
0. 들어가기 전에
- 스프링 프로젝트를 진행하며 에포크 기반 랜덤 값을 리턴하는 Tsid 라이브러리를 사용하다가 궁금한 점을 테스트를 통해 확인했습니다.
싱글톤 인스턴스에 여러 쓰레드가 접근한다면 지연이 발생할까?라는 질문을 가지고 테스트했습니다.
🛠️ 실습환경
Lang: Java 17
Test: jUnit5📝 실습 목표
멀티쓰레드 환경에서 싱글톤 인스턴스에 여러 쓰레드가 접근한다면 지연이 발생할까? 에 대한 답변
1. 테스트
- 동기화 처리가 필요한 인스턴스를 사용할 때 싱글톤 인스턴스일 때, 미리 생성된 인스턴스가 n개 있을 때, 매번 새로운 인스턴스를 생성할 때를 나누어 테스트 해봅니다.
- 동시 요청 수는
128,256,512회로 고정합니다
1.1 테스트 코드
import com.github.f4b6a3.tsid.TsidFactory;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.Arguments;
import org.junit.jupiter.params.provider.MethodSource;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.stream.Stream;
public class TsidDurationTest {
static String pathFormat = "src/test/resources/results%s-ready%s.csv";
static void write(int numberOfRequest, int numberOfInstance, long s, long m, long n) {
String path = String.format(pathFormat, numberOfRequest, numberOfInstance);
try (BufferedWriter writer = new BufferedWriter(new FileWriter(path, true))) {
writer.append(String.format("%s,%s,%s\n", s, m, n));
} catch (IOException e) {
e.printStackTrace();
}
}
static Stream<Arguments> args() {
List<Integer> numberOfRequests = List.of(128, 256, 512);
List<Arguments> args = new ArrayList<>();
numberOfRequests.forEach(value1 -> {
args.add(Arguments.of(value1, 10));
args.add(Arguments.of(value1, 100));
});
return args.stream();
}
@ParameterizedTest
@MethodSource("args")
void singleInstanceVsMultiInstance(int numberOfRequests, int numberOfInstance) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool();
List<Callable<Long>> singleTasks = new ArrayList<>();
TsidFactory singleFactory = TsidFactory.builder().withNode(0).withNodeBits(16).build();
while (singleTasks.size() < numberOfRequests) {
singleTasks.add(() -> singleFactory.create().toLong());
}
long singleStart = System.nanoTime();
service.invokeAll(singleTasks);
long singleDuration = System.nanoTime() - singleStart;
List<TsidFactory> factories = new ArrayList<>();
while (factories.size() < numberOfInstance) {
factories.add(TsidFactory.builder().withNode(0).withNodeBits(16).build());
}
List<Callable<Long>> multiTasks = new ArrayList<>();
while (multiTasks.size() < numberOfRequests) {
for (TsidFactory factory : factories) {
multiTasks.add(() -> factory.create().toLong());
}
}
long multiStart = System.nanoTime();
service.invokeAll(multiTasks);
long multiDuration = System.nanoTime() - multiStart;
List<Callable<Long>> newTasks = new ArrayList<>();
while (newTasks.size() < numberOfRequests) {
newTasks.add(() -> TsidFactory.builder().withNode(0).withNodeBits(16).build().create().toLong());
}
long newStart = System.nanoTime();
service.invokeAll(newTasks);
long newDuration = System.nanoTime() - newStart;
write(numberOfRequests, numberOfInstance, singleDuration, multiDuration, newDuration);
}
}
- 테스트 결과를 CSV 파일로 만들고 엑셀 차트에 불러와 보기 편하게 만들어 봅니다.
2. 결과
2.1 테스트 결과 지표
공유 스프레드시트 링크
결과 차트를 만들어 표와 그래프를 나타낸 문서입니다.
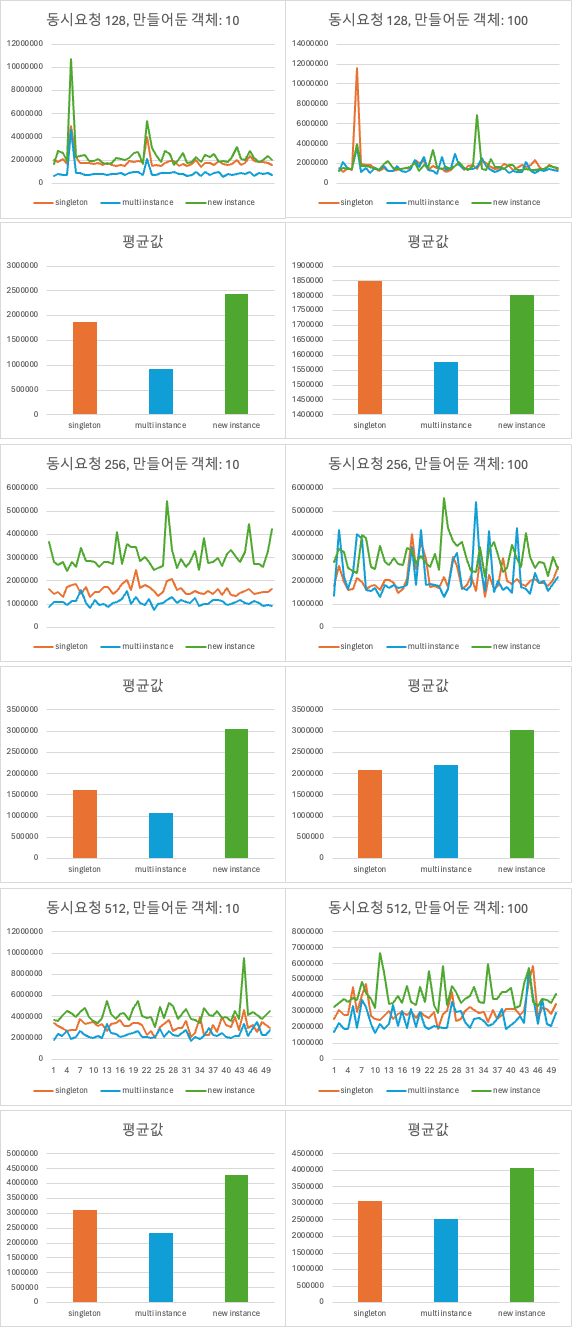
- 하나의 인스턴스에 접근해 작업을 수행하는 것 보다 미리 만들어 둔 객체들에 작업을 분배하면 수행 시간이 줄어드는 유의미한 결과를 확인 할 수 있습니다.
2.2 왜 차이가 발생할까?
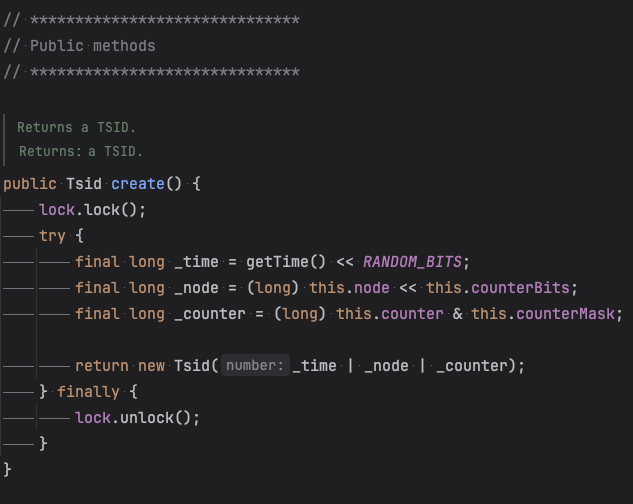
- TSID의 특성상 하나의 객체가 식별자 값을 생성할 때 같은 밀리세컨드 에포크에서는 원자적으로 동작하며 식별자 값을 1씩 증가시키고 연속된 값을 반환할 수 있도록 합니다.
- Tsid 라이브러리를 살펴보면 실제 식별자 값을 생성 할 때 ReenterantLock을 통해 동시성 문제를 해결하고 있습니다.
- 이 때, 동시에 몰리는 작업이 하나씩 순서대로 처리되며 여러 인스턴스로 작업이 분배될 때 보다 많은 시간을 소요하는것으로 보입니다.
2.3 발생할 수 있는 문제점은?
- 식별자 값을 생성하는 인스턴스가 여러개일 때 중복이 발생할 수 있습니다.
- 같은 밀리세컨스 에포크, 같은 nodeId, 라이브러리 랜덤함수에 의해 같은 랜덤값을 반환하는 경우 등 특정 조건을 만족할 때 중복 값이 발생할 수 있습니다.
2.4 어떻게 인스턴스를 나눠서 사용하면 좋을까?
- 정답은 없지만 식별자 값이 중복돼도 괜찮은 경우에 나눌 수 있습니다.
- 예를들어 RDB에
FOO,BAR테이블이 있다고 가정할 때 둘의 식별자 값이 중복돼도 괜찮은 경우 인스턴스를 나누어 사용할 수 있습니다. - 사용하려는 인스턴스 내부적으로
synchronized,ReentrantLock처럼 동기화 작업을 수행하는 경우 사용할 수 있습니다.
3. 맺음말
동시성 처리가 필요한 객체를 싱글톤 객체와 미리 생성된 객체, 그리고 매번 새 객체를 생성해 사용하고 여러 작업이 집중될 때 작업 수행 소요시간을 비교해봤습니다.
테스트코드, 과정에서 이상한점, 문제점 등 이슈가 발견되면 댓글이나 이메일로 알려주세요. :)

Hi. I'm Neo