들어가기 전
이번에 Amazon review dataset를 여러가지 방면으로 분석하는 프로젝트를 진행하다가 Pandas 모듈에 대해서 한번 정리하고 가야겠다라는 생각을 하게 되었다. 이번 포스팅에서는 저번에 다운로드한 Amazon_shoes_reviews.tsv 데이터셋에서 2015년 봄(3~7월)에 어떤 신발이 인기가 많았었는지 분석해보려고 한다.
1. 긍정적으로 평가한 review 만 추출하기
먼저 "x라는 review는 이 신발을 높게 평가한다." 에서 "높게" 의 필요 조건을 정해야 한다. 데이터셋은 분명히 "review"를 나타내는 자료이므로 popular 를 나타내는 column이 없다. 그래서 나는 x라는 신발을 매우 긍정적으로 평가했고, 리뷰를 3월~6월에 작성했으며 직접 구매한 사람들의 review를 먼저 filtering 하기로 했다.
- star_rating > 4 (별점 0~5)
- 3 =< review_datetime < 7
- verified_purchased = Yes
라는 조건에 의해 먼저 거대한 dataframe에서 filtered 된 data를 추출했다.
def find(self, dataset):
for i in dataset:
if int(i['star_rating']) > 4 and 2 < int(i['review_date'][5:7]) < 7 and i['verified_purchase'] == 'Y':
self.list.append(i.values())2. 긍정적인 review가 많은 순서대로 품목을 정렬하기
여기서는 pandas 모듈의 중요한 메서드 중 하나인 sort_value() 를 사용한다.
먼저 위에서 amazon review dataset에서 조건에 맞는 data만 추출했으므로, 다음 data 중에서 가장 빈번하게 나온 review가 가장 많은 긍정적인 평가를 많은 review일 것이므로, 이에 맞게 정렬 코드를 작성했다.
2.1. 데이터 값 기준 정렬 : sort_value()
sort_value() :
by=[column 명]: 정렬할 때 참조하기 위한 column 명key =: 이 인수를 통해 정렬할 때 함수를 적용할 수 있음inplace = bool: true일 경우 원본을 대체하게 됨axis=: {0:index, 1: columns} 정렬할 레이블을 정함ascending= (default: True): False일 경우 내림차순
def filter(self, data : CircularDoublyLinkedListFilter):
df = pd.DataFrame(data.list[1:], columns=data.list[0])
df = df.sort_values(by="product_title", key= lambda x : df.value_counts('product_title')[x], ascending= False)
return df[:][['product_title', 'review_id', 'star_rating', 'helpful_votes', 'review_date']]2.2. 중간 결과
df.head()

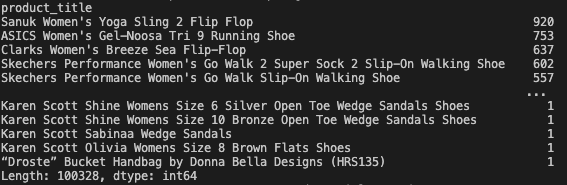
결과를 보니 당연히 리뷰의 개수가 많은 상품들이 중복되어서 정렬된 것을 볼 수 있었다. 이를 해결하기 위해 그냥 value_counts() 함수를 사용하기로 했다.
2.3. value_counts() 로 자동 정렬하기
value_counts('column 명') 함수는 DataFrame 객체에서 특정 열을 기준으로 최빈값을 추출할 수 있게 해준다. 이 때, 함수는 series 데이터 객체를 반환하게 된다.
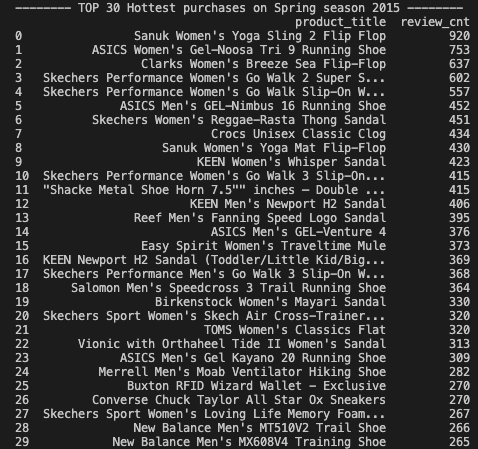
이 데이터를 다시 Dataframe 객체 타입으로 바꿔주고, 랭킹 30위 까지만 출력할 수 있도록 해보자.
def analyze_data(df):
print("-------- TOP 30 Hottest purchases on Spring season 2015 --------")
cnt = df.value_counts('product_title')
result = pd.DataFrame({"product_title": cnt.index, "review_cnt" : cnt.values})
print(result[:30])최종 결과
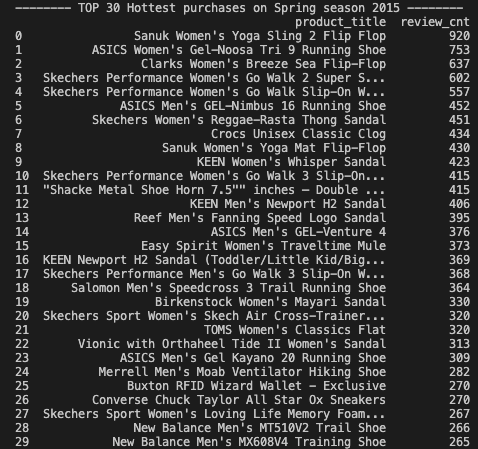
이렇게 2015년 봄에 작성된 신발 카테고리에 대한 리뷰들을 가지고 그 당시 인기가 많았던 신발 30종이 무엇인지 분석해 보았다.
