그림들
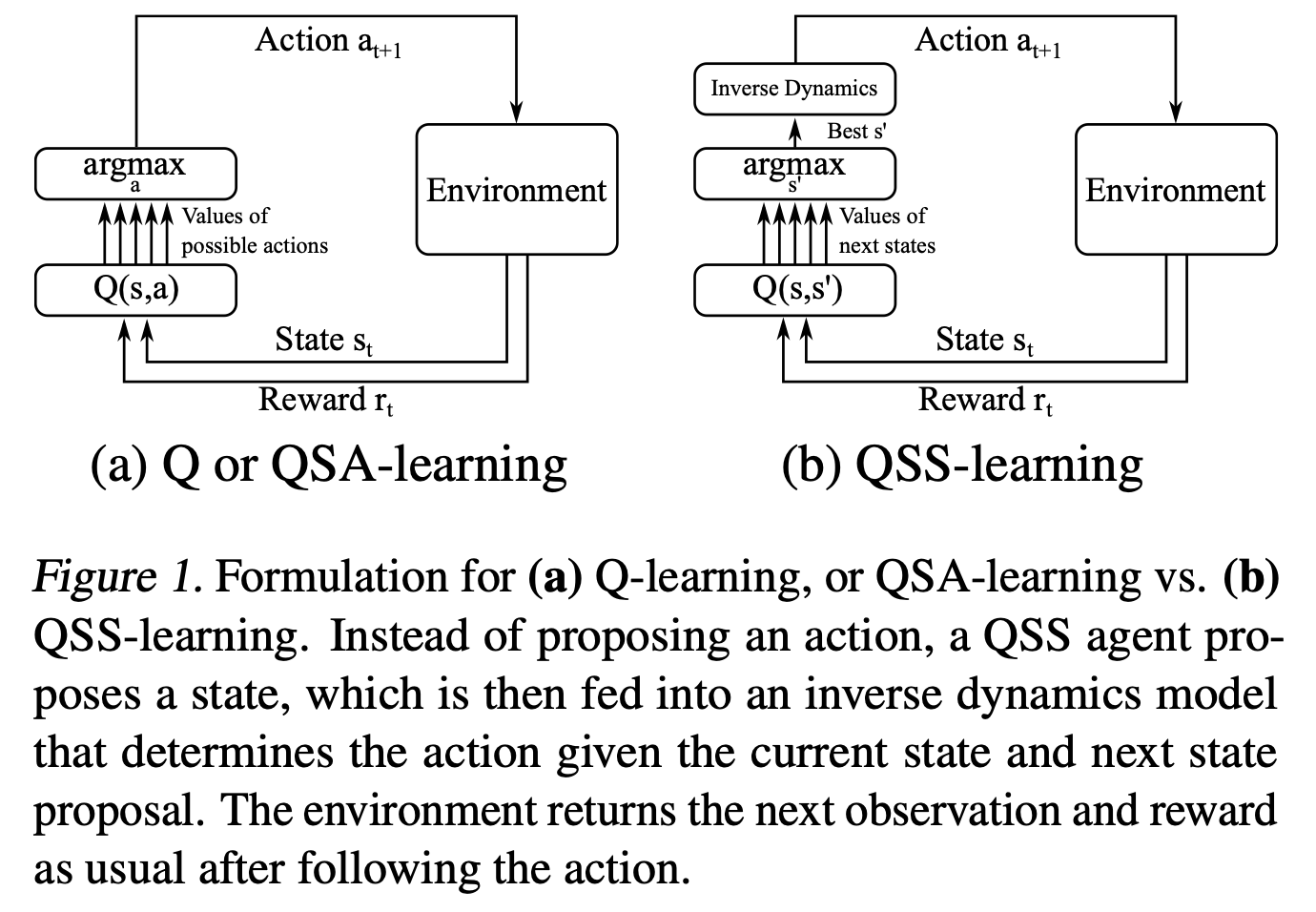
- 기존
- actions 중 Q값이 큰 action을 선택하여 이동
- states 중 Q값이 큰 state를 선택하여 이동(바로 이동할 수 없으니, inverse dynamics를 이용하여 action 도출)
Abstract
- value function Q(s, s′)
- expresses the utility of transitioning from a state s to a neighboring state s′
- and then acting optimally thereafter.
- In order to derive an optimal policy, we develop a
forward dynamics model- that learns to make next-state predictions that maximize this value.
- This formulation decouples actions from values while still learning off-policy.
- We highlight the benefits of this approach in terms of
value function transfer,- learning within redundant action spaces,
- learning off-policy from state observations generated by sub-optimal or completely random policies.
- Code and videos are available at http:// sites.google.com/view/qss-paper.
Conclusion
- To train QSS, we developed Deep Deterministic Dynamics Gradients, which we used to
- train a model to make predictions that maximized QSS.
- We showed that the formulation of QSS learns similar values as QSA,
- naturally learns well in environments with redundant actions, and
- can transfer across shuffled actions.
- We additionally demonstrated that D3G can be used
- to learn complicated control tasks,
- can generate meaningful plans from data obtained from completely random observational data,
- and can train agents to act from such data.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.