[ASC] BERT를 활용한 Aspect-Based Sentiment Analysis 모델

Transformer Encoder를 활용한 ABSA
Transformer와 BERT에 대해서는 간략하게만 설명을 남긴다.
Self-attention을 여러 겹 활용한 encoder와 Generation을 위한 decoder, 그리고 그 사이를 이어주는 attention 등으로 이뤄진 Transformer는, 시퀀스(sequential) 데이터를 시계열 적으로(RNN, LSTM, GRU 등) 처리할 때 발생하는 시간적 비효율을, 병렬 처리로서 줄여준다.
그리고 Encoder 부분만 떼어서 사전학습을 시킨 것이 BERT 계열의 Language Model이다. 참고로 요즘 핫한 GPT 계열은 문장을 generation 해야 하기 때문에 Decoder를 사용한다.
ABSA를 위한 BERT 구조
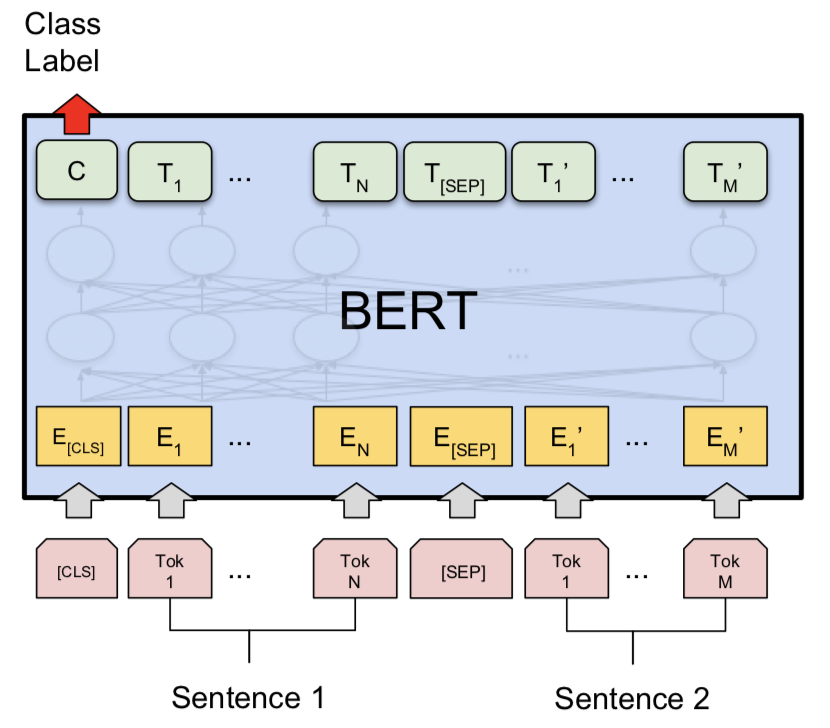
Sentence Pair Classification tasks in BERT paper
기본적으로 위와 같이 Sequence Classification 구조를 따른다. 위의 이미지는 문장 두 개가 들어갔을 때 서로 유사한 의미인지 등을 판별하는 구조이다. ABSA에 이 모형을 활용하려면 Sentence 2를 다르게 만들어주면 된다.
아래는 torch.utils.data.Dataset을 내려받아 커스터마이징 하는 클래스의 일부이다. Aspect Term을 해당 Sentence의 뒤쪽 pair에 넣어준 것을 볼 수 있다. Review A가 sentence로 들어갈 때 제2문장에는 'service general'(SERVICE#GENERAL에서 #을 제외)이 붙는다. token_type_id가 1이 배정되는 등 기본적인 pair sentence와 동일하게 인코딩된다.
for sentence, term, polarity in zip(list_sentence, list_term, list_polarity):
if pair: # encode_plus에서 text_pair에 term을 넣어주었다.
encoded = tokenizer.encode_plus(text=sentence, text_pair=term, add_special_tokens=True,
padding='max_length', max_length=max_length, pad_to_max_length=True,
return_token_type_ids=True, return_tensors='pt')BERT의 내부 레이어들을 활용한 ABSA
ABSA의 주요 연구자 중 한 명인 Youwei Song은 2020년 Utilizing BERT Intermediate Layers for Aspect Based Sentiment Analysis and Natural Language Inference(link)에서 BERT의 내부 12개 레이어들을 활용하여 ABSA 성능을 향상시킨 바 있다.
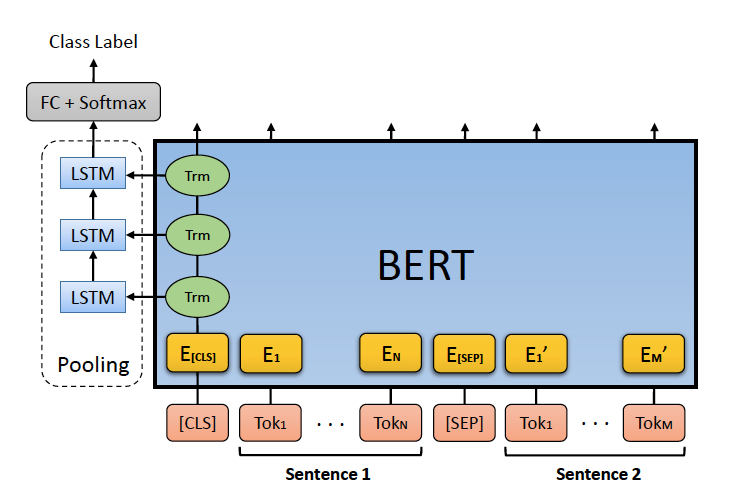
아래 그림과 같이 BERT 내부의 Self-attention Layer들의 states들을 다시 한번 pooling을 해주는 방식이다. 이 때 pooler로는 LSTM이나 attention layer가 사용된다.
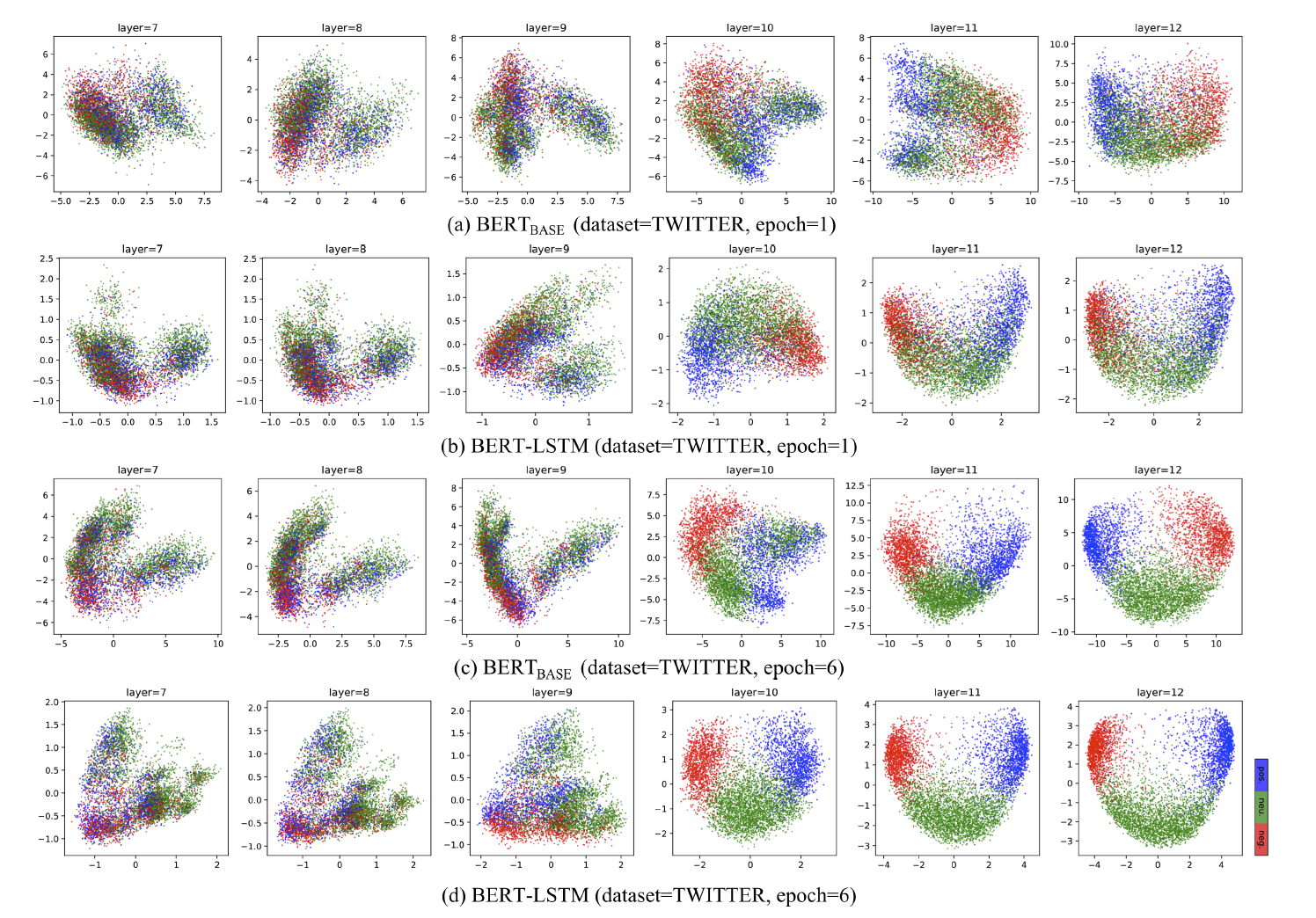
중간 단계의 states들의 변화를 encoding 하는 게 어떤 의미를 가질 수 있을지 궁금했다. 연구자에 따르면 아래 그림처럼 BERT-base 보다 BERT-LSTM에서 각 클래스를 더 명확하게 구분할 수 있다. 세 가지 감성(positive, neutral, negative)으로 나눠 CLS 토큰을 PCA를 통해 2차원 공간에 표현한 것이다. 더 확실하게 나눠지기 때문에 classifier에서도 잘 구분할 수 있을 것이다.
페이퍼 리뷰는 -> Notion Review
주요 코드
기본 BERT for Sequence Classification과 다른 점은 pooling layer를 붙이고 그쪽에 각 layer의 CLS 토큰 결과물들을 넣어줬다는 점이다.
우선 __init__에서 아래와 같이 어텐션을 위한 weight들을 생성해준다.
q_t = np.random.normal(loc=0.0, scale=0.1, size=(1, self.embed_dim))
self.q = nn.Parameter(torch.from_numpy(q_t)).float().to(self.device)
w_ht = np.random.normal(loc=0.0, scale=0.1, size=(self.embed_dim, self.fc_hid_dim))
self.w_h = nn.Parameter(torch.from_numpy(w_ht)).float().to(self.device)그리고 attention layer를 정의한다. #의 shape에서 8은 batch size, 12는 활용할 layer의 수가 된다. 12개의 레이어 결과물 벡터들이 8개씩 묶인 배치 데이터가 된다. 그리고 각각 256dim의 최종 representation vector로 변형된다.
def attention(self, h):
v = torch.matmul(self.q, h.transpose(-2, -1)).squeeze(1)
#print('v shape: ', v.shape) # [8, 12]
v = F.softmax(v, -1)
#print('v Softmaxed: ', v.shape) # [8, 12]
v_temp = torch.matmul(v.unsqueeze(1), h).transpose(-2, -1)
#print('v_temp shape: ', v_temp.shape) # [8, 768, 1]
v = torch.matmul(self.w_h.transpose(1, 0), v_temp).squeeze(2)
#print('final v shape: ', v.shape) [8, 256]
return v각 layer의 hidden states들을 쌓아서 attention layer에 넣을 준비를 한다. 아래는 layer_i 개의 레이어를 뽑아서 torch.stack으로 매트릭스에 쌓아주고, attention 레이어에 넣어주는 부분의 코드이다. BERT모델을 생성할 때 (output_hidden_states=True)를 정의해주면 내부 레이어들의 states가 출력되는데 이걸 attention layer에 forwarding 해주면 된다.
hidden_states = torch.stack([hidden_states[-layer_i][:,0].squeeze()\
for layer_i in range(1, self.num_layers+1)], dim=-1)
hidden_states = hidden_states.view(-1, self.num_layers, self.embed_dim)
out = self.attention(hidden_states)
out = self.dropout(out)
out = self.fc(out)
return out전체적인 코드는 github에서 볼 수 있다. model code
성능 향상
PT는 리뷰 데이터를 활용한 LM의 Post training을 의미한다. 단순 BERT의 CLS 토큰보다는 intermediate layer의 결과물들을 활용했을 때 aspect에 대한 감성을 잘 맞추고 있음을 알 수 있다.
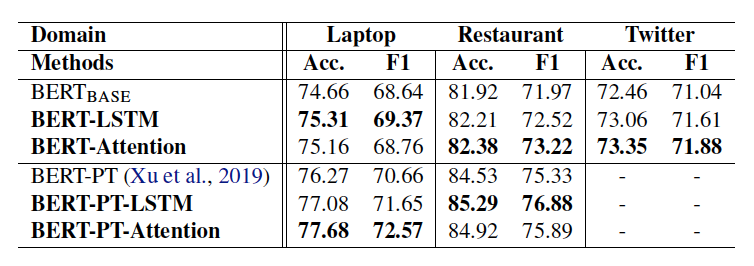
다음 포스팅부터는 BERT의 ABSA를 위한 encoding을 활용하면서 모델 구조를 조금씩 바꿔서 실험해 본 경험을 공유할 예정이다.

안녕하세요 공부중인 학생입니다..! hidden dimension을 256으로 하신 이유가 있을까요??representation vector를 tokenized_data length(80)도 아니고 BERT hidden_size(768)도 아니고 왜 256인지 궁금합니다..!