DRL-VO: Learning to Navigate Through Crowded Dynamic Scenes Using Velocity Obstacles
human avoidance
목록 보기
7/7
- 2023, 9회 인용
- https://arxiv.org/pdf/2301.06512.pdf
Introduction
- 사람 회피 주행에, RL을 쓴 이유
로봇이 작동할 환경의 복잡성(사람이 무진장 많음) 때문에,전통적인 모델 기반 프레임워크 내에서, 사람을 회피하는 명확한 규칙을 설계하기 여렵기 때문에감독 학습 기법을 적용하기에 충분히 대표적인 교육 데이터를 수집하기 어려운 것 때문에
- 이 논문 6 가지 주요 기여
- 1) 우리는 신경망 기반 제어 정책에 입력할 데이터 표현의 새로운 조합을 만듭니다.
- 이는 풀링된 라이다 데이터의 짧은 역사, 근처 보행자의 현재 운동학, 하위 목표 지점
- 우리는 모든 데이터를 로봇의 로컬 좌표 프레임에 넣어 위치 오류에 강하게 만들고,
원시 센서 데이터에서 고급 표현을 수작업으로 만들어 새로운 환경에 대한 일반화를 향상- `보행자 운동학에 대한 완벽한 정보를 가질 필요가 없습니다.
- 2) 우리는 DRL 프레임워크에 대한 새로운 보상 함수를 생성하기 위해 속도 장애물(VO) 이론을 적용
- 3)
제안된 제어 정책이 충돌 회피와 속도 사이에서 더 나은 균형+다양한 군중 크기와 새로운 보지 못한 환경에서 기존 접근 방식보다 더 잘 일반화- 비교군: 모델 기반 컨트롤러 [4], 감독 학습 기반 접근 [5], 그리고 두 가지 DRL 기반 접근 [6]이 포함
- 4) 우리의 제안된 제어 정책이 다른 로봇 플랫폼에서 재훈련 없이 효과적으로 작동
- 5) 코드 + 3D 인간-로봇 상호 작용 시뮬레이터: https://github.com/TempleRAIL/drlvo_nav
- 6) 다른 로봇 학습 시스템에 적용될 수 있는, 우리 작업에서의 여러 중요한 설계 원칙을 요약
- 1) 우리는 신경망 기반 제어 정책에 입력할 데이터 표현의 새로운 조합을 만듭니다.
Related Work
- 로봇 항법 문제를 풀기위한 3가지 접근법
- 모델 기반 접근법
- 감독 학습 기반 접근법
- 강화 학습 기반 접근법
- 각 접근법은 각각의 장단점이 있지만, 통제되지 않고 인간이 가득한 환경에서,
- 일반 모델을 수동으로 설계하거나 효과적인 훈련 데이터를 수집하기 어렵기 때문에
- 우리는 강화 학습 기반 프레임워크를 선택합니다.
1. 모델 기반 접근법
기대점
- 효율적인 경로를 계산하며 매개변수가 쉽게 해석됨
한계점
- 보행자 운동학에 대한 지식이 필요하며, 아래의 이유로 인해
새로운 시나리오로 일반화하고 구현하기 어려움센서 데이터를 처리하기 위해 다단계 절차를 사용해야함.종종 실무자들이 모델 매개변수를 신중하게 수동 조정해야함.
- 다양한 시나리오에 대해 모델 매개변수를 수동으로 조정해야 합니다 [4], [9]–[19].
1) 전형적인 접근법: obstacle costmap
- ROS[8] 네비게이션 스택이며, 장애물 정보를 저장하기 위해 코스트맵을 사용하고, 로컬 계획을 수립하기 위해 동적 윈도우 접근법(DWA) 플래너[4]를 사용
- ROS 네비게이션 스택을 기반으로, [9]는 최근에 인간 인식 항법 문제를 처리하기 위해,
글로벌 및 로컬 플래너 모두에 인간 안전성 및 가시성 코스트맵을 추가(볼만 함)
2) 속도 장애물(VO) 기반 알고리즘
- [10]-[12]: 로봇 속도 공간(VO)에 동적 환경을 매핑하고, 이러한 속도 제약에서 안전한 제어 속도를 생성
- 마찬가지로, Arul 등[13]은 상호 속도 장애물(RVO)과 버퍼링된 보로노이 셀을 결합하여 다중 에이전트 항법 문제를 해결
3) 모델 예측 제어(MPC)[14], [15]를 사용
- environment dynamics 고려
- 이는 로봇 제약 조건에, 충돌 회피 및 장애물 동역학을 통합
4) 인간과 로봇의 상호 작용을 직접 모델링하려고 시도
- 사회적 힘[16], [17], 가우시안 혼합 모델(GMM)[18] 또는 잠재적 기능과 한계주기의 결합[19]을 사용
2. supervised-learning 기반 접근법
기대점
- 순수하게 데이터 기반으로 사용하기 쉽다.
한계점
- 네트워크를 훈련시키기 위해 전문가 데모 세트를 수고롭게 수집해야 합니다 [5], [20]–[24].
3. 강화 학습 기반 접근법
한계점
- 보상 함수를 신중하게 설계해야 합니다 [6], [26]–[41].
중요 포인트
- 어떤 센서 데이터를 사용할지, 어떻게 처리할지, 어떤 데이터 표현을 사용할지
1) 원시 센서 데이터 수준 접근법
기대점
- 센서 데이터를 처리하기 위한 별도 절차가 필요하지 않음.
- 빠르고 쉽게 제어 정책을 생성할 수 있음.
한계점
- 정적 또는 동적 장애물을 구별할 수 없으며
- 장애물의 위치와 속도와 같은 고급 정보를 활용할 수 없음
논문 소개
- Guldenring 등[6]은
2D 라이다 데이터의 다양한 상태 표현을 조사하고 -> PPO 훈련 알고리즘을 사용하여 인간 인식 항법 정책을 훈련- 읽어보기
- Learning Local Planners for Human-aware Navigation in Indoor Environments
- http://ras.papercept.net/images/temp/IROS/files/0122.pdf
- 2020, 51회 인용, IROS
- Arpino 등[28]은
원시 라이다 데이터를 입력으로 사용하여 -> 실내 항법 정책을 훈련하는 다중 레이아웃 훈련 체제를 제시- 읽어보기
- Robot navigation in constrained pedestrian environments using reinforcement learning
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9560893
- 2021, ICRA 53회 인용
- Huang 등[29]은
원시 라이다 데이터와원시 카메라 이미지 데이터를 융합하는 다중 모달 후기 융합 네트워크를 구축.- 읽어보기
- Towards multi-modal perception-based navigation: A deep reinforcement learning method
- 2021, 25회 인용
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9372890
2) 보행자 운동(위치/속도 등)에 대한 정보를 활용 하는 에이전트 수준 접근법
원시 센서 데이터만 사용하는 한계를 해결하기 위해,보행자 운동에 대한 정보를 활용
기대점
- 정적 또는 동적 장애물을 구별하여 처리
- 장애물의 위치와 속도와 같은 고급 정보 활용 가능
한계점
- 개방된 공간에서 혼잡한 항법 문제를 해결하기에만 적합하며
정적 장애물과 레이아웃의 기하학적 제약을 무시
소개
- Everett 등[30]-[32]은
- 보행자의 상대 위치와 속도를 직접 신경망에 공급하고,
- 보행자가 많은 환경에서 사회적으로 인식되는 충돌 회피 정책을 생성
- Chen 등[33] -> 로봇-인간 상호작용 모델링
인간-로봇 및 인간-인간 상호 작용을 self attention 메커니즘으로 함께 모델링하는 데 중점- 읽어보기
- 2019, 462회 인용
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8794134
로봇-인간 상호 작용을 추론하고 그들의 궤적을 예측하기 위해 관계형 그래프 학습 네트워크를 제안[34]. -> 로봇-인간 상호작용 모델링 + 보행자 궤적 예측- 읽어보기
- 2020, 100회 인용
- Relational graph learning for crowd navigation
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9340705
[35]은 그래프 컨볼루션 네트워크(GCN)로 군중 상태를 인코딩하고 인간의 주의를 예측- 읽어보기
- 2020, 112회 인용
- Robot navigation in crowds by graph convolutional networks with attention learned from human gaze
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8990034
- 최근에, Liu 등[36]은 로봇과 보행자 사이의 상호 작용을 모델링하기 위해
분산 구조적 순환 신경망(RNN)을 사용 -> 로봇-인간 상호작용 모델링- 읽어보기
- 2021, ICRA 64회 인용
- Decentralized structural-rnn for robot crowd navigation with deep reinforcement learning
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9561595
3) 에이전트 수준 접근법 + 정적 장애물과 레이아웃 고려
기대점
- 정적 또는 동적 장애물을 구별하여 처리 +
정적 장애물과 레이아웃 고려
한계점
- 센서 인식 정보와 그 데이터 표현을 활용하는 데만 초점을 맞추고 있으며, 보상 함수 설계를 무시
소개
- Liu 등[37]은 추가적인 정적 장애물 맵을 추가하여 [33]의 작업을 확장하지만,
보행자의 존재/부재를 처리하기 위해 두 개의 병렬 네트워크 모델이 필요-> 로봇-인간 상호작용 모델링- 읽어보기
- Robot Navigation in Crowded Environments Using Deep Reinforcement Learning
- 2020, 79회 인용
- http://ras.papercept.net/images/temp/IROS/files/0386.pdf
- Sathyamoorthy 등[38]은 [26]의 PPO 훈련 정책을 확장하여
보행자 궤적 예측과 원시 라이다 데이터를 결합하는 후기 융합 네트워크를 사용 -> 보행자 궤적 예측- Densecavoid: Real-time navigation in dense crowds using anticipatory behaviors
- 읽어보기
- 2020, 77회 인용
- https://obj.umiacs.umd.edu/gamma-umd-website-imgs/pdfs/crowdmultiagent/ICRA_2020_DenseCAvoid.pdf
- Dugas 등[39]은
미래 라이다 잠재 상태를 예측하고 재구성하기 위해 unsupervised 학습 아키텍처를 사용- Navrep: Unsuper- vised representations for reinforcement learning of robot navigation in dynamic human environments
- 2021, ICRA 46회 인용
- https://jenjenchung.github.io/anthropomorphic/Papers/Dugas2021navrep.pdf
4) 에이전트 수준 접근법 + 정적 장애물과 레이아웃 고려 + 보상함수 고려
기대점
- 정적 또는 동적 장애물을 구별하여 처리 +
정적 장애물과 레이아웃 고려+보상 함수 설계 고려
한계점
- knowledge distillation reward의 효과는 전문가 데이터셋의 품질에 크게 의존
- 정사각형 경고 영역 기반 보상 함수는 너무 보수적이어서 느린 동작을 초래
소개
- 이와 관련하여, Xu 등[40]은 propose a knowledge distillation reward term to encourage the robot to learn expert behaviors.
- Patel 등[41]은 로봇이 장애물의 향하는 방향과 반대 방향으로 항해하도록 장려하는 정사각형 경고 영역 기반 보상 함수를 제안 -> 장애물 비용 행렬 구축
- 읽어보기
- Dwa-rl: Dynamically feasible deep reinforcement learning policy for robot navigation among mobile obstacles
- https://obj.umiacs.umd.edu/gamma-umd-website-imgs/pdfs/crowdmultiagent/DWA_RL.pdf
비교 분석
1. 사전 처리된 데이터 표현을 쓰는 것이 더 성능이 좋다. (원시 센서 데이터 보다)
- 모델 기반 접근법의 장기적 성공과 최근 강화 학습 연구의 결과는
원시 센서 데이터 < 사전 처리된 데이터 표현이라는 것을 입증- 이는 보행자 동작에 대한 보다 유용한 정보를 포함하며, 그 결과 동적 환경에서의 안전성을 향상
- 이러한 추세에 따라, 우리는 라이다 데이터의 짧은 역사와 보행자의 현재 운동학을 포함한 사전 처리된 센서 데이터를 사용 [5].
- 이 데이터 표현의 주요 장점
다른 강화 학습 기반 작업 [33]–[38]에서 사용되는 복잡한 보행자 예측 또는 상호작용보다 훨씬 간단하고 해석하기 쉽다는 것
- 또한, 모든 데이터는 로봇의 로컬 좌표 프레임 내에 전적으로 표현되어 밀집된 동적 환경에서 흔한 위치 오류에 강한 솔루션을 만듦.
2. 충돌 회피의 부담을 사람에게 전가하지 않고, TTC기반 위험한 사람에만 국한되지 않는, 개선된 보상 함수를 설계했다.
- 대부분의 접근법은 목표로의 진행을 보상하는 항목과 충돌을 처벌하는 항목을 포함합니다 [6], [26]–[39].
- 이 간단한 보상 함수 설계는 잘 작동할 수 있지만, 희박한 충돌 회피 보상 함수는 충돌에 대해 큰 부정적인 보상만 제공하며,
로봇이 장애물을 적극적으로 피하도록 유도하는 직접적이고 효과적인 보상 신호를 제공하지 않음. - 실제로, 수동적인 충돌 회피 보상 함수는 제로 차수 함수로, 충돌 위험이 장애물과의 거리에만 의존한다고 가정
- 이 간단한 보상 함수 설계는 잘 작동할 수 있지만, 희박한 충돌 회피 보상 함수는 충돌에 대해 큰 부정적인 보상만 제공하며,
보행자(및 기타 객체)의 상대적 움직임이 더 중요하다!- 왜냐하면 people often follow one another closely in dense crowds and give more space when walking in opposite directions.
- 이에 대한 한 시도는 [41]의 역 보상 함수로, 안전을 우선시하지만 느린 움직임을 유발하고 밀집된 군중에서 교착 상태를 야기할 수 있음.
- 우리는 충돌로 이어질 가능성이 있는 향방을 처벌하는 일차 속도 장애물(VO)을 사용하는 새로운 보상 함수를 제안
- 이를 통해
로봇은 목표를 향해 진행하면서 보행자 군중을 적극적으로 피하기 위해 지속적으로 향방을 조정
- 이를 통해
- Han et al. [42]은 동시에 분산 다중 로봇 항법을 위한 상호 속도 장애물(RVO) 기반 보상 함수를 개발했으나, 우리 속도 장애물 개념(VO)은 2가지 차별점이 있다.
- 첫째, 우리의 작업은,
충돌 회피의 책임을 전적으로 ego 로봇에게만 부여- 우리는 로봇-인간 충돌을 방지하기 위해 VOs를 사용
이는 충돌 회피의 전체 부담을 로봇에게 전가- 왜냐하면
우리는 직접 인간 행동을 모델링하거나 제어할 수 없기 때문
- 반면에 Han et al. [42]은 RVO를 사용하여 로봇-로봇 충돌을 방지하려고 합니다.
- 이는 두 에이전트가 유사한 제어 정책을 실행한다는 가정에 기반하여 충돌 회피의 부담을 에이전트 간에 분담
- 우리는 로봇-인간 충돌을 방지하기 위해 VOs를 사용
- 둘째, 우리의 접근법은
로봇이 잠재적인 미래 로봇-인간 충돌을 피하면서 목표를 향해 적극적으로 가는 것을 장려하는 반면,그들의 접근법은 충돌 예상 시간(TTC)으로 판단된 잠재적인 로봇-로봇 충돌에만초점을 맞추고 목표를 무시- 43번 논문은 강화 학습 보상 함수에서 RVO를 사용하는 대신, 충돌이 임박했을 때 강화 학습에서 RVO로 전환하는 병렬 제어 정책으로 사용
3. 논문 기여 요약
- 우리 논문 기여: 센서 데이터 표현 + 보상 함수 설계
- 우리는 제어 정책에 대한 입력으로 사전 처리된 센서 데이터의 독특한 조합을 사용
- 라이다 데이터의 짧은 역사: 정적 장애물과 환경의 기하학적 구성에 대한 정보
- 다중 객체 추적기: 동적 장애물에 대한 운동학 정보
- 부목표 지점: 목적지에 도달하는 방법에 대한 정보
- 우리는 모델 기반 접근법(즉, 속도 장애물)의 유용성을 활용하여 새로운 보상 함수를 설계합니다.
- 구체적으로,
보행자 운동학에 대한 완벽한 정보를 가질 필요가 없습니다. - 이 새로운 term은, 로봇이 충돌 회피와 속도 사이의 좋은 균형을 가진 견고한 항법 정책을 배울 수 있게 함.
- 구체적으로,
Navigation Policy
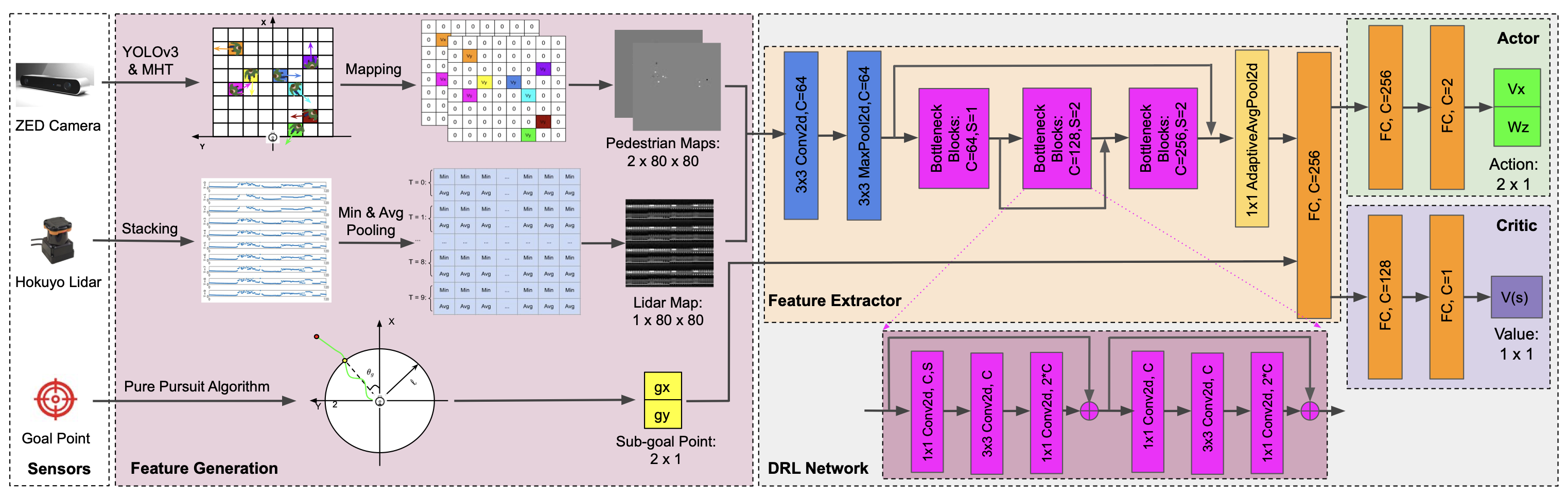
Observation Space
- [5]와 같은 partial obseration을 사용했음.
Pedestrian Kinematics
- 기존 연구 [46]은 crowd의 위치 정보만 이용한 representation을 사용했다.
- 우리는 사람들의 위치와 속도 정보를 모두 representation에 사용했다.
- 로봇 정면
20m * 20m(80 * 80Grid) - human detection: YOLOv3
- Tracking (사람 속도 추출을 위함)
- Multi Hypothesis Tracker(MHT)
Lidar History (l_t)
0초 ~ 과거 0.5초의 데이터를 봅니다.- 실험해보니, 과거 0.5초까지의 데이터를 보는게 결과가 가장 좋았다고 합니다.
- 4.5도를 resolution으로 하여, 360도를 80칸에 표현함. (각 칸에 대해, min & average 값을 이용)
위 포멧이 적절한 Lidar format임을, 실험을 통해 증명
- 비교군
- reshaping the raw lidar data
- projecting scan points into an occupancy grid map
- pooling(min / average / median / max)
- 결과적으로, min & avg pooling이 젤 좋았다.
Goal Position
- 2m 앞의 subgoal을 input으로 넣음.
위 input 3가지에 대해, 각각 -1~+1 사이로 normalize해서, 넣어줌.
- 좋은 방법은 아닌 것 같다. (최대 감지거리 4m인 로봇과, 8m 인 로봇에 대해, 하나의 network로 사용하려면, 위 방법은 부적절한 normalize로 보임)
Network Architecture
- 위 Input 구조는, 로봇에 어떤 센서가 어디에 붙어있든 상관없이, 하나의 네트워크로 여러 센서 suite에 적용할 수 있습니다.
Reward Function
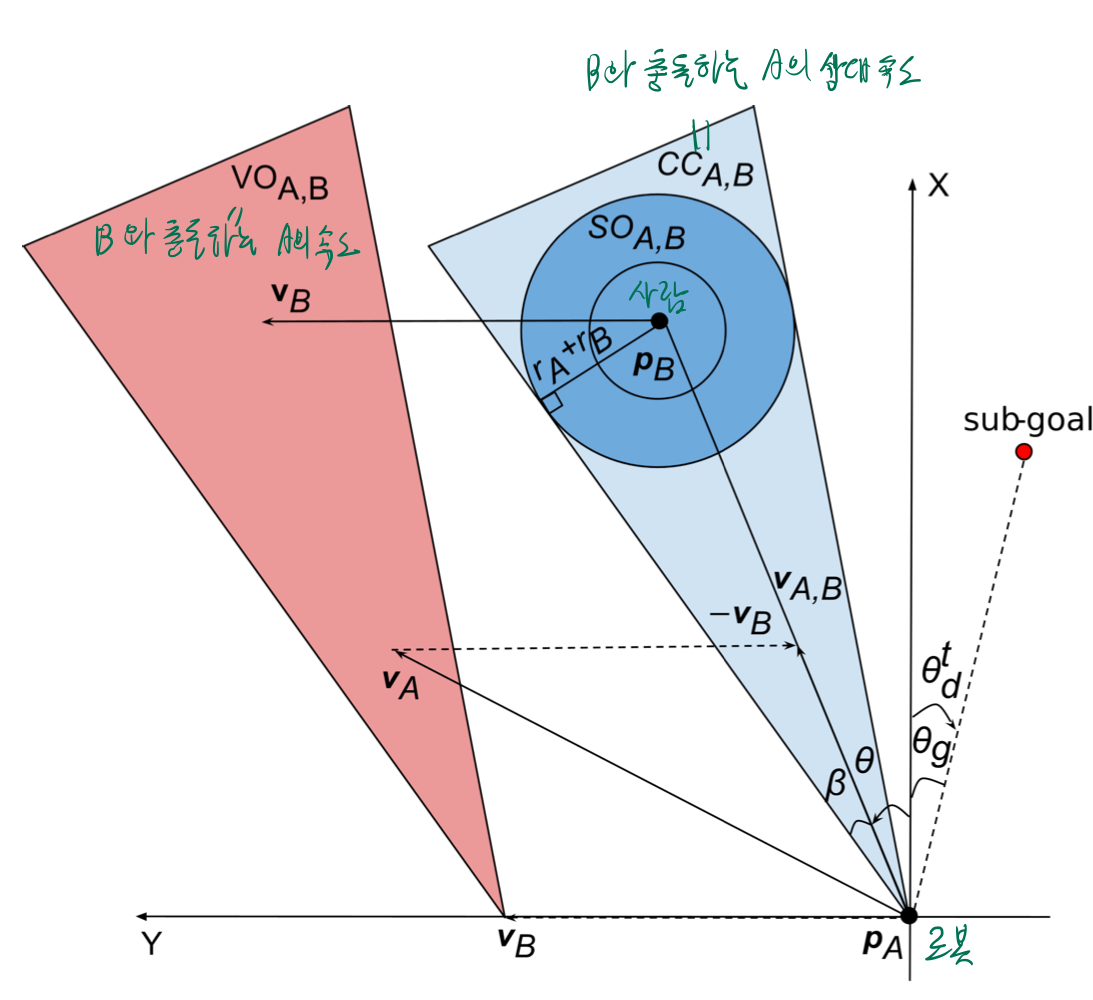
- g
- goal에 다가갈 때 보상
- 우리가 쓰던 거랑 똑같음. (t-1초 때 goal과의 거리 - t초 일때 goal과의 거리)
- c
- 장애물과의 거리에 따른 벌.
- 장애물과의 거리가 1.2m 안에 들어오면, 가까워질수록 선형적으로 벌점을 늘립니다.
- 장애물과의 거리가 0.3m 안에 들어오면, 최대 벌점
- w
- 급격히 방향 꺾을 때 벌.
- 각속도가 1rad(57도) 이상이면, 커질수록 선형적으로 벌점을 늘립니다.
- d
- 요약: 현재 heading이, 사람과 충돌을 일으키지 않으면서도 목표를 바라보고 있을 수록 -> 보상을 선형적으로 크게 주겠다.
- 과정 1: 모든 장애물의 VO 에 속하지 않으면서도, sub-goal에 가장 가까운
현재 local coordinate 기준 목표 각도 찾기 - 과정 2:
현재 local coordinate 기준 목표 각도의 절댓값이 0에 가까울수록 보상을 크게 줌 
CROWDED DYNAMIC ENVIRONMENTS
- Gazebo 시뮬레이터 [56]와 PEDSIM 라이브러리 [57]를 사용하여 일련의 3D 시뮬레이션 실험을 수행
PEDSIM은 사회적 힘 모델 [16], [58]을 사용하여 개별 보행자의 움직임을 안내하는 미시적 보행자 군중 시뮬레이션 라이브러리- 여기서 Fp는 보행자 p의 움직임을 결정하는 결과적인 힘이며;
- Fdes는 보행자를 목적지로 이끌고;
- Fobs는 보행자를 정적 장애물로부터 멀리 밀어내며;
- Fper는 다른 보행자와의 상호작용(예: 충돌 회피 또는 그룹화)을 모델링하고;
- Frob는 보행자를 로봇으로부터 멀리 밀어내어,
- 사람들이 자연스럽게 충돌을 피하는 방식을 모델링하여 우리의 제어 정책이 이 행동을 학습할 수 있게 합니다.
- 첫 세 항목은 표준 모델의 일부이며 마지막 항목은 새로운 것입니다.
- 훈련 환경의 또 다른 중요한 측면은 인간 행동의 현실성입니다.
- 항법 연구자들이 사용하는 보행자 군중 모델에는 세 가지 유형이 있습니다:
- 사회력 기반 모델 [5], [6], [9], [17],
- 속도 장애물 기반 모델 [28], [30]–[34], [36]–[39], 그
- 리고 보행자 데이터셋 기반 모델 [18], [35], [40].
- 이 연구들, 특히 보행자 데이터셋에 의해 주도되는 연구들은 보행자 역학만을 모델링하고, 인간-로봇 상호 작용을 완전히 무시합니다.
- 그러나, 우리의 실제 세계 실험에서, 우리는 로봇에 대해 세 가지 구별되는 유형의 인간 반응을 관찰했으며, 각각은 로봇에 다른 방식으로 영향을 미칩니다.
- 첫 번째이자 가장 일반적인 것은 보행자들이 로봇을 피하기 위해 그들의 경로를 약간 조정하지만 그들의 길을 계속 가는 것입니다.
- 두 번째로, 일부 보행자들은 우리 로봇에 대해 궁금해하며 종종 멈춰서 지켜보거나 로봇의 행동을 관찰하기 위해 로봇을 따라갑니다.
- 세 번째이자 가장 드문 것은 일부 보행자들이 로봇을 두려워해 빠르게 로봇에서 멀어지려고 시도하는 것입니다.
- 이 목록은 결코 포괄적이지 않으며, 항법에 영향을 미치는 훨씬 더 많은 인간-로봇 상호 작용이 있을 것입니다.
- 대신, 이 목록은 로봇에 대한 인간의 반응을 완전히 무시하는 접근 방식이 덜 성공적일 것이며 시뮬레이션과 현실 간의 격차가 더 클 것임을 보여주기 위한 것입니다.
- 우리의 접근 방식은 몇몇 다른 그룹들 [6], [17]과 마찬가지로 간단합니다: 사람들과 로봇을 서로 멀어지게 하는 추가적인 사회적 힘을 추가합니다.
- 우리는 미래의 작업에서 유망한 방향 중 하나는 인간 행동의 범위를 탐구하고, 이것이 로봇에 어떤 영향을 미치는지 결정하며, 시뮬레이션 환경에서 이 행동을 (대략적으로) 재구성하는 방법을 개발하는 것이 될 것이라고 믿습니다.
실험 설정
- ZED 카메라의 깊이 범위는 [0.3, 20]m로 설정되며, 시야각은 90도입니다. Hokuyo 라이다의 측정 범위는 [0.1, 30]m로 설정되며, 시야각은 270도이고, 각도 해상도는 0.25도입니다.
시뮬레이션 결과 metric
- 성공률: 충돌 없는 시도의 비율
- 평균 시간: 평균 이동 시간
- 평균 길이: 평균 이동 거리
- 평균 속도: 평균 이동 속도
결과 분석
보상 설계
- 속도 장애물을 사용하는 또 다른 동기는 로둇이 성공적인 모델 기반 접근 방식에서 간접적으로 학습할 수 있도록 하는 것이었습니다.
- 예를 들어, 속도 장애물을 기반으로 하는 컨트롤러는 환경에 대한 완벽한 지식이 있다는 가정 하에 충돌 회피를 보장할 수 있습니다.
- 그러나 실제로는 그러한 가정이 결코 유효하지 않습니다.
- 따라서 속도 장애물을 직접 적용하여 제어 동작을 생성하는 대신, 안전에 (적어도 가까운) 행동을 안내하는 보상 항으로 사용합니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.