Data Science, Big Data
데이터 과학
데이터 과학의 개념
- 데이터를 수집한 후 분석을 통해 데이터를 정확히 이해함으로써 그 속에 숨겨진 새로운 지식을 발견하고, 이를 문제 해결에 활용하는 모든 과정의 활동을 의미
- 데이터 생성, 수집, 저장, 분석, 표현의 모든 과정과 연관됨
- 활동을 지원하는 수단이나 기술도 포함
데이터 과학의 목표
- 수집된 데이터로부터 가공된 정보를 거쳐 지식과 지혜를 추출하는 것
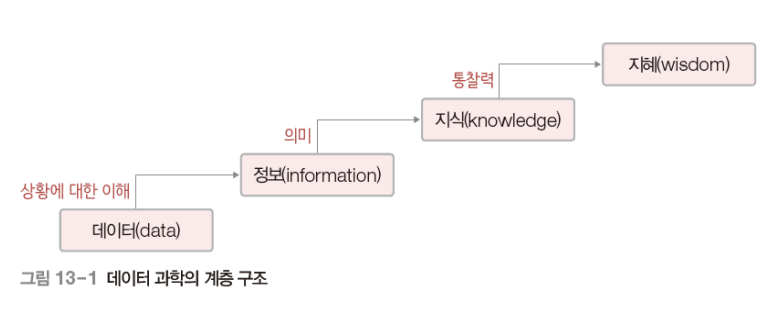
DIKW 계층 구조
- Data-Information-Knowledge-Wisdom 구조
data, 데이터
- 관찰하거나 측정하여 수집한 사실이나 값
ex) 3년간 전체 책 판매량 조사information; 정보
- 상황에 대한 이해를 바탕으로 데이터를 목적에 맞게 가공한 것
ex) 연간 분기별 책 판매량 계산knowledge, 지식
- 규칙이나 패턴을 통해 찾아낸 의미있고 유용한 정보
ex) 3분기에 책 판매량이 증가하는 원인을 찾아냄wisdom, 지혜
- 지식에 통찰력을 더해 새롭고 창의적인 아이디어를 도출한 것
ex) 3분기에 출간할 책의 콘텐츠 & 홍보 전략 기획
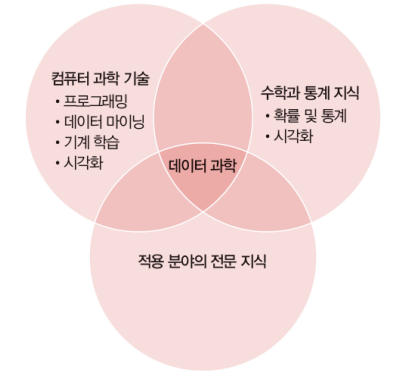
데이터 과학의 특징
빅데이터
빅데이터의 개념
좁은 정의
- 기존 DB가 저장하고 관리할 수 있는 범위를 넘어서는 대규모의 다양한 데이터
넓은 정의
- 대규모 데이터를 저장 & 관리하는 기술과 가치있는 정보를 만들기 위해 분석하는 기술까지 포함
빅데이터의 특징 (3V)
Volume; 데이터 양
- 테라바이트(TB) 단위 이상의 대량데이터
- 여러 경로를 통해 계속 생성되고 있는 많은 양의 데이터를 의미
Velocity; 속도
- 데이터의 수집과 분석을 정해진 시간 내에 처리해야 함
- 많은 양의 데이터가 생성되고 전달되는 속도가 빠르므로 수집 & 분석작업도 실시간으로 진행되어야 함
Variety; 다양성
- 형태의 다양성이 존재
- 정형 데티어: 관계 DB와 같이 정형화된 시스템에 저장된 데이터 형태
- 비정형 데이터: 구조가 정해져 있지 않은 데이터
빅데이터의 기술 - 저장 기술
하둡; Hadoop
- 대용량 데이터를 분산처리할 수 있는 Java 기반의 오픈소스 프레임워크
- 분산 파일 시스템인 HDFS (Hadoop Distributed File System) 에 데이터를 저장
- 분산 처리 시스템인 맵리듀스 (MapReduce) 를 이용해 데이터를 처리
- 오픈소스이기 때문에 기존 DB 시스템보다 비용 ↓
- 여러 대의 서버에 데이터를 분산해서 저장 → 처리 속도 ↑
NoSQL
- 관계 데이터 모델 & SQL 사용하지 않는 DB 시스템
- 일관성보다는 가용성과 확장성에 중점
- 비정형 데이터 저장을 위해 유연한 데이터 모델 지원
- 관계 DB와 동일한 데이터 처리 가능 + 비용 ↓ + 분산 처리 (O) + 병렬 처리 (O)
- ex) H베이스, 카산드라, 몽고DB, 카우치DB etc.
빅데이터의 기술 - 분석 기술
- 텍스트 마이닝 (정형 or 비정형 텍스트 → NLP → 정보 추출/가공)
- 오피니언 마이닝 (긍정, 부정, 중립 등의 선호도)
- 소셜 네트워크 분석 (영향력, 관심사, 성향, 행동 패턴)
- 군집 분석 (유사 특성의 데이터 집합 추출)
빅데이터의 기술 - 표현 기술
R언어
- 통계 계산과 다양한 시각화를 위한 언어와 개발 환경 제공
- 데이터 분석을 통해 추출한 의미와 가치를 시각적으로 표현하기 위해 사용
- 기본 통계 기법 ~ 최신 데이터 마이닝 기법까지 구현 가능
- 다양한 프로그래밍 언어와 연동 가능
- 다양한 운영체제 지원
- Hadoop 환경에서 분산 처리를 지원하는 라이브러리 제공
이전 데이터 vs 빅데이터

빅데이터 저장 기술: NoSQL
NoSQL
등장배경
- 관계 데이터베이스를 대신할 새로운 대안의 필요성
- 정형화된 데이터를 주로 처리하는 관계 데이터베이스는 빠른 속도로 대량생산되는 다양한 유형의 비정형 데이터를 저장 및 관리하는데 적합하지 않음
- 단일 컴퓨터 환경에서 주로 사용되는 관계 데이터베이스는 여러 컴퓨터가 연결되어 하나의 시스템을 구성하는 클러스터 환경에는 확장성 측면에서 비효율적임
- 새로운 대안으로 NoSQL 등장
- 관계 데이터베이스에만 의존하지 않고 필요에 따라 다른 특성을 제공하는
데이터베이스를 사용하는 것이 좋다는 의미
의미
- 빠른 속도로 생산되는 대량의 비정형 데이터를 저장 & 처리 목적
- ACID를 위한 트랜잭션 기능 제공 (X)
- 저렴한 비용으로 여러 대의 컴퓨터에 데이터를 분산/저장/처리 가능
특징
- 관계모델보다 융통성 ↑
- 스키마 없이 동작 → 데이터 구조를 미리 정의할 필요 (X) & 수시로 구조를 바꿀 수 있어 비정형 데이터를 저장하기에 적합
- 대부분 오픈소스로 제공
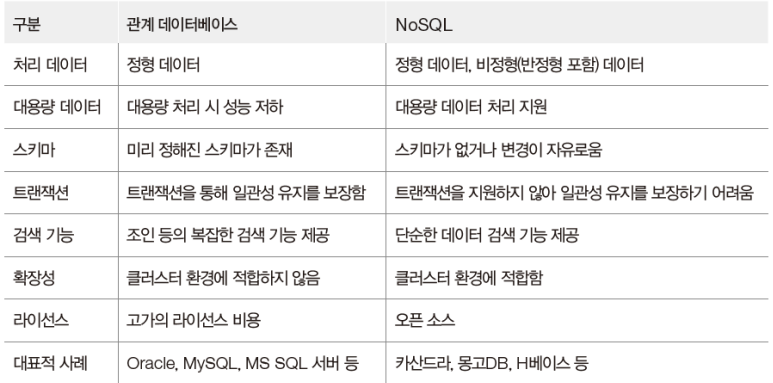
관계 DB vs NoSQL
관계 DB
- 장점
- 트랜잭션을 통해 일관성 유지
- 외래키로 테이블 간의 관계 표현 → Join과 같은 복잡한 질의 처리 가능
- 단점
- 빠른 속도로 증가하는 대량의 비정형 데이터를 저장하는데, 확장성 ↓
NoSQL
- 장점
- 트랜잭션 기능 (X) + 정해진 스키마 (X)
- 자유롭게 구조 바꿈 + 대량의 비정형 데이터 빠르게 저장 & 처리 가능
- 단점
- SQL 대신 별도의 분석기술을 이용해 데이터 분석
NoSQL은 관계 DB의 경쟁자가 아니다!
- NoSQL은 관계 DB가 적합하지 않은 새로운 환경에서 선택의 폭을 넓히기 위한 대안
- 저장될 데이터의 형태 & 처리 목적에 더 적합한 것을 선택
빅데이터 분석 기술: 데이터 마이닝
데이터 분석 기술 & 빅데이터 분석 기술
데이터 분석 기술
- 데이터 안에 숨겨진 유용한 정보, 즉 지식을 찾아내기 위해 데이터를 가공하는 역할을 담당
- DB에서 SQL문을 통해 자신이 원하는 데이터를 추출 & 분석하는 것
빅데이터 분석 기술
- 기존 데이터 분석 기술 + 빅데이터의 특징
- 다양한 형태의 비정형 데이터를 기반으로 방대한 양의 데이터 처리
- 대표적인 기술
- 데이터 마이닝, 기계학습
데이터 마이닝 vs 기계학습
각자의 목적을 위해 서로의 기법 활용
- 분석 목적이 발견 → 데이터 마이닝
- 수집된 데이터에서 숨겨진 규칙과 패턴을 찾아 가치 있는 유용한 정보인 지식을 활용하는 것
- 분석 목적이 예측 → 기계 학습
- 수집된 데이터로 프로그램을 학습시켜서 유사한 상황의 새로운 데이터가 입력되었을때 결과를 예측하는 것
데이터 마이닝
대량의 데이터 안에 숨겨진 지식을 발견하기 위해 규칙과 패턴을 찾아내는 기술
- 분류 분석
- 군집 분석
- 연관 분석
분류 분석
- 새로운 데이터가 어떤 그룹 또는 등급에 속하는지 예측하는데 주로 사용
- 미리 정의된 기준에 따라 기존 데이터의 그룹이 나뉘어 있음 (군집 분석과의 차이점)
- ex) Logistic Regression, Decision Tree, K-Nearest Neighbor, Bayes Classifier, Neural Network, Support Vector Machine, Genetic Algorithm
군집 분석
- 미리 정해진 기준이 없는 상태에서 유사한 특성을 공유하는 데이터들을 여러개의 독립적인 군집으로 나누는 것
- 군집의 개수나 형태를 미리 가정하지 않은 상태에서 데이터 간의 유사성에 기반을 두고 거리가 가까운 데이터들을 하나의 군집으로 모음
- 형성된 군집들의 특성을 파악하여 군집들 사이의 관계를 분석
- 계층적 군집 분석 & 비계층적 군집 분석이 있음
연관 분석
- 데이터 간의 발생 빈도를 분석하여 그 속에 숨겨진 연관 규칙(association rule)을 파악
- 상품이나 서비스 간의 연관 관계를 분석하여 마케팅에 주로 활용
- 장바구니 분석(market basket analysis)이라고도 함
- ex) Apriori 알고리즘

Student Dev - Language Tech & Machine Learning