Neural networks
Components of a neuron: weights, biases; trainable/learnable parameters
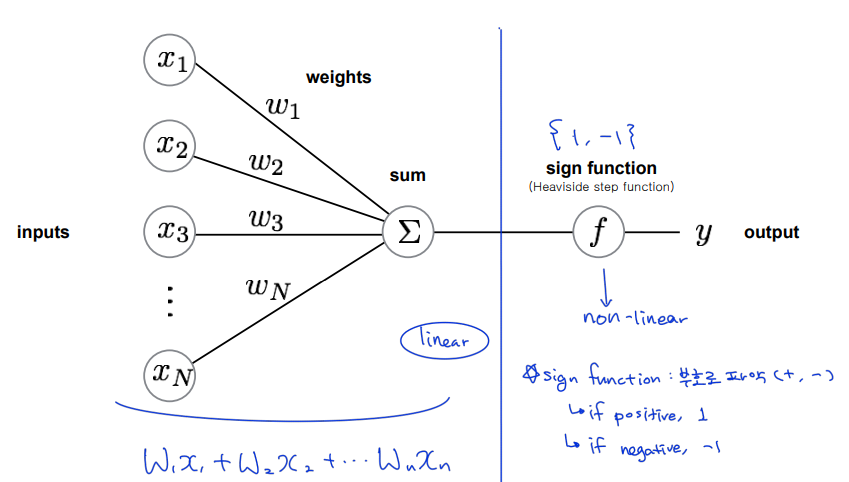
: 제곱 아님. t번째라는 뜻
: 0보다 크거나 같으면 +1 / 0보다 작으면 -1
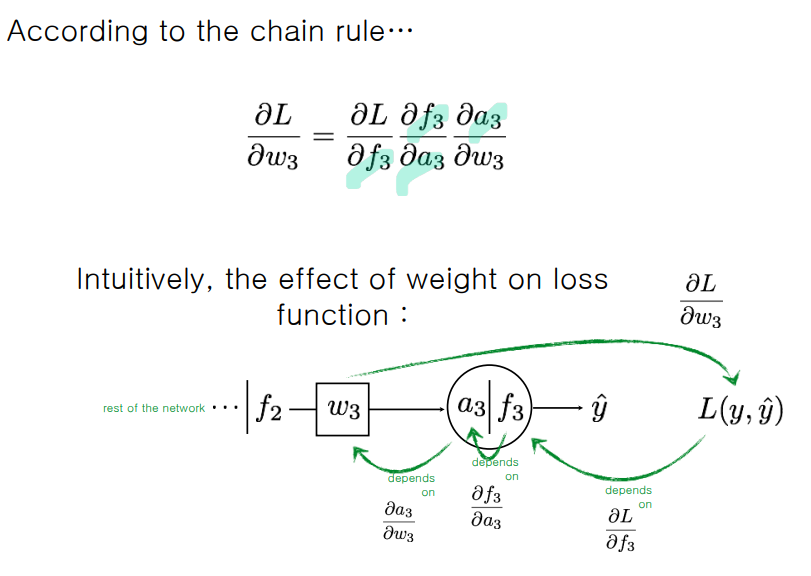
: w에 대한 미분 ()
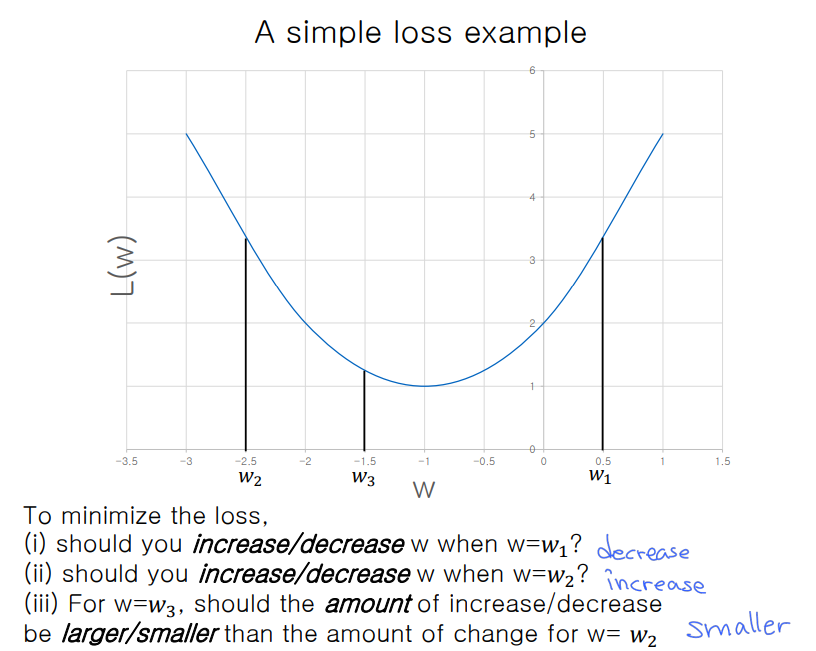
: 얼마만큼 조정?
: 조정 필요한지 여부 확인

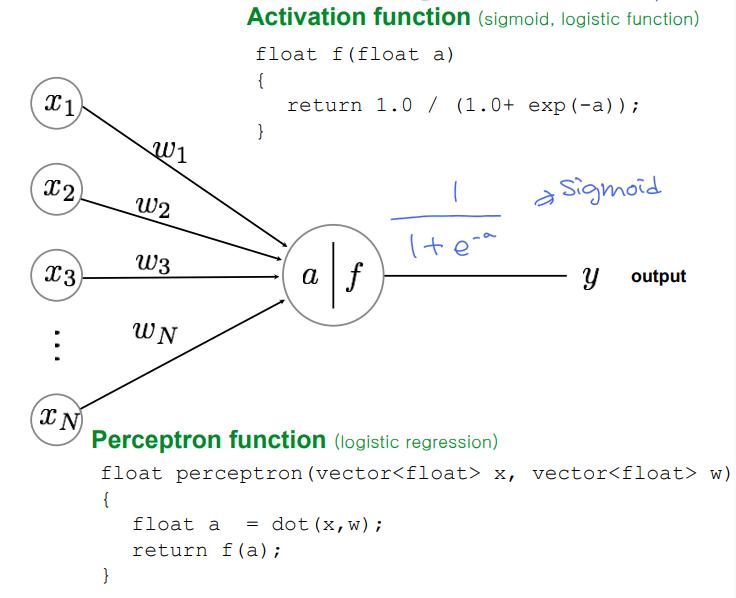
Neural network
dimensions of input/output, weights, bias; trainable/learnable parameters
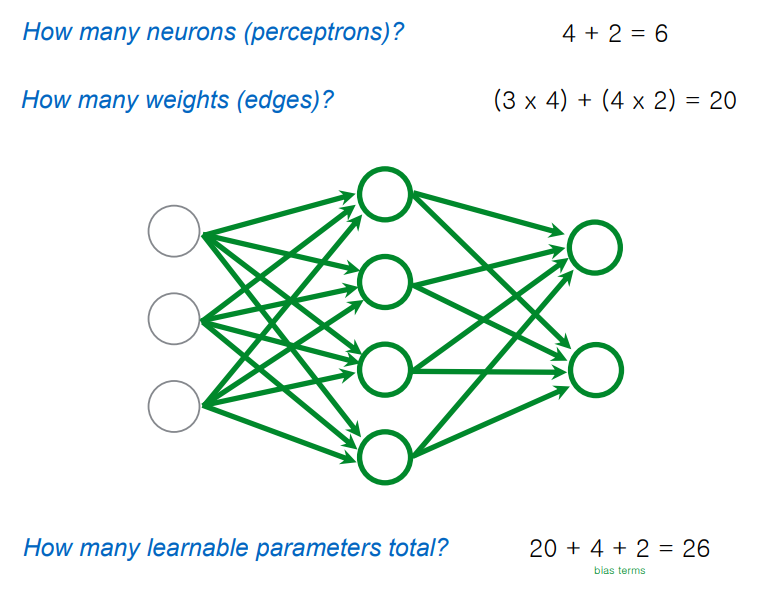
forward propagation

backward propagation (i.e. gradient propagation and parameter updates)




Activation functions: sigmoid, tanh, ReLU, softmax
Regression vs classification objective
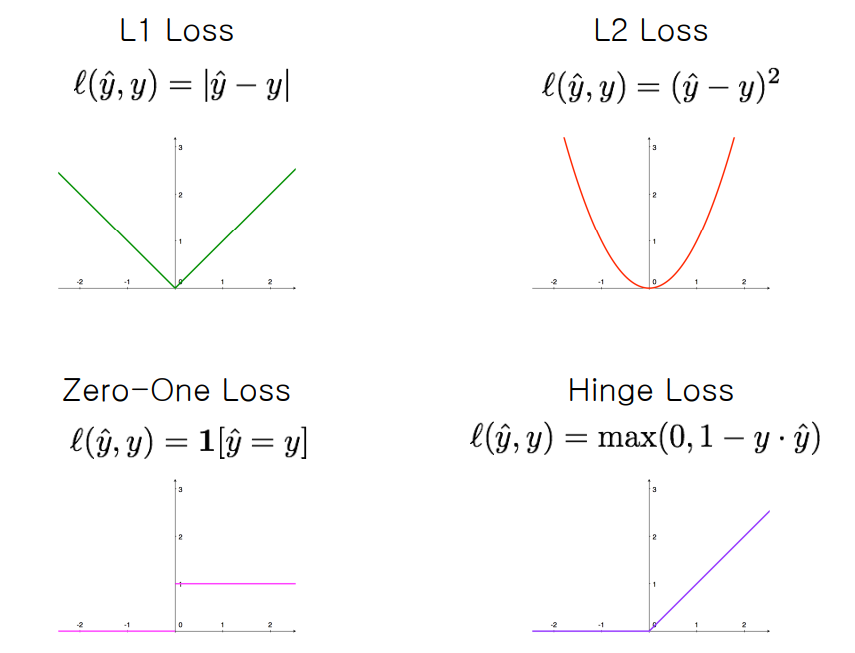
L2 loss, L1 loss, cosine loss
Cross-entropy loss, one-hot encoding

Student Dev - Language Tech & Machine Learning