Image Classification
Challenges of image classification
- camera position
- illumination
- scale
- deformation
- occlusion
- background clutter
- intra-class variations
- illumination
- deformation
- occlusion
- background clutter
- intra-class variations






Input image/text as BoW & TF-IDF
Bag of Words (→ Bag of Features)

- deals well with occlusion
- scale invariant
- rotation invariant
TF-IDF
: term frequency
: inverse document frequency
: total no.
: 문서에 단어가 있으면 1, 아니면 0
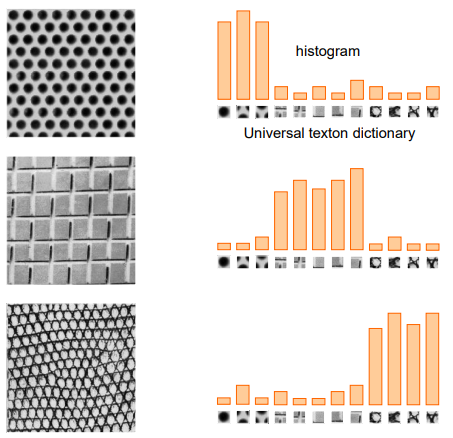
Standard BoW pipeline for image classification
Dictionary learning
- learn visual words using clustering
- extract features (e.g. SIFT) from images
- learn visual dictionary (e.g. K-means clustering)
K : 몇개의 단어를 원하는지에 따라 달라짐
- Detect patches
- Normalize patch → 스케일 fix
- Compute SIFT descriptor → SIFT feature descriptor 길이 다 같음 (길이 같아야 차원 같음 & 비교 가능)
- patch에 대한 feature histogram → 이것을 vector로 볼 수 있음
K-means clustering
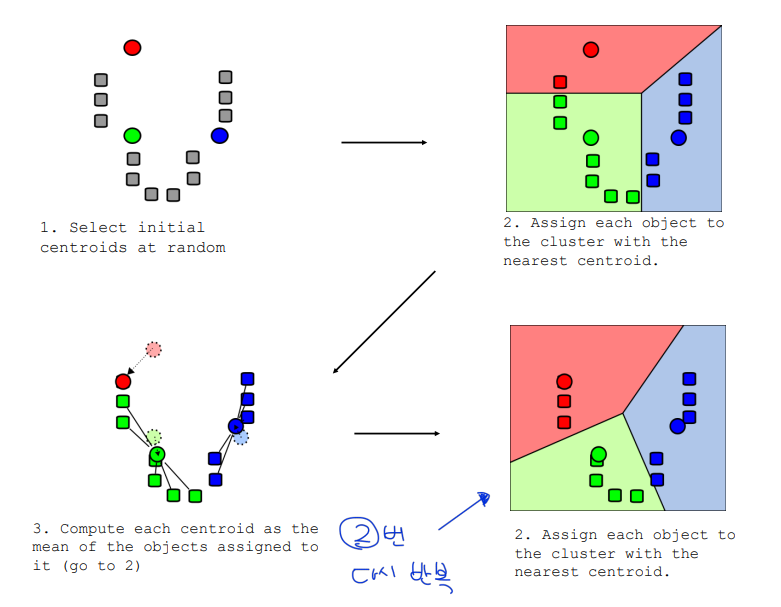
given k: 1. select initial centroids at random (number of centroids = k) 2. assign each object to the cluster with the nearest centroid 3. compute each centroid as the mean of the objects assigned to it 4. repeat previous 2 steps until no change
Encoding
- build BoW vectors for each image (= img → BoW vectors)
- histogram: count the number of visual word occurrences
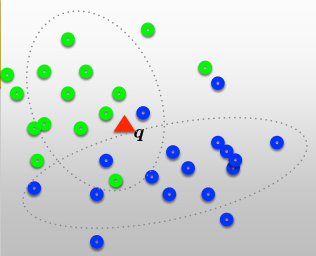
Classification using K-nearest neighbor
- train & test data using BoW → using KNN
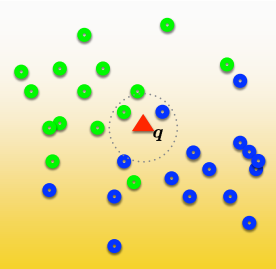
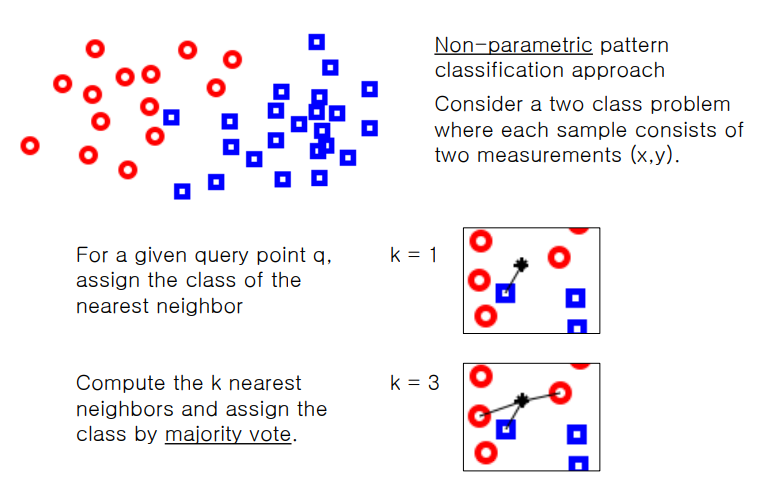
1. for a given query point q, assign the class of the nearest neighbor
2. compute the k nearest neighbors and assign the class by majorith voteDistance metric?
- typically Euclidean distance
- locality sensitive distance metrics
- important to normalize
- dimensions have different scales
how many K?
- typically k=1 is good
- cross-validation (try different k)
Pros
- simple yet effective
Cons
- search is expensive (can be sped-up)
- storage requirements
- difficulties with high-dimensional data
KNN - Complexity & Storage
training: O(1)
testing: O(MN)
→ need the opposite
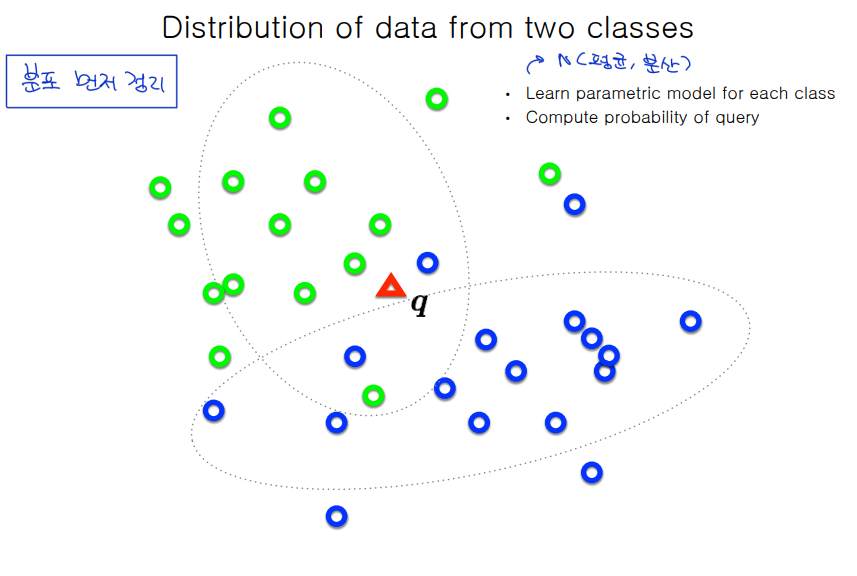
Classification using Multinomial Naive Bayes
- train & test data using BoW → using MNB
class로 알려주지 않고 확률로 알려줌
Distance metrics between two vectors
Cosine Distance
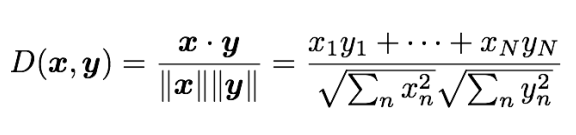
Euclidean distance (L2 distance)
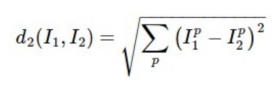
Manhattan distance (L1 distance)
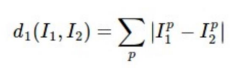
Posterior, prior, likelihood in Naive Bayes
posterior
: 클래스
: 한 이미지에서 추출한 feature 집합
Calculation
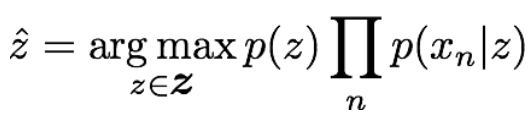
→ 너무 작아져서 log를 취해야함
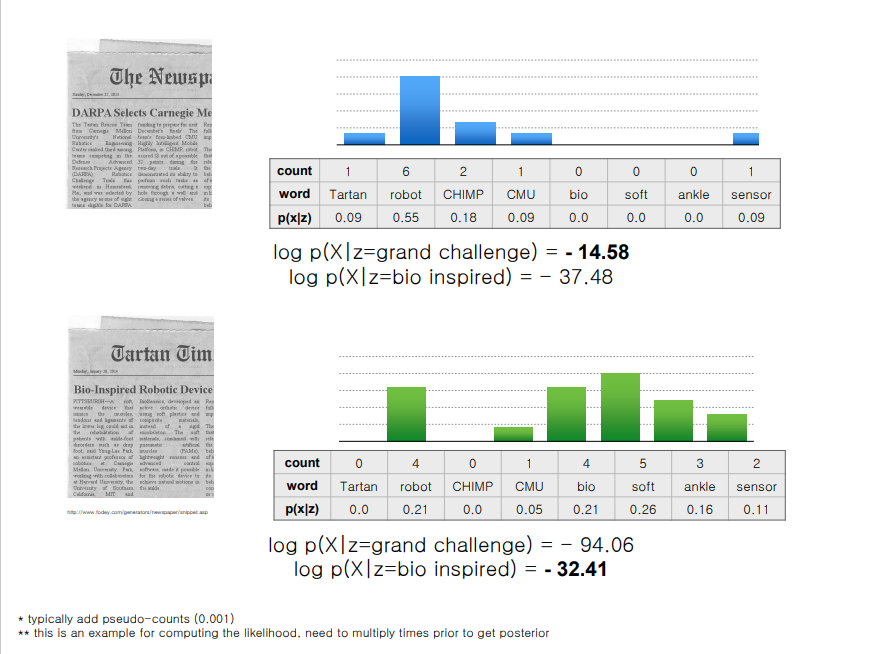

Student Dev - Language Tech & Machine Learning