3 ways to create a Keras model
방법1 Sequential API
사용된 라이브러리 / 변수
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from keras import optimizers
import numpy as np
x_data = np.array([[1],[2],[3],[4],[5]],dtype=np.float32)
y_data = np.array([11,32,54,66,70])1. 상관계수확인
print('상관계수 : ',np.corrcoef([x_data,y_data])) - 0.974의 높은 상관계수가 확인되었지만, 인과관계를 확인하기 위해서는 선형회귀 모델을 사용하여 알아봐야한다.
2. 선형회귀 모델
# 생성
model = Sequential()
model.add(Dense(units=2,input_dim=1,activation='linear')) #1->2->1 구조
model.add(Dense(units=1,activation='linear'))
print(model.summary())
# 학습
opti = optimizers.Adam(learning_rate=0.1)
model.compile(optimizer=opti, loss='mse', metrics=['mse'])
history = model.fit(x=x_data,y=y_data,batch_size=1,epochs=100,verbose=2)3. 결과 (예측/loss/결정계수)
#loss
loss_metrics = model.evaluate(x=x_data,y=y_data)
print('loss metrics : ',loss_metrics)
#예측
print('실제값',y_data)
print('예측값',model.predict(x_data).flatten())
#결정계수
from sklearn.metrics import r2_score
print('설명력 : ',r2_score(y_data,pred))
#새로운 값으로 예측
new_data = [1.5,2.3,5.8]
new_data = np.expand_dims(new_data,axis=1) #차원 확장 1->2. 줄일땐 flatten
print('새 예측값',model.predict(new_data).flatten())- new_data 는 x_data와 차원을 맞춰주어야함
시각화
- 분석데이터 시각화
import matplotlib.pyplot as plt
plt.rc('font',family='malgun gothic')
plt.plot(x_data.ravel(),model.predict(x_data),'b',\
x_data.ravel(),y_data,'ko')
plt.xlabel('공부시간')
plt.ylabel('점수')
plt.show()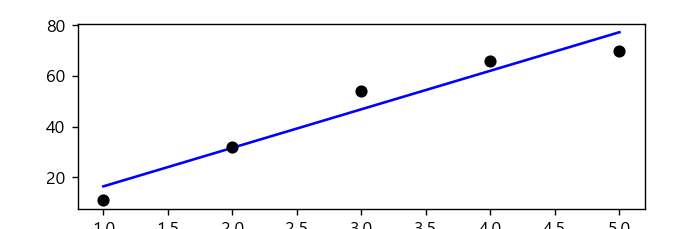
- MSE의 변화 추이를 시각화
plt.plot(history.history['mse'],label='평균제곱오차')
plt.xlabel('학습횟수')
plt.show()
방법2 Functional API
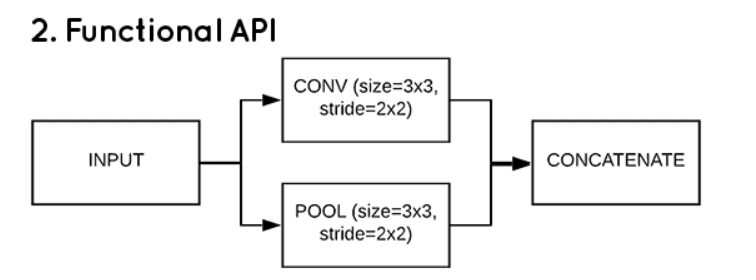
- 유연한 구조, 입력데이터로부터 여러층 공유, 다양한 종류의 입출력 가능.
from keras.layers import Input
from keras.models import Model
inputs = Input(shape=(1,)) #입력층
output1 = Dense(units=2,activation='linear')(inputs) #은닉층
output2 = Dense(units=1,activation='linear')(output1) #출력층
#모델 생성
model2 = Model(inputs,output2) #첫 input과 마지막 output을 넣는다- 이전 층을 다음층에 차례로 할당한다. 1->2->1 구조
- 나머지 분석 부분은
방법1과 같다.
방법3 Model Subclassing
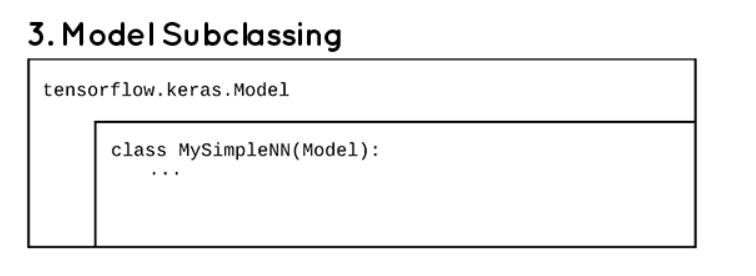
동적인 구조. 고난이도의 작업에서 활용성이 높다.
class MyModel(Model):
def __init__(self): #생성자
super(MyModel,self).__init__()
self.d1 = Dense(units=2,activation='linear')
self.d2 = Dense(units=1,activation='linear')
def call(self,x):
inputs = self.d1(x)
return self.d2(inputs) #이전 층값을 넣는다.
model3 = MyModel() - Model을 상속. 생성자에서 layer를 생성하고, call에서 구성한다.
기본적인 형태는 이러하나, 실제론 잘 사용하지 않는 형태이다.
아래의 형식을 참고하자
- 사용자 정의층 Layer
새로운 연산을 위한 레이어 혹의 편의를 위해 여러 레이어를 하나로 묶어 구현할때 사용한다.
from keras.layers import Layer
import tensorflow as tf
class Linear(Layer):
def __init__(self,units=1):
super(Linear,self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1],self.units),\
initializer='random_normal',trainable=True) #trainable 역전파 활성화
self.b = self.add_weight(shape=(self.units,),\
initializer='zeros',trainable=True)
def call(self,inputs):
return tf.matmul(inputs,self.w)+self.b #y=wx+b 구조의 행렬곱build: 모델 가중치 관련 내용 기술call: 정의된 값으로 해당층의 로직을 정의
- 모델 구성
class MyLinearModel(Model):
def __init__(self):
super(MyLinearModel,self).__init__()
self.linear1 = Linear(2)
self.linear2 = Linear(1)
def call(self,inputs):
x = self.linear1(inputs)
return self.linear2(x)
model4 = MyLinearModel()- 나머지 분석은
방법1과 같다.
참고
- 학습 도중 조기 종료
EarlyStopping객체를 생성 후 모델 fit 옵션에 callbacks를 추가한다.
from keras.callbacks import EarlyStopping
es = EarlyStopping(patience=3,mode='auto',monitor='val_loss')
history = model.fit(x_train, y_train, epochs=10000, batch_size=32, \
verbose=2, validation_split=0.2,callbacks=[es])
이렇게 되면 epochs를 몇을 주더라도 일정 학습량을 도달하면 학습을 멈춘다.
