1. Previous Story
저번 포스팅에서는 wget을 사용해 amazon dataset tsv 파일을 다운로드하는 것까지 진행했다. 이번에는 Python Pandas를 사용해 amazon review 중 Shoes category에 해당하는 review들을 파싱해보자.
2. Parsing
이번에는 Jupyter notebook을 개발환경으로 사용할 것이다.
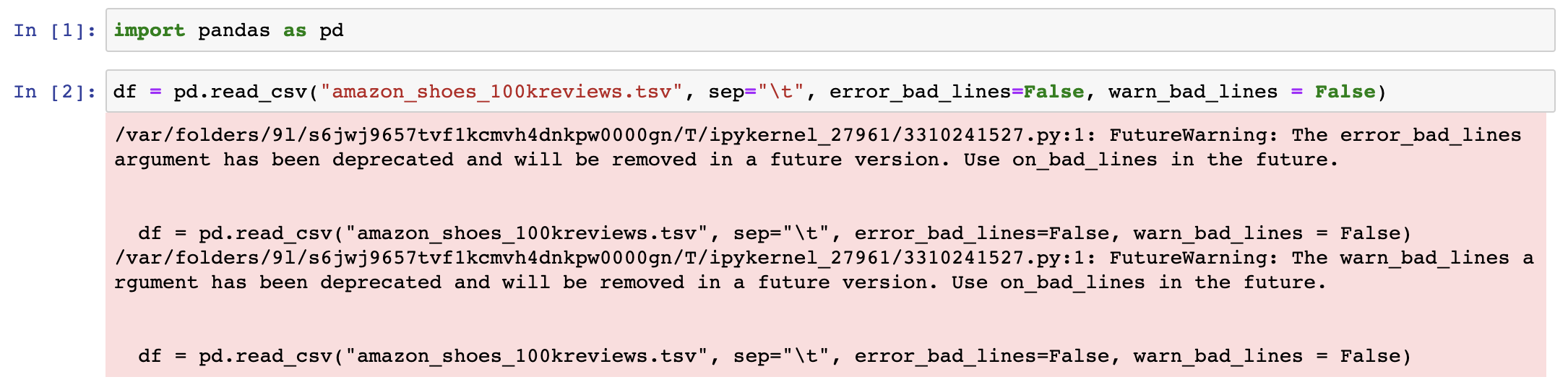
tsv 파일을 불러오는 과정에서, '\t'키로 구분이 되지 않는 에러가 간혹 발생할 수 있다. 그럴 때는
$ error_bad_lines = False를 파라미터로 넣어주면 에러를 무시하고 코드를 실행하게 된다.
아래 결과를 보면 dataset을 잘 가져왔음을 알 수 있다. 나는 amazon review dataset 중 shoes category에 대한 tsv 파일을 다운로드했다.
(파일이 너무 커서 5백만개 데이터를 백만개로 줄였다)
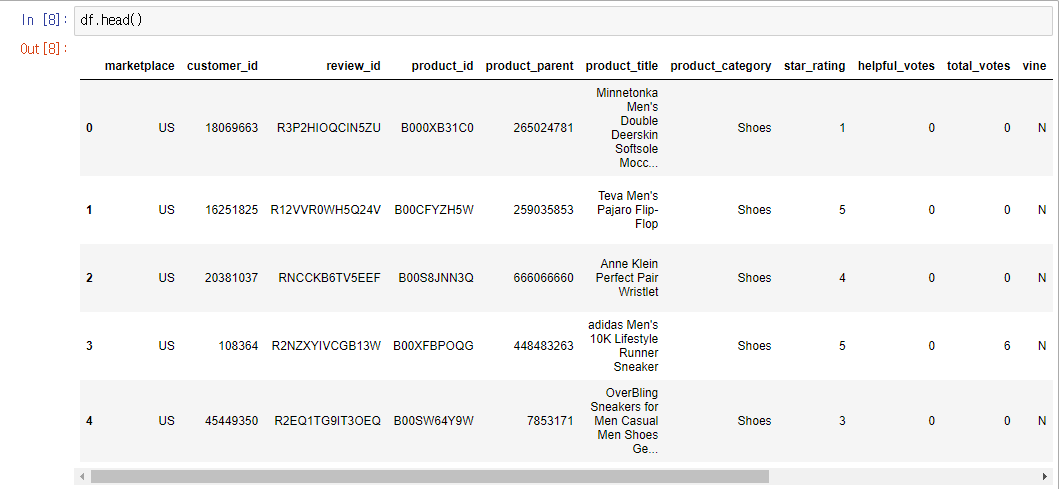
head() 함수는 데이터프레임 객체의 0~5행 까지를 반환한다. 어떤 파일을 데이터프레임 객체로 불러왔을 때 대충 어떻게 생겼나 보고 싶을 때 유용할 듯 하다.
tail()함수는 마지막 3개 행을 보여준다고 하니 인덱스 마지막 번호를 알고 싶을 때 유용할 것 같다.
shape : 데이터프레임 객체의 행과 열의 개수가 담긴 변수이다.

columns : 데이터프레임 객체의 colnmn들의 이름이 들어간 변수이다.
아래 그림을 보면 판매국가, 고객아이디, 상품 이름, 별점, 리뷰 등의 컬럼들이 존재하는 것을 알 수 있다.

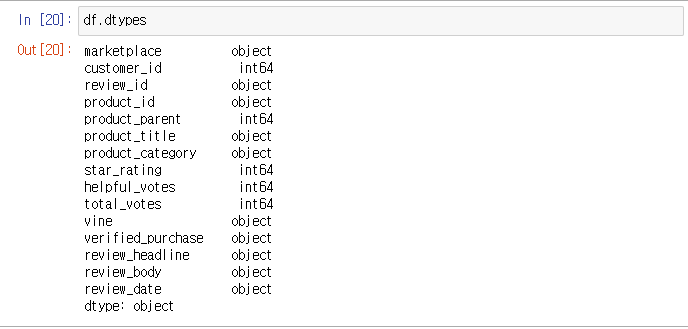
dtypes : 데이터프레임 객체의 colnmn의 각 자료형을 나타내준다.
요약
오늘은 Python의 Pandas 모듈로 tsv 파일을 파싱하고, 개괄적인 형식과 크기 등 메타데이터를 조회하는 방법에 대해 알아보았다. 다음에는 구체적으로 조건문을 통해 amazon_review_shoes dataset 을 낱낱이 파헤쳐보면 좋을 것 같다.
