Introduction
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos
Raft is similar in many ways to existing consensus algorithms, but it has several novel features:
- Strong Leader: Raft uses a stronger form of leadership than other consensus algorithms.
- Leader election: Raft uses randomized timers to elect leaders.
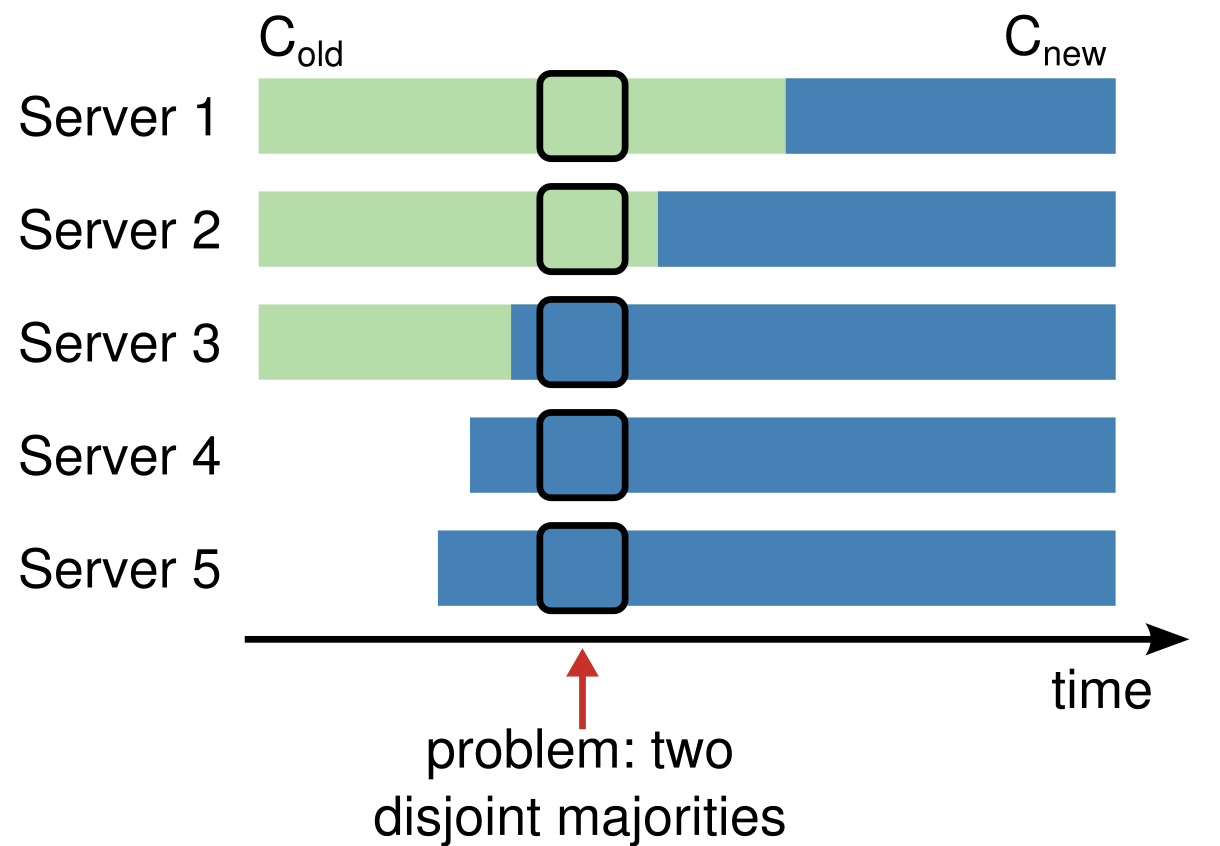
- Membership changes: Raft’s mechanism for changing the set of servers in the cluster uses a new joint consensus approach where the majorities of two different configurations overlap during transitions.
Replicated state machines
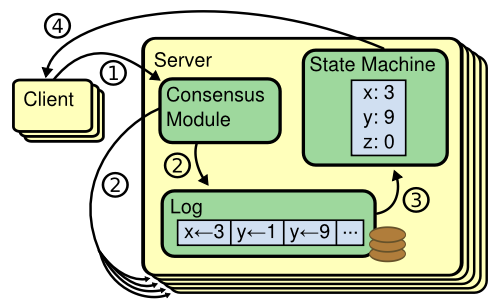
The consensus algorithm manages a replicated log containing state machine commands from clients. The state machines process identical sequences of commands from the logs, so they produce the same outputs.
- They ensure safety (never returning an incorrect result) under all non-Byzantine conditions
- They are fully functional (available) as long as any
majorityof the servers are operational and can communicate with each other and with clients - They do not depend on timing to ensure the consistency of the logs
- Command can complete as soon as a
majorityof the cluster has responded to a single round of remote procedure calls
The Raft consensus algorithm
Raft decomposes the consensus problem into three relatively independent subproblems
- Leader eletction: A new leader must be chosen when an existing leader fails
- Log replication: The leader must accept log entries
State
Persistent state on all servers
- CurrentTerm: latest term server has seen (initialized to 0 on first boot, increases monotonically)
- votedFor: candidateId that received vote in current term (or null if none)
- log[]: log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1)
Volatile state on all servers
- commitIndex: index of highest log entry known to be committed (initialized to 0, increases
monotonically) - lastApplied: index of highest log entry applied to state machine (initialized to 0, increases monotonically)
AppendEntries RPC
Invoked by leader to replicate log entries. Also used as heartbeat
Arguments
- term: leader's term
- leaderId: so follower can redirect clients
- prevLogIndex: index of log entry immediately preceding new ones
- prevLogTerm: term of prevLogIndex entry
- entries[]: log entries to store (empty for heartbeat; may send more than one for efficiency)
- leaderCommit: leader’s commitIndex
Results
- term: currentTerm, for leader to update itself
- success: true if follower contained entry matching prevLogIndex and prevLogTerm
Receiver implementation
- Reply
falseifterm<currentTerm - Updates its
termifterm>currentTerm - Reply false if log doesn’t contain an entry at
prevLogIndex
whose term matchesprevLogTerm - If an existing entry conflicts with a new one (same index
but different terms), delete the existing entry and all that
follow it - Append any new entries not already in the log
- If
leaderCommit>commitIndex, setcommitIndex=
min(leaderCommit, index of last new entry)
RequestVote RPC
Invoked by candidates to gather votes
Arguments
- term: candidate’s term
- candidateId: candidate requesting vote
- lastLogIndex: index of candidate’s last log entry
- lastLogTerm: term of candidate’s last log entry
Results
- term: currentTerm, for candidate to update itself
- voteGranted: true means candidate received vote
Receiver implementation
- Reply false if
term<currentTerm - Updates its term if
term>currentTerm - If
votedForis null orcandidateId, and candidate’s log is at
least as up-to-date as receiver’s log, grant vote
Rules for Servers
All Servers
- If
commitIndex>lastApplied: incrementlastApplied, apply log[lastApplied] to state machine - If RPC request or response contains
termT >currentTerm: setcurrentTerm = T, convert to follower
Follwers
- Respond to RPCs from candidates and leaders
- If election timeout elapses without receiving AppendEntries
RPC from current leader or granting vote to candidate: convert to candidate - If client contacts a follower, the follower redirects it to the leader
Candidates
- On conversion to candidate, start election:
- Increment current Term- Vote for self
- Reset election timer
- Send RequestVote RPCs to all other servers
- If votes received from majority of servers: become leader
- If
AppendEntriesRPC received from new leader: convert to
follower - If election timeout elapses: start new election
Leaders
- Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server; repeat during idle periods to prevent election timeouts
- If command received from client: append entry to local log, respond after entry applied to state machine
- If last log index ≥ nextIndex for a follower: send AppendEntries RPC with log entries starting at nextIndex
- If successful: update nextIndex and matchIndex for
follower
- If AppendEntries fails because of log inconsistency:
decrement nextIndex and retry - If there exists an N such that N > commitIndex, a majority
of matchIndex[i] ≥ N, and log[N].term == currentTerm: set commitIndex = N
Properties that Raft guarantee
- Election Safety: At most one leader can be elected in a given term
- Leader Append-Only: A leader never overwrites or deletes entries in its log
- Log Matching: If two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index
- Leader Completeness: If a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms
- State Machine Safety: If a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index

٩( ᐛ )و