프로젝트 목표
- 반도체 공정 데이터 분석을 통하여 공정 이상을 예측하는 분류 모델 수행
- 공정 이상에 영향을 미치는 요소들에 대한 데이터 분석
프로젝트 목차
-
데이터 읽기 : 반도체 공정(SECOM) 데이터를 불러오고 Dataframe 구조를 확인
-
데이터 정제 : 비어 있는 데이터 또는 쓸모 없는 데이터를 대체
-
데이터 시각화 : 변수 시각화를 통하여 분포 파악
3.1. Pass/Fail 시각화
3.2. 센서 데이터 시각화 하기
3.3. 59번 센서 데이터 시각화 하기 -
데이터 전 처리 : 머신러닝 모델에 필요한 입력값 형식으로 데이터 처리
4.1. x와y로 분리
4.2. 데이터 정규화 -
머신러닝 모델 학습 : 분류 모델을 사용하여 학습 수행
5.1. 기본 분류 모델 학습 - 로지스틱 분류기
5.2. 다양한 분류 모델 학습 -
평가 및 예측 : 학습된 모델을 바탕으로 평가 및 예측 수행
6.1. Confusion Matrix
6.2. Precision & Recall
6.3. 테스트 데이터의 예측값 출력
프로젝트 개요
제조 분야의 디지털 트랜스포메이션이 진행되면서 제조 공정에서 일어나는 수많은 정보가 데이터로 정리되고 있습니다. 제조 공정의 이상을 탐지 분야는 이러한 데이터 바탕으로 구현되는 인공지능 기술로 기존 확률 기반의 예측보다 높은 효율을 내고 있습니다. 이러한 이상 탐지 알고리즘은 불량률을 예측하는 것 뿐만 아니라 어떠한 요소가 불량품을 나오게 하는지 그 원인을 파악하는데 또한 도움을 줄 수 있습니다. 따라서 제조 분야에서의 인공지능을 활용한 이상 탐지는 계속 연구되고 있으며 빠르게 적용되며 그 효율을 보여주고 있습니다.
이번 실습에서는 UCI에서 제공하는 SECOM 공정에서 측정된 센서 데이터를 기반으로 한 데이터를 바탕으로 공정 이상을 예측해보는 분류 모델을 구현합니다. 이를 활용하여 센서 데이터가 주어 졌을 때 공정 이상이 생기는지를 예측할 수 있으며, 공정 이상 시 어떠한 센서들이 중요한 역할을 하는지 알아봅니다.
1. 데이터 읽기
Pandas를 사용하여 uci-secom.csv 데이터를 읽고 dataframe 형태로 저장한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('data/uci-secom.csv')
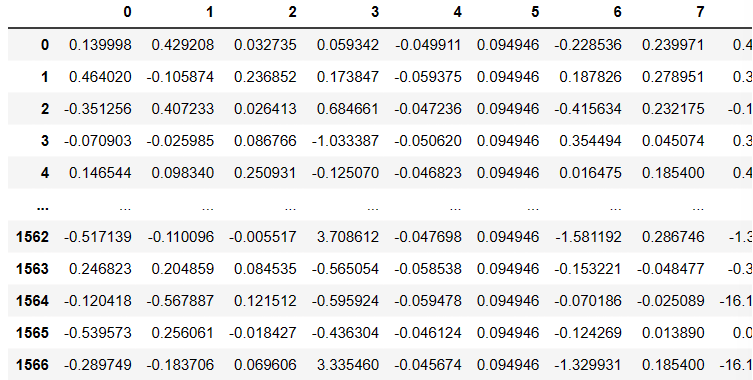
data.head(5)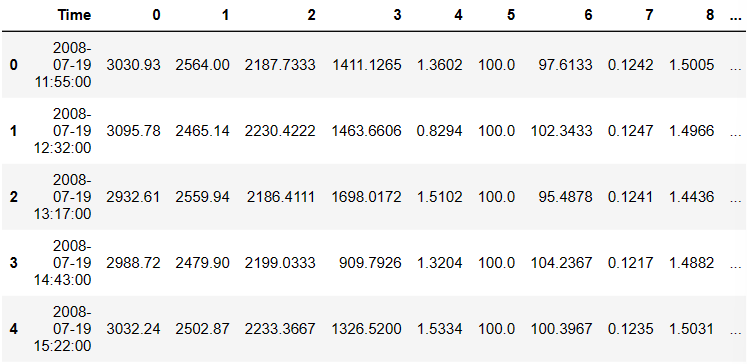
data.info()
data.shape
data.describe()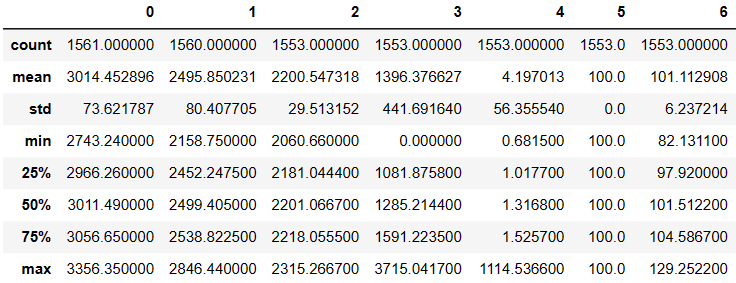
2. 데이터 정제
일반적으로 데이터 정제에서는 결측값(missing value) 또는 이상치(outlier)를 처리합니다.
결측값은 값이 없는 것을 말합니다. NaN, Null이 결측값입니다.
이상치는 일반적인 범주에서 벗어난 값을 말합니다. 평균 연령을 구할 때 200살과 같이 일반적인 범주에 있지 않는 값을 이상치라고 합니다.
머신러닝 모델을 만들 때는 데이터가 중요합니다. 결측값과 이상치는 모델의 성능에 안 좋은 영향을 줄 수 있으므로 처리해서 사용합니다.
이번 데이터에서는 수많은 변수(feature)가 존재하기에 각 데이터를 보며 이상치를 처리하기엔 한계가 있습니다.
따라서 간단하게 결측값에 대해서만 처리를 수행하겠습니다.
아래 코드를 수행하여 각 변수별로 결측값이 몇개가 있는지 확인합니다.
모든 데이터를 사용하기 위해서 결측값을 0으로 대체한다.
data = data.replace(np.NaN, 0)
data = data.drop(columns = ['Time'], axis = 1)replace를 사용하여 결측값을 0으로 바꾸고, 예측하는데 의미가 없는 열을 삭제한다.
3. 데이터 시각화
각 변수 분포를 알아보기 위하여 시각화를 수행한다.
센서에 관련된 590개의 변수들은 시각화하기에 너무 양이 많기에 영향력이 크다고 판단되는 59 센서에 대해서만 시각화를 진핸한다. 59번 데이터는 머신러닝 모델을 사용했을 때, 높은 중요도로 뽑힌 변수이기에 대표로 출력한다.
3.1 Pass/Fail 시각화
data['Pass/Fail'].value_counts().plot(kind='bar')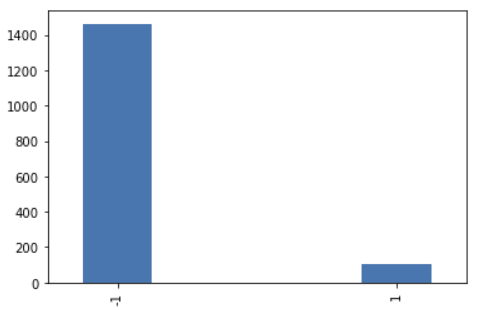
3.2 센서 데이터 시각화
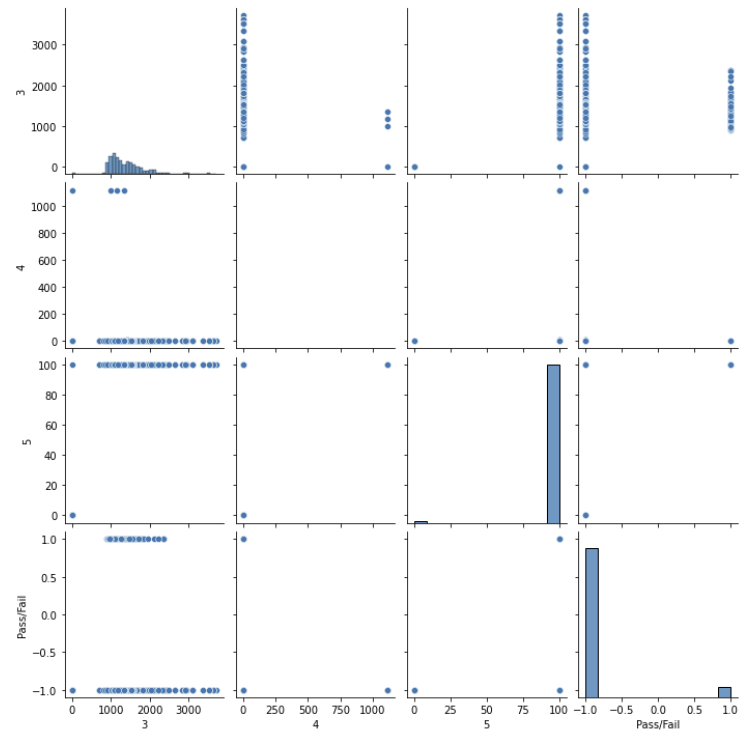
다수의 feature 데이터에 대해 한눈에 볼 수 있도록 seaborn의 pairplot을 활용하여 해결한다.
590개 센서에 대해 pairplot으로 수행하기엔 출력 시간이 오래 걸리기에, 3,4,5, Pass/Fail 데이터에 대해서만 출력한다.
data_test = data[['3','4','5', 'Pass/Fail']]
sns.pairplot(data_test)
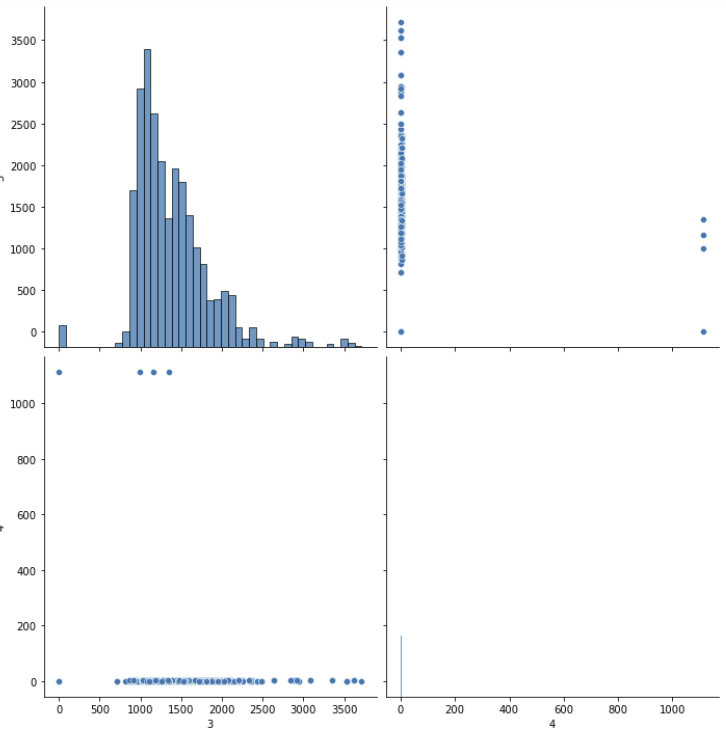
sns.pairplot(data_test,height=5, vars=['3','4'])
#pairplot을 사용해서 컬럼끼리 비교하며, vars에 해당하는 컬럼끼리 비교한다.
3.3 59번 센서 시각화
#59번 센서의 정보를 그래프로 그림.
plt.rcParams['figure.figsize'] = (10, 16)
plt.subplot(3, 1, 1)
sns.distplot(data['59'], color = 'darkblue')
plt.title('59 Sensor Measurements', fontsize = 20)
#Pass/Fail 의 값이 1인 데이터를 출력
plt.subplot(3, 1, 2)
sns.distplot(data[data['Pass/Fail']==1]['59'], color = 'darkgreen')
plt.title('59 Sensor Measurements', fontsize = 20)
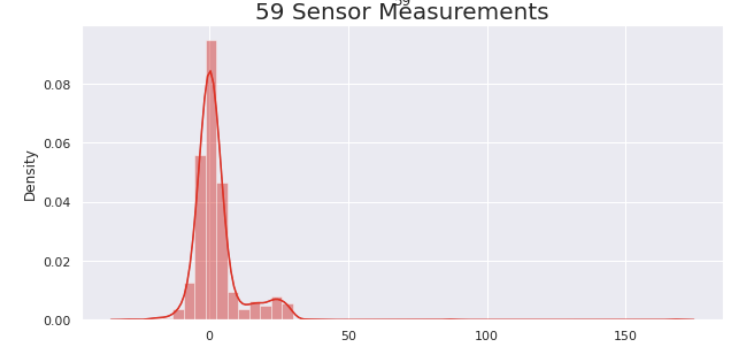
#Pass/Fail 의 값이 -1인 데이터를 출력
plt.subplot(3, 1, 3)
sns.distplot(data[data['Pass/Fail']==-1]['59'], color = 'red')
plt.title('59 Sensor Measurements', fontsize = 20)- 59번 센서의 그프
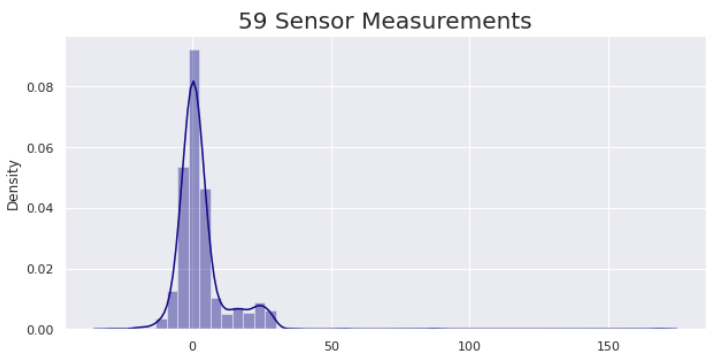
- Pass/Fail의 값이 1인 데이터
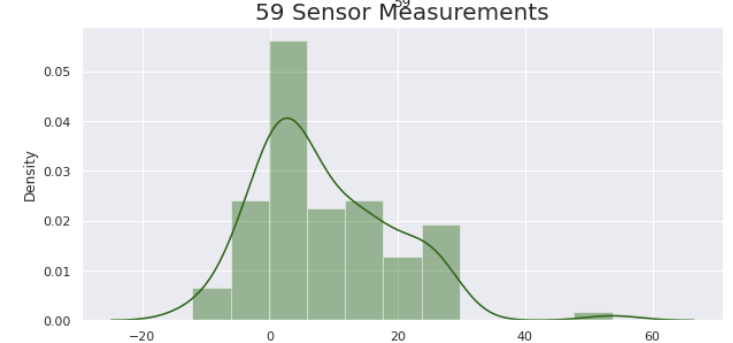
- Pass/Fail의 값이 -1인 데이터
plt.rcParams['figure.figsize'] = (15, 10)
sns.distplot(data['59'], color = 'darkblue')
sns.distplot(data[data['Pass/Fail']==1]['59'], color = 'darkgreen')
sns.distplot(data[data['Pass/Fail']==-1]['59'], color = 'red')
plt.title('59 Sensor Measurements', fontsize = 20)- 나누어 출력했던 그래프를 한번에 출력하여 비교
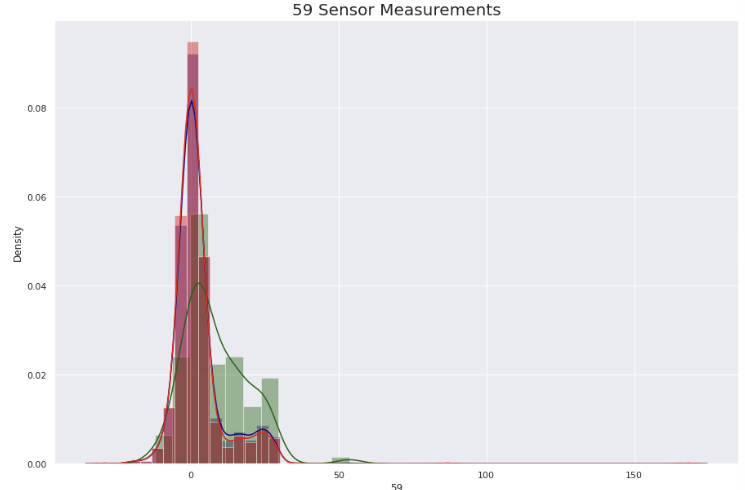
4. 데이터 전처리
공정 이상 예측을 수행하기 위해서 주어진 센서 데이터에 대해서 분류 모델을 사용한다.
분류 모델의 필요한 입력 데이터를 구하기위해 다음과 같은 전 처리를 수행한다.
1. 전체 데이터를 feature 데이터인 x와 label 데이터인 y로 분리하기
2. StandardScaler를 통한 데이터 표준화하기4.1 x와 y로 분리
머신러닝의 feature데이터는 x, label 데이터는 y에 저장한다.
x = data.drop(columns = ['Pass/Fail'], axis = 1)
y = data['Pass/Fail']
y = y.to_numpy().ravel()
#1차원 벡터로 변환한다.590개의 센서 데이터와 Pass/Fail 데이터가 저장되어 있기에 해당 데이터를 x_test, y_test 데이터 분리한다.
4.2 데이터 표준화
각 변수 마다의 스케일 차이를 맞추기 위하여 표준화 수행.
표준화는 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 작업이다.
테이터의 피처 평균이 0이고 분산이 1인 가우시안 정규 분포의 형태를 가지도록 변환한다.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x_train = sc.fit_transform(x)
x_test = sc.transform(x_test)
y_train = y
x_train_sc = pd.DataFrame(data=x_train)