What is GLUE Benchmark
- 우리는 앞서 RNN모델을 이용하여, 자연어 문제를 해결하는 방법을 알아봤다. 사실 인공지능을 공부하면서 가장 중요한 부분은 데이터의 유무이다. 아무리 좋은 모델이라고해도, 데이터가 없다면 아무 의미가 없다.
- 이런 데이터를 모두가 사용할 수 있도록, 배포한 것이 GLUE(The General Language Understanding Evaluation)benchmark이다.
- 해당 Benchmark dataset에서는 여러 Task를 할 수 있도록 나뉘어져있다.
1) Single Sequence Tasks는 하나의 sequence로 수행하는 것이다.
- CoLA(The Corpus of Linguistic Acceptability) Dataset(Acceptability Judgment): 이 데이터셋은 해당 문장이 문법적으로 올바른지 판단할 수 있는 dataset이다. 우리가 알아봤던 RNN 중 many to one으로 풀어 볼 수 있다.

- SST-2 Dataset(Sentiment Classification): SST-2는 해당 문장이 긍정적인지, 부정적인지에 대해 판단해 볼 수 있는 데이터 셋이다. 이 task 역시 우리가 앞에서 살펴본 many to one으로 풀어 볼 수 있다.
2) Sequence Pair Task는 두 문단을 이용하여 Taksk를 수행하는 것이다.
- MRPC(Microsoft Research Paraphrase Corpus): 이 데이터셋은 두 문장의 의미적 유사도를 사람이 정한 데이터 셋이다.
- QQP(Quora Question Paraphrases): 이 데이터셋은 네이버 지식인과 같은 곳으로 부터 질문들의 유사도를 측정해 둔 것으로, 동일한 문장인지 아닌지에 대해 binary로 표현되어있다.

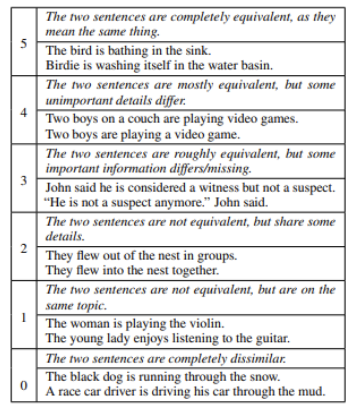
- STS-B(Semantic Textual Similarity Benchmark): 이 데이터셋은 뉴스 헤드라인, 비더오, 이미지 캡션으로 부터 의미적 유사성에 따라 문장의 쌍을 평가할 수 있는 데이터셋이다. 유사도는 5점 척도로 5에 가까울수록 매우 유사한것이다.
- MNLI(Multi Natural Language Inference): 이 데이터셋은 Stanford NLI(SNLI) 데이터셋이 그림에 대한 캡션으로만 이뤄져있다는 것에 한계를 깨기위해 나왔다. 즉 MNLI는 그림에 대한 묘사뿐만아니라, 다양한 분야의 글들이 들어있다. 기존의 SNLI보다 더 어려운 task이다.

- QNLI: 이 데이터셋은 질문과 대답이 pair로 구성되어있다. 이 데이터 셋을 통해 질문에 대한 대답을 학습시킬 수 있다.

- RTE(Recognizing Textual Entailment): 이 데이터셋은 두 문장간의 관계가 포함하고 있냐를 나누는 데이터로 구성되어 있다.
- WNLI(Winograd Natural Language Inference): 이 데이터셋 역시 질문과 답에 대한 pair로 구성되어있는 데이터셋이다.
- 이 GLUE Benmark 데이터셋은 새로운 모델이 개발되었을 때, 해당 모델의 성능을 평가하기 위한 대표적인 데이터셋 중 하나이다.
- 처음 BERT와 같은 모델이 나왔을때도, GLUE Benchmark를 통해 모델 평가를 하였고, 모든 데이터셋에 대해 가장 좋은 성능을 보였다.
