[ASC] BERT의 attention은 aspect와 관련된 단어에 잘 주목하고 있었을까?

BERT의 self-attention
BERT의 encoder는 12개의 self-attention이 포함된 레이어로 구성되어 있다. 여기서는 각각의 토큰이 어떤 다른 토큰들과 관련도가 높은지를 파악할 수 있도록 돕는다.
원래는 RNN처럼 sequential하게 데이터가 들어와야 하는데 시간을 절약하기 위해 한번에 문장들이 들어오게 되면서 단어 간의 순서 등을 파악하기 어려워졌기 때문에, 이러한 방식으로 의미적으로 인접한 단어들을 찾아낸다고 할 수 있다. 아래 이미지를 보면 it이 가리키는 게 the, animal일 확률이 높다라고 추정할 수 있는 것이다.

어떻게?
Attention의 목적은 두 토큰 간의 문장 속에서의 관계를 파악하는 것이다. 따라서 각각의 토큰에 대해 점수를 줄 수 있으면 된다. 기본적으로 Cos Similarity 값을 생각해볼 수 있다. 문장 내에서 두 벡터가 얼마나 유사한 위치와 방향을 차지하고 있는지 볼 수 있다. 간단히 Dot Product를 해줘도 Cos Sim.와 비슷한 의미의 값을 구할 수 있으며, 너무 값이 다양해지는 것을 방지하기 위해 특정 값으로 나눠줄 수도 있다. 아래 그림은 encoder의 self-attention을 나타내는 것은 아니지만 다양한 attention 계산 방식을 보여준다.
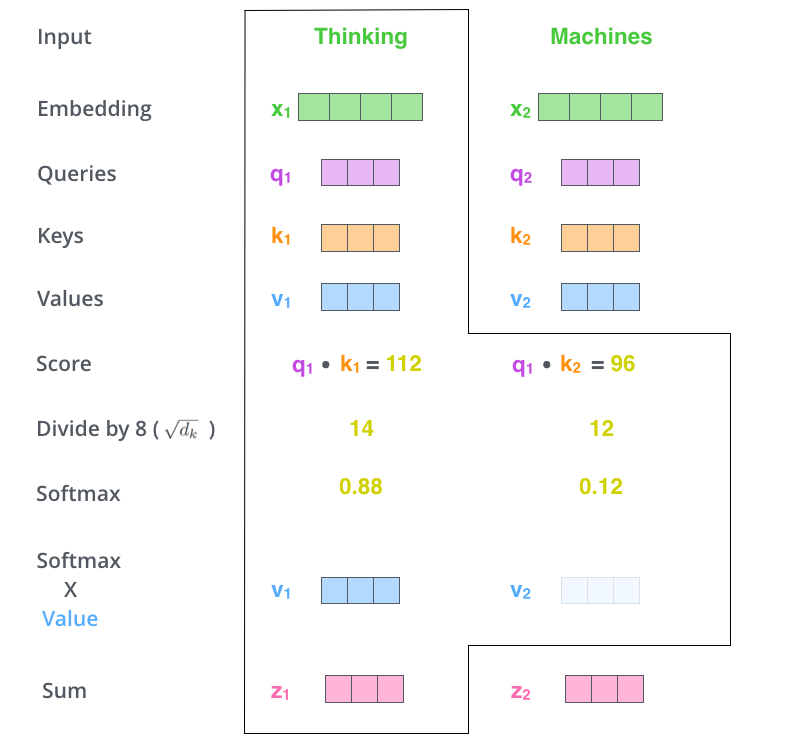
 BERT에서는 Query와 Key, Value 벡터들을 생성하고 매트릭스 연산으로 한번에 계산한다. 아래처럼 각 토큰의 Q와 K의 dot matrix 값으로 관계를 파악하고 표준화와 Softmax등의 작업을 통해 토큰A가 다른 토큰들에 대해 갖는 주목도들의 값을 하나의 벡터로 뽑아낼 수 있다. 학습이 되면서 Q, K, V 벡터들이 그 스코어들을 조정해간다.
BERT에서는 Query와 Key, Value 벡터들을 생성하고 매트릭스 연산으로 한번에 계산한다. 아래처럼 각 토큰의 Q와 K의 dot matrix 값으로 관계를 파악하고 표준화와 Softmax등의 작업을 통해 토큰A가 다른 토큰들에 대해 갖는 주목도들의 값을 하나의 벡터로 뽑아낼 수 있다. 학습이 되면서 Q, K, V 벡터들이 그 스코어들을 조정해간다.
BERT에서는 이 방식을 한 레이어당 여러 개의 다른 weight들로 진행하여 결과물을 concat하는데 'multi-head attention'이라 부른다.
http://jalammar.github.io/illustrated-transformer/
Aspect는 어떤 단어들에 주목하고 있을까?
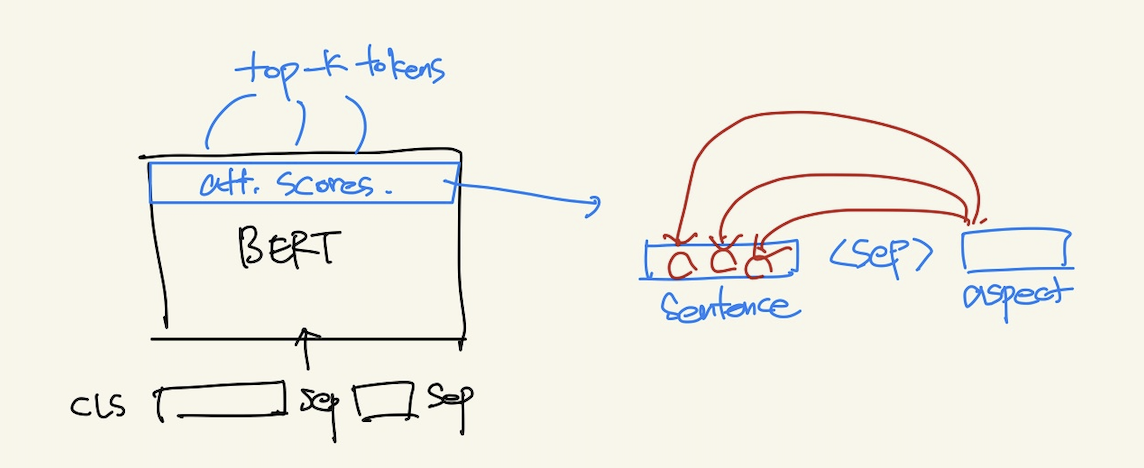
Pair text로 aspect word를 넣어줬을 때 aspect word가 주목하는 토큰들이 무엇일지 파악해보았다. 이 토큰들만을 활용해서 classification을 진행한다면 좀 더 명확하게 답을 내릴 수 있지 않을까 생각이 들었기 때문이다. 만약 aspect에 대한 감성을 나타낼 수 있는 opinion words에 주목하고 있다면 그 words에 대한 감성이 곧 aspect에 대한 감성이 될 수 있기 때문이다. 아쉽게도 opinion word에 대한 labeling은 되어 있지 않기 때문에 이걸 metric으로 뽑아내기는 어려웠고 자체 분석을 해보았다.
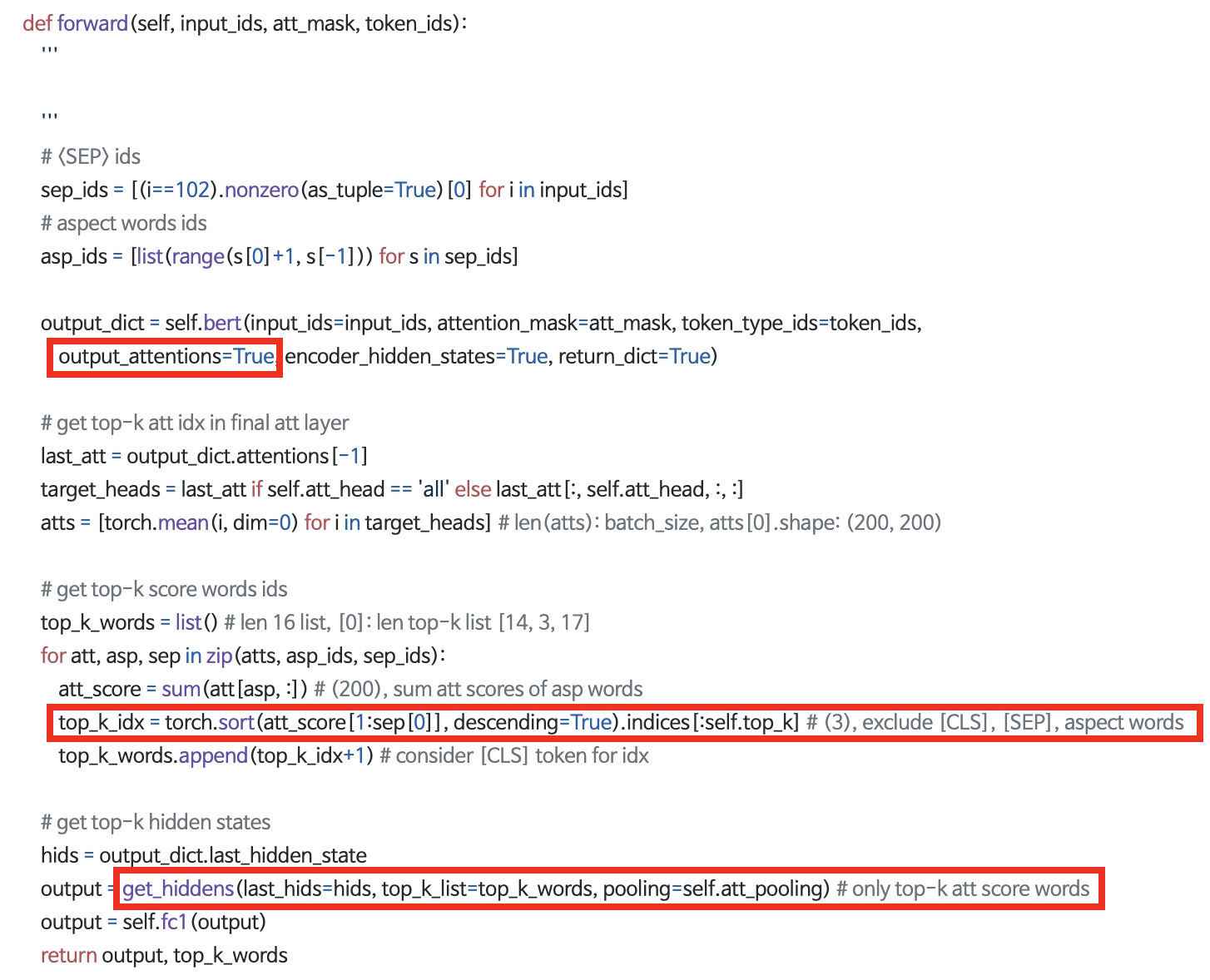
아래 코드를 보면
1. bert layer를 생성할 때 attention을 뽑아달라고 요청한다.
2. final layer에서 (output_dict.attentions[-1]) att score를 뽑아낸다. 이 때 모든 multi-head에서의 결과물들을 mean 해주는 방식을 사용했다.
3. CLS, SEP, ASP(aspect words)를 제외한 나머지 단어들 중 가장 주목도가 높은 단어들을 추려냈다. 분석을 위해 별도로 top_k_words를 생성해서 return 하도록 했다. 스코어가 높은 index(문장 내 위치)를 찾아서 추출해주고, 분석에서 그 위치의 단어들을 보면 된다.
4. get_hidden은 이후 실험에서 설명을 할 텐데, top-k words를 모아 매트릭스로 추출해주는 메소드이다. 단순 mean pooling이나 max pooling으로 classifier에 넣을지, 또는 순차적으로 RNN 계열에 들어가도록 할지에 따라 다른 형태로 추출된다. (자세한 코드는 하단의 레포지토리 참고)
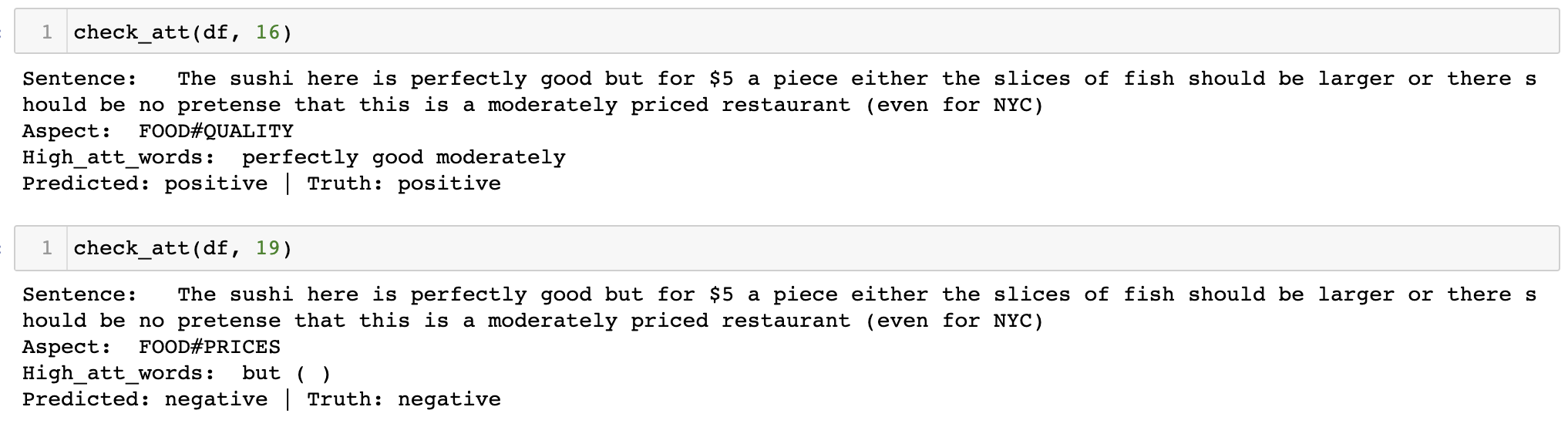
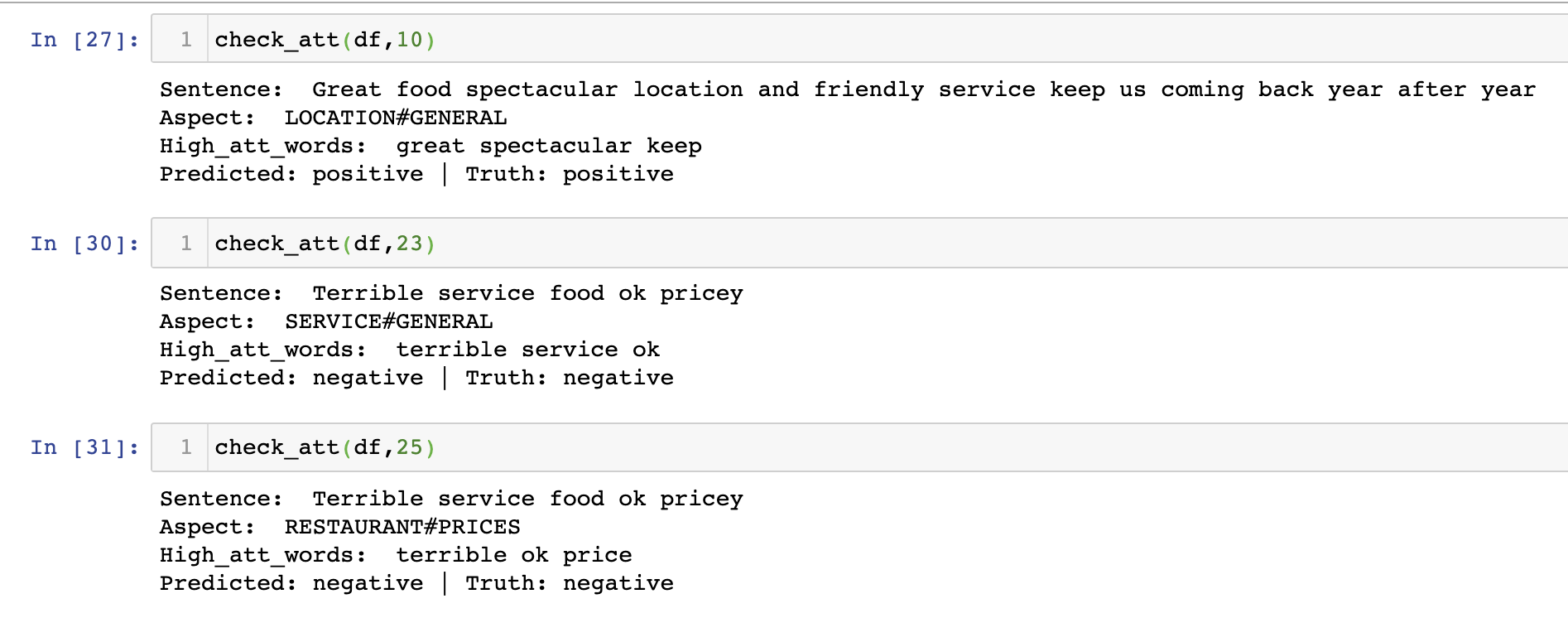
결과는 모호했다. 완전히 잘 주목한다고 볼 순 없었지만 어느 정도는 관련된 단어를 가리키고 있었다. FOOD Quality가 aspect로 들어갔을 때 적절히 perfectly good에 높은 스코어를 주고 있었으며, Price에 대해서는 'but'에 주목하고 있었다. 같은 문장이라도 aspect word가 각각 다른 부분을 주목하고 있기 때문에 이를 활용해서 classification을 해볼 수 있겠다는 생각이 들었다. (이후 포스팅에서는 이 부분에 대한 실험을 다뤄볼 예정)
물론 이 자체로 opinion words를 추출해낼 수 있다고 말할 수는 없었다. 아쉽지만 리뷰 내에서 aspect와 opinion의 pair(음식-완전히 좋았다, 가격-그러나, 부정)를 추출해내기엔 부족해보였다.