SIMPLIFYING MODEL-BASED RL: LEARNING REPRESENTATIONS, LATENT-SPACE MODELS, AND POLICIES WITH ONE OBJECTIVE
강화학습
목록 보기
13/19
abstract
- Model-based RL 성능을 극대화하기 위한 논문
강화학습 알고리즘 중, 최고의 샘플 효율성 + 더불어 계산시간 단축을 달성하기 위함- 보통 sample efficient한 model-based 알고리즘은 계산량이 많은 경우가 흔한데, 우리 방법은 SAC 의 성능에 도달하면서도 SAC 학습시간보다 50% 단축되었다.
- 강화 학습에서 환경의 내부 모델을 학습하는 방법은 샘플(경험 데이터)의 사용을 최적화하여 더 효율적인 학습이 가능할 수 있습니다.
- 하지만 고차원의 센서 데이터로부터 raw observations을 모델링하는 것은 어려운 과제입니다.
- 전 연구들은
reconstruction or value prediction과 같은 보조 목표를 사용하여 관측값의 저차원 표현을 학습 - 이 방법은 관측 데이터를 더 잘 이해하고 처리하는 데 도움을 줄 수 있지만, 이 보조 목표들이 RL의 주요 목표와 어떻게 연결되는지는 종종 불분명합니다.
- 전 연구들은
- 연구에서는
잠재 공간 모델과 정책을 동시에 최적화하는 새로운 단일 목표를 제안- 이 목표는
예상 return의 하한선을 설정하는 것으로, 이를 통해 높은 수익을 달성하면서 모델의 자체 일관성을 유지 기존의 모델 기반 RL에서 사용된 하한선들은 주로 정책 탐색(policy exploration)이나 모델 검증(model guarantees)에 적용되었지만, 이 연구에서 제안된 하한선은 전체 RL 목표에 직접 적용
- 이 목표는
Introduction
- 세계의 내부 모델을 학습하는 강화 학습(RL) 알고리즘은 모델이 없는 방법보다 더 빨리 학습할 수 있지만, 세계 모델들이 정확히 무엇을 예측해야 하는지는 여전히 해결되지 않은 문제입니다.
- 실제 세계와 현실적인 시뮬레이터는 정확하게 모델링하기에 너무 복잡합니다.
- 비록 훈련 분포 하에서 모델 오류가 드물 수 있지만, 학습된 RL 에이전트는 종종 모델이 실수하는 상태를 찾아내려 합니다. (world model을 특정 범위 내에서 신뢰도 있게 잘 만들어 놔도, policy network는 world model이 취약한 부분으로 행동을 선택할 수도 있습니다.)
- 단순히
세계 모델을 maximum likelyhood로 훈련하는 것만으로는, 일반적으로 모델 기반 RL(MBRL)에 좋은 모델을 만들지 못함.
- 정책 목표와 모델 목표 사이의 불일치는 목표 불일치 문제(Lambert et al., 2020)라고 불리며, 여전히 활발한 연구 분야입니다.
- 목표 불일치 문제는 고차원 관측값을 가진 설정에서 특히 중요하며, 이는 고신뢰도로 예측하기 어렵습니다.
- 이전 모델 기반 방법들은
원시 관측값의 동역학보다는,관측값의 컴팩트한 표현의 동역학을 학습함으로써 고차원 관측값을 모델링하는 어려움에 대처해왔습니다. - 이러한 표현들은 그들의 학습 목표에 따라
- 여전히 예측하기 어렵거나
- 작업 관련 정보를 포함하지 않을 수 있습니다.
- 예: BEV map을 표현(상상)하는데, 내가 가야할 경로 부근의 퀄리티를 높이지 않고, 이미 지나온 경로 부근의 퀄리티를 높이기 위해 학습되고 있을 수도 있다.
- 또한, 표현 예측의 정확도는 모델의 매개변수뿐만 아니라, 정책이 방문하는 상태에도 달려 있습니다.
- 예
- 정책이 익숙하지 않은 곳으로 자꾸 가려하면, 그 쪽 환경에서의 표현 예측 정확도는 낮을 것이다.
- 표현 예측 정확도를 높이기 위한, 괜찮은 정책이 있을 텐데, 현재 정책 목적함수는 이를 고려하지 않고 학습된다.
- 예
- 따라서 예측 오류를 줄이는 또 다른 방법은
모델이 부정확한 전환을 피하면서+높은 수익을 달성하는 정책을 최적화하는 것입니다. - 결국 우리는 모델, 표현, 그리고 정책을 자체 일관성 있게 훈련하고 싶습니다:
정책은 모델이 정확한 상태만 방문해야 하며,표현은 작업 관련 및 예측 가능한 정보를 인코딩해야 합니다.
- 모델 기반 추론에 충분하지만, 충분히 컴팩트한 표현을 자동으로 학습하는 모델 기반 RL 알고리즘을 설계할 수 있을까요?
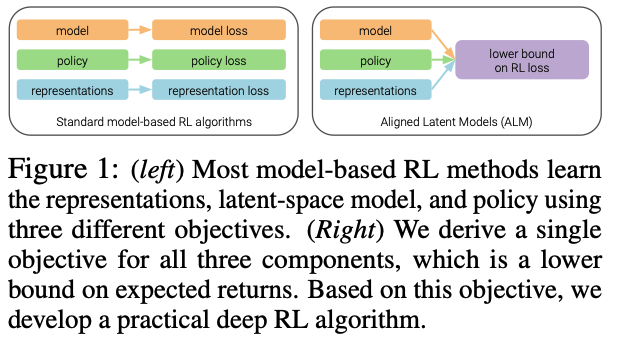
- 이 논문에서 우리는 모델 기반 알고리즘의 세 구성 요소인 표현, 모델, 정책을 동시에 최적화하는 단일 목표를 고안함으로써 이 질문에 대한 간단하면서도 원칙적인 답을 제시합니다.
- 그림 1에서 보여지듯, 이것은 세 개의 별도 목표를 사용하는 이전 방법들과 대조됩니다.
- 우리는 모델 기반 RL을 잠재 변수 문제로 보는 이전 작업을 바탕으로 합니다
목표는 return(the likelyhodd)을 극대화하는 것이며, 이것은 trajectories(관찰되지 않은 잠재 변수)에 대한 기대값입니다.이것은 보상 함수와 무관하게 관찰된 데이터의 likelyhood를 극대화하는 이전 작업과 다릅니다.- 예전에는, action sequence가 주어졌을 때, observations 의 likelyhood를 극대화하는 방향으로 representation과 model이 학습되었습니다.
- 이 관점은 모델 기반 RL 알고리즘이 추론 알고리즘과 유사해야 하며, 궤적(잠재 변수)을 샘플링한 다음, 이 궤적에서 return(우도)을 극대화해야 함을 시사합니다.
- 그러나 관측값이 고차원일 때 궤적을 샘플링하는 것은 어렵습니다.
- 우리 작업의 핵심은
trajectories(observations, actions)과representations of observations(=states)을 추론하는 것입니다. - 중요한 것은,
고차원 관측값을 샘플링할 필요 없이, 이 추론된 분포 하에서 예상 수익을 극대화하는 방법을 보여줍니다.
- 이 논문의 주요 기여는 Aligned Latent Models (ALM)입니다.
- ALM jointly optimizes the
observation representations,a model that predicts those representations, anda policy that acts based on those representations. - 우리가 아는 한, 이 목표는 잠재 공간 모델을 가진 모델 기반 RL 방법에 대한 첫 번째 하한입니다.
- 연속 제어 작업의 범위에서, 우리는 ALM이 이전 모델 기반 및 모델이 없는 RL 방법보다 더 높은 샘플 효율성을 달성한다는 것을 보여줍니다.
- 이는 이전 MBRL 방법들이 해결하지 못한 작업을 포함합니다. ALM은 앙상블 또는 decision-time planning 을 필요로 하지 않기 때문에, 우리의 오픈 소스 구현은 MBPO 보다 10배, REDQ 보다 6배 빠른 업데이트를 수행하며, SAC보다 약 50% 적은 시간에 최적의 수익을 달성합니다.
- decision-time planning
- 'decision-time planning'은 에이전트가 실행할 행동을 결정할 때, 현재의 상황에서 미래의 가능한 상황들을 시뮬레이션하여 최적의 행동을 결정하는 과정을 말합니다.
- 실시간으로 복잡한 결정을 내려야 하는 상황에서 중요한 전략이며, 미래의 가능한 결과를 고려하여 현재 최적의 결정을 내리는 데 도움을 줍니다.
- Monte Carlo Tree Search (MCTS)
- 가능한 행동의 트리를 확장하고, 무작위 시뮬레이션을 통해 각 행동의 결과를 평가합니다. 이를 통해 가장 성공적인 결과를 낳을 것으로 예상되는 행동을 선택합니다.
- Lookahead Planning
- 에이전트는 현재 상태에서 가능한 여러 행동 시퀀스를 고려하고, 각 시퀀스가 미래에 어떤 결과를 낳을지를 평가합니다.
- 이 정보를 바탕으로 현재 상태에서 가장 좋은 행동을 선택합니다.
- Model-based Reinforcement Learning
- 에이전트는 환경의 모델을 사용하여 미래의 상태와 보상을 예측하고, 이를 통해 최적의 행동 정책을 학습합니다.
- 이는 에이전트가 실제 환경에서 행동을 취하기 전에 다양한 시나리오를 탐색할 수 있게 해줍니다.
- Monte Carlo Tree Search (MCTS)
A UNIFIED OBJECTIVE FOR LATENT-SPACE MODEL-BASED RL
- test
METHOD OVERVIEW
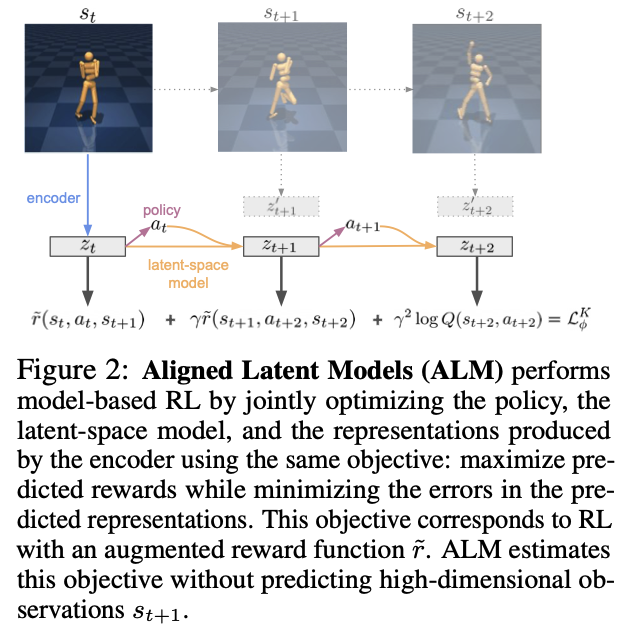
-
Encoder: 인코더는 고차원의 관측 데이터(예: 이미지)를 입력으로 받아 잠재 공간에 있는 저차원의 표현 ( z_t )로 변환합니다. 이렇게 변환된 데이터는 처리하기 쉽고, 계산적으로 효율적입니다.
-
Latent-Space Model: 잠재 공간 모델은 현재의 잠재 상태 ( zt )와 행동 ( a_t )를 기반으로 다음 시간 스텝에서의 잠재 상태 ( z{t+1} )을 예측합니다. 이 모델은 또한 이 행동이 가져올 보상을 예측하는 역할도 합니다.
-
Policy: 정책은 주어진 잠재 상태에 대해 어떤 행동을 취할지 결정하는 규칙 또는 함수입니다. 이 정책은 최적의 행동을 취하기 위해 잠재 공간 모델과 함께 최적화됩니다.
-
Objective Function: 목적 함수는 예측된 보상을 최대화하고, 예측된 표현의 오류를 최소화하는 것입니다. 이는 강화학습에서 사용되는
보상 함수에 추가적인 요소를 포함하여 수정된, 보상 함수 \(\tilde{r}\)와 관련이 있습니다.
- 이 시스템의 핵심은 각 시간 스텝에서 에이전트가 잠재 공간 모델을 사용하여 다음 상태의 잠재 표현과 보상을 예측하고, 이를 기반으로 최적의 행동을 결정한다는 것입니다. 그리고 이 모든 과정은 고차원 관측 데이터 ( s_{t+1} )를 직접 예측하지 않고도 수행됩니다. 이는 계산 비용을 절감하고, 효율적으로 학습을 진행할 수 있게 해줍니다.


새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.