- http://proceedings.mlr.press/v97/iqbal19a/iqbal19a.pdf
- supplymentary paper: http://proceedings.mlr.press/v97/iqbal19a/iqbal19a-supp.pdf
- github: https://github.com/shariqiqbal2810/MAAC
이 논문 기여 3가지
- centralized critic에 attention 알고리즘을 적용하여, 매 순간 더 집중해야할
agent 정보와 덜 집중해야할agent 정보가 무엇인지 학습합니다.- 복잡한 환경에서 성능 향상이 있고,
- 더 scalable 합니다. (agent수가 많아져도 성능이 좋습니다.)
- 협력적 MARL setting뿐만 아니라, 아래 세팅에서도 다 잘 됩니다. (
다양한 reward setting+다양한 action spaces를 가진 setting)개별화된 reward setting적대적인 settingglobal state를 제공하지 않는 setting
- COMA처럼, credit assignment 문제를 해결한 varinace-reducing baseline 를 제안합니다.
Introduction
- MA 세팅에서, SARL로 학습하면 안되는 이유
- environment가 stationary하고, Markovian하다는 가정이 깨집니다.
- 이유는, 다른 agents들이 학습하면서 policies를 계속 업데이트 하기 때문입니다.
- CTDE는 이를 해결 가능했고, 여러 연구가 진행되었으나 아래와 같은 문제가 존재
- agent수에 scalable하지 않습니다.
- 위에서 언급한 여러 settings에 전부 잘 되는 알고리즘이 아직 없습니다. (주로 cooperative 환경에 집중했습니다.)
- MAAC의 장점
- 중요한 친구에 더 집중하는 능력을 학습합니다.
- agents수가 증가함에 따라, input space가 선형적으로 증가합니다.
- cooperative/competitive/mixed 환경에서 모두 잘됩니다.
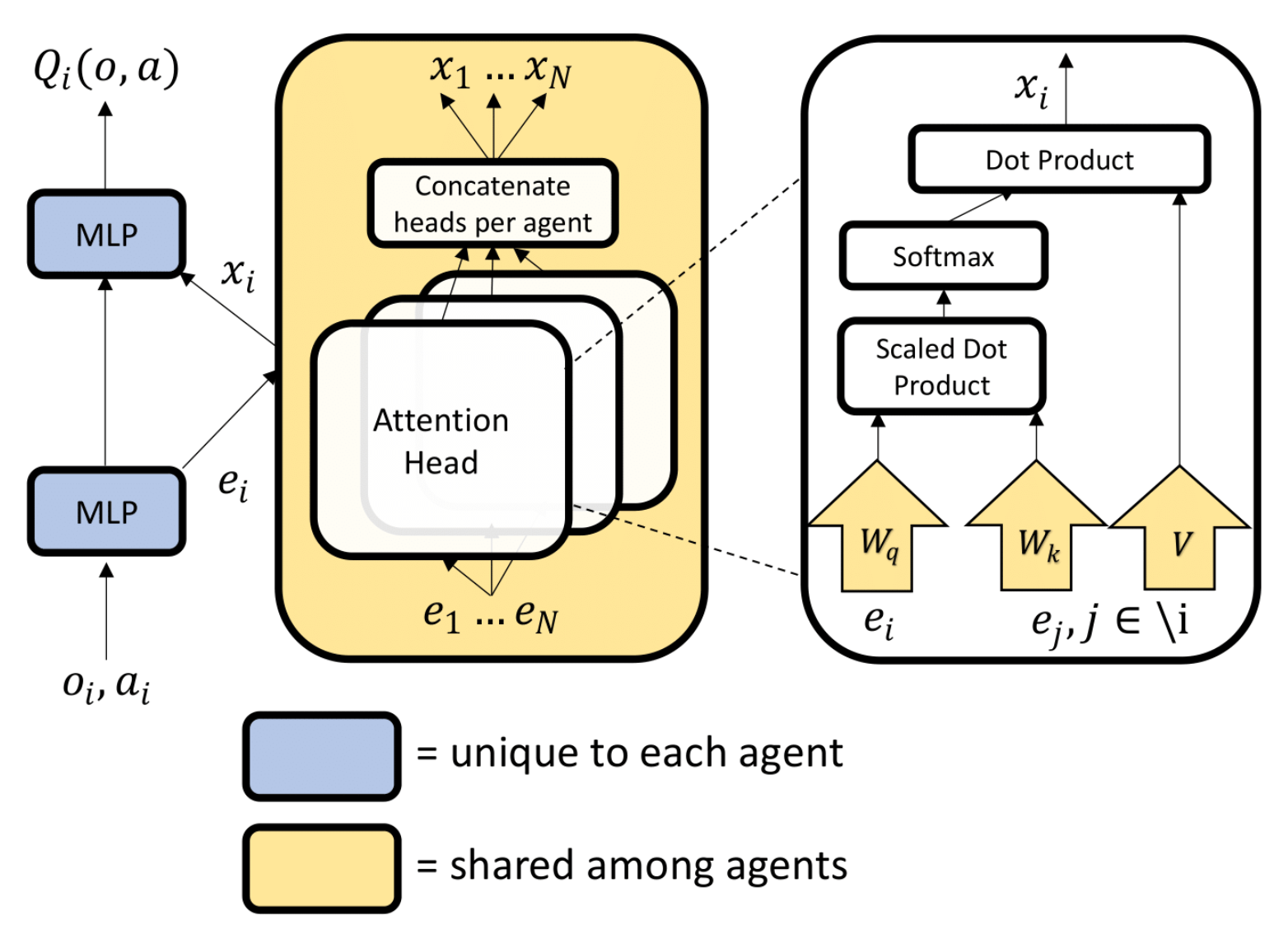
Method
- selectors(query), keys, values 를 계산하기 위한 weight는 모든 agents에 공유
- common embeddding space를 학습하는데 도움이 됩니다.
- 서로 다른 reward를 가진 환경에서도, common feature을 공유하기 때문에, 이 방법이 효과적입니다.
- critic 의 각 agent embedding을 계산할 때, local observation + action 뿐만 아니라, global state의 정보 추가도 가능합니다.
loss function
- COMA와의 비교가 중요하기 때문에, COMA와 비교하면서 진행하였습니다.
- COMA: https://velog.io/@jk01019/COMA-구조
Actor loss
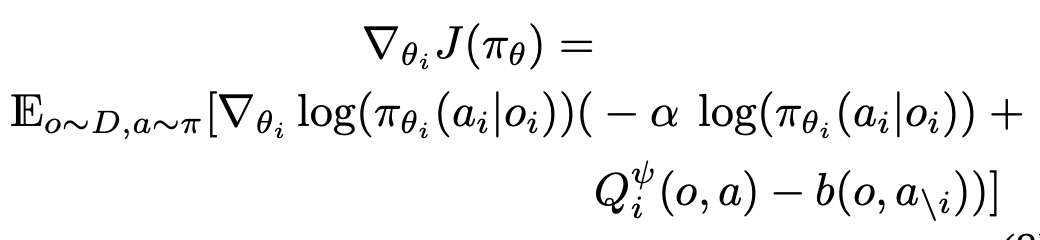
baseline
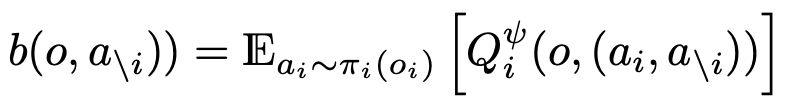
- COMA의 baseline과 개념적으로 같은 컨셉: https://velog.io/@jk01019/COMA-구조
- 다른 action space를 지닌 경우, global reward를 사용하지 않는 경우 등에도 모두 사용 가능
- continuous action space
- baseline을 계산할 때, 아래 2가지 방법 중 하나를 쓴다.
- sampling from agent i's policy
- 동료 agents의 actions만 input으로 받는, 독립된 value head를 학습.
풋살로 비유!
시간 t에서 전체 선수들의 시야 frame(o_1, ..., o_n)과,시간 t 의 전체경기장 시야 frame(o)을 가져옵니다.- COMA와 다른점: COMA는
시간 t에서 나를 제외한 동료 선수들의 행동(a)도 데이터셋에서 가져옵니다.
- COMA와 다른점: COMA는
시간 t에서 내 시야 frame과(o_i)에서 내가 판단한 내 행동들의 확률분포를 아래 확률 목표와 유사하게 만드는 것이 목표입니다.- 확률 분포 목표 구하는 법
시간 t에서 전체 선수들의 시야 frame(o_1, ..., o_n)에서각 선수들이 현재 생각으로 선택할 행동들(a)을 먼저 계산합니다.시간 t 의 전체경기장 시야 frame(o)에서,각 선수들이 현재 생각으로 선택할 행동들(a)을 했을 때의 가치의 확률 분포 - baseline- COMA와 다른점: COMA는
시간 t에서 나를 제외한 동료 선수들의 행동(a)을 dataset에서 가져와서 사용합니다. (실제 내가 돌려본 실험 결과도 이 방법의 성능이 더 좋음)- MAAC에서 이렇게 한 이유는, 과거에 주변 동료들이 한 행동을 기반으로 목표 확률 분포를 정해버리면,
- 선수들이 현재 판단한 행동 분포들을 닮아가기 어렵고
- 실력이 부족했던 과거 상황의 판단에 의존하여, 내 행동의 확률 분포를 학습하기 때문입니다.
- MAAC에서 이렇게 한 이유는, 과거에 주변 동료들이 한 행동을 기반으로 목표 확률 분포를 정해버리면,
- COMA와 다른점: COMA는
- 확률 분포 목표 구하는 법
Critic loss
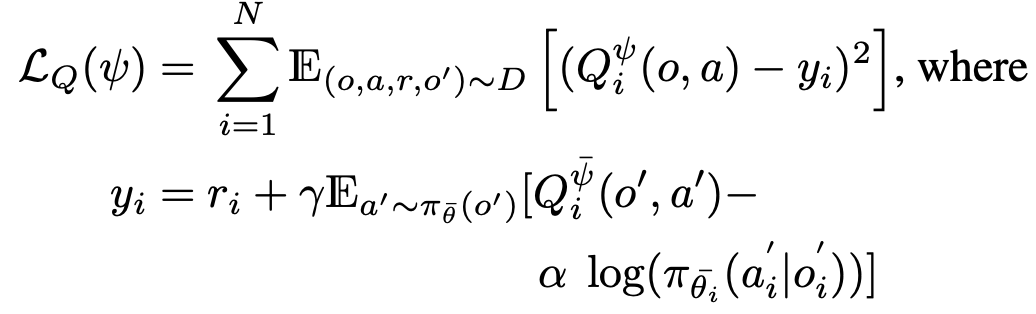
풋살로 비유!
시간 t 의 전체경기장 시야 frame(o)에서 내가 한 행동의 가치를 아래와 같게 만들고 싶다.내가 한 행동 행동으로 얻은 보상+시간 t+1 의 전체경기장 시야 frame(o')에서 나와 선수들의 현재 판단(a')으로 할 행동을 했을 때의 가치- COMA와 다른점: COMA는
t+1에서 나를 제외한 주변 동료들의 행동(a')을 데이터셋에서 가져옵니다. (실제 내가 돌려본 실험 결과도 이 방법의 성능이 더 좋음)- MAAC에서 이렇게 한 이유는, 과거에 주변 동료들이 한 행동을 기반으로 목표 가치를 설정하면,
- 실력이 부족했던 과거 상황의 판단에 의존하여, 내가 한 행동을 잘못 평가해버릴 수 있기 때문입니다.
- COMA way: potentially causing overgeneralization where agents fail to coordinate based on their current policies.
- MAAC에서 이렇게 한 이유는, 과거에 주변 동료들이 한 행동을 기반으로 목표 가치를 설정하면,
학습 순서
target policy network n개각각에(o_i_t+1)을 각각 통과시켜,a'와prob을 구함.-
네트워크 구조
critic (=AttentionCritic)
- COMA와 기본적으로 같음.
agent i의 Oi+나머지 agents들의 Oj, aj를 입력값으로 가짐
critic_encoders (shared!)
- agent 수 만큼
- 매 network마다 각 s_i, a_i를 인풋으로
- sa_encodings를 아웃풋으로.
- state-action encoding for each agent
구조
- enc_bn
nn.BatchNorm1d(sdim + adim)
- enc_fc1
nn.Linear(sdim + adim, hidden_dim)
- enc_nl
nn.LeakyReLU
state_encoders
- agent 수 만큼
- 각 encoder마다 s_i를 입력으로
- 출력은 s_encodings
- state encoding for each agent that we're returning Q for.
구조
- s_enc_bn
nn.BatchNorm1d(sdim)
- s_enc_fc1
nn.Linear(sdim, hidden_dim)
- s_enc_nl
nn.LeakyReLU()
Attention
- head가 각각 4개씩
- 출력은 전부
[ [_, _ , -- n마리], ... num_head... , [_, _ , -- n마리] ]
selector_extractors (shared!)
- s_encodings가 Input (n마리의 s_encoding)
- output 이름:
all_head_selectors
구조
nn.Linear(hidden_dim, attend_dim, bias=False)
key_extractors (shared!)
- sa_encodings가 Input (n마리의 sa_encoding)
- output 이름:
all_head_keys
구조
nn.Linear(hidden_dim, attend_dim, bias=False)
value_extractors (shared!)
- sa_encodings가 Input (n마리의 sa_encoding)
- output 이름:
all_head_values
구조
nn.Linear(hidden_dim, attend_dim)nn.LeakyReLU()
critics
- agent 수 만큼
- input: 내 s_encoding + 동료들의 other_all_value (attention 통과한)
- output: all_q (내 가능한 행동 전부의 q값)
구조
- critic_fc1
nn.Linear(2 * hidden_dim, hidden_dim)
- critic_nl
nn.LeakyReLU()
- critic_fc2
nn.Linear(hidden_dim, adim)
구현 계획
- actor은 그대로
- get_actions_learning 시
- 선택한 1개의 prob만 출력하는 기능도 필요
- critic은
- critic_input_encoder에서
- 아래 내용 구현
- critic_encoders
- state_encoders
- selector_extractors
- key_extractors
- value_extractors
- attention 알고리즘 구현
- input: n마리의 state, n마리의 action
- 아래 내용 구현
- critic에서
- q값 구하도록 구현
- regularize 출력하도록 구현
- attention logit 최소화
- critic_input_encoder에서

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.