Glossary
- Node: Server
- Link: Connection between Nodes
- Address: Node's ip and port number
- Consensus: Consensus between nodes. Similiar with shared memory
- Quorum: The number of nodes which agree with the suggestion to consensus
- Majority: (N + 1 / 2)
Consensus
The Raft Algorithm aims to achieve stable consensus among servers in a distributed system. However, factors such as network errors and node failures can disrupt stable connections between servers.
Async vs Sync
Here's a concise comparison of asynchronous and synchronous operations in a distributed system:
Sync
- The caller waits for the callee to finish its execution.
Async
- Caller doesn't wait for the callee's reponse and proceeds with the next task.
- The caller is indifferent to the callee, with no defined response time.
- Two Generals' Problem: In extreme cases, two generals can never reach consensus if all requests and responses are lost.
- FLP Impossibility: A perfectly asynchronous distributed system that makes no timing assumptions cannot exist.
- At some point, the system must wait for a response synchronously due to timing assumptions.
What Makes Consensus Reliable?
- Partition Tolerance: The system's ability to restore functionality after a connection loss.
- Availability: The percentage of time the system can respond (e.g., 5m 15s downtime per year -> 99.999% availability).
- Consistency: How consistently the system responds "Normally".
- Consistency Models: How can we define "Normally".
- Sequential Consistency Model, Causal Consistency Model, Eventual Consistency Model, Strong Consistency Model...
CAP theroy
- It's impossible to satisfy those three features(Partition Tolerance, Availability, Consistency)
- Absence of Partion Tolerance will kill the server at every network disable. So Partion Tolerance is essential value.
- One of Availability and Consistency must be sacrifice
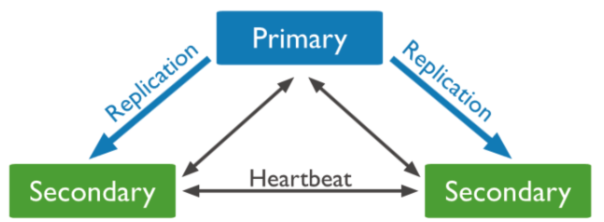
CP (Consistency and Partition Tolerance)
Sacrifices availability. For example, MongoDB nodes communicate to check statuses. If a node doesn't respond for a few seconds, it's considered "unavailable." If the primary node is unavailable, a secondary node is promoted to primary with the election. All persistence requests are unavailable until the election finishes.
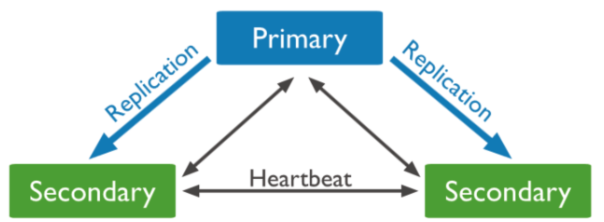
AP (Availability and Partition Tolerance)
Sacrifices consistency. For example, in Cassandra, all nodes can write and read without a primary node, replicating data to adjacent nodes as many times as specified. Even if a connection is lost, nodes can still write and read data without ensuring consistency. Cassandra later recovers this through Eventual Consistency.
Raft
Raft is a representative CP system. Accordingly, it is used in strongly consistent distributed key-value systems like TiKV and etcd.
