이 글의 목적
- Multi-agent RL 분야 중, CTDE(Centralized Training Decentralized Execution)의 기초 논문인 COMA에 대해 소개
논문 기여 3개로 요약
기여 1
decentralized actor + centralized critic구조 제안
기여 2
- MARL이 공통의 reward로 reward 계산이 되다 보니, 특정 agent의 행동이 공통의 reward 향상에 얼마나 도움을 주었는지 산술적으로 계산하지 못했던 문제를 해결.
- joint action 중, target agent의 action이 공동의 reward에 얼마만큼 기여했는지? 를 계산해서 학습에 반영하기 위해, counterfactual baseline 개념 도입.
기여 3
- (discrete action space 문제에서) joint actions 의 차원복잡도를
(U**n -> U)로 줄이기 위한, 독창적 centralized critic 구조 제안.
방법론
기여 1: decentralized actor + centralized critic 구조 제안
- 이 논문의 독창적 기여는 아님.
- 개별 agent마다:
decentralized actor + centralized critic의 shared network & weight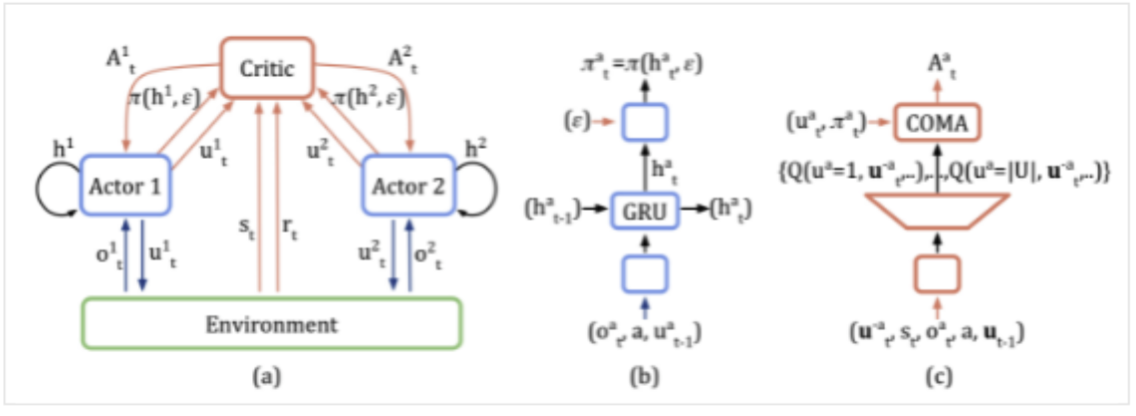
- actor: 개별 actor의 observation 만 사용.
- critic
- 모든 agent의 state 사용.
- output은 개별 agent의 모든 가능한 action 후보군들에 대한 Q(st,at) 을 출력 (discrete action space 기준으로 논문이 설명됨)
- inference 시에는 사용될 필요가 없고, 학습 시 actor을 잘 학습시키기 위한 도구로만 이용됨.
기여 2: shared reward에 대한, credit assignment 문제 해결
- 기존 MARL 문제점
- 공통의 reward로 reward 계산이 되다 보니, 특정 agent의 행동이 공통의 reward 향상에 얼마나 도움을 주었는지 산술적으로 계산하지 못했고 -> 학습이 잘 되지 않았다.
- 해결책
- counterfactual: 사실과 다른 가정 또는 상상의 상황을 나타내는 용어
- joint action 중, target agent의 action이 공동의 reward에 얼마만큼 기여했는지? 를 알기 위해
counterfactual baseline계산.- 다른 agent들의 action은 고정한 채, target agent의 action을 바꿔가며 Q값의 평균(
counterfactual baseline)을 계산 - 이것은 actor loss function의
Q(St,at)대신Q(St,at) - counterfactual baseline로 대체됩니다. - 예: <SAC + COMA에서 actor loss의 변화>

참고사항(중요)- COMA에서는, 주변 agents들의 행동은 현재 Policy에서 가져오지 않고, dataset에서 가져와서 학습한다.
- MAAC에서는, 내 행동 뿐만 아니라, 주변 agents의 행동도 현재 Policy에서 가져온다.
- 다른 agent들의 action은 고정한 채, target agent의 action을 바꿔가며 Q값의 평균(
기여 3: joint-action의 차원 복잡도 해결
- 위 counterfactual baseline 도입으로 인한 새로운 이슈
- 위
counterfactual baseline을 계산하는데, joint actions의 차원 복잡도에 계산량이 과도하게 증가하면 쓸 수 없습니다.
- 위
- 새로운 해결책
- 차원 복잡도를 (U**n -> U) 로 줄이기 위한,
독창적 centralized critic 구조를 제안합니다.개별 agent의 centralized critic에, 개별 agent의 action은 input으로 넣지 않고, 나머지 agent들의 action들만 input으로 넣습니다.- 그리고 위 critic의 output으로, 개별 agent의 모든 action 후보군들에 대해 Q(st, at) 값을 계산합니다.
- 차원 복잡도를 (U**n -> U) 로 줄이기 위한,
Loss function
Actor loss
풋살로 비유!
- 풋살 비디오에서
내 시야 frame(s_t^a),전체 시야 frame(s_t),시간 t에서 나를 제외한 다른 선수들이 한 행동들총 3가지를 가져옵니다. 기존 SAC의 학습 방법- "(내 시야에서) 현재 판단으로 할 수 있는 actions의 확률분포"를 "(내 시야에서) 내가 판단했을 때 각 actions의 가치"와 유사하도록 학습
COMA가 SAC(SARL)와 다른점- "(내 시야에서) 현재 내가 판단했을 때 각 actions의 가치"를 목표 분포로 쓰는 대신,
- "(전체 경기장 시야에서) 다른 선수들이 했었던 행동(at_wo_i)을 알 때, 내가 판단한 행동들의 가치"
- 를 닮고 싶은 목표 action 확률 분포로 설정합니다.
- credit assignment problem 해결
- 다만, 목표 확률 분포를 계산할 때, 다른 선수들이 했었던 행동(at_wo_i)을 판단에 고려해버리면,
- 내 행동 후보군들의 가치가, 내 행동 때문인지, 주변 동료들의 행동 떄문인지 판단하기 어렵습니다.
- 이를 막기 위해 COMA에서는, "내 현재 판단으로 할 수 있는 actions의 확률분포"를 "(전체 경기장 시야에서) 현재 내가 판단했을 때 각 actions의 가치" - "baseline"와 유사하도록 학습합니다.
- 여기서 baseline은, 그 전체 시야 frame에서, (다른 선수들이 한 행동을 고정한 후,),
- "mean( (내가 할 행동 확률) * (내가 생각하는 그 행동의 가치) )" 을 의미
- 다른 의미로, 다른 선수들의 행동으로 인한 가치 기여 정도를 뺴고, 순수 내 행동의 가치 분포와 유사하게 학습하고자 하는 의도입니다.
- 여기서 baseline은, 그 전체 시야 frame에서, (다른 선수들이 한 행동을 고정한 후,),
- 다만, 목표 확률 분포를 계산할 때, 다른 선수들이 했었던 행동(at_wo_i)을 판단에 고려해버리면,
Critic loss
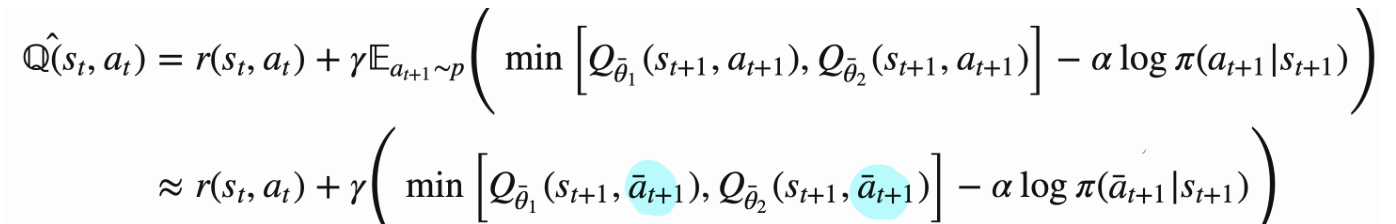
참고사항(중요)- COMA에서는, 주변 agents들의 st_1에서의 행동은 현재 Policy에서 가져오지 않고, dataset에서 가져와서 학습한다.
- MAAC에서는, (st_1에서) 내 행동 뿐만 아니라, 주변 agents의 행동도 현재 Policy에서 가져온다.
풋살로 비유!
- 풋살 비디오에서
"전체 시야 frame(s_t)","t에서 나를 포함한 동료들이 한 행동들","그 때의 보상","다음 전체 시야 frame(s_t+1)","t+1에서 나를 제외한 동료들이 한 행동"을 가져옵니다. "(전체 시야 frame(s_t) + t에서 동료들의 움직임)에서 내가 한 행동의 가치"를, (아래 목표)와 유사하도록 학습합니다.(그때 얻은 보상)+( "다음 전체 시야 frame(s_t+1)" 와 "t+1에서 나를 제외한 동료들이 한 행동" 에서, 내가 현재 판단으로 할 행동의 내가 생각하는 가치)
부록
구조 visualize
SARL 와 차별점
- CriticsInputEncoder 가 있음
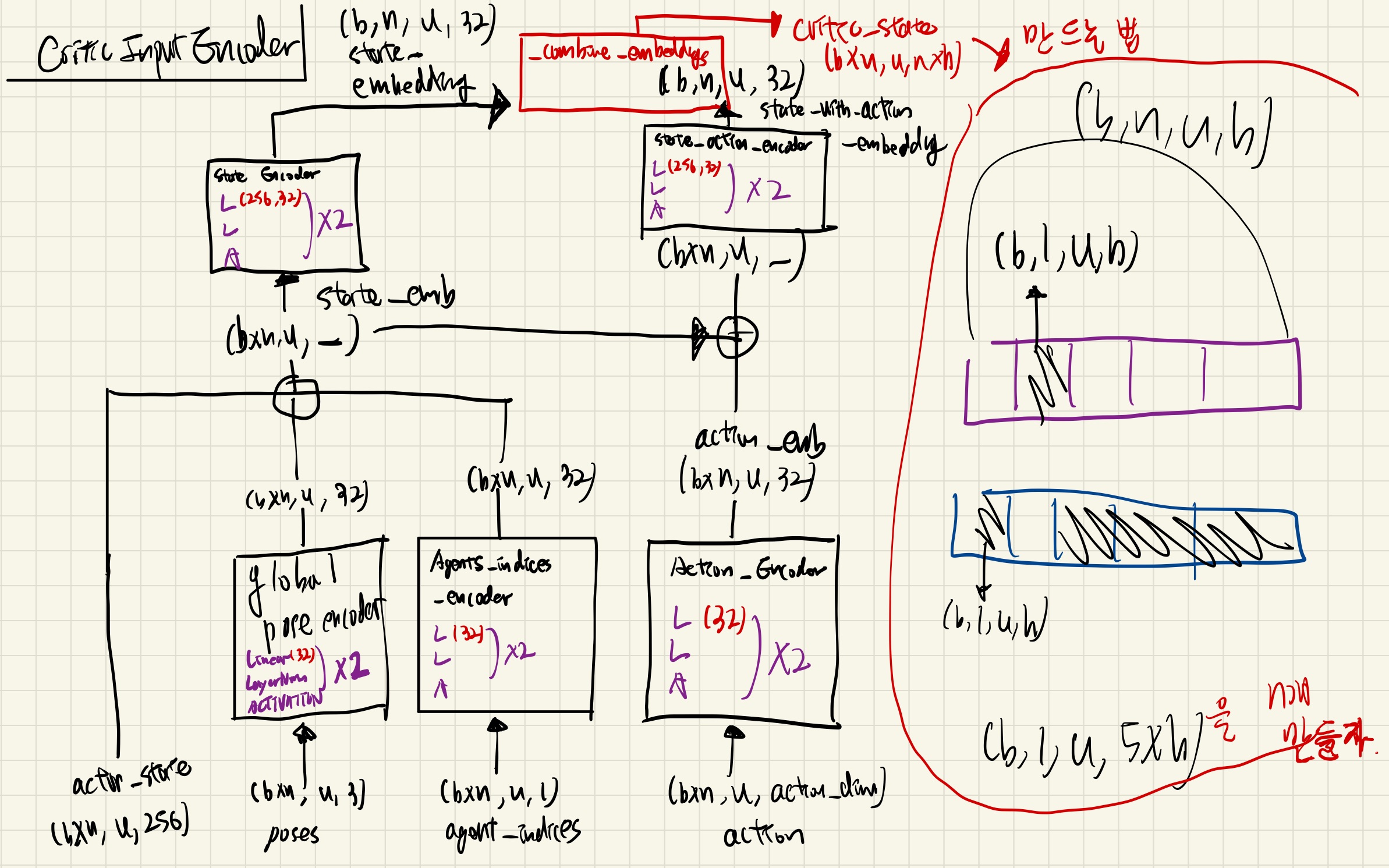
- 위 그림에서
- actor_state
내 agent의 encoding- SARL에서 쓴, encoder의 output (내 정보들의 GRU 임베딩)
- 학습시 actor의 input으로 사용됨.
- action_with_action_embedding
다른 agent의 encoding
- critic_state
- critic의 input으로 사용됨.
- actor_state
- 위 그림에서
성능 향상을 위해 고려해볼 점
- poses가 map 시나리오마다 분포가 천차만별 일텐데, normalize 해서 넣어볼까?
- use_dataset_actions_for_critic 이 True/False 임에 따라 성능이 어떻게 차이는지 확인해보자.
-
_combine_embeddings로직을 바꿔가며 테스트해보자.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.