Keras 기본 개념
- 케라스의 가장 핵심적인 데이터 구조는 "모델" 이다.
- 케라스에서 제공하는 시퀀스 모델을 이용하여 레이어를 순차적으로 쉽게 쌓을 수 있다.
- 케라스는 Sequential에 Dense 레이어(fully-connected layers 완전히 연결된 레이어)를 쌓는 스택 구조를 사용한다.
1. 데이터셋 생성
x = np.array([[0,0],[0,1],[1,0],[1,1]])
y = np.array([0,1,1,1]) #or- 원본 데이터를 불러오거나 데이터를 생성한다.
- 데이터로부터 훈련셋, 검증셋, 시험셋을 생성한다. 이 때 딥러닝 모델의 학습 및 평가를 할 수 있도록 포맷 변환을 한다.
2. 모델 구성
model = Sequential([
Dense(units=1,input_dim=2), #완전연결층 Dense
Activation('sigmoid')
])
#또는
model = Sequential()
model.add(Dense(units=1,input_dim=2))
model.add(Activation('sigmoid'))- 시퀀스 모델을 생성한 뒤 필요한 레이어를 추가하며 구성한다. 좀 더 복잡한 모델이 필요할 때는 케라스 함수 API를 이용한다.
- 위 코드에서
Dense()는 한번 사용되었지만 더 많은 레이어를 추가할 수 있다 - 첫번째 인자의 값은 1인데 이는 총 1개의 출력 뉴런을 의미한다.
- 두번째 인자인
input_dim은 입력층의 뉴런 수를 의미한다. - 2개의 입력층 뉴런과 1개의 출력층 뉴런을 만들었다.
- 위 코드에서
3. 모델 학습과정 설정,학습 process 생성
model.compile(optimizer='sgd',loss='binary_crossentropy',metrics=['accuracy'])
# 또는
from keras.optimizers import SGD,RMSprop,Adam
model.compile(optimizer=SGD(learning_rate=0.01,momentum=0.9),loss='binary_crossentropy',metrics=['accuracy'])
-
학습하기 전, 학습에 대한 설정을 수행한다. 손실 함수 및 최적화 방법을 정의. compile() 함수를 사용한다.
-
optimizer: cost function의 최소값을 찾는 알고리즘을 말함. 입력데이터와 손실함수를 기반으로 모델을 갱신. 🔗(sgb,RMSprop,adam...)- SGD : 확률적 경사하강법 (cost를 최소화 할때, 전체가 아닌 일부의 자료만 참여)
- RMSprop : SGD의 단점(local minimum, 국소 최적해)을 보완
- adam : 훈련과정을 모니터링 하고 값을 반환
-
loss: loss function(cost function,손실함수...) - train data로 모델 성능을 측정하는 방법으로, 모델이 옳은 방향으로 학습될 수 있도록함 -
metrics: 훈련과정을 모니터링 하고, 값을 반환.
정성적 분류는 accuracy, 정량적 예측은 mse를 사용하자. -
파라미터로 문자열 지정이 아닌
SGD()함수로써 지정했다. 이렇게 되면 옵션을 직접 지정하여 학습시킬 수 있다.learning_rate가 작을수록 오래 걸리지만 자세히 학습한다.
4. 모델 학습 시키기
history = model.fit(x,y,epochs=1,batch_size=1,verbose=0)-
훈련셋을 이용하여 구성한 모델로 학습 시킨다. fit() 함수를 사용한다
(더 나은 표현찾기를 자동화) -
이력을 확인하기 위해
history변수에 담는다. -
속성
- 첫번째 인자 = 훈련 데이터에 해당됨
- 두번째 인자 = 지도 학습 관점에서 레이블 데이터에 해당됨.
- epochs = 에포크 1은 전체 데이터를 한 차례 훑고 지나갔음을 의미함. 정수값 기재 필요.
총 훈련 횟수를 정의함. - batch_size = 기본값은 32. 미니 배치 경사 하강법을 사용하고 싶지 않을 경우에는 batch_size=None을 통해 선택 가능.
5. 모델 평가
loss_metrics = model.evaluate(x,y,batch_size=1,verbose=0)- 준비된 시험셋으로 학습한 모델을 평가한다. evaluate() 함수를 사용
6. 학습결과 확인 : 예측값 출력
pred = (model.predict(x>0.5).astype('int32'))
print('예측결과 : ',pred.flatten())- 임의의 입력으로 모델의 출력을 얻는다. predict() 함수를 사용한다
- 산출된 실수값을 astype()으로 0.5를 기준으로 분리.
모델 save / load
#save
model.save('./test.hdf5')
#load
from keras.models import load_model
mymodel = load_model('test.hdf5')
pred2 = (mymodel.predict(x>0.5).astype('int32'))
print("예측결과 : ",pred2.flatten())- 저장 이후엔 위의 학습과정은 더이상 필요없다.
hdf5확장자 : XML과 동일하게 자기 기술적으로 구성되어있어 데이터 형식을 파일 안에 기술이 가능하다. 많은 양의 데이터를 저장 가능하다.
학습시 발생정보 시각화
history와 loss 정보를 변수로 받아 시각화한다.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'],color='red',label='loss')
plt.plot(history.history['accuracy'],color='blue',label='loss')
plt.xlabel('epochs')
plt.legend(loc='best')
plt.show()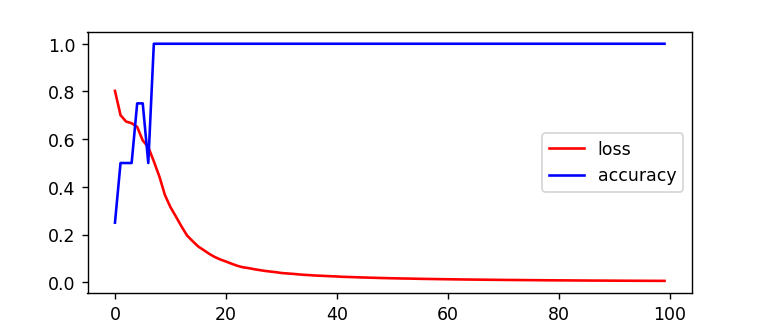
loss가 감소할수록 accuracy가 증가하는모습.
