단어 임베딩
단어 임베딩 (이론)
텍스트의 벡터화
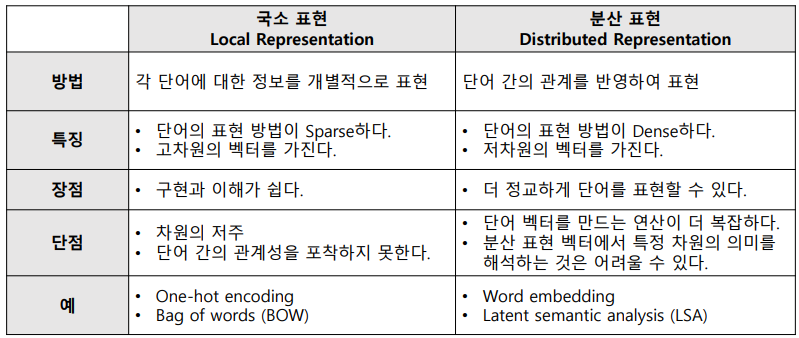
국소 표현
- 단어 자체만 보고 특정 값에 매핑하여 단어를 표현
- ex) one-hot encoding
- ex) [0, 0, 0, 1, 0, 0, 0, 0,...]
분산 표현
- 단어를 표현하기 위해 주변 정보를 참고
- ex) word embedding
- [2.13, 0.34, 1.19, 3.87,...]
국소 표현
Bag-of-Words
ex) [1, 1, 3, 1]
- 텍스트를 단어 수의 벡터로 나타냄
- 벡터의 각 차원은 어휘에서 고유한 단어를 나타냄
- 단어의 순서는 무시되고 각 단어는 서로 독립적인 것으로 취급함
(+) 단어의 빈도 정보를 사용할 수 있음
(+) one-hot encoding에 비해 저차원으로 텍스트를 표현할 수 있음
(-) 어순이 무시됨
(-) 단어 간의 관계 & 문맥 정보가 무시됨
(-) 단어가 자주 사용되지만 의미론적 가치가 거의 없는 경우 다수 존재 (ex. is, the, ...)
One-hot Encoding
ex) [1, 1, 0, 0]
- 어휘의 각 단어를 이진 벡터로 표현
- 어휘에서 해당 단어의 인덱스에 해당하는 1개의 요소를 제외하고 모든 요소가 0
- 순서를 유지하는 방식으로 단어를 나타내는데 사용
(+) 간단하게 구현 가능
(+) 직관적임
(+) 단어 순서 유지
(-) 높은 차원의 희소행렬(sparse) → 계산/메모리 문제 발생
(-) 단어 간의 관계 & 문맥 정보 무시
문제점
1. 높은 차원의 희소 행렬 문제
- 정보를 표현하는 각 점 벡터가 매우 낮은 밀도로 희소하게 퍼져있음 → 대규모 데이터 세트에서 메모리 & 계산 문제 발생
- 차원의 저주
- 특징(자질)이나 차원의 수가 증가함에 따라 ML 알고리즘의 성능이 저하되는 현상
- 공간을 커버하기 위해 필요한 학습 데이터 수가 매우 커짐
- 단어 간의 관계성 문제
- 벡터 간의 거리를 활용해 단어의 유사한 정도를 표현하기 어려움
분산 표현
워드 임베딩
- 밀집 벡터로 단어를 벡터로 표현하는 방법
- 유사한 단어가 유사한 벡터를 갖도록 단어를 벡터로 표현
(+) 축소된 차원 → 고정된 크기의 벡터 & 0인 값이 없음 (or empty값)
(-) 단어 간의 관계성 표현 가능
국소 표현 vs 분산 표현
word2vec
가설: 특정 단어의 표현은 주변 단어에 의해 정의됨
학습 방법: 유사한 문맥에서 나타난 단어들은 유사한 벡터를 가짐Two algorithms
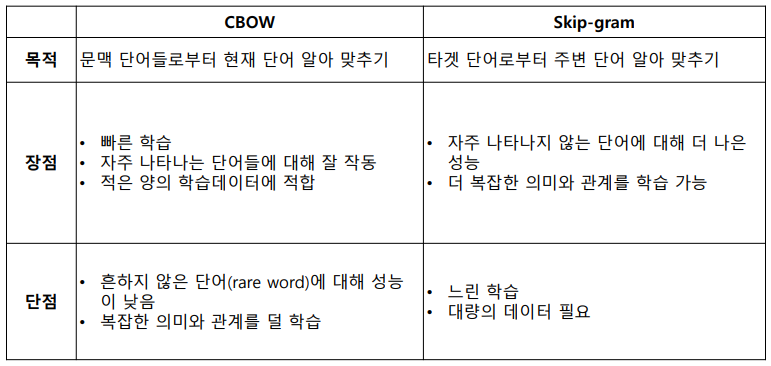
- continuous bag of words (CBOW)
- skip-gram
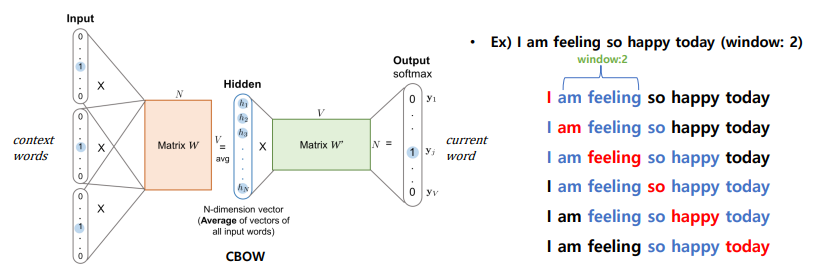
word2vec - CBOW
학습 방법: window 내에서 주변 문맥 단어가 주어졌을때, 현재 단어를 예측
- maximize P(current word | context word)
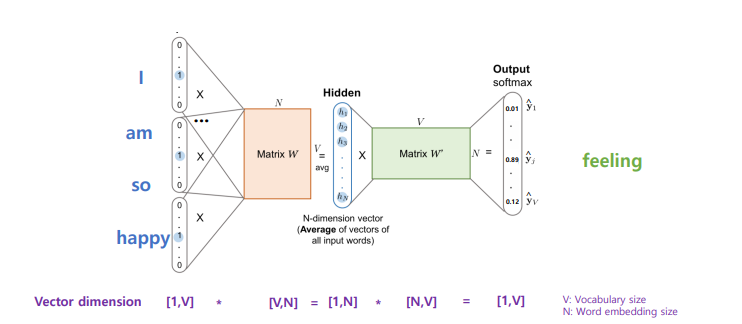
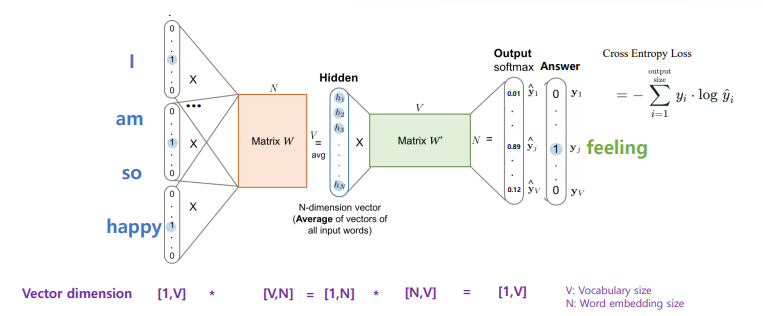
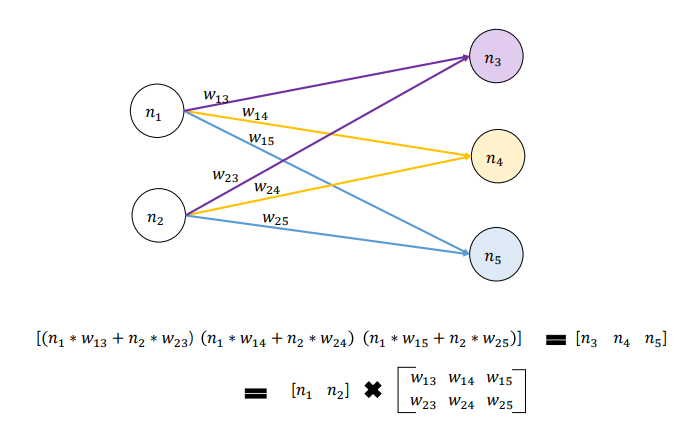
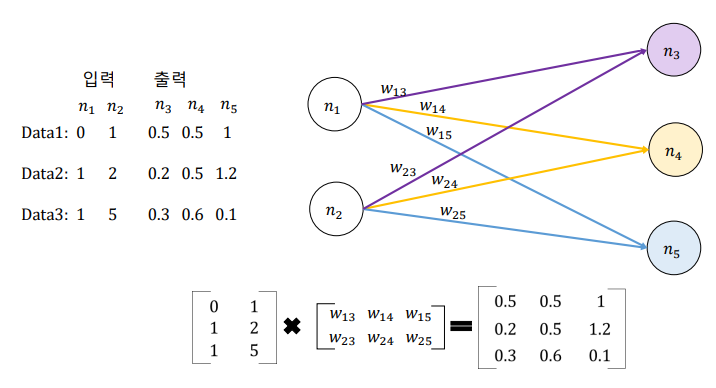
CBOW 순전파
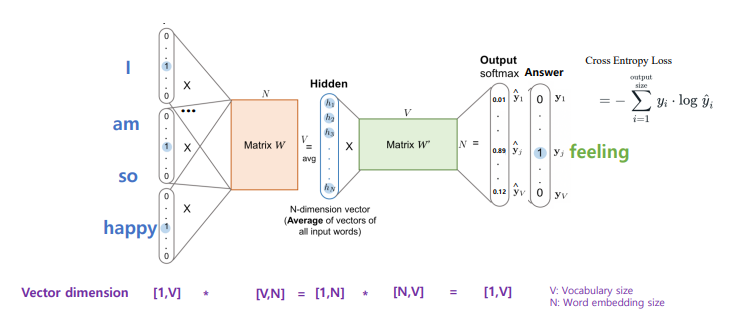
CBOW 오차 측정
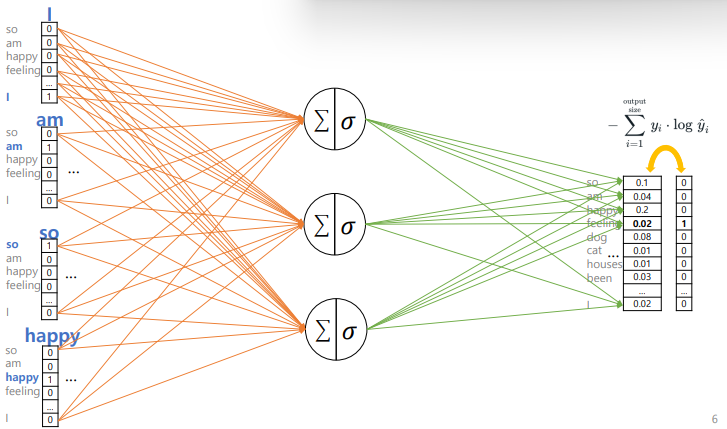
CBOW 역전파 & 가중치 업데이트
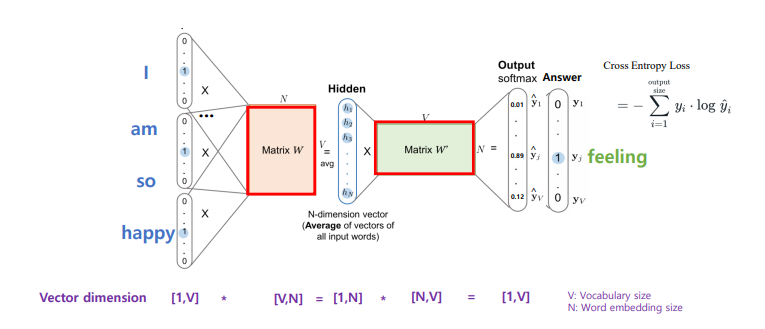
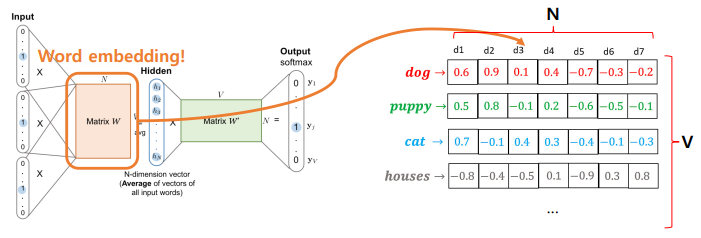
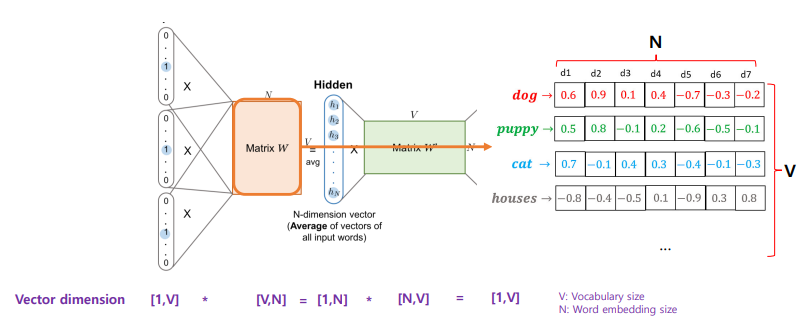
워드 임베딩 벡터 구하는 법
워드 벡터(임베딩)으로 사용하는 것은?
- Matrix W
- V*N 차원 행렬
- V차원으로 표현된 N개의 단어
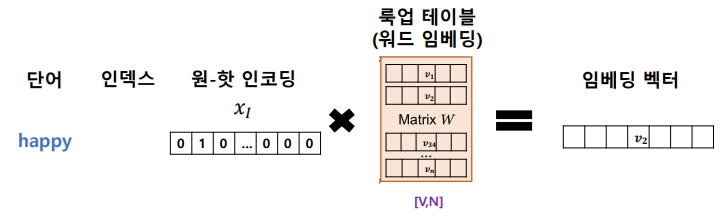
룩업 테이블
- 필요성: 가중치 행렬(W)의 번째 행(row)을 색인(lookup)하기 위해
- 번째 단어 벡터와 가중치 행렬(W)의 곱
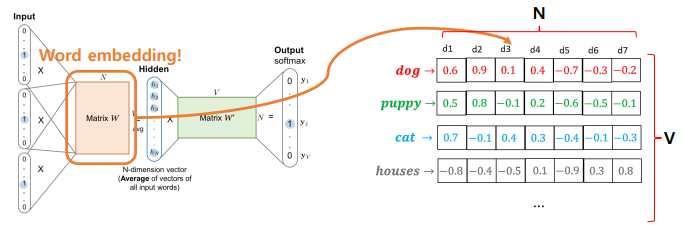
word2vec - Skip-gram
학습 방법: window 내에서 현재 단어가 주어졌을때, 주변 단어를 예측
- maximize P(context word | current word)
CBOW vs Skip-gram
워드 임베딩의 활용
word analogy
- 단어 벡터의 수학적 연산을 통해 단어 간의 의미론적 관계를 확인할 수 있음
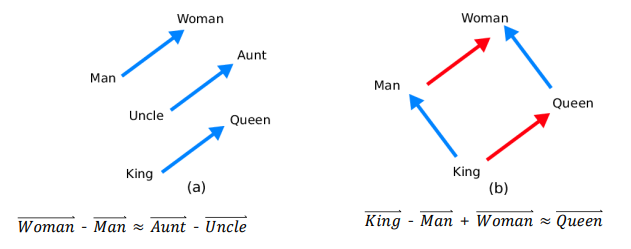
다른 임베딩 학습 방법
Glove
- word analogy방식을 직접적인 학습 목표로 삼음
- 단어들의 동시 발생 매트릭스를 사용해서 글로벌/로컬 정보를 모두 반영
- 영어 NLP 모델을 위해 많이 사용됨
FastText
- 각 단어를 여러 n-gram 집합으로 분리한 후 각 n-gram에 대한 벡터 학습
- 학습 시간이 빠름
- 어휘에 없는 단어를 처리 & 더 작은 data set에 대한 교육을 위해 선호
워드 임베딩 벡터
텍스트를 벡터로 표현하기
Classification Task
- input: 텍스트
- output: 클래스
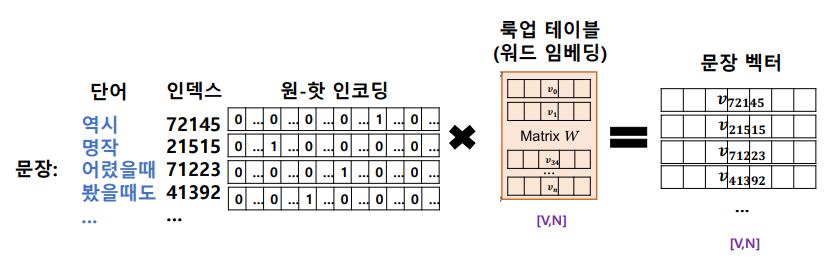
문장의 벡터 표현
단어 벡터들의 연결
- 문장에 포함된 각 단어 벡터들을 합친 것
텍스트 데이터의 연산
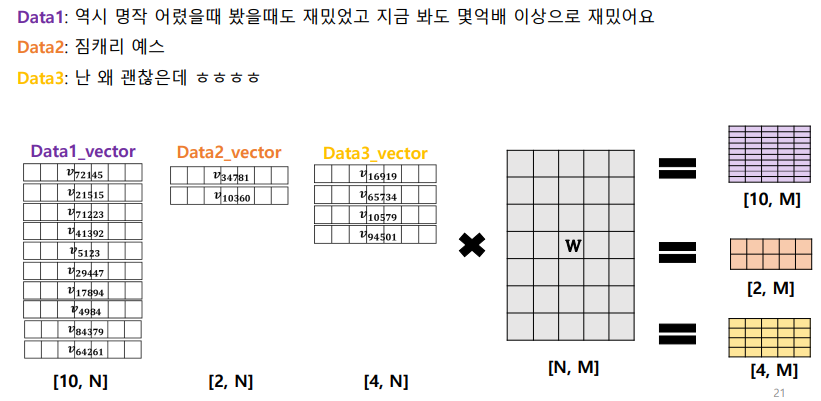
기본 구조
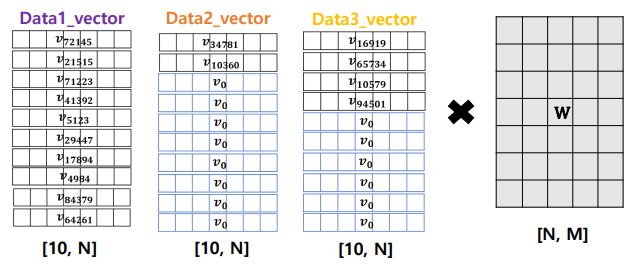
패딩
- GPU를 활용한 병렬 계산을 위해 여러 문장의 길이를 동일하게 맞추는 작업
- 를 vocab에 추가하고 특정 인덱스 부여
- cf) 단어: vocab에 없는 단어. 학습 data에 나타나지 않은 단어
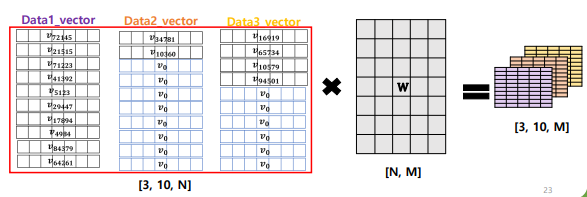
패딩 이후의 병렬 연산
- 한 배치 안의 여러 문장을 하나의 행렬로 변환
- 배치 (batch): 딥러닝 모델 학습에서 입력 data를 한번에 처리하는 데이터 묶음
- 연산 속도 ↑ & 모델 성능 ↑
- 패딩은 직접 지정하는 고정값
- ex) padding(size): 100 → 최대 100 단어로 길이를 맞춤
- 배치 안에서 최대 길이
- ex) <아래 예제> 배치 사이즈 3에서 최대 길이: 10 → 이 배치에서는 10개의 고정 길이를 맞춤
- 데이터 차원: [B, L, N(D)]
- (배치 사이즈) (배치 내 문장의 최대 길이) (임베딩 차원)

Student Dev - Language Tech & Machine Learning