SGM(Seeded Graph Maching) Network를 알아보자!
시작하며,
직전에 소개한 superglue에서 조금 더 진화한 network인 Seeded Graph Matching network에 대한 글을 써보려고 합니다. superglue는 query, key, value를 활용해 self-, cross- attention을 적용하였습니다. 여전히, attention은 computation이 굉장히 heavy 하므로 좀 더 효율적인 방법론들이 후속적으로 연구되고 있습니다. SGM은 attention에 seeding을 사용해 sparse 하게 만듦으로써 보다 효율적인 network를 구성할 수 있게 하였습니다. 아래에 관련 자료의 주소를 첨부합니다.
superglue 리뷰: https://velog.io/@jpseo99/SuperGlue-%ED%86%BA%EC%95%84%EB%B3%B4%EA%B8%B0
논문 주소: https://openaccess.thecvf.com/content/ICCV2021/papers/Chen_Learning_To_Match_Features_With_Seeded_Graph_Matching_Network_ICCV_2021_paper.pdf
Learning to Match Features with seeded Graph Matching Network
0. Abstract
SGMNet은 불필요한 connectivity를 제거하고 압축적인 표현력을 배울 수 있는 sparse 구조의 neural net입니다. 이 논문은 아래 두 개의 contribution이 있습니다.
1) Seeding Module: seeds를 적용해 small set의 reliable 한 matches만을 구성합니다.
2) Seeded Graph Neural Network: seed matches를 활용해 이미지 간의 (cross/within) message를 passing 합니다. (최초로 attentional pooling, seed filtering, attentional unpooling 방법을 제시했습니다.)
1. Introduction
지난 몇 년간, 학습할 수 있는 matching 방법론을 고안하기 위한 각고의 노력이 있었습니다. 이와 같은 결의 연구인 PointNet 계열의 networks는 잠정적인 correspondences에서 outliers를 제거했습니다. 이 연구들에서 correspondences는 permutation 불변의 networks에 통과되어 inlier의 scores를 얻어낼 수 있습니다. 좋은 결과에도 불구하고 이 방법론들은 두 측면에서 한계가 존재합니다.
1) pre-matched correspondences 상에서 수행됩니다.
2) local visual descriptor와 같은 결정적인 정보를 무시하고 기하학적 분포만을 추론합니다.
또 다른 결의 연구는 feature matching과 graph matching problem을 연관을 지어 해결합니다. superglue라는 대표적인 시도는 visual 그리고 geometric 문맥의 message passing을 적용해 image keypoints를 기반으로 한 densely connected graph를 생성했습니다. 압도적인 성능에도 불구하고 keypoints가 늘어날수록 그에 비례하여 계산량이 늘어난다는 단점이 있습니다. 모든 노드에 대해서 message passing을 진행하므로 이에 대한 시간복잡도가 입니다(는 각각 key points 개수, channel의 dimension). 이에 따라, 더 효율적인 message passing 연산을 탐구해보기로 했습니다.
또, redundant 한 정보가 많은 superglue는 computation 이외에도 아래의 문제가 있습니다.
densely connected graph에서 message passing을 하는 과정에서 contaminated 된 outliers가 포함되어 정보추출을 방해할 수 있습니다.
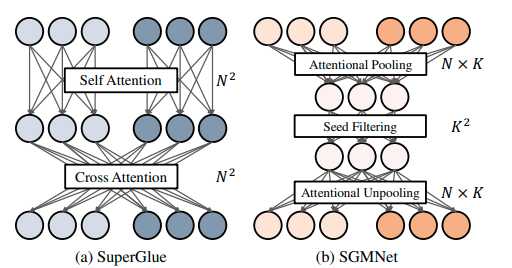
위의 그림처럼 SGMNet은 Attentional pooling, Seed Filtering, Attentional Unpooling을 활용해 Superglue보다 시간복잡도를 훨씬 낮출 수 있었습니다. 아래에 이 논문의 contribution을 정리했습니다.
1) seeding 방식은 graph matching 프레임워크에 적용되어 효율적으로 inlier compatibility를 밝힐 수 있었습니다.
2) SGMNet을 sparse graph neural network로써 clean message passing을 가능케 합니다.
3) 실험 결과, SGMNet은 Superglue보다 GPU 메모리를 절반밖에 차지하지 않지만 7배 더 빠른 결과를 관찰할 수 있었습니다.
2. Related Works
Learnable image matching
learnable image matching을 발전시키기 위한 두 갈래의 시도가 있습니다. 하나는 local descriptors와 key points를 잘 추출하는데 집중하는 것이고 다른 하나는 image matching에 outlier rejection의 기능을 수행하는 embed learning을 적용하는 것입니다. 후자의 대표적인 예시로 superglue가 있습니다. 한편, superglue는 fully connected self/cross attention으로 인한 많은 양의 computation이 필요하다는 단점이 있습니다. 이를 해결함과 동시에 계산적/저장적 비용을 절감해준 SGMNet은 아래의 개선점이 있습니다.
SGMNet은 image matching에 특화된 efficient attention block의 활용으로 computation과 memory 측면에서 cost를 절감해줬습니다.
Efficient transformer architectures
transformer의 가장 큰 문제는 quadratic complexity를 가진다는 점입니다. 따라서 큰 규모의 query, key에 대해서 많은 어려움을 겪습니다. 이를 해결하기 위한 많은 연구가 진행되었습니다. predefined sparse attention을 활용해 computation을 절감하고 또, grouping이나 pooling의 아이디어를 활용하기도 했습니다. 하지만, 이들은 주로 self-attention에 초점을 두었고 두 set으로부터 각각 추출한(cross-attention 관련) unaligned 된 key와 query에 관한 연구는 여전히 되지 않았습니다. 우리는 induced set attention에서 아이디어에 착안해 연구를 진행했습니다.
Graph matching
Graph matching은 graph의 node 간의 correspondence를 생성합니다. QAP(quadratic assignment problem)라는 수학적 구성으로 해결할 수 있으며 NP-hard 문제는 어마어마한 계산량을 요구합니다. 하지만, pre-matched correspondence를 활용한 seeded matching을 통한 approximated solution을 구할 수 있습니다. SGMNet은 Seeded Graph Matching에서 영감을 받아 compact message passing과 robust matching을 위한 seed를 GNN framework에 주입했습니다.
3. Methology
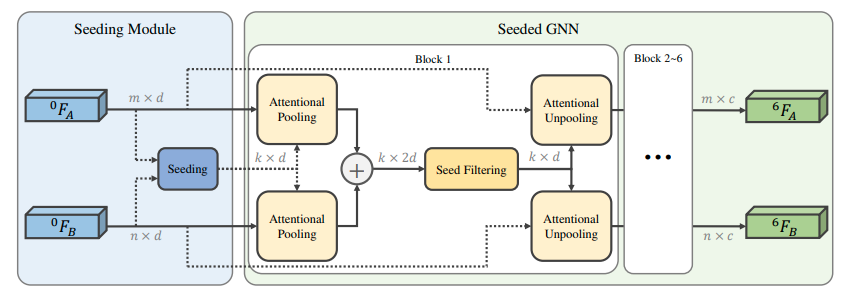
SGMNet은 두 sets의 keypoints와 visual descriptors의 correspondences를 학습합니다. 위의 그림에서 보실 수 있다시피 SGMNet은 compact message passing을 위한 Seeding Module과 per-node feature를 업데이트 하기위한 Seeded Graph Neural Network로 구성되어있습니다. 기존의 fully connected graph와 다르게 seed matches를 활용해 두 그래프 간의 matching(A, B 간의 edge)을 생성합니다. 이는 memory와 computation cost를 압도적으로 줄일 수 있습니다. 아래의 notation을 정의합니다.
: 각각 A와 B에서의 keypoints set을 나타냅니다.
{, }: A 혹은 B 둘 중 하나를 나타내는 이미지의 notation
: 이미지 I의 i번째 원소입니다. (position)과 (visual descriptor)로 구성되어있으며 는 x와 y의 좌표입니다.
3.1. overview
이미지 A와 B에 각각 n개 m개의 keypoints와 visual descriptors가 있다고 가정합니다. 이들은 각각 α = {1, ..., n}, β = {1, ..., m}의 index를 가지고 있습니다. 우리의 목표는 두 이미지 간의 reliable and robust match를 찾아내는 것입니다.
keypoints의 positions은 아래와 같이 descriptor와 합쳐져 initial representation을 구성합니다.
Seeding Module은 Seed matches S를 형성합니다. 그리고 S는 Seeded Graph Neural Network에 들어가 반복적으로 update 됩니다. OANet의 cascade refinement structure에서 영감을 받아 더욱더 정교한 feature를 얻습니다. 최종적인 match는 assignment matrix에 의해 구할 수 있습니다.
3.2. seeding Module
결론적으로 seeding Module은 α = {1, ..., n}, β = {1, ..., m}를 sparse 하게 활용할 수 있게 해줍니다. seeding Module은 output으로 가집니다. 는 각각 α, β의 부분집합입니다. NonMaximum Suppression (NMS) 방식으로 seeding을 진행합니다. 이때의 score은 아래와 같이 inverse of distance ratio을 활용했습니다.
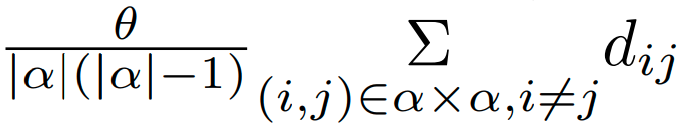
는 두 keypoints 간의 거리입니다. |.|은 집합의 크기를 나타내는 것이고 θ는 hyper parameter입니다. 실험에서는 으로 두었습니다.
3.3. seeded Graph Neural Network (Seeded GNN)
Seeded GNN은 seed matches S와 initial position-embedded features 을 활용해 message passing을 전개해나갑니다. 각 processing unit에 pooling -processing-unpooling 방식을 채택했습니다. seed features는 Attentional Pooling을 통과한 우선 모든 point sets를 취합합니다. 그 뒤, Seed Filtering을 활용해 processing을 진행하고 Attentional Unpooling을 통과시켜 본래의 크기로 feature가 복구됩니다. 우리의 Seeded GNN은 6개의 refinement를 진행합니다.
Weighted attentional aggregation
더욱 첨예하고 정제된 data 의존적인 message passing을 위해서 attentional aggregation을 진행했습니다. d의 차원을 가지는 두 feature set X와 Y 그리고 weight vector w를 생각합니다. () weighted attentional aggregation 연산인 Att는 아래와 같이 정의합니다.
: X의 linear projection
: Y의 linear projection
attentional aggregation을 통해 X는 Y의 정보가 주입됩니다. weight vector w는 V의 element의 importance의 섬세한 고려를 할 수 있습니다.
Attentional pooling
Seeding Module에서 얻은 와 그리고 연산을 종합해 3가지 연산을 순차적으로 거치게 됩니다.
: t번째 layer을 통과한 image I의 feature set
: t번째 layer을 통과한 image I의
1)
2)
3)
는 다음 seed filtering의 input으로 활용됩니다. 1)은 seeded index를 clipping 하는 작업, 2)는 1)의 결과와 full keypoint set과의 self-attention, 3) refinement로 생각할 수 있습니다.
Seed filtering
Seed filtering은 다음 두가지 목표가 있습니다.
1) seed matches간의 intra/inter-graph communication
2) outlier seed matches의 영향력 억제하기
1)은 아래의 방식으로 진행할 수 있습니다.
Intra-graph communication:
Inter-graph communication:
차후, unpooling stage를 위해서 inlier likelihood scores γ를 lightweight stacked context normalization blocks을 활용해 다음과 같이 구합니다.

이 모듈의 outputs은 filtered features 과 inlier scores 입니다.
Attentional unpooling
seed matches 간의 message exchange과 inlier score를 추출한 뒤에 pooled contexts를 전체 keypoint에 전달합니다. attentional unpooling은 inlier score를 weight로 하는 weighted attentional aggregation입니다.
inlier score는 aggregation process에 적용되어 false seed matches의 정보를 억제하는 역할을 합니다.
Assignment matrix formulation
모든 유닛의 가공을 끝내고 Sinkhorn algorithm을 활용해 assignment matrix를 구성합니다.
correlation matrix of features과 dustbin channel을 생각하여 assignment matrix M을 구합니다. z는 learnable parameter입니다.
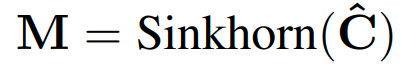
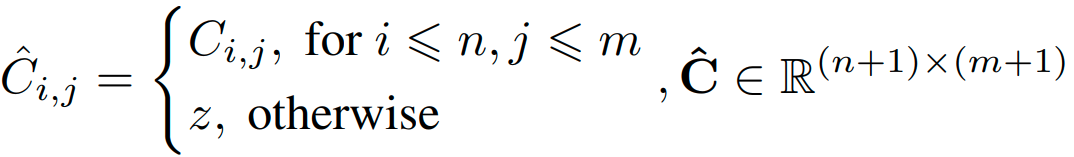
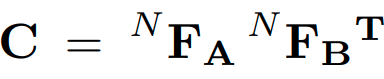
3.4. Reseeding
initial seeding은 잠재된 match를 구별해낼 수 있는 능력이 있지만, updated feature를 활용하는 두 번째 seeding module은 더욱 깨끗하고 풍성한 seeds를 제공해서 성능의 향상될 수 있습니다. 따라서, 우리는 reseeding 모듈을 채택했습니다. 첫 번째 seeding 모듈과 다르게 reseeding module은 assignment matrix M을 활용해서 seeds를 생성합니다. 구체적으로 top-k개의 scores를 가지는 matches를 선택해서 reseeding을 진행합니다.
3.5. Loss
superglue와 같아 생략했습니다.
마치며,
superglue의 후속 버전인 SGMNet에 대해서 알아보았습니다. 하지만 아쉽게도 저의 졸업 연구에 적용해봤을 때 accuracy 측면에서 뚜렷한 향상은 없었습니다. 그래도 attention을 좀 더 효과적으로 적용할 수 있게 seeding 한다는 점이 신비로웠습니다. 특히, reseeding을 할 때 assignment matrix M을 활용한다는 점에서 feature의 refinement가 잘 되겠다는 직감적인 감이 오더군요.
다음엔 Point Set Registration: Coherent Point Drift에 관련된 글을 적어보려고 합니다. 졸업 연구의 방향을 한 갈래 추가해서 EM 알고리즘 기반의 CPD를 활용해 물체의 transform을 파악하고 그 방향대로 로봇을 조종하면 어떨까 하는 조교님의 아이디어에서 출발했는데요! 얼른 논문 읽고 구현해보고 싶습니다.
