Machine Learning 모델의 평가
- 성능 평가지표는 모델이 분류인지 회귀인지에 따라 여러 종류로 나뉨
- 회귀 : 실제값과 예측값의 오차 평균값에 기반 (MAE, MSE 등), 크게 복잡하지 않음
- 분류의 성능 평가지표는 조금 더 복잡함
분류의 성능 평가지표
1. 정확도 (Accuracy)
- 실제 데이터에서 예측데이터가 얼마나 같은지를 판단하는 지표
- (TN+TP) / (TN+FP+FN+TP)
- 직관적으로 모델 예측 성능을 나타냄
- 불균형 레이블 데이터셋에서는 사용하면 안됨
from sklearn.metrics import accuracy_score
accuracy_score(y_test, pred)
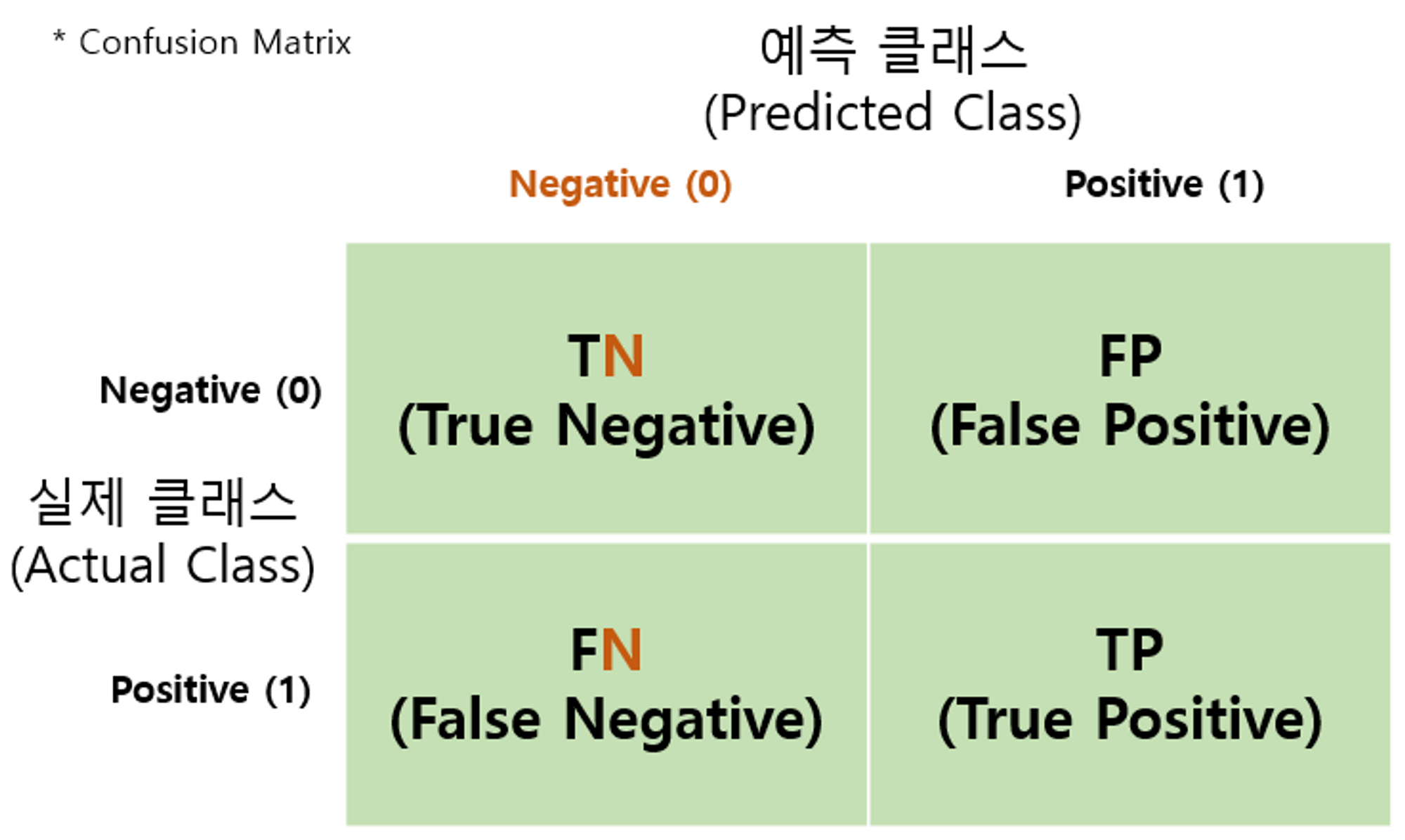
2. 오차행렬 (Confusion Matrix)
- from sklearn.metrics import confusion_matrix
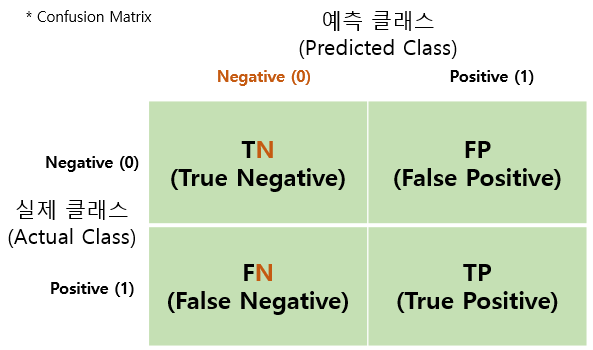
- TN : Negative(0)으로 예측하고 정답도 Negative(0)인 경우
- FN : Negative(0)으로 예측하였으나 정답이 Positive(1)인 경우
- FP : Positive(1)으로 예측하였으나 정답이 Negative(0)인 경우
- TP : Positive(1)으로 예측하고 정답도 Positive(1)인 경우
3. 정밀도 (Precision)
- 예측을 Positive로 한 대상 중에 실제 값이 Positive로 일치한 데이터의 비율
- TP / (FP+TP)
- from sklearn.metrics import precision_score
- 정밀도가 중요한 경우 : 실제 Negative인 데이터 예측을 Positive로 잘못 판단했을 때 영향이 큰 경우
4. 재현율 (Recall)
- 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positvie로 일치한 데이터의 비율
- TP / (FN + TP)
- from sklearn.metrics import recall_score
- 재현율이 중요한 경우 : 실제 Positive인 데이터 예측을 Negative로 잘못 판단 했을 때 영향이 큰 경우
5. F1 스코어
- 정밀도와 재현율을 결합한 지표
- 어느 한쪽으로 치우치지 않을 때 상대적으로 높은 값을 가짐
- Threshold 값을 수정하면서 최적의 F1 스코어를 찾을 수 있음
- 2 (Precision recall) / (precision + recall)
- from sklearn.metrics import f1_score
6. ROC AUC
- 이진분류 예측 성능 측정에서 중요하게 사용되는 지표
- AUC 값은 ROC 곡선 밑의 면적을 구한 것 (1에 가까운 값을 가질 수록 모델의 성능이 좋음)
- 랜덤 수준의 모델은 0.5의 값을 가짐
- Threshold 값의 변화에 따라 ROC AUC의 값이 변화함
- from sklearn.metrics import roc_auc_score
(참고) 정밀도 - 재현율 트레이드 오프
- 각 모델은 predict_proba() 메서드를 사용해서 레이블 별 점수를 확인 할 수 있음 (분류 모델)
- 점수가 높은 레이블을 정답으로 예측하는 방식 → predict 메서드는 predict_proba기반
- 기본은 0.5의 Threshlod 값을 가지고 클래스를 분류
- Threshold 값을 낯주면 Positive(1)로 예측할 확률이 높아짐. (0과 1로만 분류하는 문제의 경우) → 재현율이 올라감 (양성으로 예측하는 횟수가 많아짐 → 음성으로 예측하는 횟수가 적어짐)
- classification_report : 다중분류의 경우 각각의 클래스에 대한 정밀도, 재현율 출력하는 함수
- 다중 분류 평가에서 각 클래스의 성능을 개별적으로 측정하고 비교해야함
from sklearn.metrics import classification_report
report = classification_report(y_true, y_pred)
print(report)