 환경을 인스턴스화하면 초기화 시간이 길어지고
HTTP API 를 많이 사용하면 지연 시간과 네트워크 오버헤드가 증가한다.
대조적으로, Faaslet 호스트 인터페이스는 최소한의 가상화를 목표로 하므로
격리를 제공하는 데 필요한 오버헤드를 줄인다.
호스트 인터페이스는 다양한 고성능 serverless 어플리케이션을 지원하기 위해 특별히 제작된 로우레벨 API이다.
호스트 인터페이스는 런타임에 functions 코드와 동적으로 연결되어
외부 API를 통해 동일한 작업을 수행하는 것보다 인터페이스를 호출하는 것이 더 효율적이다.

Tab. 2 는 다음을 지원하는 Faaslet host interface API 를 나열한다.
- 체인된 serverless function 호출
- 공유 상태와의 상호 작용
- 메모리 관리, timing, 난수, 파일/네트워크 I/O 및 동적 연결에 대한 POSIX 유사 호출의 subset
이러한 POSIX와 유사한 호출의 subset 은 서버 측 WebAssembly 인터페이스에 대한 새로운 표준인
WASI에 따라 구현된다.
API의 일부 주요 세부 정보는 다음과 같다.
- Function invocation.
function 은 read_call_input 함수를 사용하여 바이트 배열로 직렬화된 입력 데이터를 검색하고,
마찬가지로 write_call_output 을 사용하여 출력 데이터를 바이트 배열로 쓴다.
바이트 배열은 언어에 구애받지 않는 일반적인 인터페이스를 구성한다.
Non-trivial serverless 어플리케이션은 chain_call function 으로 만들어진,
chained call 의 일부로 함께 작동하는 여러 function 을 호출한다.
사용자의 function 은 고유한 이름을 가지며, 호출을 위한 입력 데이터를 포함하는 바이트 배열과 함께
chain_call 로 전달된다. chain_call 에 대한 호출은 호출된 function 의 호출 ID를 반환한다.
호출 ID는 wait_call로 전달되어 다른 호출이 완료되거나 실패할 때까지 차단 대기를 수행하여
반환 코드를 산출할 수 있다.
Faaslet 은 function 이 완료될 때까지 차단하고, 동일한 호출 ID를 get_call_output으로 전달하여
chained call 의 출력 데이터를 검색한다.
chain_call 및 wait_call 에 대한 호출은 표준 다중 스레드 코드와 비슷한 방식으로
호출을 생성하고 대기하는 루프에서 사용될 수 있다.
우리는 Listing 1의 파이썬에서 이 패턴을 보여준다.
- Dynamic linking.
일부 레거시 어플리케이션과 라이브러리는 동적 링크에 대한 지원이 필요하다.
예를 들어, Cpython 은 Python 확장을 동적으로 링크한다.
동적으로 로드된 모든 코드는 먼저 WebAssembly 로 컴파일되어야 하며
다른 사용자 정의 코드와 동일한 유효성 검사 과정을 거쳐야 한다.
이러한 모듈은 표준 Faaslet 파일 시스템 추상화를 통해 로드되며
상위 function 과 동일한 안전 보장에 의해 다뤄진다.
Faaslet은 WebAssembly 동적 링크 규약에 따라 구현되는 표준 POSIX 동적 링크 API를 통해 이를 지원한다.
- Memory.
function 은 직접 또는 dlmalloc 를 통해, mmap()와 brk()에 대한 호출을 통해 동적으로 메모리를 할당한다.
Faaslet은 개인 메모리 영역에 메모리를 할당하고,
필요하면 기본 호스트에서 mmap을 사용하여 영역을 확장한다.
각 function 은 미리 정의된 메모리 제한을 가지고 있으며,
개인 영역의 성장이 이 제한을 초과할 경우 이러한 호출이 실패한다.
- Networking.
지원되는 네트워킹 call 의 subset 은 간단한 클라이언트 측 송수신 작업을 허용하며
외부 데이터 저장소 또는 원격 HTTP endpoint 연결과 같은 일반적인 사용 사례에 충분하다.
소켓, 커넥트, 바인드 function 을 통해 데이터를 읽고 쓸 때 소켓을 설정할 수 있다.
call 은 IPv4/IPv6 (예를 들어, AF_)을 통한 단순한 송신/수신 작업과 관련이 없는 플래그를 전달하면
실패한다. 예, AF_UNIX flag.
호스트 인터페이스는 이러한 call 을 호스트의 동등한 소켓 작업으로 변환한다.
모든 call 은 Faaslet의 가상 네트워크 인터페이스와 배타적으로 상호 작용하므로
사설 네트워크 인터페이스로 제한되며 트래픽 조절 규칙으로 인해 속도 제한을 초과할 수 없다.
- Byte arrays.
function 입력, 결과, 상태는 모든 function 메모리와 마찬가지로 단순한 바이트 배열로 표현된다.
이를 통해 API를 통과하는 동안 데이터를 직렬화하고 복사할 필요가 없으며
임의로 복잡한 메모리 내 데이터 구조를 공유하는 것이 간단해진다.
3.3 Shared Memory Regions
섹션 2에서 논의한 바와 같이, 효율적인 serverless 빅데이터 어플리케이션을 위해서는
메모리 내 상태를 공유하는 동시에 격리 상태를 유지하는 것이 중요한 요구사항이다.
Faaslet은 새로운 개념의 공유 영역을 기존 WebAssembly 메모리 모델에 추가하여 이를 수행한다.
공유 영역은 공유 프로세스 메모리의 분리된 세그먼트에 대한 동시 액세스 기능을 제공하여
공유 데이터 구조에 대한 직접적이고 짧은 지연 시간을 허용한다.
공유 영역은 표준 OS 가상 메모리에 의해 지원되어 추가적인 직렬화나 오버헤드가 없으므로
Faaslet은 네이티브 멀티 스레드 어플리케이션과 동등한 수준의 효율적인 동시 액세스를 달성한다.
§4.2에서는 Faaslet이 이 메커니즘을 사용하여
글로벌 상태에 대한 공유 메모리 내 액세스를 제공하는 방법을 설명한다.
공유 영역은 기존 WebAssembly 메모리 모델의 메모리 안전 보장을 유지하며
표준 OS 가상 메모리 메커니즘을 사용한다.
WebAssembly는 각 function 의 메모리를 연속적인 선형 바이트 배열로 제한하며,
프로세스 메모리의 분리된 부분으로부터 런타임에 Faaslet 에 의해 할당된다.
새로운 공유 영역을 만들기 위해, Faaslet은 function 의 선형 바이트 배열을 확장하고,
공통 프로세스 메모리의 지정된 영역에 새로운 페이지를 다시 매핑한다.
function 은 선형 메모리의 새 영역에 정상적으로 액세스하여 메모리 안전을 유지하지만
기본 메모리 액세스는 공유 영역에 매핑된다.
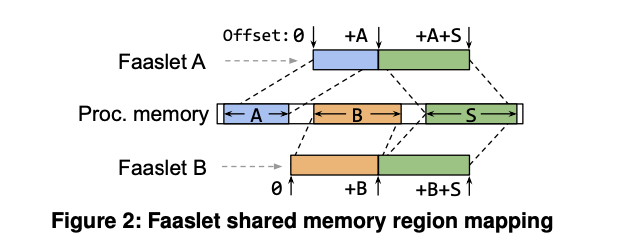
그림 2는 공통 프로세스 메모리의 분리된 영역(중앙 영역으로 표시)에서
할당된 공유 영역(레이블 S)에 액세스하는 Faaslet A와 B를 보여준다.
각 Faaslet은 프로세스 메모리로부터 할당된 자체적인 개인 메모리 영역(레이블 A와 B)을 가지고 있다.
각 Faaslet 내부의 function 은 0부터 오프셋으로 모든 메모리에 접근하여 단일 선형 주소 공간을 형성한다.
Faaslet은 이러한 오프셋을 개인 영역(이 경우 하위 오프셋) 또는 공유 영역(이 경우 상위 오프셋)에 매핑한다.
다중 공유 영역이 허용되며, 함수는 brk(§3.2)와 같은 호스트 인터페이스의 메모리 관리 기능에 대한 call 을 통해
개인 메모리를 확장할 수 있다.
개인 메모리의 확장과 새로운 공유 영역의 생성은 함수의 메모리를 나타내는 바이트 배열을 확장한 다음,
기본 페이지를 공유 프로세스 메모리의 영역으로 다시 매핑함으로써 처리된다.
이는 function 이 여러 가상 메모리 매핑에 의해 뒷받침될 수 있는,
빽빽하게 채워진 단일 선형 주소 공간을 계속 볼 수 있음을 의미한다.
Faaslet은 기본 호스트에서 mmap call 을 통해 공유 프로세스 메모리를 할당하고
MAP_SHARED 및 MAP_Anonymous 플래그를 전달하여 공유 및 개인 영역을 각각 생성하고
이러한 영역을 mremap으로 다시 매핑한다.
3.4 Building Functions for Faaslets
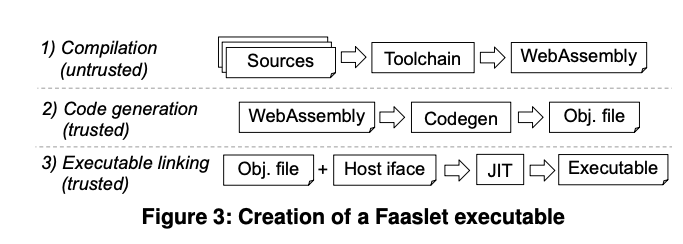
그림 3은 함수의 소스 코드를 Faaslet 실행 파일로 변환하는 3단계를 보여준다.
-
사용자는 Faaslet 툴체인을 호출하여 function 을 WebAssembly 바이너리로 컴파일하여
Faaslet 호스트 인터페이스의 언어별 선언에 대해 링크하고
-
코드 생성은 WebAssembly 에서 기계 코드를 사용하여 객체 파일을 생성한다.
-
호스트 인터페이스 정의는 기계 코드와 연결되어 Faaslet 실행 파일을 생성한다.
Faaslet 이 배포되면 WebAssembly 바이너리를 생성하기 위한 컴파일 단계가 사용자의 컴퓨터에서 수행된다.
이는 신뢰할 수 없으므로, 코드 생성 단계는 WebAssembly 규격에서 정의된 대로
WebAssembly 바이너리를 검증함으로써 시작된다.
이렇게 하면 바이너리가 사양을 준수하는지 확인할 수 있다.
그런 다음 사용자가 function 을 업로드한 후 신뢰할 수 있는 환경에서 코드가 생성된다.
링크 단계에서 Faaslet 은 LLVM JIT 라이브러리를 사용하여
객체 파일과 호스트 인터페이스 구현의 정의를 링크한다.
호스트 인터페이스 함수는 thunk 로 정의되며, 이를 통해 신뢰할 수 있는 호스트 인터페이스 구현을
function 바이너리에 주입할 수 있다.
Faaslet 은 검증, 코드 생성 및 링크를 수행하기 위해 WAVM 을 사용한다.
WAVM 은 오픈 소스 WebAssembly VM으로 WebAssembly 적합성 테스트를 통과하여
결과 실행 파일이 메모리 안전 및 제어 흐름 무결성을 적용함을 보증한다.
4. Local and Global State
Stateful serverless 어플리케이션은 편리한 고급 상태 인터페이스를 노출하는,
언어별 클래스인 분산 데이터 개체(DDO)를 사용하여 Faaslet 으로 생성할 수 있다.
DDO는 Tab. 2 의 키/값 상태 API를 사용하여 구현된다.
Faaslet과 관련된 상태는 로컬 공유와 상태의 글로벌 배포를 결합하는 2계층 접근 방식을 사용하여 관리된다.
로컬 계층은 동일한 호스트의 상태에 대한 공유 인메모리 액세스를 제공한다.
전역 계층을 통해 Faaslet은 호스트 간에 상태를 동기화할 수 있다.
DDO는 2계층 상태 아키텍처를 숨기고 분산 데이터에 대한 투명한 액세스를 제공한다.
그러나 함수는 일관성 및 동기화를 보다 세부적으로 제어하거나
사용자 지정 데이터 구조를 구현하기 위해 상태 API에 직접 액세스할 수 있다.
4.1 State Programming Model
각 DDO는 해당 상태 키를 보유하는 문자열을 사용하여 시스템 전체에서 참조되는 단일 상태 값을 나타낸다.
Faaslet은 push 를 수행하여 로컬에서 글로벌 계층으로 변경사항을 작성하고
pull 작업을 수행하여 글로벌에서 로컬 계층으로 읽는다.
DDO는 결국 일관된 목록 또는 집합에서 업데이트를 지연시키는 것과 같은 가변 일관성을 생성하기 위해
push 및 pull 작업을 사용할 수 있으며, 분산 dictionary 와 같이 액세스될 때만 값을 느리게 가져올 수 있다.
특정 DDO는 불변하므로 반복적인 동기화를 피한다.

Listing 1 은 파이썬에서 확률적 경사 강하(SGD)를 구현하기 위해
DDO를 통한 2계층 상태의 암시적 및 명시적 사용을 보여준다.
weight_update 함수는 SparseMatrixReadOnly 및 MatrixReadOnly DDO(라인 1 및 2)를 통해
두 개의 큰 입력 매트릭스와 VectorAsync(라인 3)를 사용하여 단일 공유 가중치 벡터에 액세스한다.
VectorAsync는 주기적으로 로컬 계층에서 글로벌 계층(라인 13)으로 업데이트를 push 하는 데 사용되는
push() 함수를 표시한다.
weight_update에 대한 호출은 sgd_main(줄 19)의 loop 에 연결되어 있다.
weight_update 함수는 열 속성(7행과 8행)을 사용하여
training matrix 에서 임의로 할당된 하위 열 집합에 액세스한다.
DDO는 암시적으로 데이터가 존재하는지 확인하기 위해 pull 작업을 수행하고
로컬 계층에서 상태 값의 필요한 부분 집합만 복제한다. 즉, 전체 매트릭스가 불필요하게 전송되지 않는다.
4.2 Two-Tier State Architecture
Faaslet 은 상태 값을 참조하기 위해 고유한 상태 키를 사용하여 키/값 추상화로 상태를 나타낸다.
각 키에 대한 권한 있는 상태 값은 KVS(분산 key-value 저장소)가 뒷받침하고
클러스터의 모든 Faaslet 이 액세스할 수 있는 글로벌 계층에 저장된다.
주어진 호스트의 Faaslet은 로컬 계층을 공유하며,
해당 호스트의 Faaslet 에 현재 매핑된 각 상태 값의 복제본을 포함한다.
로컬 계층은 Faaslet 공유 메모리 영역에서 독점적으로 관리되며,
Faaslet은 SAND 또는 Cloudburst 에서와 같이 별도의 로컬 스토리지 서비스를 가지고 있지 않는다.
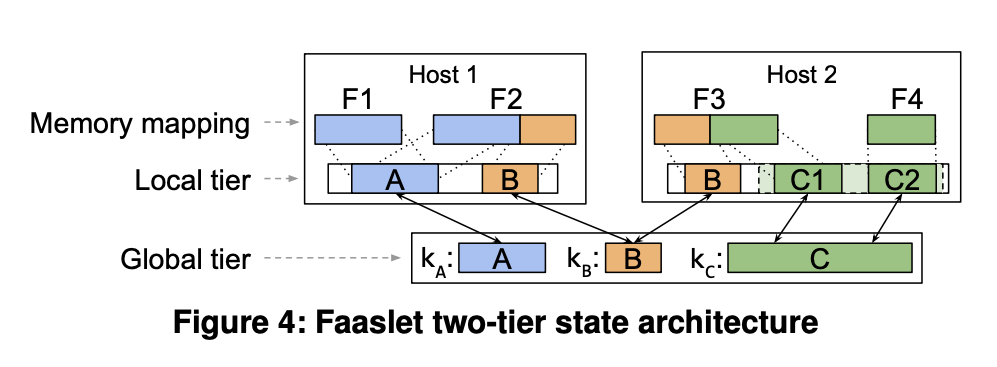
그림 4는 두 호스트에 걸친 2계층 상태 아키텍처를 보여준다.
호스트 1의 Faaslet 은 상태 값 A를 공유하고, 두 호스트의 Faaslet 은 상태 값 B를 공유한다.
따라서 호스트 1의 로컬 계층에는 상태 값 A의 복제본이 있고
두 호스트의 로컬 계층에는 상태 값 B의 복제본이 있다.
Ensuring local consistency.
로컬 계층의 상태 값 복제본은 Faaslet 공유 메모리(§3.3)를 사용하여 생성된다.
복제본에 접근하는 Faaslet들 간의 일관성을 보장하기 위해,
Faaslets는 읽을 때 로컬 읽기 lock 을 획득하고 쓸 때 로컬 쓰기 lock 을 획득한다.
이 lock 은 모든 상태 API 함수의 일부로 암시적으로 발생하지만
function 이 포인터를 통해 로컬 복제본에 직접 쓰는 경우에는 발생하지 않는다.
상태 API는 로컬 lock 을 명시적으로 획득하는 데 사용할 수 있는
lock_state_read 및 lock_state_write 함수를 노출한다.
요소를 원자적으로 추가할 때 상태 값에 여러 쓰기를 수행하는 목록을 구현한다.
Faaslet은 pull_state 또는 get_state가 없는 경우 호출 후 새 로컬 복제본을 생성하고
쓰기 lock 을 통해 일관성을 보장한다.
Ensuring global consistency.
DDO는 Listing 1의 VectorAsync 에 표시된 것처럼 계층 간 다양한 수준의 일관성을 생성할 수 있다.
DDO는 강력한 일관성을 적용하려면 global 읽기/쓰기 lock 을 사용해야 한다.
이는 각각 lock_state_global_read 및 lock_state_global_write 를 사용하여
각 상태 키에 대해 획득 및 해제할 수 있다.
global 계층에 일관된 쓰기를 수행하기 위해 객체는 global 쓰기 lock 을 획득하고
pull_state 를 호출하여 로컬 계층을 업데이트하고, 쓰기를 로컬 계층에 적용하고,
push_state 를 호출하여 글로벌 계층을 업데이트한 다음 lock 을 해제한다.
5. Faasm Runtime
Faasm 은 클러스터 전체에서 분산 Stateful serverless 응용 프로그램을 실행하기 위해
Faaslet 을 사용하는 serverless 런타임이다.
Faasm 은 기본 인프라, auto-scaling functionality 및
사용자 대면 프런트엔드를 제공하는 기존 serverless 플랫폼과 통합되도록 설계되었다.
Faasm 은 Faaslet 의 일정, 실행, 상태 관리를 관리한다.
Faasm 의 설계는 분산 아키텍처를 따른다:
여러 개의 Faasm 런타임 인스턴스가 서버 집합에서 실행되며, 각 인스턴스는 Faaslet 풀을 관리한다.
5.1 Distributed Scheduling
Faasm 런타임의 로컬 스케줄러는 Faaslet 의 스케줄링을 담당한다.
스케줄링 전략은 executed function 이 필요한 메모리 내 상태와 함께 배치되도록 함으로써
데이터 전송(섹션2 참조)을 최소화하는 데에 중요하다.
런타임 인스턴스에 의해 관리되는 하나 이상의 Faaslet 은 warm 일 수 있다.
스케줄링 목표는 warm Faaslet 에 의해 가능한 많은 function call 이 실행되는 것을 보장하는 것이다.
기본 플랫폼의 스케줄러에 대한 수정 없이 이를 달성하기 위해,
Faasm 은 오메가(Omega)와 유사한 분산 공유 상태 스케줄러를 사용한다.
function call 은 로컬 스케줄러로 라운드 로빈이 전송되며,
warm 및 용량이 있는 경우 함수를 로컬로 실행하거나, 다른 warm 호스트와 공유한다.
각 function 에 대한 warm 호스트 집합은 Faasm 상태 global 계층에서 유지되며,
각 스케줄러는 스케줄링 결정 중에 이 집합을 query 하고 원자적으로 업데이트할 수 있다.
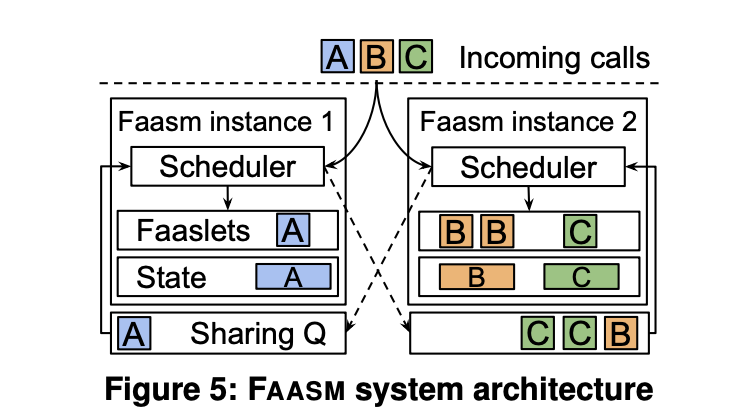
그림 5는 각각 자체 로컬 스케줄러, Faaslet 풀, 메모리에 저장된 상태 collection 및
공유 큐를 가진 두 개의 Faasm 런타임 인스턴스를 보여준다.
A-C 함수에 대한 호출은 로컬 스케줄러에 의해 수신되며,
로컬 스케줄러는 warm Faaslet이 있으면 로컬로 실행하고 없으면 다른 호스트와 공유한다.
인스턴스 1은 함수 A에 대한 warm Faaslet 을 가지고 있으며 이 함수에 대한 호출을 받아들이는 반면,
해당 warm Faaslet 을 가진 인스턴스 2와 함수 B와 C에 대한 호출을 공유한다.
만약 함수 호출이 수신되고 warm Faaslet 이 있는 인스턴스가 없다면,
호출을 받은 인스턴스는 "cold start"를 발생시키는 새로운 Faaslet 을 생성한다.
5.2 Reducing Cold Start Latency
일반적으로 Faaslet 은 10ms 이내에 초기화되지만,
Faasm 은 클러스터의 모든 호스트에서 복원할 수 있는 임의 실행 상태의 스냅샷을 포함하는
Proto-Faaslet 을 사용하여 이를 더 감소시킨다.
이 스냅샷에서 Faasm 은 일반적으로 초기화를 수백 마이크로초(µ6.5)로 줄이는
새로운 Faaslet 인스턴스를 생성한다.
스냅샷 전에 실행되는 사용자 정의 초기화 코드를 지정함으로써
함수에 대해 서로 다른 Proto-Faaslet 이 생성된다.
만약 함수가 호출할 때마다 동일한 코드를 실행한다면,
그 코드는 초기화 코드가 되어 함수 자체에서 제거될 수 있다.
동적 언어 런타임 기능이 있는 Faaslet의 경우, 런타임 초기화는 초기화 코드의 일부로 수행될 수 있다.
Proto-Faaslet 스냅샷에는 WebAssembly 사양에 정의된 대로
함수의 스택, 힙, 함수 테이블, 스택 포인터 및 데이터가 포함된다.
WebAssembly 메모리가 스택, 힙, 데이터를 포함하는 연속적인 바이트 배열로 표현되기 때문에,
Faasm 은 쓰기 시 복사 메모리 매핑을 사용하여 스냅샷을 새로운 Faaslet 으로 복원한다.
다른 모든 데이터는 표준 C++ 객체에 보관된다.
스냅샷이 기본 OS 스레드나 프로세스와 독립적이기 때문에
Faasm 은 Proto-Faaslet 을 직렬화하고 호스트 전체에서 인스턴스화할 수 있다.
Faasm 은 HTTP endpoint 를 노출하는 업로드 서비스를 제공한다.
사용자는 WebAssembly 바이너리를 이 endpoint 에 업로드한 다음 코드 생성(3.4)을 수행하고
결과 객체 파일을 공유 객체 저장소에 기록한다.
이 store 의 구현은 기본 serverless 플랫폼에만 한정되지만 AWS S3 와 같은
클라우드 프로바이더 고유의 솔루션이 될 수 있다.
이 과정의 일환으로 Faasm global 상태 계층에 Proto-Faaslet 이 생성되어 저장된다.
Faaslet은 Cold Start 를 거치면 객체 파일과 Proto-Faaslet 을 로드하여 복구한다.
또한, Faasm 은 각 function 호출 후 Faaslets 를 재설정하기 위해 Proto-Faaslets 를 사용한다.
Proto-Faaslet 는 함수의 초기화된 실행 상태를 캡처하므로,
이를 복구하면 이전 호출로부터의 정보가 공개되지 않음을 보장한다.
serverless 웹 응용 프로그램과 같은 멀티 테넌트 기능에 사용할 수 있다.
Faasm 은 각 함수 실행 후 메모리에 저장된 개인 데이터가 지워지는 것을 보장하며,
따라서 Faaslet이 테넌트 전체에서 후속 호출을 처리할 수 있게 한다.
컨테이너 기반 플랫폼에서는 일반적으로 안전하지 않습니다.
플랫폼이 호출 사이에 컨테이너 메모리가 완전히 정리되었는지 확인할 수 없기 때문이다.
6. Evaluation
우리의 실험 평가는 다음과 같은 질문을 대상으로 한다:
- Faasm 상태 관리가 병렬 머신러닝 훈련의 효율성과 성능을 어떻게 향상시키는가?
- Proto-Faaslet 와 낮은 초기화 시간이 추론 서비스 수행의 성능과 처리량에 어떻게 영향을 미치는가? (§6.3)
- Faaslet 격리는 동적 언어 런타임을 사용하는 선형 대수 벤치마크에서 성능에 어떤 영향을 주는가? (§6.4)
- Faaslet의 오버헤드는 Docker 컨테이너와 어떻게 비교되는가? (§6.5)
6.1 Experimental Set-up
Serverless baseline.
최첨단 serverless 플랫폼에 대해 Faasm 을 벤치마킹하기 위해,
우리는 Kubernetes 을 기반으로 구축된 컨테이너 기반 시스템인 Knative 을 사용한다.
모든 실험은 컨테이너 기반 코드에 대한 Faaslet 호스트 인터페이스의 Knative 고유의 구현과 함께
Faasm 과 Knative 모두에 대해 동일한 코드를 사용하여 구현된다.
이 인터페이스는 Faasm 과 동일한 상태 관리 코드를 사용하지만
배치된 function 간의 로컬 계층을 공유할 수 없다.
표준 Knative API를 통해 Knative 함수 체인을 수행한다.
Redis는 분산 KVS에 사용되며 동일한 클러스터에 배포된다.
FAASM integration.
default autoscaler 를 사용하여 복제되는 Knative function 으로
Faasm 런타임 인스턴스를 실행하여 Faasm 과 Knative를 통합한다.
시스템은 기본 엔드포인트 및 스케줄러를 사용하여 수정되지 않는다.
Testbed.
FAASM과 Knative 어플리케이션은 동일한 쿠버네티스 클러스터에서 실행되며, 20개의 호스트에서 실행되고,
모든 인텔 Xeon E3-1220 3.1 GHz 시스템은 16GB RAM을 갖추고 1Gbps 연결로 연결된다.
섹션 6.5에서의 실험은 32 GB 램을 가진 단일 인텔 제온 E5-2660 2.6 GHz 머신에서 실행되었다.
Metrics.
실행 시간, 처리량 및 대기 시간과 같은 일반적인 평가 메트릭 외에도,
시간에 따른 메모리 소비를 정량화하는 billable 메모리도 고려한다.
이것은 peak 함수 메모리에 함수의 수와 런타임(GB-second)을 곱한 값이다.
이것은 많은 serverless 플랫폼의 메모리 사용을 귀속시키는 데 사용된다.
모든 메모리 측정에는 컨테이너/Faaslet 및 해당 상태가 포함된다.
6.2 Machine Learning Training
이 실험은 Faasm 의 상태 관리가 런타임, 네트워크 오버헤드 및 메모리 사용에 미치는 영향에 초점을 맞춘다.
우리는 HOGWILD! 알고리즘을 사용하고, 분산 확률적 경사 강하(SGD)를 사용하여
로이터 RCV1 데이터 세트에서 텍스트 분류를 실행한다.
이것은 중앙 가중치 벡터를 여러 epoch 에 걸친 함수 배치와 병렬로 업데이트한다.
우리는 증가하는 수의 병렬 function 으로 Knative와 Faasm 을 모두 실행한다.

그림 6a는 훈련 시간을 보여준다.
Faasm 은 낮은 병렬에서 Knative 에 비해 런타임에서 10% 소폭 향상되고
15개의 병렬 함수에서 60% 향상되었다.
20개 이상의 병렬 Knative function 으로 기본 호스트는 메모리 pressure 이 증가하며
30개 이상의 function 으로 메모리를 소모한다.
훈련 시간은 Faasm 에 대해 최대 38개의 병렬 function 까지 지속적으로 개선되며,
이때 2개의 function 에 비해 80% 이상 개선된다.
그림 6b는 병렬화가 증가함에 따라, Faasm 과 Knative 모두에서 네트워크 전송량이 증가함을 보여준다.
Knative 는 2개의 병렬 function 으로 145GB, 30개의 function 으로 280GB가 전송되는 등
시작할 데이터가 더 많고 볼륨도 더 빠르게 증가한다.
Faasm 은 2개의 병렬 function 을 가진 75GB와 38개의 병렬 function 을 가진 100GB를 전송한다.
그림 6c는 2개 function 의 경우 1,000GB-sec 에서 30개 function 의 경우 5,000GB-sec 이상으로
Knative의 billable 메모리가 더 병렬적으로 증가한다는 것을 보여준다.
billable time : 청구되는 작업에 대해 소요한 시간
Faasm 의 billable 메모리는 2개 function 의 경우 350GB-sec 에서
38개 function 의 경우 500GB-sec 로 천천히 증가한다.
Knative의 증가된 네트워크 전송, 메모리 사용량 및 지속 시간은 주로
컨테이너에 데이터를 적재하는 것과 같은 데이터 전송에 의해 발생한다.
Faasm 은 로컬 계층을 통해 데이터를 공유함으로써 오버헤드를 상각하고 대기 시간을 단축한다.
기간과 네트워크 오버헤드의 추가적인 개선은 공유 가중치 벡터에 대한 업데이트의 차이에서 비롯된다:
Faasm 에서는 여러 기능의 업데이트가 호스트당 일괄 처리되는 반면,
Knative에서는 각 함수가 외부 스토리지에 직접 기록되어야 한다.
Knative와 Faasm 의 billable 메모리는 병렬화가 진행될수록 증가하지만,
Knative의 메모리 footprint 와 지속 시간이 증가함에 따라 더 뚜렷해진다.
Faasm 과 Knative 의 기본 성능 및 리소스 오버헤드를 격리하기 위해,
우리는 80만 개에서 128개로 줄어든 training 예제 수로 동일한 실험을 실행한다.
32개의 병렬 function 에 걸쳐 Faasm 과 Knative 에 대해 관찰한다.
각각 460ms와 630ms의 training 시간, 19MB와 48MB의 네트워크 전송,
0.01GB-sec 및 0.04GB-sec 의 billable 메모리 사용.
이 경우, Knative의 지속시간 증가는 Knative HTTP API를 통한 function 간 통신의 지연시간과
볼륨으로 인해 발생한다.
Faasm 은 첫 번째 실험에서처럼 Knative 에 비해 네트워크 전송이 감소하지만,
두 시스템 모두에서 이러한 전송의 오버헤드는 작고 모든 function 에 걸쳐 상각되기 때문에 무시할 수 있다.
billable 메모리는 각 function 컨테이너의 메모리 오버헤드가
8MB(각 Faaslet당 270kB에 비해)이기 때문에 Knative 에서 증가된다.
이러한 개선은 전체 데이터 세트의 감소된 데이터 전송 및 복제에서 도출된 것과 비교할 때 미미하다.
6.3 Machine Learning Interence
이 실험은 Faaslet 초기화 시간이 cold start 및 function call 처리량에 미치는 영향을 탐구한다.
머신 러닝 추론 어플리케이션은 일반적으로 사용자 대면형이기 때문에,
대기 시간에 민감하고 대량의 요청을 처리해야 하기 때문에,
우리는 머신 러닝 추론 어플리케이션을 고려한다.
우리는 파일 서버에서 로드되고 사전 훈련된 MobileNet 모델을 사용하고
분류된 이미지를 사용하여 TensorFlow Lite 를 사용하여 추론 서비스를 수행한다.
구현에서 각 사용자의 요청은 기본 serverless function 의 서로 다른 인스턴스로 전송된다.
따라서 각 사용자는 첫 번째 요청 시 cold start 를 보게 된다.
처리량을 늘리고 cold start 비율을 변경할 때 대기 시간 분포와 중앙값 대기 시간의 변화를 측정한다.

그림 7a와 7b는 모든 cold start 비율을 포함하는 Faasm 의 단일 라인을 보여준다.
cold start 는 1ms 미만의 무시해도 될 정도의 지연 시간 패널티만 발생하며
상당한 리소스 경합을 추가하지 않으므로 모든 비율이 동일하게 동작한다.
TensorFlow Lite 컴파일에서 WebAssembly까지의 성능 오버헤드로 인해
추론 계산이 더 오래 걸리기 때문에 Faasm 의 최적 지연 시간이 Knative보다 높다.
그림 7a는 Knative의 중간 지연 시간이 cold start 비율에 따라
특정 처리량 임계값에서 급격히 증가함을 보여준다.
이는 대기 및 리소스 경합을 초래하는 cold start 로 인해 발생하며,
20% cold start 워크로드에 대한 대기 시간 중앙값은 약 20req/s에서 90ms에서 2초 이상으로 증가한다.
Faasm 은 200req/s 이상의 처리량에서 120ms의 중간 대기 시간을 유지한다.
그림 7b는 cold start 비율이 다른 연속 call 을 처리하는 단일 function 에 대한
대기 시간 분포를 보여준다.
Knative는 2초 이상의 tail latency 를 가지며 35% 이상의 call 은 20% cold start 와 함께
500ms 이상의 대기 시간을 갖는다.
Faasm 은 모든 비율에 대해 150ms 미만의 tail latency 를 달성한다.
6.4 Language Runtime Performance with Python
다음 두 실험은
-
기존의 동적 언어 런타임인 Cpython 인터프리터를 사용하여 분산 벤치마크에 대한
Faaslet 격리의 성능 영향을 측정하고,
-
컴퓨팅 마이크로벤치마크와 파이썬 마이크로벤치마크 제품군을 실행하는
단일 Faaslet 에 미치는 영향을 조사한다.
우리는 파이썬과 Numpy 로 구현된 분산 분할-정복 매트릭스 곱셈을 고려한다.
Faasm 구현에서 이러한 함수는 Faaslet 내의 Cpython을 사용하여 실행되며
Knative에서는 표준 Python을 사용한다.
BLAS 와 LAPACK 에 대한 WebAssembly 지원이 없으므로, 두 구현 모두 사용하지 않는다.
이 실험은 계산 집약적이지만 파일 시스템, 동적 링크, 함수 체인 및 상태를 사용하므로
모든 Faaslet 호스트 인터페이스를 사용할 수 있다.
각 행렬 곱셈은 더 작은 하위 행렬의 곱셈으로 세분되고 병합된다.
이 function 은 serverless function 을 재귀적으로 연결함으로써 구현되며,
각 곱셈은 64 곱셈 function 과 9 병합 function 을 사용한다.
우리는 점점 더 큰 행렬의 곱셈을 실행할 때 실행 시간과 네트워크 트래픽을 비교한다.
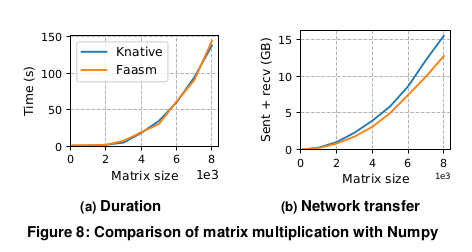
그림 8a는 Faasm 과 Knative에서 매트릭스 곱셈의 지속시간이
매트릭스 크기를 증가시키는 것과 거의 동일함을 보여준다.
둘 다 100×100 행렬의 경우 약 500ms, 8000×8000 행렬의 경우 거의 150초가 소요된다.
그림 8b는 Faasm 이 모든 매트릭스 크기에 걸쳐 네트워크 트래픽을 13% 감소시키므로
중간 결과를 보다 효율적으로 저장함으로써 작은 이점을 얻을 수 있음을 보여준다.
다음 실험에서는 Polybench/C 를 사용하여 간단한 계산 기능에 대한 Faaslet 성능 오버헤드를 측정하고,
보다 복잡한 애플리케이션의 오버헤드에 대한 Python 성능 벤치마크를 사용한다.
Polybench/C는 WebAssembly로 직접 컴파일되어 Faaslet에서 실행되며
파이썬 코드는 Faaslet에서 실행되는 Cpython으로 실행된다.
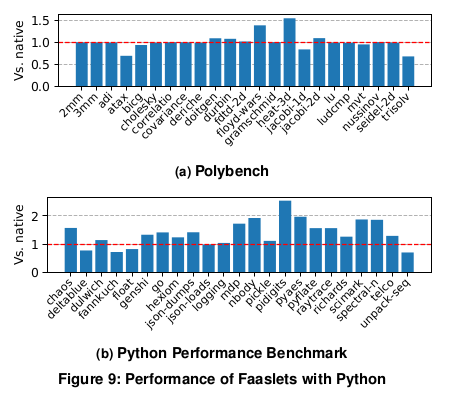
그림 9는 두 벤치마크 세트를 모두 실행할 때의 성능 오버헤드를 네이티브 실행과 비교하여 보여줍니다.
Polybench 벤치마크 중 두 개를 제외한 모든 벤치마크는 네이티브 벤치마크와 비슷하며
일부는 성능 향상을 보여준다.
두 가지 모두 40%-55%의 오버헤드를 경험하며,
두 가지 모두 WebAssembly 로 컴파일을 통해 손실되는 루프 최적화의 이점을 누린다.
많은 파이썬 벤치마크가 25% 이상의 오버헤드 내에 있지만 일부는 50%~60%의 오버헤드를 보이며
pidigit 은 240%의 오버헤드를 보여준다.
pidigits 은 32비트 WebAssembly 에서 상당한 오버헤드를 발생시키는 큰 정수 연산을 강조한다.
그외 Jangda 는 WebAssembly 로 컴파일된 코드가 더 많은 명령어, 분기 및 캐시 miss 를 가지고 있으며
이러한 오버헤드는 더 큰 응용 프로그램에서 복합적으로 발생한다고 보고한다.
그러나 serverless function 은 일반적으로 복잡한 응용프로그램이 아니며
배포 오버헤드가 지배적인 분산 환경에서 작동한다.
그림 8a에서 볼 수 있듯이, Faasm 은 동적 언어 런타임에 의해 해석되는 함수에 대해서도
네이티브 실행을 통해 경쟁력 있는 성능을 달성할 수 있다.
6.5 Efficiency of Faaslets vs. Containers
마지막으로, 우리는 Faaslet과 컨테이너 사이의 footprint 와
cold start 초기화 지연 시간의 차이에 초점을 맞춘다.
메모리 사용량을 측정하기 위해 호스트에 점점 더 많은 수의 병렬 function 을 배포하고
각 추가 function 에 따라 설치 공간의 변화를 측정한다.
컨테이너는 공유 라이브러리의 동일한 로컬 복사본에 액세스할 수 있도록
동일한 최소 이미지(알파인: 3.10.1)로 제작된다.
이 공유의 영향을 강조하기 위해 proportional set size (PSS) 및
resident set size (RSS) 메모리 소비를 포함한다.
초기화 시간과 CPU 주기는 no-op function 의 반복 실행을 통해 측정된다.
우리는 메모리가 부족하기 전에 호스트에서 유지할 수 있는
최대 동시 실행 컨테이너 또는 Faaslet 수를 관찰한다.
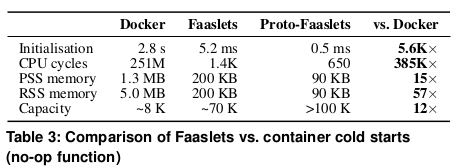
표 3은 Faaslet으로 no-op 을 격리할 때 CPU 사이클과,
경과 시간의 몇 자릿수 개선과 Proto-Faaslets를 사용한 추가 증가율을 보여준다.
컨테이너에 대한 낙관적인 PSS 메모리 측정으로
Faaslet을 사용하면 메모리 풋프린트가 거의 7배, Proto-Faaslet을 사용하면 15배 낮아진다.
single host 는 컨테이너보다 최대 10배 더 많은 Faaslet 을 지원할 수 있으며,
Proto-Fasslet 을 사용하면 12배 더 크게 성장할 수 있다.
non-trivial Proto-Faaslet 스냅샷 복원의 영향을 평가하기 위해
Python no-op function 에 대해 동일한 초기화 시간 측정을 실행한다.
Proto-Faaslet 스냅샷은 미리 초기화된 Cpython 인터프리터이며,
컨테이너는 최소 python:3.7-alpine 이미지를 사용한다.
컨테이너는 3.2초 후에 초기화되며, Proto-Faaslet 은 0.9ms 후에 복원되어
몇 배 정도 유사한 개선을 보여준다.
cold start 초기화 시간을 추가로 조사하기 위해 초당 cold start 속도가 점점 높아지는
새로운 컨테이너/Faaslet 을 만드는 시간을 측정한다.
우리는 또한 Proto-Faaslet 에서 Faaslet 을 복원할 때 이 시간을 측정한다.
실험은 컨테이너가 동일한 최소 이미지를 사용하여 단일 호스트에서 실행된다.
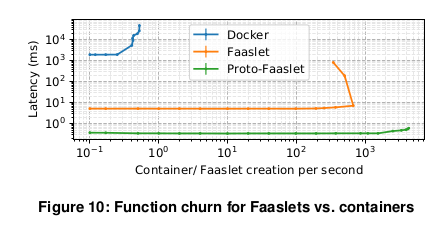
그림 10은 Faaslet 과 컨테이너가 모두 처리량 3회 미만의 실행/sec 미만에서
일정한 초기화 대기 시간을 유지하고 있으며,
도커 컨테이너는 ~2초, Faaslet 은 ~5ms(또는 Proto-Faaslet 에서 복원되는 경우 ~0.5ms)에 초기화된다.
Docker 에서 초당 3회의 실행 시간이 경과함에 따라
처리량의 증가 없이 초기화 시간이 증가하기 시작한다.
유사한 Faaslet 의 실행 제한은 초당 600회 정도이며,
Proto-Faaslet 의 실행 제한은 초당 약 4000회까지 증가한다.
우리는 Faaslet 이 Docker 컨테이너보다 더 효율적이고 성능적인 형태의
serverless 격리를 제공한다고 결론지었고, 이는 Proto-Faaslet 을 통해 더욱 개선되었다.
Faaslet 의 낮은 리소스 설치 공간과 초기화 시간은 serverless context 에서 중요하다.
리소스 설치 공간이 줄어들면 클라우드 제공자의 비용이 절감되고
주어진 호스트에서 병렬 function 의 packing 밀도가 높아진다.
초기화 시간이 짧으면 cold start 문제가 완화되어 사용자의 비용과 대기 시간이 줄어든다.
7. Conclusions
serverless 빅데이터에 대한 증가하는 수요를 충족하기 위해
격리 성능 저하 없이 고성능 효율적인 상태를 제공하는 런타임인 Faasm 을 제시했다.
Faasm 은 메모리 안전과 자원 공정성을 제공하는 Faaslets 내부의 function 을 실행하지만
메모리 내 상태는 공유할 수 있다.
Faaslet은 Proto-Faaslet 의 스냅샷 덕분에 빠르게 초기화된다.
사용자는 Faaslet 상태 API 위에 분산 데이터 개체를 사용하여
stateful serverless 어플리케이션을 구축한다.
Faasm 의 2계층 상태 아키텍처는 병렬 메모리 처리를 제공하면서도
호스트 전체에 걸쳐 확장할 수 있도록 function 과 필요한 상태를 공유한다.
또한 Faaslet 호스트 인터페이스는 동적 언어 런타임과 기존 POSIX 어플리케이션을 지원한다.
