배경
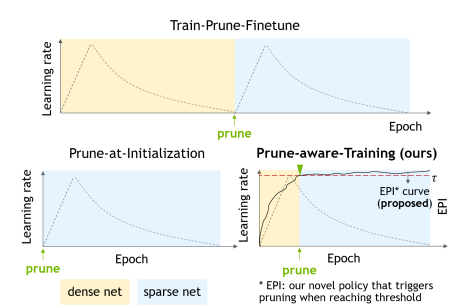
- Pruning을 진행할 때 기존에는 1) Dense network를 scratch에서 학습을 완료하고, 2) Pruning 알고리즘을 이용하여 Pruning하고, 3) 정확도 손실 회복을 위해 Finetuning하는 순서로 진행되었다. 이는 Train-Prune-Finetune 과정에 해당하며, 사실상 Train과 Finetune 과정으로 2번의 학습으로 한번 학습하는 것의 2배의 resource(시간, 메모리)가 사용되는 단점이 있다.
- 그래서 나온 방법이 Dense network를 학습 시킬 때 맨처음에 바로 pruning을 적용하고 Finetuning을 하는 Prune-at-Initialization 기법이 제안되었다. 하지만 이는 성능 손실(degradation)이 매우 크다는 단점이 있다.
- 다음으로 Dense network를 학습 시키다가 중간에 pruning하고 이후 finetuning을 하는 방식이 제안되었지만 기존에는 heuristic한 방식으로 특정 epoch를 지정하여 pruning이 진행되었다.
- 이 논문에서는 EPI라는 지표를 만들어서 automatic하게 pruning하는 epoch를 찾고 finetuning까지 적용하는 Prune-aware-Training 방식을 제안한다.
핵심 아이디어
알고리즘


- 위와 같은 알고리즘을 사용하며, 이는 Dense network를 학습하면서 각 epoch마다 EPI를 계산한다. 이 때 EPI값이 Theshold 값보다 크고 최근 5번의 EPI 값보다 크다면 pruning을 하는 지점이라고 판단하여, 이 후에는 pruned network만 학습을 진행하여 finetuning 하는 과정이다.
Early Pruning Indicator(EPI)
- Dense network를 학습하는 동안 각 epoch에서 나오는 pruned network들의 similarity를 바탕으로 similarity가 높다면 network의 stability가 높다고 판단하는 지표이다.
- 다음과 같은 수식으로 구해진다.
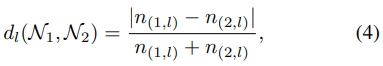
는 번째 layer간의 거리의 의미로 layer의 뉴런의 개수를 이용하여 판단한다. 또한 이는 0에서 1사이의 값을 가지며 0에 가까울수록 거리가 가깝다고 할 수 있다.
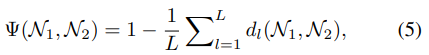
는 모든 layer의 거리를 구해 평균을 내고 그 값을 1에서 뺀 값이다. 이는 0에서 1사이의 값을 가지며 1에 가까울수록 비슷하다고 할 수 있다.
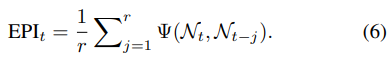
최종적으로 EPI는 현재 pruned network와 이전에 j번째 pruned network와의 차이를 평균내어 stability, 즉 similarity를 판단한다.
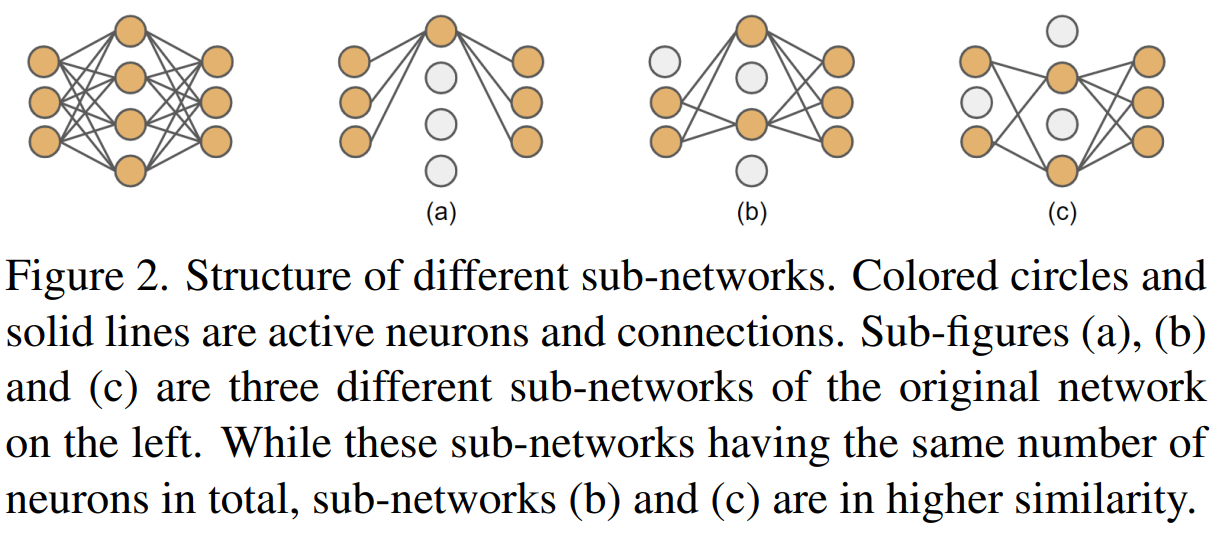
따라서 이 위의 네트워크를 비교하였을 떄 같은 레이어에 남아있는 뉴런의 개수가 같을수록 similarity가 높다고 판단이 되어 (b)와 (c)는 비슷한 모델이라고 정의한다.
실험
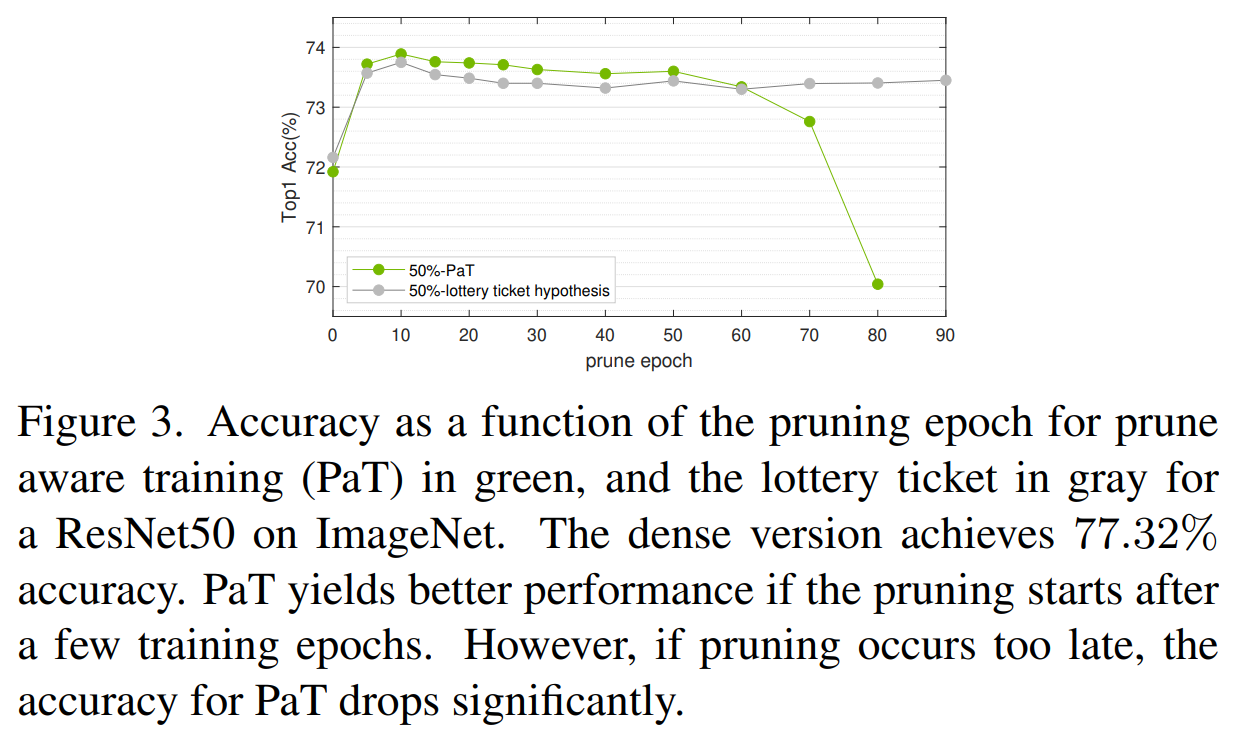
- 위 그래프는 Lottery ticket 방식과 PaT 방식을 비교하는 그래프로 Lottery ticket은 Structural Pruning에서 큰 효과가 없다는 것을 보여준다.
- 어느 epoch에서 Pruning 하는지에 따라 정확도를 표현한 것으로 PaT의 automatic한 pruning epoch을 찾는 방식이 적용되지 않고 두 그래프의 차이는 PaT는 pruning한 구조에 가중치를 그대로 가지고 finetuning을 하는 것이고 Lottery ticket은 pruning 후 가중치를 초기 가중치로 다시 초기화시킨 후 finetuning을 하는 방식이다.
- 두 방법 모두 맨 처음 epoch에서 pruning을 하면 성능이 가장 안 좋은 것을 알 수 있다. 이는 Prune-at Initialization의 실패를 보여준다.
- 초반 epoch에서 pruning하는 것이 Finetuning할 남은 epoch이 더 많아서 성능이 더 좋은 것을 알 수 있다.
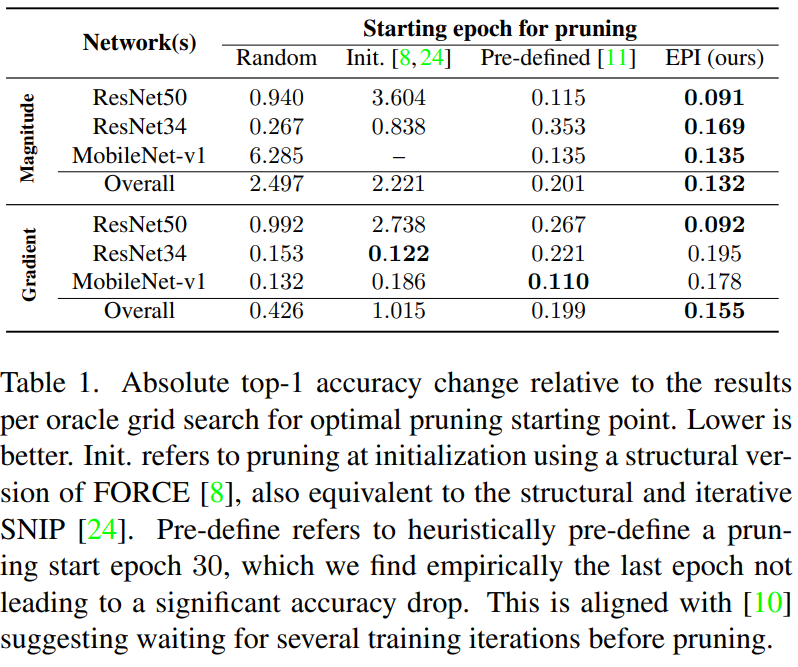
- 위 표는 Pruning epoch을 정하는 방식과 pruning method인 Magnitude-based, Gradient-based의 차이에 따른 모델별 ImageNet에 대한 Dense network와 Pruned network의 성능 차이이다. 또한 Overall은 위 성능 차이의 평균이다.
- Magnitude-based 에서는 모든 모델에서 다 좋은 성능을 보인다.
- Gradient-based 에서는 각각은 성능이 다 좋지는 않지만 전반적으로(Overall) 좋다는 것을 알 수 있다.
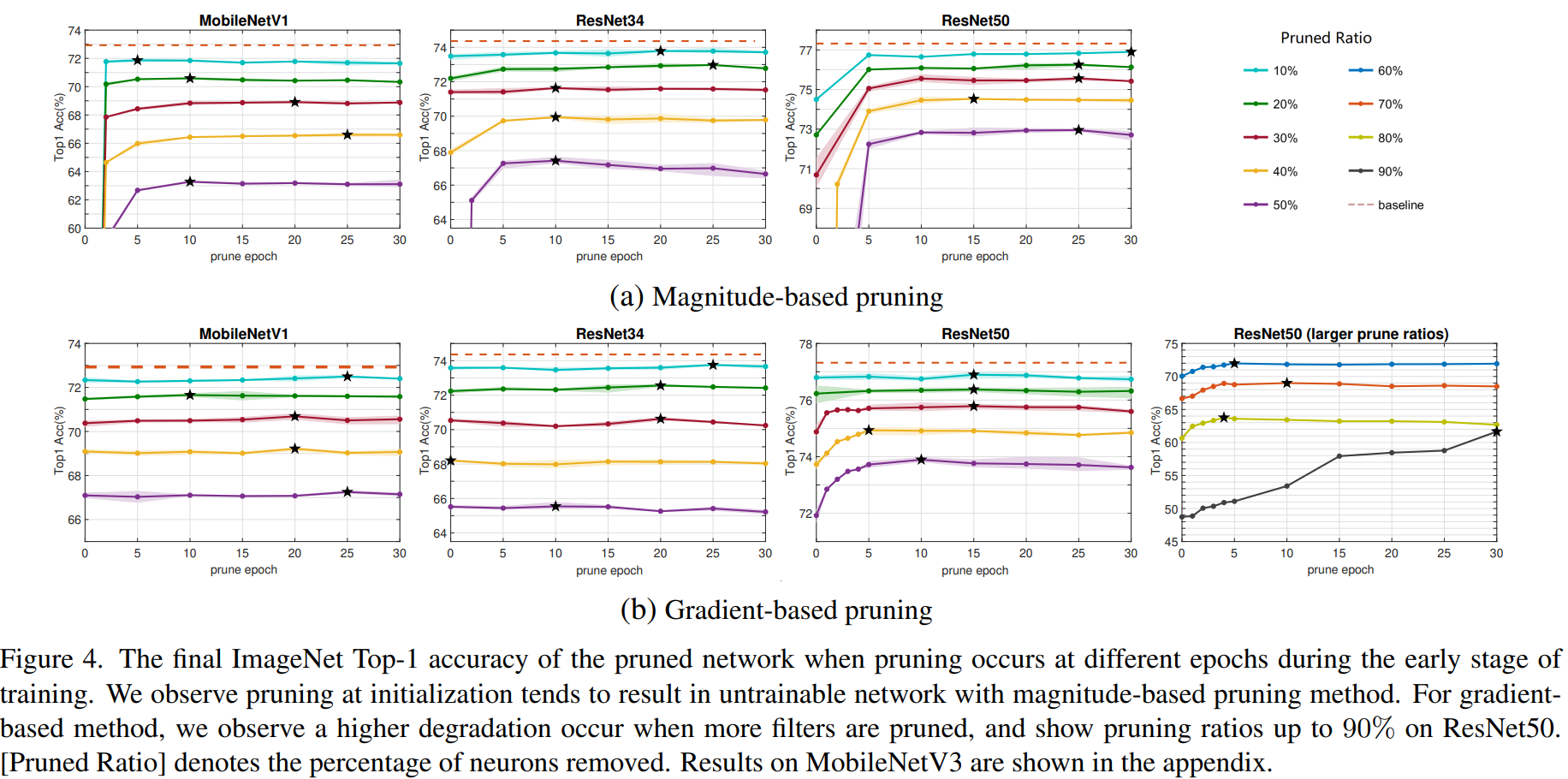
- 위 그래프는 모델별 prune epoch에 따른 정확도를 나타낸 그래프이다.
- magnitude-based는 빨리 pruning하면 정확도가 크게 떨어지는 것을 알 수 있고 Gradient-based는 그래도 큰 영향을 받지 않는 것을 알 수 있다.
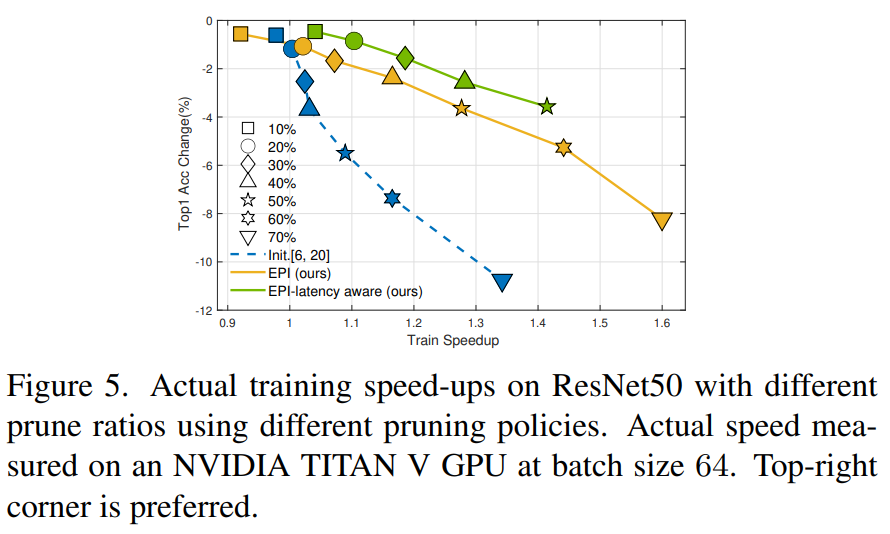
- 0 epoch에서 잘리는 뉴런은 보통 깊은 layer의 필터이다. 하지만 깊은 layer의 필터를 자르는 것은 해상도가 낮은 feature map을 다루기 때문에 latency 속도 효과가 적다. 따라서 앞쪽 layer의 필터가 더 많이 잘릴 수 있도록 the neuron group's saliency를 적용하여 이를 EPI-latency aware 이라고 하며 이는 기존 대비 속도향상이 크다는 것을 알 수 있다.
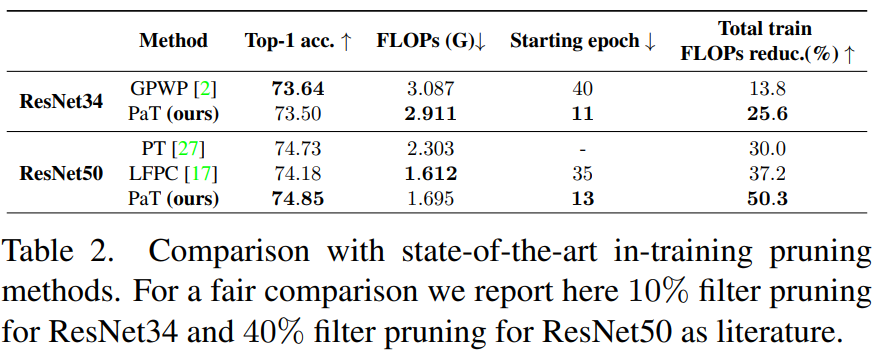
- 기존에도 training 중간에 pruning하고 finetuning하는 아이디어는 있었다. 하지만 이는 heuristic하게 prune epoch를 정했고 그들과의 비교표이다.
- ResNet34 모델 기준으로는 정확도는 조금 낮지만 속도 향상이 더 잘 되었다는 것을 알 수 있다. 이는 더 빨리 pruning 하였기 때문이다.
- ResNet50 모델 기준으로는 성능도 더 좋았고 빨리 pruning 하였기 때문에 전체 Training FLOPs도 훨씬 줄었다는 것을 알 수 있다.
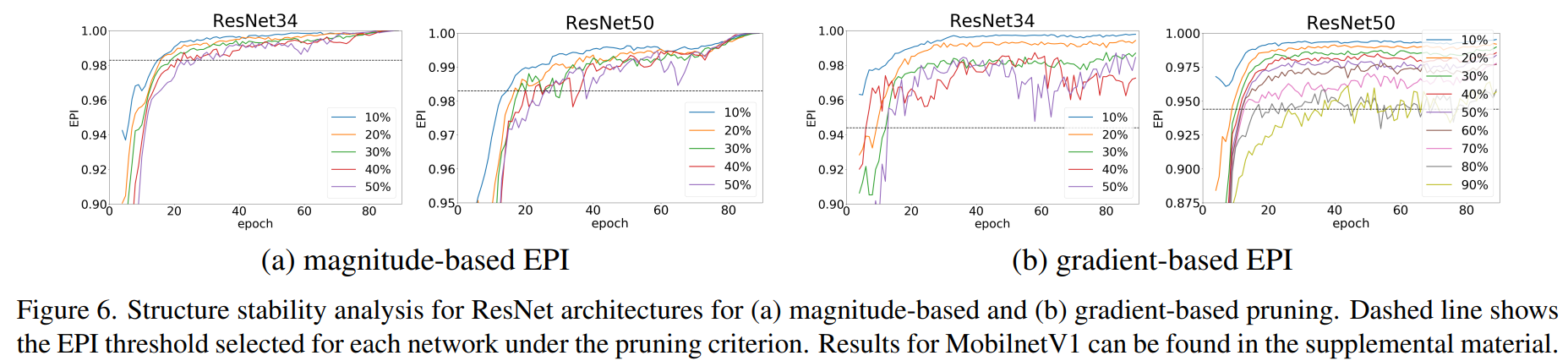
- magnitude-based EPI와 gradient-based EPI의 모델별 수치 변화를 표현한 그래프이다.
- pruning ratio가 클수록 EPI가 낮다는 것을 알 수 있고 이 수치는 epoch이 클수록 높다는 것을 알 수 있다.
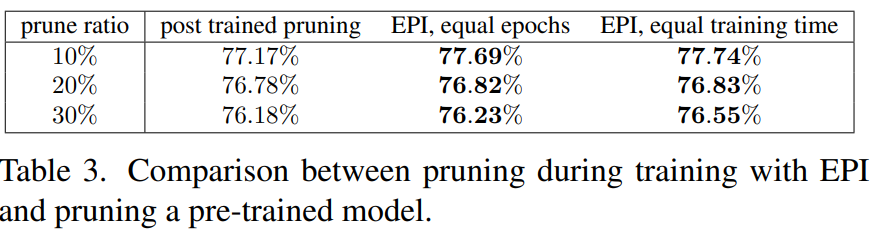
- 이 표는 train-prune-finetune(post trained pruning)과 EPI의 성능을 비교한 표이다.
- post trained pruning은 train 90 epochs, finetune 90 epochs로 총 180 epochs를 훈련시켰다.
- EPI, equal epochs는 똑같이 180 epoch 동안 그 사이에 automatic하게 빨리 pruning하고 finetuning까지 적용한 것이다. 이는 빨리 pruning하였기 때문에 finetuning epochs가 90보다 커서 성능이 더 좋을 것이고 전체 학습 속도도 더 빠르다.
- EPI, equal training time은 post trained pruning에 걸리는 시간과 같은 시간동안 학습한 것으로 총 epoch이 180보다 더 크다. 따라서 더 많이 finetuning을 진행하기 때문에 성능이 더 좋다.
Contribution
- 새로운 EPI를 제안하여 학습 중에 pruning epoch를 찾으며 이는 정확도 손실이 적다.
- 처음에 pruning을 진행하여 finetuning하는 것보다 성능이 훨씬 좋다.
- EPI를 magnitude-based와 gradient-based 모두에 적용할 수 있는 범용성이 있다는 것을 보였다.
아쉬운 점
- pruning epoch의 시기를 각 epoch에서의 pruned model의 similarity로 한 것에 대한 배경이 부족하다.
- pruning 후 실제 모델의 구조를 reconstruction 한 과정에 대한 설명이 코드가 없어서 확인 불가능하다.
- latency-aware pruning에서 neuron group's saliency를 어떻게 적용하였는지 알 수 없다.
