Abstract
- 목적: scalable + generalizable을 지닌
강화 학습 알고리즘 / behavior cloning 알고리즘을 만들기 위해, 큰 규모의 unlabeled 다양한 순차 데이터(st, at, .. 조합)을 이용해 사전 훈련하는 MaskDP을 제시scalable- 확장 가능한 모델은 다양한 규모의 데이터 세트에 적용될 수 있어야 합니다.
더 많은 데이터나 복잡성에 대응하여, 성능이 선형적으로 또는 예측 가능한 방식으로 향상됨을 의미- 더 크고 복잡한 문제에 대해서도 높은 정확도, 강인성 및 효율성을 보여야 합니다.
generalizable훈련 중에 본 데이터나 상황뿐만 아니라, 새롭고 보지 못한 데이터나 상황에 대해서도 잘 작동함을 의미- 특정 훈련 환경에 과도하게 특화되지 않고 광범위한 상황에 적용될 수 있음
- masked decision prediction(MaskDP)
- 작동 방식
- 상태(환경의 상황)와 액션(에이전트의 행동)이 포함된 시퀀스에 마스크를 적용
- 마스크된 오토인코더(MAE)를 사용하여, 가려진 상태와 액션을 맞추는 것이 목표인 학습을 진행
- 이를 통해,
dynamics에 대한 추가 정보를 학습할 수 있도록 함.
- 목적
- zeroshot 전이 능력 향상
처음 마주하는 환경에서도 에이전트가 학습 없이 바로 적용될 수 있는 능력 향상- generalization
다양한 작업 수행 능력 향상- scalable
- zeroshot 전이 능력 향상
- 추가적 장점
오프라인 강화학습에 효과적으로 적용 가능모델의 크기가 커져도 성능이 전형적으로 향상: scalable데이터 효율적인 fine-tuning: generalizable
- 작동 방식
우리 도메인에 적용하면 어떤 의미?
- 새롭고 보지 못한 데이터나 상황에 대해서도 잘 작동?
- 센서 스펙이 바뀌어도, 추가 학습 없이 한번에 잘 작동할 수 있는 주행 알고리즘
- 새로운 환경에 가도, 추가 학습 없이 한번에 잘 작동할 수 있는 주행 알고리즘
Introduction
- Self-supervised pretraining 은 scalable to large Internet-scale datasets and deep neural networks,
- leading to excellent flexibility and generalization for downstream tasks.
- 이를 RL에 도입하기 위한 시도들이 있었는데, 주로
autoregressive next token prediction방법을 택했음- While promising, these works
do not leverage diverse unlabeled datafor generalization across various downstream tasks. - 예
- 어떤 논문은
reward-labeled high quality datasets이 필요 - 어떤 논문은
discretizing states and actions이 필요.
- 어떤 논문은
- While promising, these works
- 목표: 임의의 masks를 적용할 수 있는 유연성.
- 첫번째 발견
autoregressive next token prediction말고,random masking이 더 general하다.- 이유
single model that can reason about both the forward and inverse dynamics from each sample.
- 두번째 발견
a high mask ratio (95%) is necessary to make reconstruction task meaningful.- 이유
- since states and actions are highly correlated temporally, trajectories have significantly lower information density,
- i.e, it is easier to predict action or state based on nearby states and actions.
- 세번째 발견
다양한 마스크 비율을 사용하는 것이 모델의 성능 향상에 중요하다는 점- 예를 들어, 15%, 35%, 75%, 95% 등과 같이 다양한 비율을 사용합니다.
- 학습 과정에서는 이러한 마스크 비율 중 하나를 무작위로 선택하여 데이터의 해당 비율만큼을 가립니다.
- 즉, 이 방법이 모델이 더 정확하게 예측하고 효과적으로 학습하는 데 기여합니다. (다양하고 어려운 목표를 달성하는 설정에서 높은 성능)
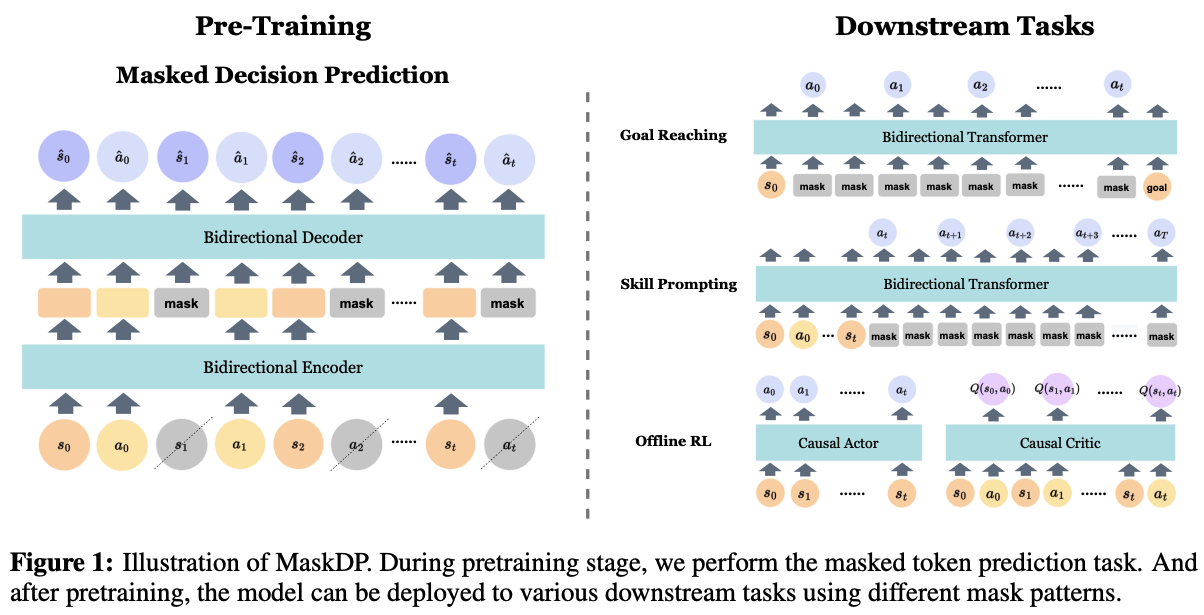
Method
MaskDP Pretraining
- unlike vision and language, where the goal is to learn good representations; we also consider directly deploying this model by leveraging its inpainting capability for various downstream tasks.
- Our encoder is a Transformer [33] but applied only on visible, unmasked states and actions, similar to MAE [12].
- The decoder operates on the full set of encoded visible state and action tokens and mask tokens.
- Each mask token is a shared, learned vector that indicates the presence of a missing token to be predicted.
- Different from other masked prediction variants [12, 9], we found
mask loss is not useful in our setting, as our goal is to obtain an scalable decision making model but not only for representation learning.- 대신, mean squared error (MSE) between the reconstructed whole sequence and original inputs 이 중요하다.
MaskDP Downstream Tasks

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.