Data Load
Local Data Load
1. 데이터 다운로드 & 확인
jisoo_lee@cloudshell:~$ git clone https://github.com/onlybooks/bigquery # 다운로드
# Cloning into 'bigquery'...remote: Enumerating objects: 986, done.remote: Counting objects: 100% (986/986), done.remote: Compressing objects: 100% (731/731), done.remote: Total 986 (delta 282), reused 915 (delta 217), pack-reused 0Receiving objects: 100% (986/986), 18.48 MiB | 10.20 MiB/s, done.Resolving deltas: 100% (282/282), done.
jisoo_lee@cloudshell:~$ cd bigquery
jisoo_lee@cloudshell:~/bigquery$ ls
# appendix bigquery_cover.jpg blogs ch01 ch02 ch03 ch04 ch05 ch06 ch07 ch08 ch09 ch10 README.md set_env.md
jisoo_lee@cloudshell:~/bigquery$ cd ..
jisoo_lee@cloudshell:~$ cd bigquery/ch04
jisoo_lee@cloudshell:~/bigquery/ch04$ zless college_scorecard.csv.gz
# 압축파일 내용 확인 > space로 내용 확인 > q로 Fin.2. BigQuery로 데이터 로드 > 데이터셋 생성
bq --location=US mk ch04
# 데이터셋 위치 US로 지정(default 값이 US)
# 특정 region만 선택해서 생성 가능함 us-east4
bq: BigQuery 서비스를 사용하기 위한 명령들 제공 > bq 명령으로 행할 수 있는 작업들은 REST API 혹은 GCP 클라우드 콘솔로도 가능함
DataSet
- 테이블, 뷰, 머신러닝 모델 등을 정리 및 접근성을 제어하기 위한 Top 폴더처럼 작동
- 현재 프로젝트에 생성되며, 데이터셋 내 테이블에 대한 스토리지 비용은 프로젝트에 청구됨
- Region이 다른 테이블 간 join은 불가
3. 데이터 로드
- 실제 데이터 로드하기 전에 필수적으로 데이터 정리 및 변형을 진행해야 함 > 아래 4번에서 진행
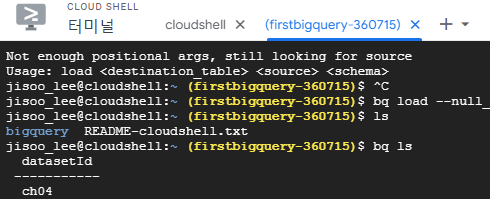
bq --location=US \
load --null_marker=NULL --replace \
--source_format=CSV --autodetect \
ch04.college_scorecard \
./college_scorecard.csv.gz
# 원본이 CSV형식 + 스키마를 자동으로 탐색(컬럼별 데이터 형식)
# college_scorecard 테이블을 ch04 데이터셋 안에 생성하고,
# 데이터는 현재 디렉토리의 college_scorecard.csv.gz 파일에서 찾아라 Question.
load --null_marker=NULL --replace \ --source_format=CSV --autodetect \ ch04.college_scorecard \ ./college_scorecard.csv.gz이건 되고
왜 \없이 일자로 쭉 나열한건 안되지???
문제는 테이블 안에 NULL값이 존재할 경우 테이블 생성이 불가능함, 해결방법은 아래와 같음
1) 각 칼럼의 스키마를 직접 명시, Null 값 허용하도록 컬럼 타입을 문자열로 변경
2) --max_bad_records=20과 같은 파라미터를 이용해 문제있는 레코드는 pass 설정
3) 로드 프로그램에게 특정 파일은 null값을 문자열 NULL로 표현하고 있다고 인지[Best Option]
본래 CSV 파일의 NULL 값은 빈칸으로 세팅함
주의사항 : Project에 해당하는 terminal에서 데이터를 로드해야 함
- 테이블 만료 코드
ALTER TABLE SET OPTIONS으로 테이블 만료일 지정할 수 있음
4. (데이터 로드 전) SCHEMA 지정
1. Schema 자동 탐지 알고리즘 오류
- Schema 자동 탐지 알고리즘은 파일의 모든 행을 확인하지 않고, 처음 몇 개의 행만 샘플화 하여 스키마를 확인하기 때문에 해당 Column의 Schema를 정확히 파악하지 못하는 경우가 존재함
2. Therefore, 로드 시점에 컬럼의 데이터 타입을 지정해야 함
압축된 파일에서 특정 문자열을 NULL로 바꾸는 명령
zless ./college_scorecard.csv.gz | \ sed 's/PrivacySuppressed/NULL/g' | \ gzip > /tmp/college_scorecard.csv.gz-문자열 편집기
sed를 이용하여 PrivacySuppressed 문자열을 NULL로 변환
3. 그래도 우선 테이블 스키마 자동 탐지로 확인
- Method #1 (Mainly Use)
- Schema 확인하면서 json으로 저장 > 이후에 원하는 Schema로 일부 수정할 계획이기 때문에
bq show --format prettyjson --schema ch04.college_scorecard
# Schema 파일로 저장
bq show --format prettyjson --schema ch04.college_scorecard > schema.json- Method #2
<dataset>.INFORMATION_SCHEMA를 이용하여 All Table의 Schema를 얻음
INFORMATION_SCHEMA로 데이터셋의 메타데이터들을 확인할 수 있음- 데이터베이스 이름, 테이블 이름, 컬럼의 Schema, 접근권한 etc 민감 정보도 포함하고 있음
TO_JSON_STRING을 사용하면 스키마 정보를 JSON 형식으로 변환함
SELECT
TO_JSON_STRING(
ARRAY_AGG(STRUCT(
IF(is_nullable = 'YES', 'NULLABLE', 'REQUIRED') AS mode,
column_name AS name,
data_type AS type)
ORDER BY ordinal_position), TRUE) AS schema4. Schema 수정
-
텍스트 편집기(ex. cloud shell의 pen 아이콘 > 기본 편집기)를 열어 필요에 따라 컬럼의 타입 변경
Question
이거 정확히 어디에서 진행하는지 확인하기 > 그리고 다른 텍스트 편집기 어떻게 쓰는지 확인하기 -
수정 후 데이터 로드 시 스키마 파일도 함께 지정해주기
- Schema를 직접 지정할 경우에는 csv파일에서 header 정보를 갖고있는 첫번째 row는 무시하도록 설정해야 함
load --null_marker=NULL --replace \
--source_format=CSV \
--schema=schema.json --skip_leading_rows = 1
ch04.college_scorecard \
./college_scorecard.csv.gz - 결과적으로 데이터를 로드할 때, Schema를 지정해주었기 때문에,
SAFE_CAST를 하나 하나 지정할 필요 없음
4. 데이터 수정
1. 필요 데이터만 새로운 테이블에 복사
CREATE TABLE이용- 이와 같이 ETL Pipeline을 이르게 사용하면 데이터는 깔끔해지긴 하지만 해당 결정은 돌이킬 수 없기도 하다
CREATE OR REPLACE TABLE ch04.college_scorecard_etl AS SELECT 블라블라 FROM ch04.college_scorecard
2. 데이터 삭제
- terminal 사용
bq rm <dataset>.<table> # 하나 table 제거
bq rm -r -f <dataset> # -r : 재귀적으로 -f : 경고 없이 dataset 안의 모든 table 삭제
bq rm -r <folder> # folder 삭제시 -r 필수적- SQL 사용
DROP TABLE IF EXISTS <dataset>.<table>- 일정 시간 이후로 만료되게끔 설정
ALTER TABLE SET OPTION
ALTER TABLE <dataset>.<table>
SET OPTIONS(
expiration_timestamp = TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 7 DAYS),
description = "블라블라"
)- 특정 조건 row만 삭제
DELETE FROM <dataset>.<table>
WHERE <row> IS NULL
CREATE TABLE,ALTER TABLE,DROP TABLE> 이런 애들은 DDL(Data Definition Language) 데이터 정의 언어
3. 데이터 추가
- 데이터 추가
INSERT <dataset>.<table>
(원래있던 컬럼 이름들,
블라블라)
VALUES(각 컬럼에 들어갈 데이터들),
(각 컬럼에 들어갈 데이터들)- 테이블 복사
- Subquery를 이용하여 한 테이블의 값을 다른 테이블로 복사
INSERT <dataset>.<table>
SELECT *
FROM <dataset><table2>
WHERE col_a IS NULL
DELETE,INSERT,MERGE> DML(Data Manipulation Language) 데이터 조작 언어
- terminal 이용 :
bq cp_-a|--append_table: 첨부 //-noappend_table: 교체
SQL 쿼리문보다bq cp가 쿼리 비용이 들지 않고 메타데이터만 복사하기 때문에 빠름
bq cp <dataset>.<table>
someds.<table2>5. 데이터 로드
- 파일 형식
-
CSV : 비효율적이며 배열이나 구조체를 표현할 수 없어서 표현력이 떨어짐
-
AVRO 아브로
- 빅쿼리로 데이터를 로드하고 파일 삭제할 경우 선택
장점
- 바이너리 파일 사용
- 계층구조 표현
- 블록단위로 분리되어 압축 가능
- 데이터를 병력로 로드 및 병렬로 내보낼 수 있음
- 데이터 용량이 적어짐
- 자기 기술적(스키마 지정하지 않아도 됨, 파일 자체가 스키마를 포함하고 있음)
단점
- 사람이 읽을 수 없는 형식
- 줄 단위로 저장됨
-
Parquet 파케이
- 통합 쿼리를 위해 파일 계속 보유시 파케이 선택
장점
- 아브로 장점 동일 : 바이너리형식, 블록 단위, 작은 크기, 계층 구조, 자기 기술적
- 컬럼 단위 저장
단점
- 보통 데이터 로드시에 모든 컬럼을 읽어야 하기 때문에 컬럼 단위 저장 방식이 데이터 로드에는 덜 효율적
그러나 통합쿼리 실행시에는 컬럼형 파일 형식인 파케이가 아브로보다 나음 -
ORC(Optimized Row Columnar) : 파케이와 비슷
-
JSON : 가독성과 표현력이 중요할 경우 선택, 그러나 용량 큼
현재 압축된 CSV, JSON 파일의 로딩은 최대 4GB. 그보다 큰 데이터셋이면 여러개로 분할해야 함
- 데이터 로드
- 빅쿼리는 데이터 로드에 대해서는 요금을 청구하지 않음
- 압축된 파일은 전송에 유리하고 용량이 작아 공간을 적게 차지하지만, 데이터 로드시에는 더 느림(네트워크 로드 시간이 오래 걸림)
- CSV, JSON같은 형식은 압축을 지원하지 않아 gzip을 이용해 압축을 할지 선택해야 함
gsutil cp로 여러 스레드를 활용해 데이터 업로드 가능- 데이터가 Google Cloud Storage에 있다면
bq load로 업로드 가능
gsutil -m cp *.csv gs://파일_위치
bq load ... gs://파일_위치/*.csv파일을 GCS에 스테이징하고 데이터를 로드하는 경우가 존재하고, GCS에 스테이징 하지 않고 데이터를 로드하는 경우가 존재
파일을 GCS에 스테이징하면 최소한 빅쿼리가 로드 작업을 완료하기 전까지 스토리지 비용이 청구됨
GCS에 스테이징된 데이터를 로드하면 네트워크 전송 시간이 소요되고, 빅쿼리로의 로드 시간이 소요됨
압축하지 않은 파일을 빅쿼리로 데이터를 로드하면 빠르지만, 파일을 네트워크로 전송하는 시간이 느려서 해당 장점을 상쇄GCS 스테이징 데이터 > 네트워크 전송 > 빅쿼리로 로드 > 데이터 로드 완료
6. 통합 쿼리 & 외부 쿼리
1. 통합 쿼리
- 데이터 로드 없이 쿼리 엔진으로만 빅쿼리 사용 가능 (빅쿼리를 이용해 외부 데이터 원본에 쿼리를 실행)
- 통합쿼리(Federated query)를 이용해 외부 데이터 원본을 쿼리할 수 있음
- 외부 데이터란 Google Cloud Storage, Cloud Bigtable, Cloud SQL, Google Drive etc.
bq mkdef(테이블 정의 생성) >bq mk테이블 생성하고 외부 테이블 정의 전달 > 테이블 쿼리- 통합 쿼리는 편리하기는 하지만 쿼리의 실행에 앞서 얼마나 많은 데이터를 빅쿼리가 스캔해야 하는지 예측 불가함 (CSV 파일은 줄 단위 저장이고 임의의 순서 정렬이기 때문에 빅쿼리와 관련된 효율적인 부분이 적용 불가함)
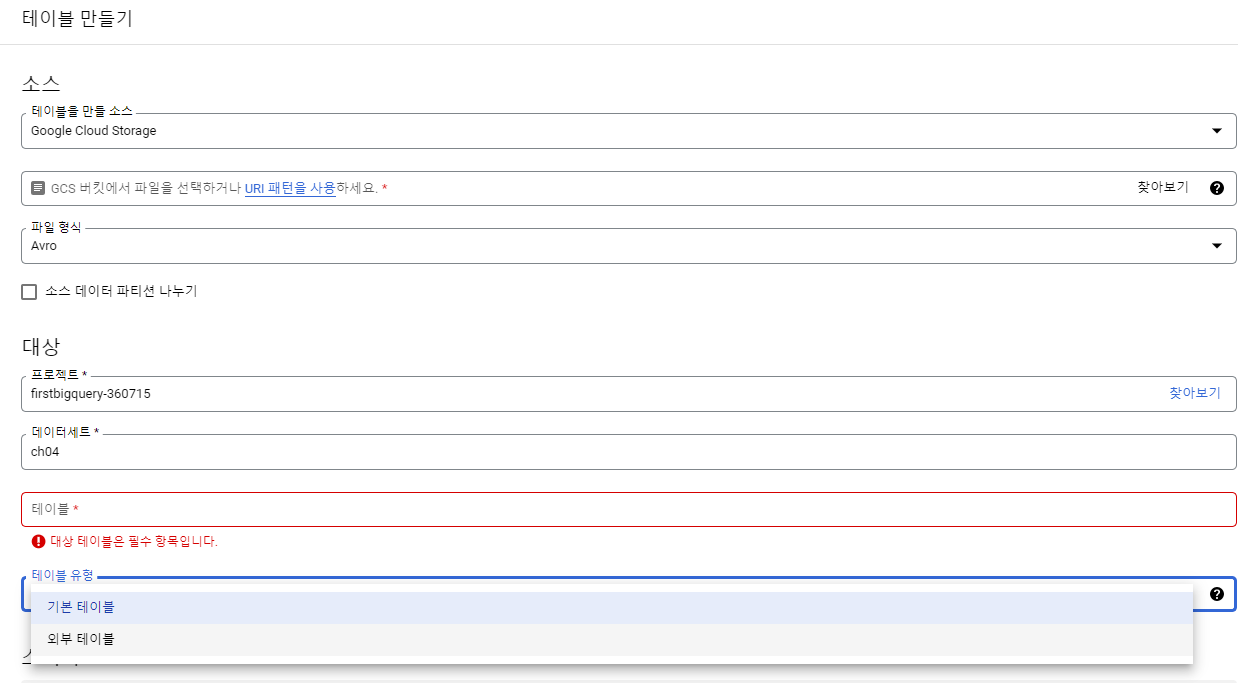
- 테이블 생성
-
UI로 테이블 생성: 꼭 외부 테이블 Type을 선택해야 함
-
terminal 사용
bq mkdef로 테이블 정의를 생성(테이블 정의 파일을 standard output에 출력) > 해당 출력 결과 파일에 기록 후 테이블 생성하는bq mk명령 실행시 param으로 전달
- 아래 코드를 통해 <테이블명> 테이블을 쿼리할 수 있지만 이건 GCS에 저장된 CSV 파일 대상이 아니고, 데이터 자체도 빅쿼리의 Native Storage에 적재되지 않음
bq mkdef --source_format=CSV \ # 테이블 정의 생성
--autodetect \
gs://파일위치/파일명.csv \ # *로 정의에 맞는 모든 파일을 참조하는 테이블을 만들 수도 있음
> /tmp/테이블이름.json
bq mk --external_table_definiton = /tmp/테이블이름.json \
<데이터셋>.<테이블명>
- 테이블 생성 + Query
mkdef,mk,query를 한번에(테이블 정의 param + query) 전달하면 쿼리가 실행되는 동안에만 테이블 정의 사용 가능함
LOC="--location US"
INPUT=gs://bigquery-oreilly-book/college_scorecard.csv
SCHEMA=$(gsutil cat $INPUT | head -1 | awk -F, '{ORS=","}{for (i=1; i <= NF; i++){ print $i":STRING"; }}' | sed 's/,$//g'| cut -b 4- )
bq $LOC query \
--external_table_definition=cstable::${SCHEMA}@CSV=${INPUT} \
'SELECT SUM(IF(SAT_AVG != "NULL", 1, 0))/COUNT(SAT_AVG) FROM cstable'
# 이미 테이블 정의 파일 갖고 있으면 아래와 같이 지정할 수 있음
# --external_table_definition=cstable;;${DEF}Question SCHEMA 이거 무슨 뜻이야 > 미리 지정해놓은 variable은 $variable_name 해놓으면 가져와지는거 같긴한데
- Parquet와 ORC의 로드 및 쿼리
- 컬럼형 데이터 형식
- CSV, JSON과 같은 줄단위 형식 파일에 저장된 데이터를 쿼리하는 것보다 성능이 좋음 (less than Bigquery의 Native Capacitor Storage)
- 파일 자체가 스키마를 포함하고 있기 때문에 스키마를 따로 명시하지 않고 테이블 정의를 생성할 수 있음
bq mkdef --source_format=PARQUET gs://폴더/files* > table_def.json
bq mk --external_table_definiton = table_def.json <dataset>.<table>
- Hive 파티션의 로드 및 쿼리
- 통합쿼리 사용 권장 Environment
외부 데이터 쿼리는 빅쿼리 네이티브 데이터를 쿼리하는 것보다 느리고, 빈번하게 접근해야 하는 데이터에는 권장하지 않지만 권장하는 경우가 존재함
- 빅쿼리로 로드하기 전 데이터 변환을 연구하기 위한 목적, 혹은 외부 데이터를 스테이징해서 통합쿼리로 데이터 변환 후 운영 테이블에 기록 가능
- 데이터에 대한 쿼리가 빈번하지 않은 경우
2. 외부 쿼리 External Query
-
외부 데이터베이스의 쿼리를 실행하고 그 결과를 빅쿼리에 저장된 데이터의 결과와 유기적으로 결합
-
현재는 Cloud SQL내의 MySQL과 PostgresSQL 데이터베이스 지원
-
외부 쿼리를 사용하려면 빅쿼리 안에 연결 자원 생성 > 사용자에게 권한 할당
-
외부 데이터 베이스의 성능에 의존하고, 임시 테이블을 사용하기 때문에 클라우드 SQL이나 빅쿼리에서 실행되는 쿼리보다 느림
-
그러나 데이터를 옮길 필요가 없어서 ETL, 예약, Orchestration이 불필요하고 실시간으로 RDBMS에 저장된 데이터를 쿼리할 수 있는 장점
-
외부 데이터베이스와 빅쿼리 데이터를 연결해서 쿼리 날릴 수 있음
-
EXTERNAL_QUERY로 사용
SELECT * FROM EXTERNAL_QUERY(<외부 데이터베이스 이름>, cloud_sql_query)SELECT
c.customer_id
, c.gift_card_balance
, rq.latest_order_date
FROM ch04.gift_cards AS c
LEFT OUTER JOIN EXTERNAL_QUERY(
'<외부 데이터베이스 이름>',
'''SELECT customer_id, MAX(order_date) AS latest_order_date
FROM orders
GROUP BY customer_id''') AS rq ON rq.customer_iㅉd = c.customer_id
WHERE c.gift_card_balance > 100
ORDER BY rq.latest_order_date ASC;3. Google Sheet 데이터 Query
- Google Drive > Spreadesheet 가져오기
- UI로 Google Drive에서 Google Sheet 가져오는 테이블 생성 > (스키마 자동 감지) > Query
# Google Sheet 데이터를 a_dataset이라는 데이터셋, b_table 이라는 테이블로 만들었을 때 아래와 같이 쿼리
SELECT * FROM a_dataset.b_table- 사용하는 경우
- 빅쿼리 데이터 이용해 스프레드 시트 생성하는 경우
Google Sheet > Data > Data Connectors > BigQuery > 프로젝트 선택 (이때 비용 발생) > 테이블에서 쿼리 작성 - 시트를 이용해 테이블 조회하는 경우
- 시트의 데이터를 SQL을 이용해 쿼리하는 경우
- 빅쿼리 데이터 이용해 스프레드 시트 생성하는 경우
- 용량이 작아 전체 테이블이 sheet에 로드되면 셀을 편집하고 변경된 spreadsheet를 변경할 수 있지만, 용량이 높아 500행만 들고오는 경우(미리보기라 생각하면 됨) 데이터시트를 필터링, 테이블 피봇만 가능함 > 이런 기능들도 전체 빅쿼리 테이블에 적용됨
4. Cloud BigTable SQL Query
Cloud BigTable은 관리형 NoSQL 데이터베이스 서비스(구글운영)
