생성 모델
-> 데이터로부터 확률 모델을 추정해서 데이터를 생산하는 모델
베이즈 정리와 주변화
- 확률의 곱 법칙
- 확률의 합 법칙
- 베이즈 정리
: 사후 확률
: 우도
: 사전 확률
: 정규화 상수
A를 가설, B를 증거라고 하면 베이즈 정리란?
가설에 대한 믿음을 증거를 토대로 갱신하는 과정
판별 모델과 생성 모델
- 판별 모델 (discriminative model)
- 관측 데이터가 있을 때 각 클래스가 속할 확률을 예측
- (관측 데이터)가 (클래스)에 속할 조건부 확률 분포
- 생성 모델
- 관측 데이터의 확률분포를 학습해서 새로운 샘플을 생성하는 모델
- (사전확률 분포)와 관측 데이터의 조건부 확률 를 구한 뒤 베이즈 정리를 이용해서 사후분포 를 예측정규화 상수 : 합의 법칙으로 구해짐
잠재변수 모델
- 생성 모델이 잠재변수 모델(latent variable model)인 경우 를 잠재변수 로 일반화
- 잠재변수 가 주어졌을 때 관측데이터 에 대한 조건부확률분포 로 표현
ex) 잠재변수 가 고양이의 종류와 속성을 나타낸다면,
생성모델은 를 입력했을 때 고양이 이미지의 조건부 확률분포 를 출력한다.
생성모델의 종류
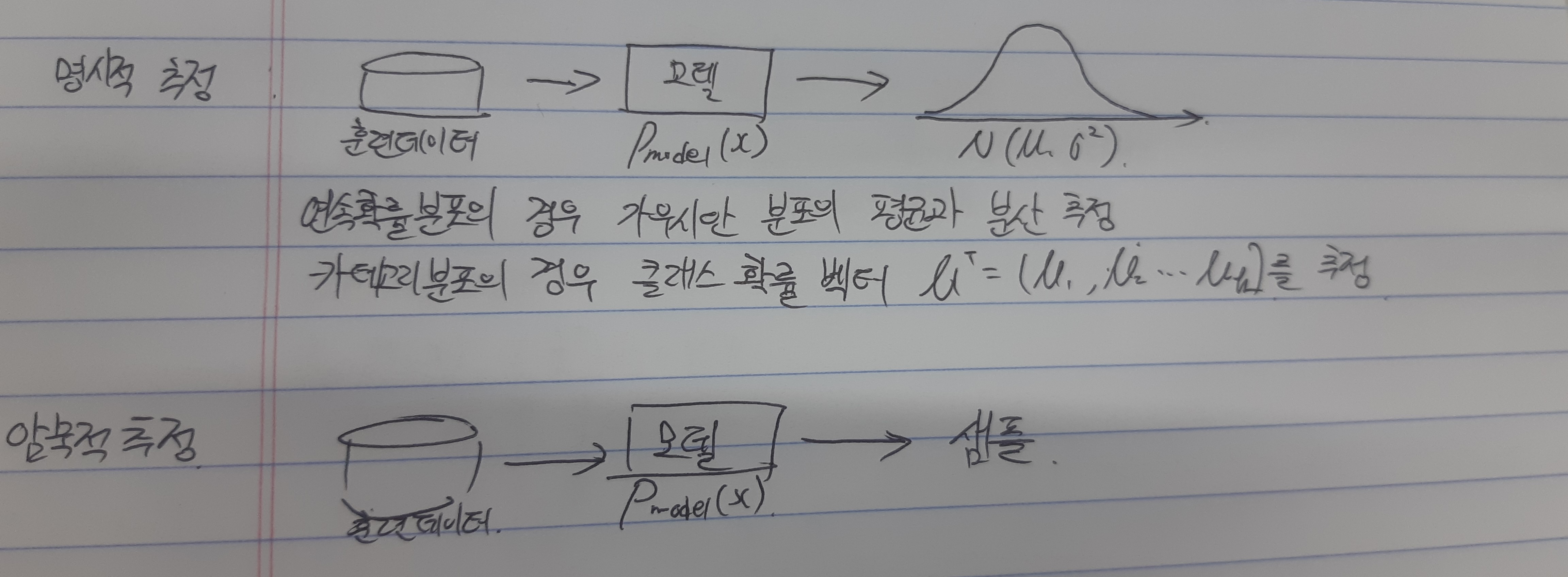
- 명시적 추정방식
- 확률분포를 명식적으로 추정
- 자기회귀 모델 (autoregressive model): 확률분포를 정확히 추정
- VAE: 확률 분포를 근사적으로 추정
- 확률분포를 명식적으로 추정
- 암묵적 추정방식
- 모델이 확률분포를 따르는 샘플을 생성
- GAN
자기회귀 모델(AR)
이미 생성된 자신의 데이터를 이용해서 나머지 데이터를 생성하는 모델
생성해야할 데이터가 가 차원 데이터 이라면,
이전 차원의 확률분포를 다음 차원에서 사용하기 때문에 각 차원의 순서가 중요하며, 모든 가 관측 변수가 되기 때문에 FVBN(fully visible belief network)라고 불린다.
- 장점: 잠재변수 모델이 아니므로 관측 데이터만으로 확률분포를 정확히 추정한다.
- 단점: 순차적으로 한 차원씩 생선하는 만큼 학습 속도가 매우 느리다.
VAE
인코더 - 디코더 구성된 잠재변수 모델로 확률분포를 변분적으로 근사한다.
변분적이란?
함수의 함수를 나타내는 범함수를 최대화하거나, 최소화 하는 방법.
함수의 미적분 또는 최적화 방법을 사용해 VAE에서 확률분포를 근사할 때, 알고있는 확률분포와 근사하는 확률분포의 거리를 최소화하는 과정에서 사용한다.
VAE model graph
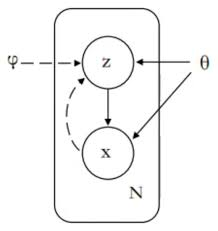
x에서 z로 올라가는게 encoder, z에서 x로 내려가는게 decoder
인코더는 관측 변수 를 표현하는 잠재변수 의 확률 공간 (위 그림에서 z왼쪽)를 함수 (위 그림에서 z오른쪽)로 근사한다. 디코더는 잠재변수 가 표현하는 관측 변수 의 확률분포 를 추론한다.
VAE는 확률분포를 근사하는 방식이라 정확한 확률분포를 추정하지는 못하지만, 훈련 과정이 안정적이고 빠르다는 장점이 있다.
GAN
GAN은 생성자(generator)와 판별자(discriminator)가 적대적 관계에서 훈련하는 모델이다.
-
생성자는 가짜 데이터를 만들면서 판별자가 진짜라고 속을 때까지 학습한다.
-
판별자는 훈련 데이터는 진짜 데이터로 판별하고, 생성자가 만든 데이터는 가짜 데이터로 판별하도록 학습한다.
-
생성자는 가짜 데이터를 판별자에게 테스트했을 때 가짜와 진짜를 더 구분하지 못할 때까지 학습한다.
-
생성자는 판별자를 통해 훈련 데이터의 확률분포를 간접적으로 학습한다.
GAN으로 생성된 이미지는 선명하고 현실감이 있지만, 생성자와 판별자가 경쟁적으로 학습하는 방식 때문에 학습 과정이 불안정하고 최적화가 어렵다는 단점이 있다.
생성 모델 예시
- 인페인팅
- 고해상도 이미지로 변환
- 데이터 증강
- 이미지 변환
참고
- Do It 딥러닝 교과서 (출판: 이지스 퍼블리싱)
