리뷰
1. 특징
- semantic feature vector 형태로 map을 저장하기 때문에, 한번 지도를 생성해놓으면 어떤 open vocabulary로도 물체를 검색할 수 있다.
2. dataset
- Matterport 3D dataset
- Visual Language Map (2D)는 아래그림
- Visual Language Map을 이용하여 할 수 있는 task 예시
0. abstract
- 동영상 예시는 VLMaps 웹사이트에서 볼 수 있습니다.
- 우리는 VLMaps를 개발
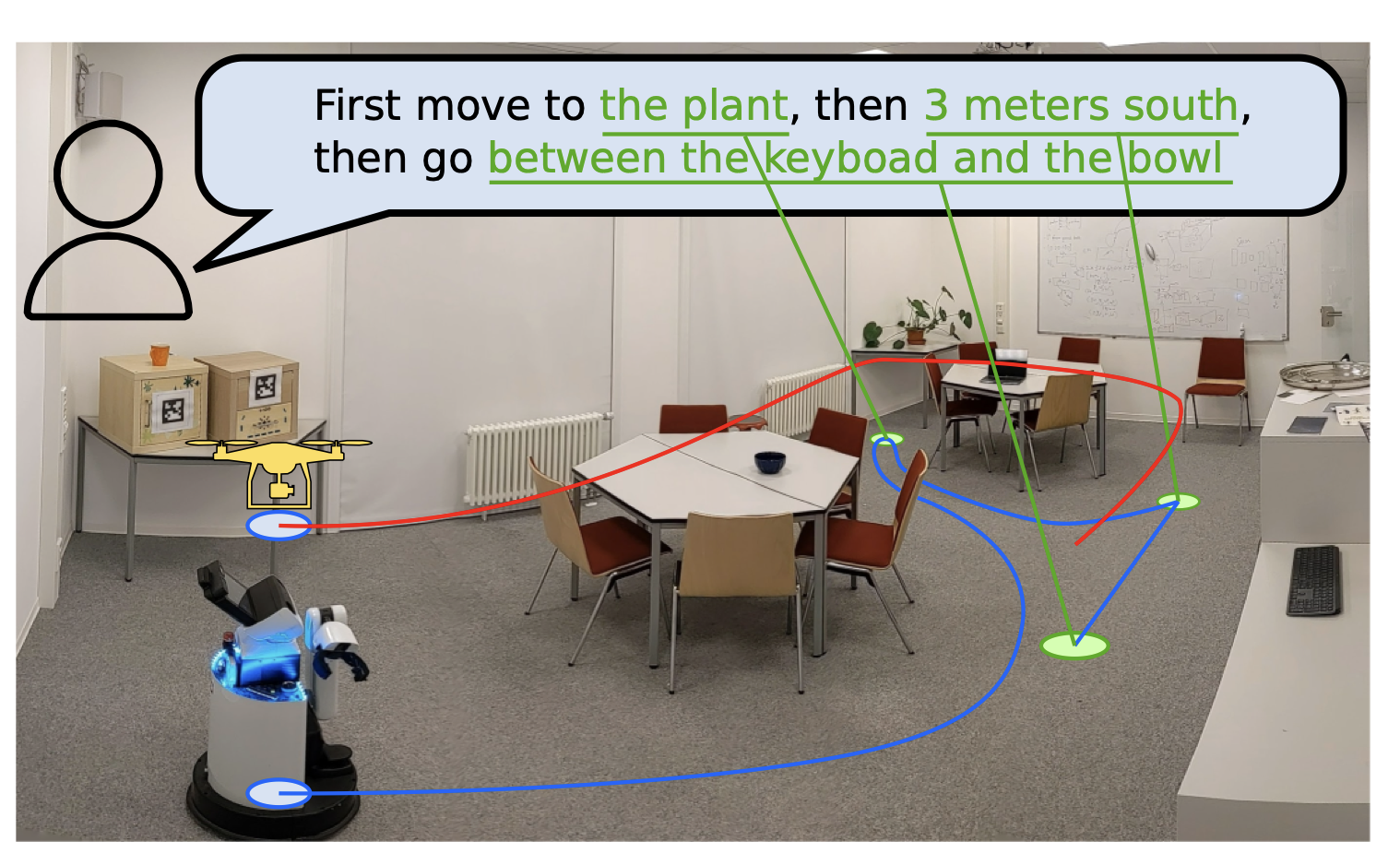
- 이 지도를 통해, 로봇은 복잡한 언어 지시에 따라 길을 찾을 수 있다.
- 예:
책상 정면을 1m 앞에서 바라보는 곳으로 가!
- 예:
- 이 지도를 통해, 로봇은 복잡한 언어 지시에 따라 길을 찾을 수 있다.
- VLMaps: Visual-Language Maps
- 2d global grid map이며, 각 픽셀에는 물체 종류를 추론할 수 있는 feature vector가 저장되어 있다.
- 찾고싶은 물체 카테고리 라스트는, 내가 맘대로 설정 가능하다. (예: "음식점", "카페", "엘레베이터" 등을 포함한 200개 단어)
- 이 지도를 만들기 위해,
pre-train된 LVM만 가져와서 사용하면 되며, fine-tuning 없이 적용 해볼 수 있다. - 우리가 해야할 일:
로봇이 수동으로 돌아다니거나, 자동 탐색 알고리즘을 통해 돌아다니면서 RGBD 비디오 촬영 - 이 기술의 핵심은
- "소파와 TV 사이"나 "의자에서 오른쪽으로 1 미터"와 같이 구체적이고 공간적인 지시를 할 때,
- VLMaps가 이를
정확한 위치 정보로 변환해 로봇이 이해할 수 있게 해준다는 것
- 또한, 서로 다른 모양과 크기를 가진 여러 로봇이, 이 지도를 공유하면서 새로운 장애물을 식별
- 이를 지도에 실시간으로 업데이트할 수도 있음
- 기존 연구들과의 차별점
- 기존의 방법보다 더 복잡한 언어로 된 지시에 따라 로봇이 길을 찾는 데 효과적
1. Introduction
- LVM을 사용하지 않던 기존 연구들은,
- 로봇이 주변 환경에 대한 기하학적 지도를 만듭니다.
- 예를 들어, 로봇이 벽이나 장애물을 감지하여 이를 지도에 표시합니다.
- 그런 다음, 이 지도를 기반으로 목적지까지의 경로를 계획합니다.
- 또한, 이 방식은 자연어 명령어(예: "문으로 가세요")를 분석하여 로봇이 수행해야 할 구체적인 작업을 결정할 수 있도록 지원합니다.
- 로봇이 주변 환경에 대한 기하학적 지도를 만듭니다.
- 기존 연구들의 문제점
- 이 방법은
로봇이 처음 보는 상황이나 지시에 대처하는 데 한계 - 즉, 로봇이 과거에 학습하지 않은 새로운 명령어나 환경에 직면했을 때, 어떻게 행동해야 할지 판단하기 어려울 수 있습니다.
- 예: 특정 카테고리만 분류하는 segmentation model로 지도를 만들었는데, 다른 class도 찾고 싶으면, 매핑을 다시 해야함.
- 이 방법은
- 최근 연구들: 인터넷 규모의 데이터(예: 이미지 캡션)에 대해 사전 학습된 시각-언어 모델(VLMs) 을 사용
- 이 기술은 로봇이
시각적 관찰을 자연어로 이해할 수 있도록 돕는다. - 예를 들어,
로봇이 사진에서 의자를 인식하고 "의자 옆으로 가세요"라는 명령어를 이해할 수 있게 됩니다. - 이 접근법의 장점은 추가적인 데이터 수집이나 모델 fine-tuning 없이도 새로운 상황이나 지시에 대응할 수 있다는 것
- 하지만,
기하학적 지도의 공간적 정밀도는 확보하지 못한 방법들이 대부분이었다.
- 이 기술은 로봇이
- 또한, VLMs는
CoW와 LM-Nav와 같은 탐색 알고리즘과 결합될 수 있습니다. - 위 방법들은 유망하지만, 아래와 같은 문제점 존재
- (i)
멀티 로봇들이 하나의 map을 관리하고 구축하는데에 한계점이 있음 - (ii)
디테일한 공간적 목표(예: “소파와 TV 사이”)의 정확한 위치를 알아내는 것이 어려움 - (iii)
다양한 embodiments(mobile robot, drone 등) 간에 공유될 수 있는 지속적인 표현을 구축하는 것이 어려움
- (i)
- 이 논문의 VLMaps은, 위 문제들을 극복하고, 아래의 것들을 할 수 있음!
객체 중심 목표를 넘어서서, 공간적 목표를 지역화할 수 있습니다.- 예를 들어, “TV와 소파 사이”나 “의자의 오른쪽” 또는 “주방 영역”을
code-writing LLMs를 사용하여 가능케 함
- 예를 들어, “TV와 소파 사이”나 “의자의 오른쪽” 또는 “주방 영역”을
- 다양한 언어 명령을 줬을 때, 그 목적지로 가는 성능이 뛰어남
- 자연어 지시 ->
a sequence of open-vocabulary goals로 바꾸는 방법- Socratic fashion의 LLM을 사용!
- https://velog.io/@jk01019/Socratic-Models-Composing-Zero-Shot-Multimodal-Reasoning-with-Language
Related work
- scene graphs 논문들
추상적 지도predefined set of semantic class에 한정되어 있었음- https://openaccess.thecvf.com/content/CVPR2021/papers/Wu_SceneGraphFusion_Incremental_3D_Scene_Graph_Prediction_From_RGB-D_Sequences_CVPR_2021_paper.pdf (Hydra 전 논문임)
- 2021, 136회 인용
- https://arxiv.org/pdf/2201.13360.pdf (Hydra 임)
- 2022, 138회 인용
- 이것도 시간되면 읽어보자.
- https://arxiv.org/pdf/2209.09874.pdf
- 2023, 123회 인용
- VLMaps는 이전 연구와 달리,
- 구축된 지도를 이용하여, 다양한 자연어 인덱싱을 가능하게 하는 open-vocabulary 시맨틱 맵입니다.
2. Method
- 아래 그림이 논문의 핵심이다.
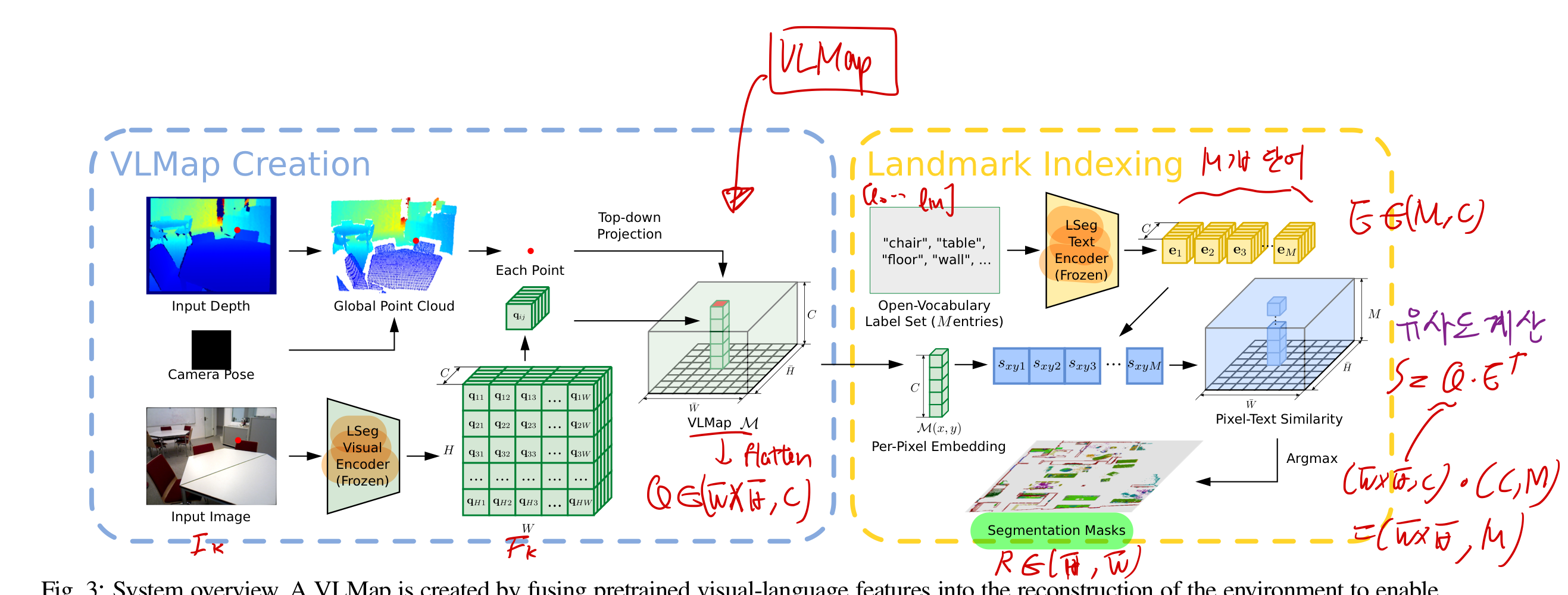
- 전체 과정은, 위 그림을 보고 이해하는 것만으로 충분하다.
2.1. Visual-Language Map 만드는 법!
- VLM을 만드는 과정은, 위 그림의 왼쪽 파란색 상자에 설명되어 있다.
- visual-language model로, LSeg를 썼는데, 이는 CLIP을 사용하는 것보다 성능이 훨씬 좋다.
- 구체적으로는,
- RGB image encoder: LSeg의 image encoder을 씀
- Open Vocabulary Label Set의 encoder: LSeg의 Text Encoder을 씀.
- 우리의 가정
- RGB-D SLAM이 가능하다.
2.2. VLM을 이용하여, 임의의 Landmark를 localizing 하자!
- 위 그림의 오른쪽 노란색 상자에 설명되어 있다.
2.3. Generating Open-Vocabulary Obstacle Maps
- 자연어로 설명된 장애물 카테고리 목록이 주어진 경우,
런타임에이러한 장애물들을 로컬라이징하여- 충돌 회피 및/또는 최단 경로 계획을 위한 바이너리 지도를 생성할 수 있습니다.
- 이의 두드러진 사용 사례는 different embodiments를 가진 다양한 로봇 간에
- 동일한 환경의 VLMap을 공유하는 것입니다 (즉, 크로스 엠보디먼트 문제 [36], [37]).
- 이는 다중 에이전트 조정 [38]에 유용할 수 있습니다.
- 예를 들어,
큰 모바일 로봇은 테이블(또는 다른 큰 가구) 주위를 탐색해야 할 수 있지만,드론은 그 위를 직접 날아갈 수 있습니다.- 큰 모바일 로봇을 위한 하나의 장애물 카테고리 목록(여기에 "테이블"이 포함됨)과
- 드론을 위한 다른 목록(여기에 "테이블"이 포함되지 않음)을 제공함으로써,
- 두 로봇 각각이 사용할 수 있는 두 개의 별도의 장애물 지도를 동일한 VLMap에서 실시간으로 생성할 수 있음
- 이를 수행하기 위해,
- 먼저 깊이 포인트 클라우드의 탑다운 지도에서 각 투영된 위치가 1로 할당되고 그렇지 않은 경우 0으로 할당되는
- 장애물 지도 O ∈ {0, 1}H×W를 추출합니다.
- 바닥이나 천장에서 포인트를 피하기 위해, 높이에 따라 필터링된 포인트 PW가 제외됩니다.
2.4. Zero-Shot Spatial Goal Navigation From Language
- 이 섹션에서는 아래 예시와 같은
자연어 지시로 지정된 랜드마크 설명 세트를 제공하여 장기 목표(공간적) 내비게이션에 접근하는 방법을 설명- "먼저 카운터의 왼쪽으로 이동한 후, 싱크대와 오븐 사이를 이동하고, 소파와 테이블을 두 번 왕복하여 이동합니다."
- 기존 연구 [12], [13]와는 달리,
- VLMaps는
"TV 옆 소파 사이"또는"의자에서 동쪽으로 3미터"와 같은 정확한 공간 목표를 참조할 수 있음 - 구체적으로, 우리는 대형 언어 모델(LLM)을 사용하여, 입력된 자연어 명령을 해석하고 이를 sub goals로 분해 [35], [13], [14].
- VLMaps는
- (기존 연구), 이러한
sub goals를 언어로 참조하고, 시맨틱 translation [39] 또는 affordance(e.g. 컵: 들기 / 옮기기 / 뒤집기) [35], [40], [41], [42]를 통해 low-level polices으로 매핑하는 대신, - 우리는 LLM의 코드 작성 능력을 활용하여
실행 가능한 파이썬 로봇 코드를 생성[43], [33], [44], [27]. - 이 코드는
- (i) 매개변수화된 내비게이션 기본 기능을 정확하게 호출할 수 있으며,
- (ii) 필요할 때 산술 연산을 수행할 수 있습니다.
- 생성된 코드는 내장된 파이썬 exec 함수를 사용하여 로봇에서 직접 실행할 수 있습니다.
- exec: 이 함수를 사용하면
문자열 형태의 파이썬 코드를 실제 코드처럼 실행
- exec: 이 함수를 사용하면
- 최근 연구 [43], [33], [44], [27]는
Github에서 수십억 줄의 코드를 학습한 코드 작성 언어 모델(예: Codex [44])이docstring에서 새로운 간단한 파이썬 프로그램을 합성하는 데 사용할 수 있음을 보여줌- TODO: 나~중에 이쪽에 대해서도 공부해보기
- 이 연구에서 우리는
이러한 모델을 모바일 로봇 계획에 재사용하여,몇 가지 자연어 명령 입력 예제(주석 형식)와이에 대응하는 로봇 코드로 프라이밍합니다. (Few 샷 프롬프팅을 통해)- "프라이밍":
특정 작업을 수행하기 위해 시스템이나 모델을 준비시키는 과정을 의미
- "프라이밍":
- 로봇 코드는
- 함수 또는 논리 구조(
if-then-else 문이나for/while 루프)를 표현하고 - API 호출(예:
robot.move_to(target_name)또는robot.turn(degrees))을 매개변수화할 수 있음
- 함수 또는 논리 구조(

- get_contour(object_name):
- 가장 가까운 앞쪽에 있는 객체의 윤곽선 전환점을 찾아야 한다는 의미
- get_contour(object_name):
- 이 코드는
language commands으로 구체화된 공간 행동에 매핑됨 - 테스트 시,
- 모델은 새로운 명령을 입력받아, API 호출을 자율적으로 재구성하여 새로운 로봇 코드를 생성할 수 있습니다
- 아래 코드는 prompt 프라이밍 과정
# move a bit to the right of the fridge robot.move_to_right(‘refrigerator’)
# move in between the couch and bookshelf robot.move_in_between(‘couch’, ‘bookshelf’) # face the toilet
robot.face(‘toilet’)
# move to the west of the chair robot.move_west(‘chair’)
# turn right 20 degrees
robot.turn(20)
# find any chairs in the environment robot.move_to_object(‘chair’)
# with the television on your left robot.with_object_on_left(‘television’)
# move forward for 3 meters robot.move_forward(3)
# move right 2 meters
robot.turn(90)
robot.move_forward(2)
# move back and forth to the chair and table 3 times pos1 = robot.get_pos(‘chair’)
pos2 = robot.get_pos(‘table’)
for i in range(3):
robot.move_to(pos1)
robot.move_to(pos2)
# move 3 meters south of the chair robot.move_south(‘chair’) robot.face(’chair’)
robot.turn(180)
robot.move_forward(3)
# turn west
robot.turn_absolute(-90)
# turn east
robot.turn_absolute(90)
# turn south
robot.turn_absolute(180)
# turn north
robot.turn_absolute(0)
# turn east and then turn left 90 degrees robot.turn_absolute(90)
robot.turn(-90)
# navigate to 3 meters right of the table robot.move_to_right(’table’) robot.face(’table’)
robot.turn(180)
robot.move_forward(3)- 테스트 시: (입력 작업 명령은 주석, 생성된 출력).
# move first to the left side of the counter, then move between the sink and the oven, then move back and forth to the sofa and the table twice
robot.move_to_left(‘counter’)
robot.move_in_between(‘sink’, ‘oven’)
pos1 = robot.get_pos(‘sofa’)
pos2 = robot.get_pos(‘table’)
for i in range(2):
robot.move_to(pos1)
robot.move_to(pos2)
# move 2 meters north of the laptop, then move 3 meters rightward
robot.move_north(‘laptop’)
robot.face(‘laptop’)
robot.turn(180)
robot.move_forward(2)
robot.turn(90)
robot.move_forward(3)- 코드 작성 LLM은 언어 명령에 언급된 새로운 랜드마크를 참조할 뿐만 아니라,
새로운 API 호출 시퀀스를 연결하여,보지 못한 지시를 따를 수 있는 코드를 생성
- 언어 모델이 호출하는 내비게이션 기본 함수(예: robot.move_to_left('counter'))는
- 미리 생성된 VLMap을 사용하여 지도에서 오픈 보캐블러리 랜드마크('counter')의 좌표를 로컬라이징하고,
- 미리 정의된 스크립트 오프셋으로 수정합니다('왼쪽'을 정의하기 위해).
- 그런 다음, embodiment-specific 장애물 지도를 입력으로 받아 이 좌표로 이동합니다.
3. Experiment
3.1. Simulation Setup
Habitat Simulator (+Matterport 3D dataset)을 기반으로, 언어 기반 목적지 도달 알고리즘을 테스트- Habitat Simulator: 사실적인 3D 렌더링
- Matterport 3D dataset: 다양한 실내공간의 3D 스캔을 포함하는 데이터셋 (사실적 texture)
- 열 개의 다른 장면에서 12,096개의 RGB-D 프레임을 수집하고 각 프레임의 카메라 포즈를 기록
- AI2THOR simulator에서도 평가함. (여러 에이전트 유형(예: LoCoBot 및 드론)을 지원 )
- AI2THOR의 열 개의 방에서 1,826개의 RGB-D 프레임을 수집
- 이 두 환경에서 로봇은 전진 0.05미터, 좌회전 1도, 우회전 1도 및 정지와 같은 행동으로 연속적인 환경을 탐색해야 함
3.2. Baselines
- 총 5가지 ( 이들 모두는
시각-언어 모델을 활용하며,제로샷 언어 기반 내비게이션이 가능) - LM-Nav
- 환경의 이미지 관찰을 노드로 저장하고 이미지 간의 근접성을 엣지로 나타내는 그래프를 생성
- GPT-3와 CLIP을 결합하여 언어 지시를 랜드마크 목록으로 파싱하고, 해당 노드를 향해 그래프 상에서 계획
- CLIP on Wheels(CoW)
- CLIP과 GradCAM [47]을 사용하여
목표 카테고리의 중요도 지도를 생성함으로써언어 기반 객체 내비게이션을 수행 - 중요도 값을 임계값으로 설정하여 목표 객체 카테고리의 분할 마스크를 검색하고, 그런 다음 지도를 따라 경로를 계획
- CLIP과 GradCAM [47]을 사용하여
- CLIP-features-based map(CLIP Map)
- 우리와 유사한 방식으로 환경에 대한 기능 지도를 생성하는 baseline
- LSeg visual feature 대신, CLIP visual feature을 뷰를 통해 평균하여 지도에 투영
- 객체 카테고리 마스크는 지도 기능과 객체 카테고리 기능 간의 유사성을 임계값으로 설정하여 생성
- (우리 논문 방법인데, LSeg 대신 Clip 쓴 방식)
- 우리 논문 방법
- 우리 논문 방법인데, GT LVMap을 시뮬레이터에서 확보한 후, 그걸 이용해서 알고리즘 돌린 방식
3.3. 결과
- 목적지에 도착 성공한 성공률 비교
- subgoal 갯수를 늘려가며 테스트하였다.
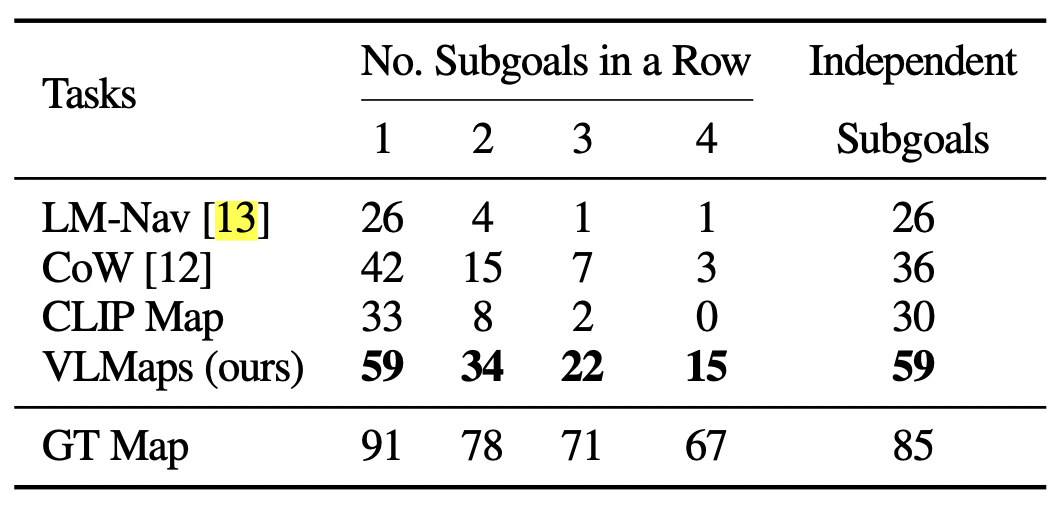
- GT Map을 들고 주행한 것보다, 성공률이 아직 많이 낮다. 이유는 무엇일까?
4. 한계점 및 개선점
- 성공률이 아직 많이 낮은 이유
- Map 구축 과정에서, localization noise 때문에, depth 추정이 부정확해서
- 비슷하게 생긴 랜드마크를, 어떻게 구분할지는 아직 숙제이다.
- 화장실 가줘! (몇 층 화장실로 가달라는거야?)
- navigation 알고리즘을, LLM 기반 코드 생성 방식에 의존해서
5. 부록
C. 프롬프트 엔지니어링
- 이 연구의 모든 방법(기준선을 포함하여)에서 CLIP 텍스트 인코딩을 사용할 때, 객체 카테고리의 레이블을 단순히 프롬프트하는 대신,
- [10]에서 언급된 "label의 사진", "label의 그림"과 같은 프롬프트 템플릿의 앙상블을 사용하여 검색 성능을 향상시킵니다.
D. Top-down Map Semantic Segmentation
- ablation study를 위해, 우리는 Habitat 시뮬레이터에서 Matterport3D 데이터셋을 사용하여 Top-down Map Semantic Segmentation를 계산
- 섹션 IV-A에서 언급된 수집된 RGB-D 프레임을 사용하여 VLMaps와 CLIP on Wheels 중요도 지도를 생성
- 우리는 Matterport3D 데이터셋에서 지원하는 모든 시맨틱 카테고리(전체 목록은 링크1에서 확인 가능)를 평가하지만,
- https://github.com/niessner/Matterport/blob/master/metadata/mpcat40.tsv
- "void", "floor", "ceiling", "objects", "misc"는 제외
- 실제 시맨틱 마스크를 얻기 위해, 우리는 RGB-D 프레임과 실제 이미지 시맨틱 마스크를 사용하여 시맨틱 탑다운 지도를 생성
- 우리는 깊이 픽셀을 3D 공간으로 다시 투영하고 이를 탑다운 지도에 투영
- 관련 시맨틱 값을 탑다운 지도 픽셀에 할당
- 중요:
여러 포인트가 동일한 위치에 투영되는 경우, 새 포인트의 높이가 이전 포인트보다 큰 경우 이전 값을 덮어씀(2D의 한계)
- 중요:
- VLMaps에 대한 시맨틱 마스크를 계산하기 위해, 우리는 섹션 III-B에서 설명한 오픈 보캐블러리 랜드마크 인덱싱 기술을 전체 카테고리 목록에 적용
- CLIP on Wheels에 대한 시맨틱 마스크를 계산하기 위해, 우리는 중요도 값을 계산하고 [12]에서와 동일한 임계값 설정 과정을 적용하여 각 카테고리에 대한 이진 마스크를 얻습니다.
- 우리는 [50]에서 사용된 시맨틱 분할 메트릭을 평가합니다. 분할 결과는 표 V에 표시됩니다.
- 표는 VLMaps가 대부분의 상위 10개 빈번한 카테고리에서 CoW Map보다 더 잘 수행된다는 것을 보여줍니다.
- 이는 주로 CoW에서 사용된 GradCam이 중요도 지도에 많은 노이즈를 도입하여 결과에 과분할을 초래하기 때문입니다.
- 또한 "seating" 클래스에서 VLMaps가 0 IOU 점수
- 우리가 사용한 LSeg 모델이, 일부 쿼리 클래스가 사전 정의된 훈련 카테고리에 포함되지 않은 세그멘테이션 데이터셋에서 사전 훈련되었기 때문에,
- LSeg의 시각적 인코더는 시각적으로 보지 못한 객체("seating")를 유사한 본 객체의 임베딩 공간("chair" 또는 "sofa")에 인코딩할 것입니다.
- 결과적으로 시각적-텍스트 불일치가 발생할 수 있습니다.
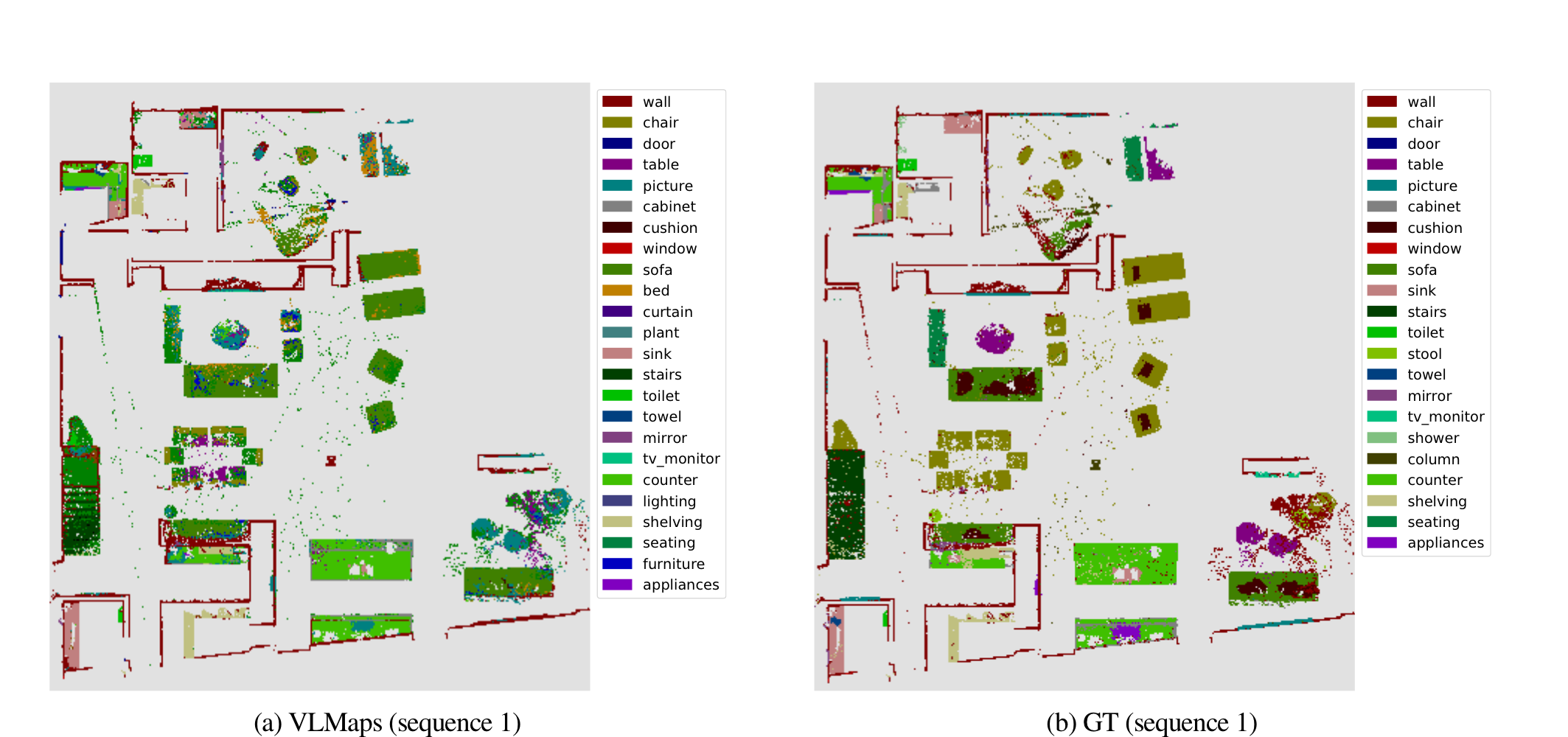
- 우리는 그림 6에서 정성적 분할 결과를 시각화합니다.
- "wall", "chair", "counter", "table", "bed" 카테고리의 경우, 분할 결과가 대부분 정확합니다.
- 때때로, "sofa"와 "chair"가 유사한 재료와 형태로 있을 때(그림 6a 및 6b), VLMaps는 이를 구별하지 못하여 잘못된 계획 동작을 초래할 수 있습니다.
- 우리는 또한 그림 6c 및 그림 6e에서 일부 객체의 분할이 노이즈가 있는 것을 관찰
- 이는 우리가 채택한 기능 융합 전략에 의해 발생할 수 있음
- 우리가 장면에 대한 VLMaps를 생성할 때, 우리는 탑다운 지도에서 동일한 위치에 투영되는 포인트의 시각적 임베딩을 평균화
- 평균화 작업은 융합된 기능에 노이즈를 도입하여 노이즈가 있는 분할 예측을 초래할 수 있음(테이블에 "sink" 예측).
- 향후 더 발전된 융합 기술을 탐색하여 분할 결과를 개선할 수 있음

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.