분산 시스템이란?
💡 블록체인의 핵심 중 하나는 분산된 노드 간의 합의를 어떻게 할 것인가이다.분산 시스템은 분산 컴퓨팅(ditstributed computing)또는 분산 데이터 베이스(distributed databases)로 알려져 있다. 하나의 분산 시스템은 서로 다른 머신들에 위치해 있는 독립된 컴포넌트들의 묶음이며 이 묶음은 하나의 공통된 목적을 달성하기 위해 서로 메시지를 주고 받는다
분산 시스템의 구성요소
각 노드가 공통된 결과를 도출하는 것을 목적으로 함
- Message channel : 정보의 이동 ( 정보가 개별 노드들에게 도달해야 함)
- Nodes : 개별 프로세스
- 전체적으로 같은 흐름으로 흘러감
- Safety : 일어나지 않을 정보는 절대로 받지 않는다 (일어나지 않을 일은 절대 안 일어남!)
- Liveness : 결과적으로 똑같은 정보에 도달하게 된다.
- Correcteness : 전체 시스템이 의도한 목적을 달성
- Validity : 결정된 모든 가치는 프로세스로부터 제안되어야 한다
- Agreement : 모든 non-faulty 프로세스는 하나의 가치에 동의해야 한다
- Termination : 모든 non-faultty 프로세스들은 결정을 내려야만 한다
분산 시스템의 장점
→ 분산 시스템의 목표는 확장성, 퍼포먼스, 애플리케이션의 고가용성
- 수평적 확장이 가능 - 머신들이 필요할 때 추가시킬 수 있음
- 낮은 latency - 머신을 물리적으로 유저와 가깝게 위치시키며 지연을 낮춤
- fault tolerance - 하나의 서버가 다운되면 다른 서버들이 그 일을 처리 할 수 있음
분산 시스템의 단점
→ 많은 머신들이 존재할수록 더 많은 메시지와 데이터들을 주고받으며 이슈 발생
- 데이터 통합과 일치 - 데이터와 상태를 분산시스템에서 동기화하기까지 까다로움
- Network and communication failure - 메시지들이 올바른 노드에 도달하지 않거나 순서가 틀릴 경우 통신 기능 장애 발생할 수 있음
- Management overhead - 더 많은 모니터링, 로드밸런싱이 가식성을 위해 분산 시스템의 연산과 실패에 투입되어야 함
분산 시스템 합의 알고리즘
CAP theorem
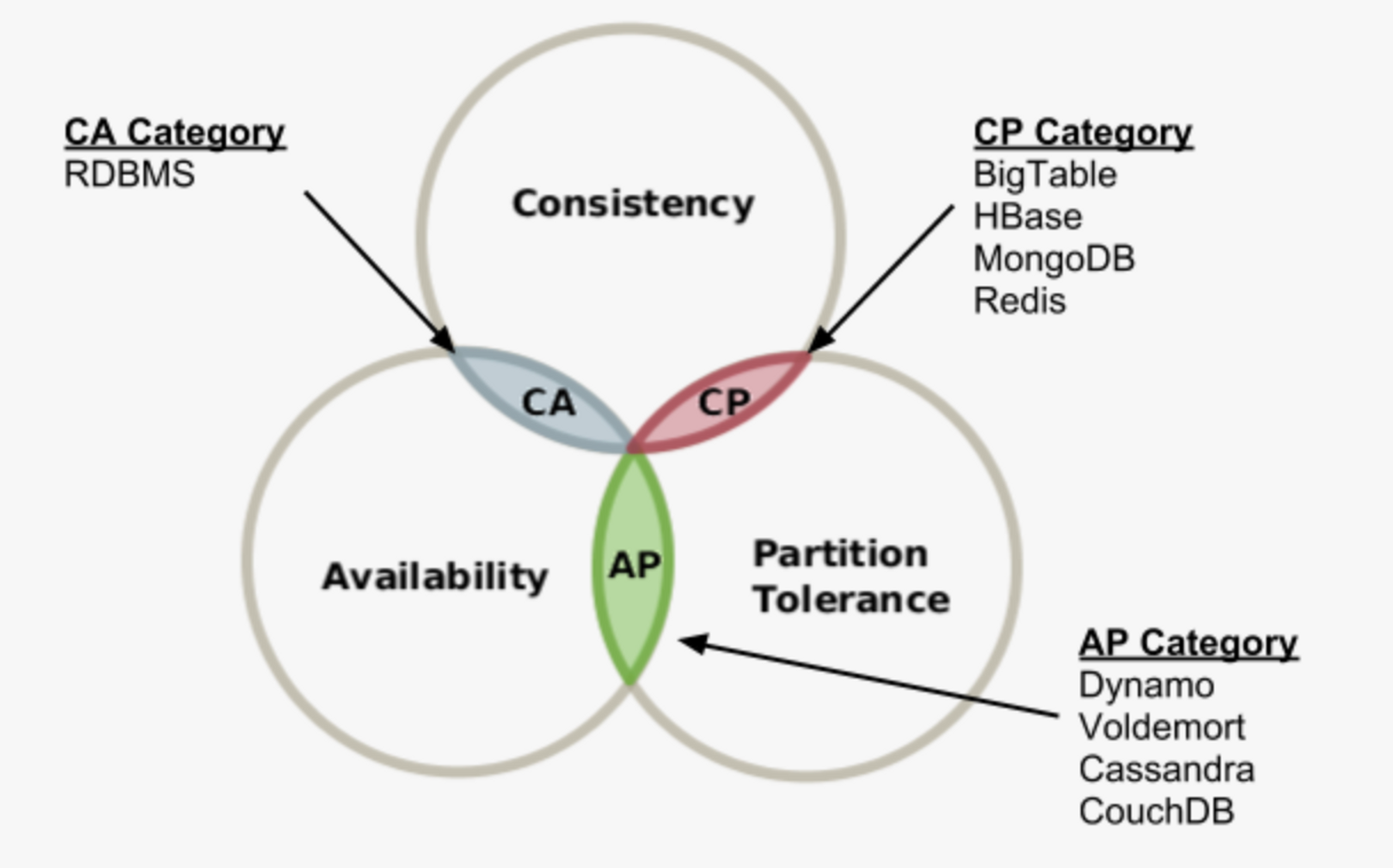
CAP(Consistency: 일관성, Availability: 가용성, Partition Tolerence: 분할내성)
세가지 조건을 모두 만족하는 분산 컴퓨터 시스템은 존재하지 않음을 나타내는 이론, 세가지 중 두가지를 택해야 한다는 이론
Consistency : 모든 노드가 가장 최근 상태를 반환
Availability : 모든 노드는 일관된 읽기 및 쓰기 권한을 가짐
Partition tolerance : 시스템은 네트워크의 분리가 일어나더라도 동작
Paxos Algorithm
→ 신뢰할 수 없는 프로세서들의 네트워크에서 합의 문제를 해결하기 위한 프로토콜 그룹 , 참가자의 그룹에서 단일 결과에 대한 합의를 얻는 과정
Non - Byzantine model : 각 노드는 느려질 수 있으며 정지나 재기동 가능, 메시지는 느리게 배달되거나 중복, 소실될 수 잇지만 변조되지는 않는다.
대용량 데이터의 복제에 일반적으로 사용된다.
- 여러 프로세스들로부터 여러 값을 제안 받음
- 그 값들 중 하나의 값을 선택
- 선택한 값을 여러 프로세스들이 인지
- Synod
- Proposer, Acceptor, Learner로 프로세스 구분
- 각 Agent는 느려질 수 있고 정지하거나 재기동 가능
Proposer : 입법자로 시민의 요구를 대변하여 프로토콜을 실행
Acceptor : 입법자의 제안에 대해 투표하는 역할 수행
Learner : 투표 결과를 기억하고 수행하는 역할 수행
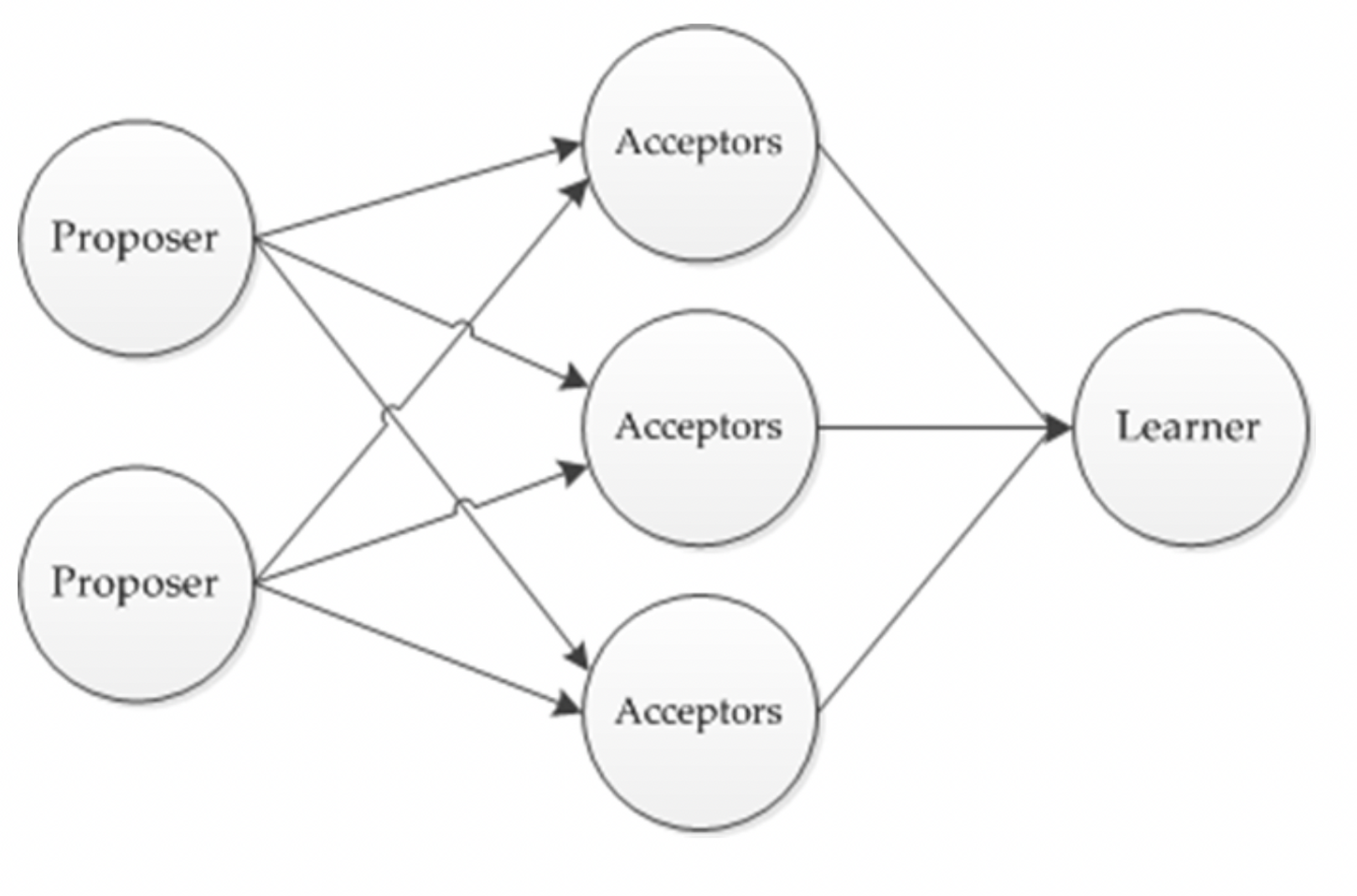
- Prepare
- Proposer은 제한번호 n을 선택하고 Acceptors에게 prepare 요청 발송
- Acceptors는 이미 응답했던 prepare 요청보다 큰 제안번호 n에 대해서만 응답하며 지금까지 수락했던 제안 번호 중 가장 큰 값과 함께 prepare 요청에 대한 응답 전송
- Accept
- Proposer은 Acceptors의 응답을 확인하고 제안번호 n에 대한 accept 요청을 보냄
- Acceptor은 n번 제안에 대한 accept 요청을 받는 경우 n보다 큰 prepare 요청에 응답한 적이 없는 경우에만 제안 수락
Raft Algorithm
→ 이해하기 쉽도록 설계된 분산 합의 알고리즘 , 여러 서버들 중 일부 서버에 장애가 발생하더라도 기능을 유지하도록 하는 내결함성을 가지고 있음
- Leader - based approach ( 리더를 기준으로 프로그램이 돌아감 !)
프로토콜
- RequestVotes - Caondidate 노드에 의해 전달되고 투표를 얻기 위해 사용
- AppendEntris - Leader 노드에 의해 전달되고 로그 항목을 복제하기 위해 사용되거나 heartbeat 메커니즘으로도 사용
리더 선출(leader election)
- 모든 노드는 follower 상태에서 시작한다. election timeout 후 follower가 candidate가 되어 새로운 선거 기간(term)을 시작한다.
- election timeout : follower가 candidate 가 될때까지 기다리는 시간 (150ms~300ms)
-
Candidate 노드는 자신에게 투표하고 RequestVotes를 follower에게 보냄
-
Follower가 현재 term에 투표한 적이 없다면 바로 투표 요청을 Candidate에게 응답
( 모든 노드는 term당 투표 한번만 가능 , 응답을 한 Follower는 election timeout 을 초기화) -
과반수 이상의 투표를 받은 candidate는 leader가 된다
리더 선출 후, Leader는 Fllower에게 AppendEntries 메시지를 보내기 시작한다. 이 메시지는 Heartbeat timeout을 초기화하고 각 AppendEntries 메시지에 응답한다. 이 선거기간은 follower가 Heartbeat 수신을 중단하고 Candidate가 될 때까지 계속된다.
재선거 (re-election)
- Leader 노드가 죽어 더 이상 AppendEntries메시지를 보내지 못한다. election timeout 후 Follower가 Candidate가 되어 새로운 선거 기간(Term)을 시작한다.
- Candidate노드는 자신에게 투표하고 RequestVotes를 Follower에게 보냄
- Follower가 현재 term에 투표한 적이 없다면 바로 투표 요청을 Candidate에게 응답
- 과반수 이상의 투표를 받은 candidate는 leader가 된다
로그 복제 (log replication)
-
시스템에 대한 모든 변경 사항이 Leader를 통하여 변경하게 된다.
-
각 변경 사항은 노드의 로그 엔트리에 추가되고 다른 노드(Follower)에 복제된다.
(AppendEntry 메시지를 사용하여 수행됨) -
Leader는 Hearbeat timeout 주기마다 한번씩 AppendEntries 메시지를 Follower에게 전달함
로그 엔트리에 포함되는 정보
Term - Leader 선출 시 할당되는 1씩 증가하는 Sequence 번호
Index - Log 가 저장될 때마다 1씩 증가하는 Sequence 번호
Data
로그 복제 과정
- 클라이언트가 Leader에게 변경 사항 요청
- 변경 사항은 Leader의 LogEntry에 저장
- Leader는 다음 Hearbeat에 log를 AppendEntry 형태로 Follower에게 전달
- AppendEntry 메시지를 받은 Follower는 새로운 LogEntry를 저장하고 AppendEntryResponse 메시지로 성공 응답 전송
- 과반수 응답을 받았다면 Leader는 자신의 Entry를 commit 하고 클라이언트에게 응답 메시지 전송
- Follower들에게도 변경 사항이 commit 되었음을 알리고 알림 받은 Follower들은 commit
참조
Raft Consensus Algorithm 알아보기
CAP 정의, CAP theorem, 브루어 정리(Brewer's theorem)
분산 시스템(distributed system)
Paxos Algorithm
