[CV] #15. 머신 러닝
K-fold Cross ValidationK-nearest neighborSVMStatModelSupervised LearningSupport Vector MachineUnsupervised LearningfindNearestkernel trickopencv머신 러닝컴퓨터비전필기체 숫자 인식
Computer Vision
목록 보기
17/18

#15-1. 머신 러닝과 OpenCV
머신 러닝 개요
-
머신 러닝 : 데이터 분석 → 규칙성, 패턴 찾기
-
과정
- train (학습, 훈련)
- 데이터로부터 규칙 찾기
- model (모델)
- 학습에 의해 결정된 규칙
- predict(예측), inference(추론)
- 새로운 데이터를 학습된 모델에 입력으로 전달 후 결과 판단
- label(레이블)
- 훈련 데이터에 대한 정답
- train (학습, 훈련)
-
일부 : 성능 측정을 위한 테스트 용도
- 학습 : 8000개
- 테스트 : 2000개 → 분류 정확도 계산
- 파라미터에 의해 성능 달라짐 → 최적의 파라미터 찾기
-
분류
-
supervised learning(지도 학습)
- 정답을 알고 있는 데이터 이용
- 수학적, 논리적 연산 수행 (규칙 찾기)
- 다수의 훈련 영상에서 특징 벡터 추출

- 영상 분류 과정

- 회귀
- 연속된 수치 값 예측 (ex. 온도 예측)
- 분류
- 이산적인 값을 결과로 출력
- 입력 → 결과 : 0 or 1 (사과 : 0번 클래스, 바나나 : 1번 클래스)
- 인식(recognition) : 사과인지 바나나인지 구분하는 것
-
unsupervised learning(비지도 학습)
- 정답에 대한 정보없이 오로지 데이터 자체만을 이용
- 전체 사진을 두 개의 그룹으로 나누도록 학습
- 각각의 그룹이 무엇을 의미하는지는 알 수 X
- 서로 구분되는 특징 → 분리하는 작업만
- 군집화(clustering) 사용
-
-
영상 픽셀값 : 머신러닝 입력으로 사용 X
- 환경에 따라 민감하게 변화
- 환경에 민감하지 않은 특징 정보 추출하여 입력으로 전달
- 유효한 특징 : 주된 색상(hue), 객체 외곽선, 면적 비율 등
-
개요
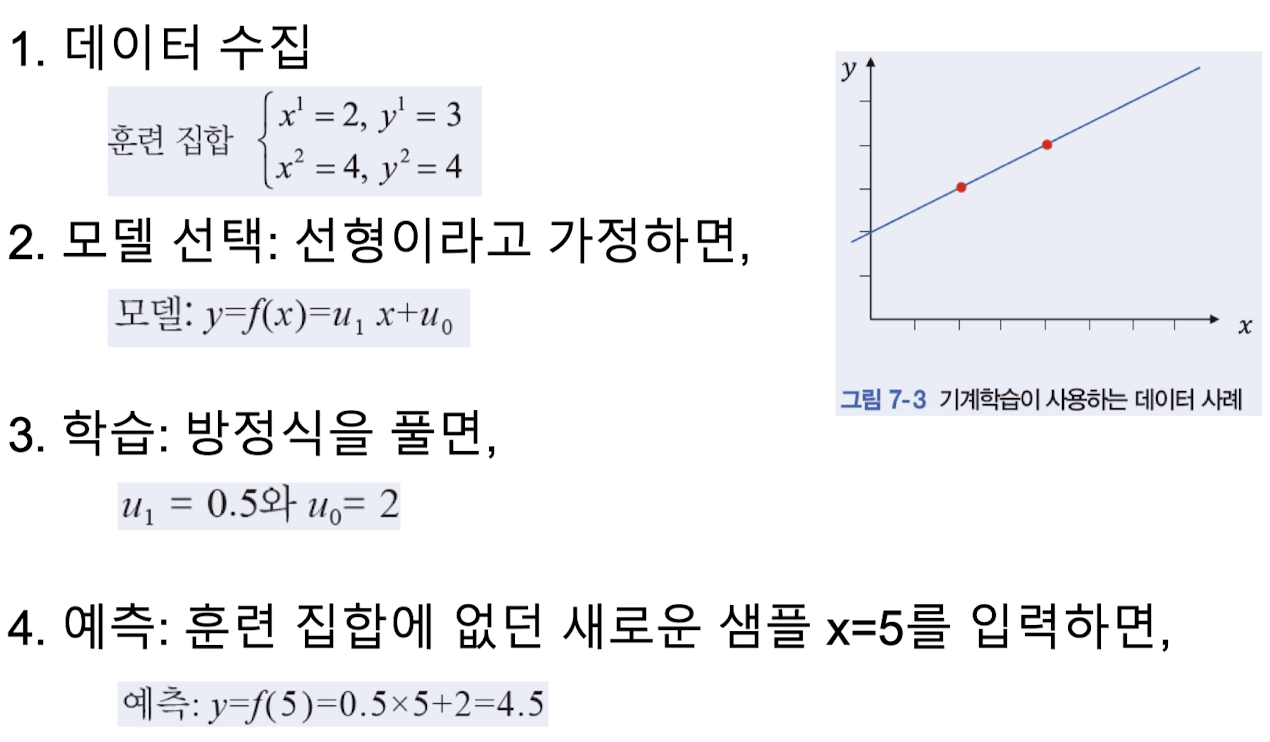
- 학습 : loss function이 최소가 되도록
학습
- 최소 오류로 맞히는 최적의 가중치 값 찾기
- 분석적 방법 사용 : 단순 방정식 풀어 해결
-
기계학습 - 수치적 방법 (오류 조금씩 줄이는 과정)
-
모델의 오류 측정하는 손실 함수 필요
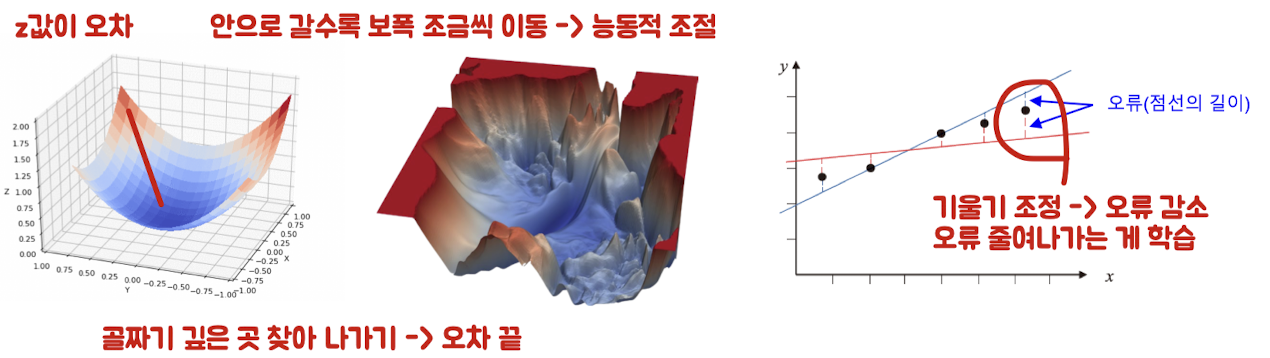
-
k-폴드 교차 검증 (k-fold cross-validation)
- k개의 부분집합으로 분할 → 학습, 검증 반복하며 최적의 파라미터 찾기

훈련 데이터의 이상치
-
훈련 데이터에 포함된 잡음, 이상치(outlier) 영향 고려
-
훈련데이터를 효과적으로 구분하는 경계면 찾기
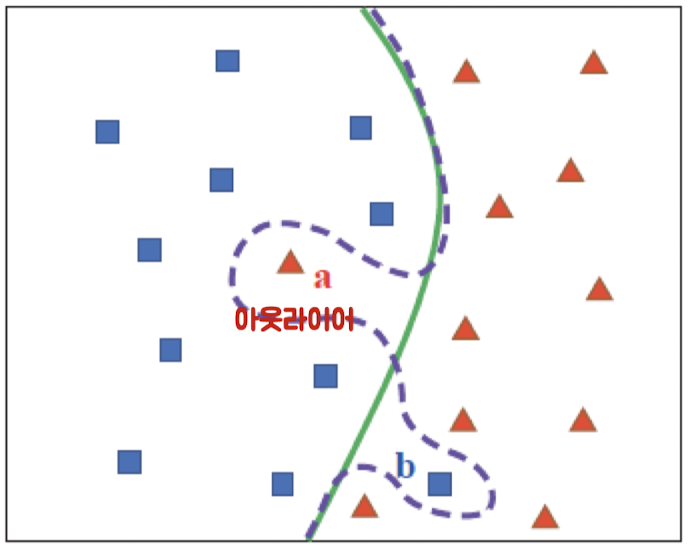
→ 실제 새로운 입력 데이터에 대해서는 정확도 떨어짐
→ 잡음, 잘못 측정된 값일 가능성
→ 녹색 실선 경계면 사용
OpenCV 머신 러닝 클래스
- cv::ml::StatModel 추상 클래스를 상속받아 생성
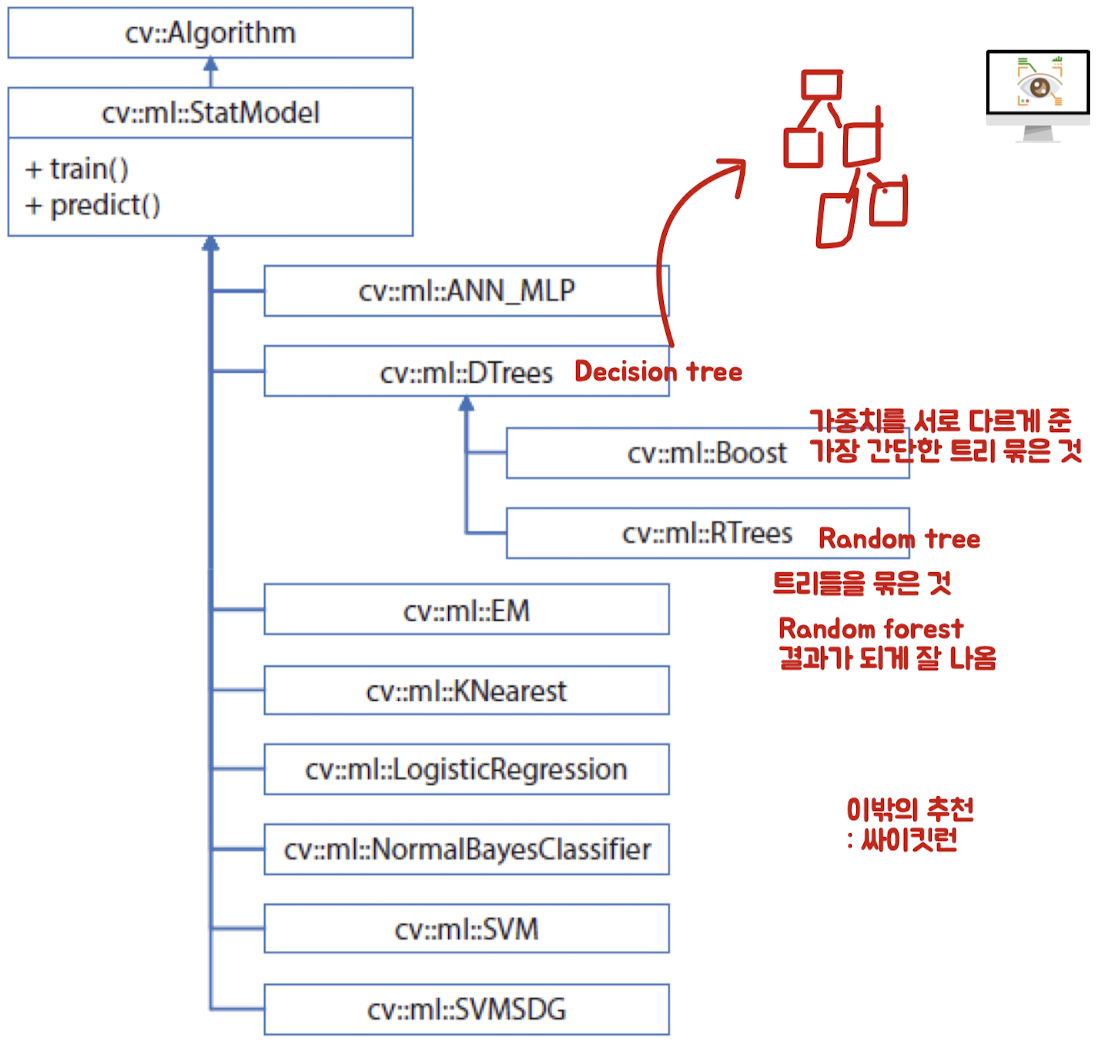
- StatModel : 통계적 모델
- StatModel::train() → 머신러닝 알고리즘 학습
train(samples, layout, responses); //정상 학습되면 true 반환- samples : 훈련 데이터 행렬
R G B Label S1 250 150 100 사과 S2 바나나 …
- samples : 훈련 데이터 행렬
- StatModel::predict() → 테스트 데이터에 대한 결과 예측
predict(samples, results=noArray(), flags = 0)- 순수가상함수로 선언 → 구현 클래스에서 재정의
- 고유의 예측 함수도 제공
- StatModel::train() → 머신러닝 알고리즘 학습
- ANN_MLP : 인공신경망 다층 퍼셉트론
- DTrees : 이진 의사 결정 트리 알고리즘
- Boost : 부스팅 알고리즘, 다수의 약한 분류기에 적절한 가중치 부여
- RTrees : 랜덤 트리, 랜덤 포레스트 알고리즘
- EM : 기댓값 최대화, 가우시안 혼잡 모델을 이용한 군집화 알고리즘
- KNearest : k 최근접 이웃 알고리즘
- LogisticRegression : 로지스틱 회귀, 이진 분류 알고리즘의 일종
- NormalBayesClassifier : 정규베이즈분류기
- SVM : 서포트 벡터 머신 알고리즘
- SVMSDG : 통계적 그래디언트 하향 SVM
#15-2. k-nearest neighbor
k 최근접 이웃 알고리즘
- 지도학습 알고리즘
- 분류, 회귀에서 사용
- 레이블링 필요
- 분류
- 특징 공간에서 테스트 데이터와 가장 가까운 k개의 훈련 데이터 찾기
- 훈련 데이터 중에서 가장 많은 클래스 → 테스트 데이터의 클래스로 지정
- 회귀
- 테스트 데이터에 인접한 k개의 훈련 데이터 평균을 테스트 데이터값으로 설정
- k=1 → 최근접 이웃 알고리즘
- 보통 1보다 큰 값 설정
- 주어진 데이터에 의존적으로 결정
- 커질수록 : 잡음, 이상치 데이터의 영향 감소
- 너무 커지면 : 분류 및 회귀 성능 감소
KNearest 클래스 사용하기
- KNearest 객체 생성
- KNearest::create()
- 정적 멤버 함수
- 기본값: k = 10 → 변경 : KNearest::setDefaultK(val)
- 속성 설정
- 기본값 : 분류
- KNearest::setIsClassifier(val) → true : 분류, false : 회귀
- train() 함수로 학습 진행
- 실제적인 학습 진행 X
- 훈련 데이터, 레이블데이터 → KNearest 클래스 멤버 변수에 모두 저장
- 테스트 데이터에 대한 예측 수행
- findNearest(samples, k, results, neighborResponses = noArray(), dist = noArray())
- neighborResponses : KNearest 클래스 정보 담고 있는 행렬
- dist : 입력 벡터와 예측에 사용된 k개의 최근접 이웃과의 거리 저장한 배열
import numpy as np
import cv2
train = [] # 훈련 데이터와 레이블 저장할 리스트
label = []
k_value = 1 # 초기 K값 설정
def on_k_changed(pos): # 변경될 때마다 k-NN 모델 재학습
global k_value
k_value = pos
if k_value < 1: # 최소 1이 되도록
k_value = 1
trainAndDisplay() # 결과 훈련 및 표시
def addPoint(x, y, c): # 훈련 세트에 새 데이터 포인트 추가
train.append([x, y]) # 훈련 데이터에 점 추가
label.append([c]) # 해당 레이블 추가
def trainAndDisplay(): # k-NN 분류기 훈련 -> 결과 표시
train_array = np.array(train).astype(np.float32)
label_array = np.array(label)
knn.train(train_array, cv2.ml.ROW_SAMPLE, label_array)
for j in range(img.shape[0]): # 이미지 각 픽셀에 대해 반복
for i in range(img.shape[1]):
# 샘플 포인트 생성
sample = np.array([[i, j]]).astype(np.float32)
# 가장 가까운 이웃 찾기
ret, res, _, _ = knn.findNearest(sample, k_value)
response = int(res[0, 0]) # 예측된 레이블 가져오기
if response == 0: # 예측된 레이블에 따라 픽셀 색상 변경
img[j, i] = (128, 128, 255)
elif response == 1:
img[j, i] = (128, 255, 128)
elif response == 2:
img[j, i] = (255, 128, 128)
for i in range(len(train)): # 훈련 포인트 이미지에 그리기
x, y = train[i]
l = label[i][0]
if l == 0: # 각 훈련 포인트에 원 그리기
cv2.circle(img, (x, y), 5, (0, 0, 128), -1, cv2.LINE_AA)
elif l == 1:
cv2.circle(img, (x, y), 5, (0, 128, 0), -1, cv2.LINE_AA)
elif l == 2:
cv2.circle(img, (x, y), 5, (128, 0, 0), -1, cv2.LINE_AA)
cv2.imshow('knn', img)
img = np.zeros((500, 500, 3), np.uint8) # 500x500크기 3개의 색상 채널
knn = cv2.ml.KNearest_create() # k-NN 분류기 생성
cv2.namedWindow('knn')
cv2.createTrackbar('k_value', 'knn', k_value, 5, on_k_changed)
NUM = 30
rn = np.zeros((NUM, 2), np.int32)
cv2.randn(rn, 0, 50) # 클래스 0 에 속하는 점 추가
for i in range(NUM):
addPoint(rn[i, 0] + 150, rn[i, 1] + 150, 0)
cv2.randn(rn, 0, 50)
for i in range(NUM): # 클래스 1에 속하는 점 추가
addPoint(rn[i, 0] + 350, rn[i, 1] + 150, 1)
cv2.randn(rn, 0, 70)
for i in range(NUM): # 클래스 2에 속하는 점 추가
addPoint(rn[i, 0] + 250, rn[i, 1] + 400, 2)
trainAndDisplay()
cv2.imshow('knn', img)
cv2.waitKey()
cv2.destroyAllWindows()-
2차원 점 분류
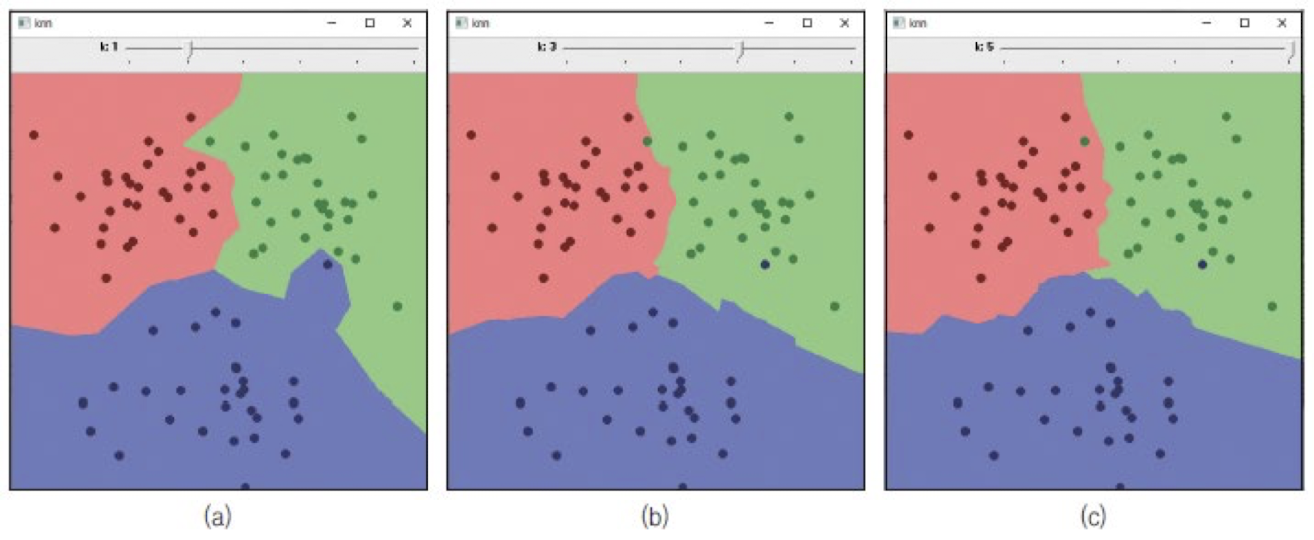
(a) k = 1
-
클래스 경계면이 유난히 볼록하게 튀어나온 부분 발생
(b) k = 3, (c) k = 5
-
다소 완만한 형태
-
k값이 증가함에 따라 잡음, 이상치 영향 감소
-
kNN을 이용한 필기체 숫자 인식
- 각각의 숫자 : 가로 100개, 세로 5개 (20x20픽셀) → 20 x 20 x 10 x 100 x 5 = 2000 x 1000 (전체 크기)
- 각각의 숫자 영상을 부분 영상으로 추출하여 훈련 데이터 생성
- 적합한 특징 벡터 추출
- 20x20 숫자 영상 픽셀 값 자체를 입력으로 사용
- 숫자 크기, 위치 거의 일정 → 픽셀값 그대로 이용해도 충분
- 5000개의 숫자 영상 데이터
- 훈련데이터, 테스트 데이터 구분 X
- 전체를 학습에 사용
- 20x20픽셀 → 1x400
- 400차원 공간에서의 한 점
- 5000 x 400크기의 행렬 → KNearest 클래스의 훈련 데이터로 전달
- 처음 500개 행은 숫자 0에 대한 데이터 → 다음 500개 행은 숫자 1에 대한 데이터 …
import sys
import numpy as np
import cv2
oldx, oldy = -1, -1
def on_mouse(event, x, y, flags, _):
global oldx, oldy
if event == cv2.EVENT_LBUTTONDOWN:
oldx, oldy = x, y
elif event == cv2.EVENT_LBUTTONUP:
oldx, oldy = -1, -1
elif event == cv2.EVENT_MOUSEMOVE:
if flags & cv2.EVENT_FLAG_LBUTTON:
cv2.line(img, (oldx, oldy), (x, y), (255, 255, 255), 40, cv2.LINE_AA)
oldx, oldy = x, y
cv2.imshow('img', img)
digits = cv2.imread('digits.png', cv2.IMREAD_GRAYSCALE)
if digits is None:
print('Image load failed!')
sys.exit()
h, w = digits.shape[:2] # 이미지에서 각 숫자 분리
cells = [np.hsplit(row, w/20) for row in np.vsplit(digits, h/20)]
cells = np.array(cells)
train_images = cells.reshape(-1, 400).astype(np.float32)
train_labels = np.repeat(np.arange(10), len(train_images) / 10)
knn = cv2.ml.KNearest_create() # k-NN 분류기 생성
knn.train(train_images, cv2.ml.ROW_SAMPLE, train_labels)
img = np.zeros((400, 400), np.uint8)
cv2.imshow('img', img)
cv2.setMouseCallback('img', on_mouse)
while True:
c = cv2.waitKey()
if c == 27:
break
elif c == ord(' '):
img_resize = cv2.resize(img, (20, 20), interpolation=cv2.INTER_AREA)
img_flatten = img_resize.reshape(-1, 400).astype(np.float32)
_ret, res, _, _ = knn.findNearest(img_flatten, 3)
print(int(res[0, 0]))
img.fill(0) # 이미지 초기화
cv2.imshow('img', img)
cv2.destroyAllWindows()#15-3. Support Vector Machine
서포트 벡터 머신 (SVM)
- 초평면 찾는 머신 러닝 알고리즘
- 두 개의 클래스로 구성된 데이터를 가장 여유있게 분리
- N차원 공간 상의 평면
- 지도 학습 → 분류, 회귀에 사용
- 선형 분리 가능한 데이터에 적용
- 실생활은 분리되지 않는 경우가 많음
- 이 경우 kernel trick 기법 사용 → 적절한 커널 함수를 통해 입력 데이터 특징 공간 차원을 늘리는 방식
- 고차원 특징 공간으로 이동하면 선형으로 분리 가능한 형태로 바뀔 수 있음
두 클래스 점 분할
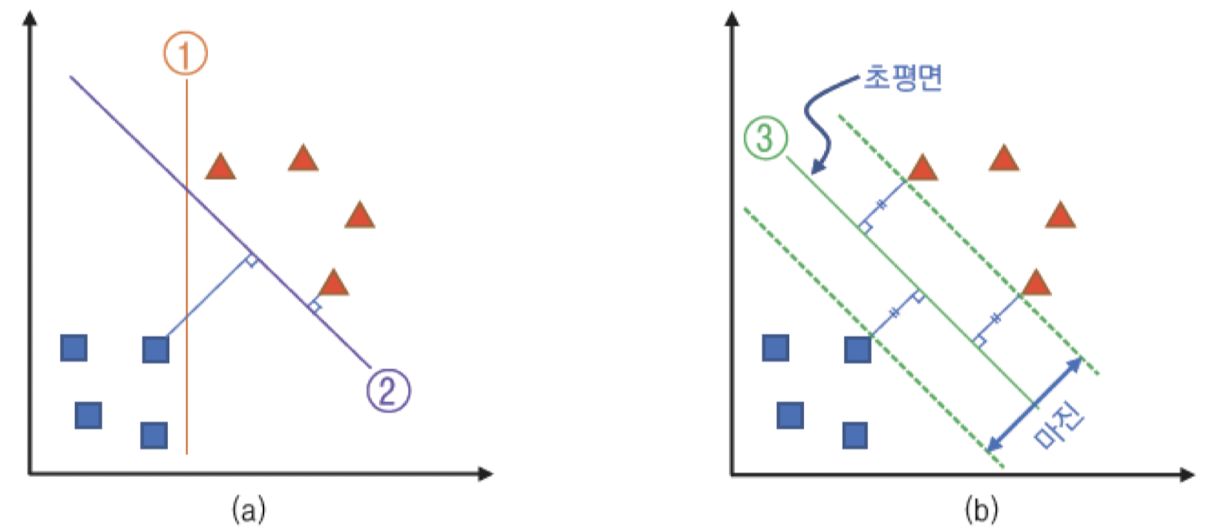
- 1,2번 직선 : 왼쪽, 오른쪽 조금만 이동하면 분리 실패
- 3번 직선 : 충분히 여유있게 분할
- margin : 빨간색 또는 파란색 점과의 거리 → 최대로 만드는 초평면을 구하는 알고리즘 : SVM
비선형 데이터에 커널 트릭 적용하기
- 특징 공간 차원 증가 → 데이터 선형 분리
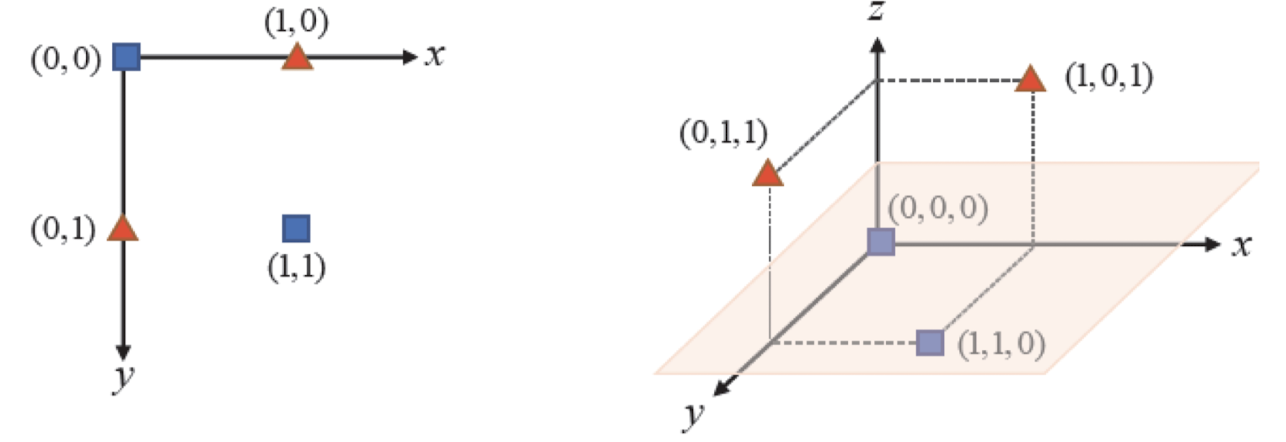
- X = {(0, 0, 0), (1, 1, 0)}
- Y = {(1, 0, 1), (0, 1, 1)}
- z = 0.5 평면의 방정식 → 효과적 분리
다양한 SVM 커널
- 가장 널리 사용하는 커널 : 방사 기저 함수
- 선형 분리 가능 → 선형 커널 (빠름)

SVM 클래스
- 오픈소스라이브러리 LIBSVM 기반으로 만들어짐
- SVM 객체 생성
- SVM::create()
- 속성 설정
- 타입 설정
- SVM::setType(val)
- SVM::Types 열거형 상수 중 하나 지정
- SVM::Types::C_SVC ← 기본값
- SVM 알고리즘 내부에서 사용하는 C 파라미터 값 적절하게 설정
- 작은 C값 : 훈련 데이터 중 잘못 분류되는 데이터 있어도 최대 마진 선택
- 큰 C값 : 마진이 작아지더라도 잘못 분류되는 데이터 적어지도록 분류
- 잡음, 이상치 데이터 많으면 C값 크게 설정
- 커널 함수 선택
- SVM::setKernel(kernerType)
- SVM::KernelTypes::RBF ← 기본값
- 방사 기저 함수 커널
- 타입 설정
- 파라미터 설정
- C, Nu, P, Degree, Gamma, Coef0 = 1, 0, 0, 0, 1, 0
- setXXX(), getXXX()
- SVM::KernelTypes::RBF 커널 → setC(), setGamma() 설정 필요
- train() : 학습
- 파라미터 설정 어려움
- trainAuto()
- 가장 성능이 좋은 파라미터를 자동으로 찾아 학습
- trainAuto(samples, layout, responses, kFold = 10, Cgrid, gammaGrid, pGrid, nuGrid, coeffGrid, degreeGrid, balanced = false)
- layout = ROW_SAMPLE || COL_SAMPLE
- Grid : 탐색 범위
import numpy as np
import cv2
train = np.array([[150, 200], [200, 250],
[100, 250], [150, 300],
[350, 100], [400, 200],
[400, 300], [350, 400]]).astype(np.float32)
label = np.array([0,0,0,0,1,1,1,1])
svm = cv2.ml.SVM_create() # SVM 분류기 생성
svm.setType(cv2.ml.SVM_C_SVC) # 유형 설정
svm.setKernel(cv2.ml.SVM_RBF) # 커널 설정
# svm.setKernel(cv2.ml.SVM_LINEAR)
svm.trainAuto(train, cv2.ml.ROW_SAMPLE, label) # 자동 매개변수 조정
img = np.zeros((500, 500, 3), np.uint8)
for j in range(img.shape[0]): # 각 픽셀에 대해 예측 수행
for i in range(img.shape[1]):
test = np.array([[i, j]], dtype = np.float32) # 현재 픽셀 위치
_, res = svm.predict(test) # SVM으로 예측
if res == 0: # 레이블 0일 경우 색상 설정
img[j, i] = (128, 128, 255)
elif res == 1: # 레이블 1일 경우
img[j, i] = (128, 255, 128)
color = [(0, 0, 128), (0, 128, 0)] # 레이블 별 색상 정의
for i in range(train.shape[0]):
x = int(train[i, 0])
y = int(train[i, 1])
l = label[i]
cv2.circle(img, (x, y), 5, color[l], -1, cv2.LINE_AA)
cv2.imshow('svm', img)
cv2.waitKey()
cv2.destroyAllWindows()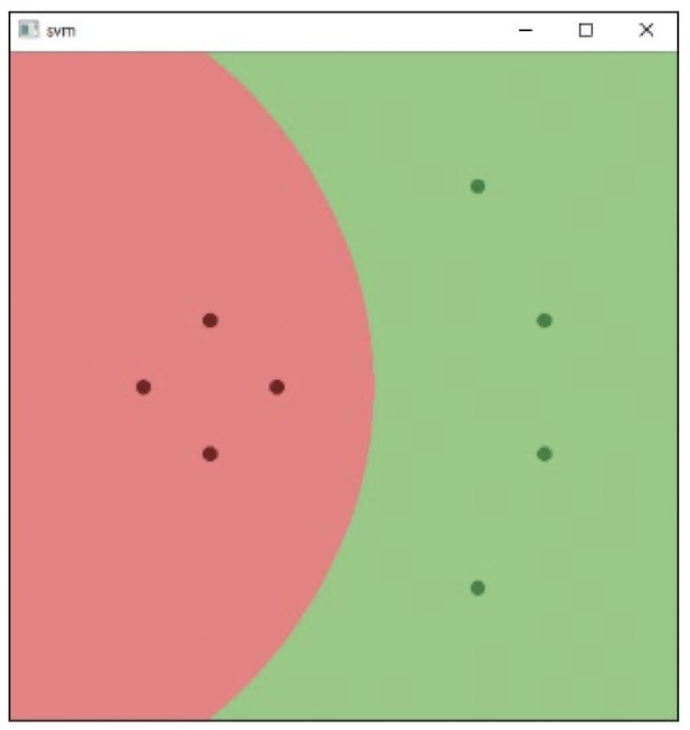
- 빨간색 원으로 표시된 점 : 0번 클래스 녹색 점 : 1번 클래스
HOG & SVM 필기체 숫자 인식
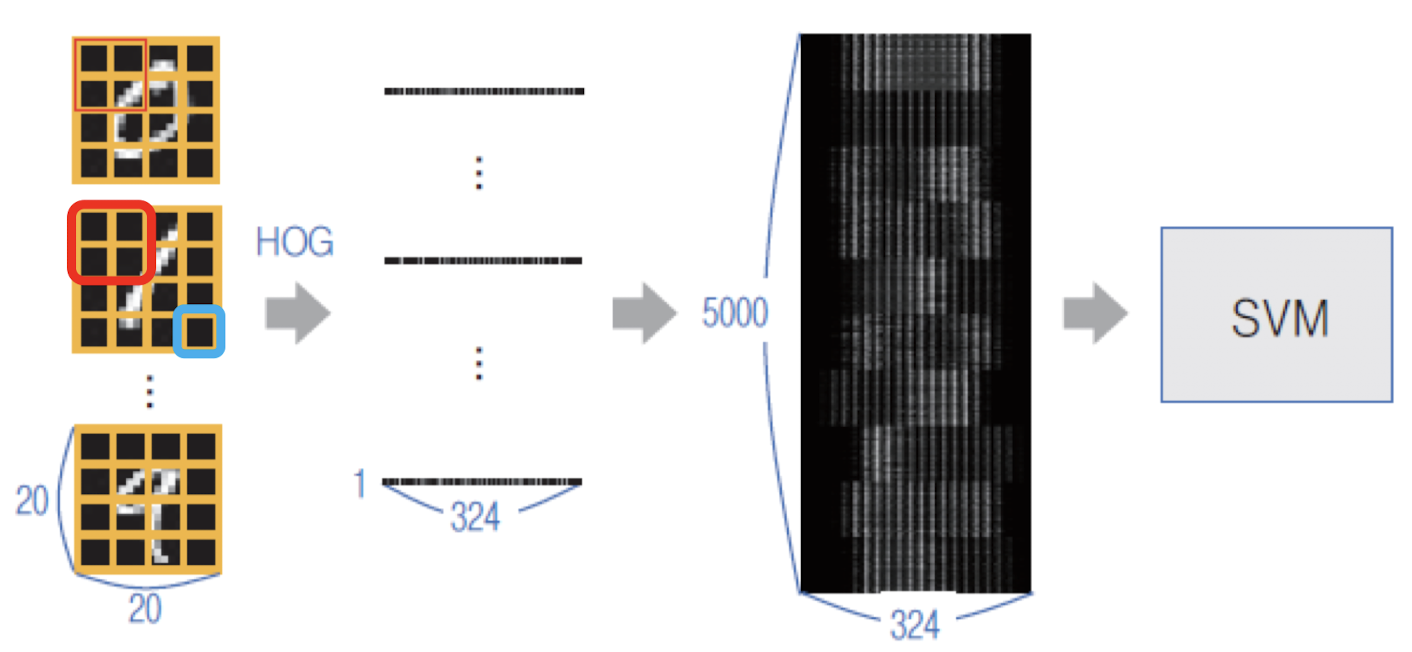
- HOG
- 입력 영상을 일정 크기의 cell로 분할
- 2x2 셀을 합쳐 하나의 block으로 설정
- 필기체 숫자영상 : 20x20
- 셀 하나의 크기 5x5로 지정
- 블록 하나의 크기 10x10
- 셀 하나에서 그래디언트 방향 히스토그램 : 9개의 빈
- 블록 하나에 9x4=36개의 빈으로 구성
- 셀 단위 이동 → 가로 3개, 세로 3개 생성
- HOG 특징 벡터의 차원 크기 : 36 x 9 = 324
- 20 x 20 → 1 x 324 특징 벡터 행렬 생성
- 세로로 쌓으면 : 5000 x 324 크기 → SVM 클래스의 훈련 데이터로 전달
- 세로로 쌓으면 : 5000 x 324 크기 → SVM 클래스의 훈련 데이터로 전달
HOG 클래스
- HOG 특징 벡터 추출
- HOGDescriptor 클래스 사용
- HOG 기술자 추출 기능 제공
- 객체 먼저 생성 → 기본 생성자 사용
- HOGDescriptor(_winSize, _blockSize, _blockStride, _cellSize, _nbins, _derivAperture = 1, _winSigma = -1, _histogramNormType, _L2HysThreshold = 0.2, _gammaCorrection = false, _nlevels = .., _signedGradient = false)
-
20x20 영상
-
5x5 셀
-
10x10 블록 사용
-
9개의 그래디언트 방향 히스토그램
→ hog(Size(20, 20), Size(10, 10), Size(5, 5), Size(5, 5), 9);
-
- HOG 기술자 계산
- HOGDescriptor::compute(img, descriptors, winStride, padding, locations);
import sys
import numpy as np
import cv2
oldx, oldy = -1, -1
def on_mouse(event, x, y, flags, _):
global oldx, oldy
if event == cv2.EVENT_LBUTTONDOWN:
oldx, oldy = x, y
elif event == cv2.EVENT_LBUTTONUP:
oldx, oldy = -1, -1
elif event == cv2.EVENT_MOUSEMOVE:
if flags & cv2.EVENT_FLAG_LBUTTON:
cv2.line(img, (oldx, oldy), (x, y), (255, 255, 255), 40, cv2.LINE_AA)
oldx, oldy = x, y
cv2.imshow('img', img)
digits = cv2.imread('digits.png', cv2.IMREAD_GRAYSCALE)
if digits is None:
print('Image load failed!')
sys.exit()
h, w = digits.shape[:2]
# HOG 디스크립터 설정 : 윈도우크기, 블록크기, 셀크기, 블록스트라이드, 방향그래디언트 빈의수
hog = cv2.HOGDescriptor((20, 20), (10, 10), (5, 5), (5, 5), 9)
# 숫자 이미지 20x20 크기 셀로 분할
cells = [np.hsplit(row, w/20) for row in np.vsplit(digits, h/20)]
cells = np.array(cells)
cells = cells.reshape(-1, 20, 20)
# HOG 특징 벡터 계산
desc = []
for img in cells:
dd = hog.compute(img)
desc.append(dd)
train_desc = np.array(desc).squeeze().astype(np.float32)
train_labels = np.repeat(np.arange(10), len(train_desc)/10)
# SVM 분류기 생성 및 설정
svm = cv2.ml.SVM_create()
svm.setType(cv2.ml.SVM_C_SVC)
svm.setKernel(cv2.ml.SVM_RBF)
svm.setC(2.5)
svm.setGamma(0.50625)
svm.train(train_desc, cv2.ml.ROW_SAMPLE, train_labels)
img = np.zeros((400, 400), np.uint8)
cv2.imshow('img', img)
cv2.setMouseCallback('img', on_mouse)
while True:
c = cv2.waitKey()
if c == 27:
break
elif c == ord(' '):
img_resize = cv2.resize(img, (20, 20), interpolation=cv2.INTER_AREA)
desc = hog.compute(img_resize)
test_desc = np.array(desc).astype(np.float32)
_, res = svm.predict(test_desc.T)
print(int(res[0,0]))
img.fill(0)
cv2.imshow('img', img)
cv2.destroyAllWindows()
숭실대학교 컴퓨터학부 21