
Django/DRF를 활용하여 어플리케이션을 작성하여 WSGI(Web Server Gate Interface) 서버로 gunicorn을 사용하면서 이슈 해결, 내용 정리를 하려고 합니다. 정리에 앞서 용어 정리를 간단하고 넘어가겠습니다.
Django/DRF 란?
Django - Python의 오픈 소스 웹 풀 스택 프레임워크입니다. 기본적으로 ORM, 어드민 페이지를 제공해주어 사용을 잘 한다면 개발의 속도를 올려줍니다.
DRF - Django 안에서 RESTful API 서버를 쉽게 구축할 수 있도록 도와주는 오픈소스 라이브러리입니다.
WSGI(Web Server Gate Interface) 란?
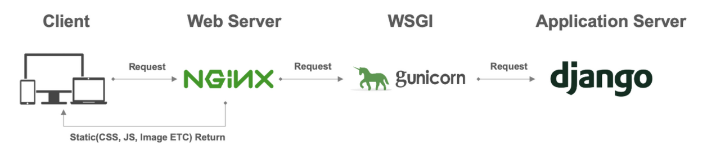
중간의 WebServer인 Nginx, Apache 들은 파이썬 코드를 이해하지 못합니다.
웹서버의 요청을 WSGI가 받아 Django/DRF 로 전달해주는 역할을 하는 인터페이스다.
Gunicorn 사용 이유?
Django에는 runserver를 통해 127.0.0.1:8000 주소로 서버를 열어주는데 이때 python의 http서버로 열기에 https는 예외처리 되어버립니다. 그러므로 보안에 대해서는 많은 예외처리가 있어 보안에 취약하다는 점입니다. django.http 주석에도 Production 단계에서의 사용을 하지 말라고 되어있습니다. 그래서 Gunicorn을 사용하였습니다.
Gunicorn
-
공식 문서 : https://gunicorn.org/
-
command : ["gunicorn", ["options"] "myapp:app"]
아래의 내용들은 사용했던 옵션에 대한 내용입니다.
Logging
log-level
defalut : info
- info을 경우 worker의 실행 및 종료까지 파악할 수 있었지만, 조금 더 상세한 내용을 log기록에서 파악하기 위해 debug를 사용하여 배포하였습니다.
Debugging
reload
defalut : False
- code가 변경될때마다 재시작이 되게 됩니다. 다만 새로운 라이브러리나 설치되었을때 적용되지 않고 재시작은 되어지면 모듈 임포트 에러가 발생합니다. 배포 환경에서는 사용하지 않았습니다.
Security
limit_request_line
defalut : 4094
- HTTP 요청 라인의 최대 크기(바이트)입니다. 최대 8190까지이며 0을 입력하게 되면 무한대로 요청을 보낼수 있는데 이때 DDOS 공격에 취약할 수 있고, Proxy에서 막힐 수 도 있습니다. HTTP 에서 GET 메소드를 사용할때 막히게 되어집니다. 실제로 많은 바이트 값을 요청하다 해당이슈에 대해 알게 되었습니다. 많은 라인을 처리할때 POST로 처리하는 방법도 있습니다. POST는 요청 본문 크기는 HTTP 서버에서 구성되며 일반적으로 1MB에서 2GB 사이입니다. 또는 최대 크기까지 분할하여 여러번 요청하는 방법도 있습니다.
Server Websocket
bind
defalut : ['127.0.0.1:8000']
사용가능한 폼 : HOST, HOST:PORT, unix:PATH, fd://FD
- bind할 소켓을 정의합니다. 여러 주소를 정의할수 있습니다. option에 정의할때 0.0.0.0:8000으로 정의하여 썼습니다. 소켓파일을 생성하여 reverser proxy를 구성할 수 도 있습니다.
Worker Processes
tiemout
defalut : 30
- 요청에 대한 대기 시간을 의미합니다. 0일 경우 timeout을 비활성화 하게 됩니다. 활성화 시 프로세스의 강제종료를 의미하기에 작업중에 발생하는 데이터 유실이 발생하기도 했습니다. 또한 서버를 옮기는 과정에서 AWS의 Load Balancer 사용 함으로써 idle timeout 시간도 고려하게 되었습니다.
workers
defalut : 1
- 공식문서에 2-4 x $(NUM_CORES) 로 제안하고 있습니다. fork하는 worker 수 입니다. 로그에 worker 수에 따라 로그가 남습니다. worker와 thread 개수를 상호조합하여 좀 더 나은 서비스를 제공할 수 있는데 thread를 사용시 오히려 context switcing 때문에 오버헤드가 발생했고, 각자 서버에 맞는 테스트를 통해 좋은 조합을 찾는 것을 권유합니다. sync(동기), gevent(비동기) worker의 종류를 선택 가능합니다.
max-request
defalut : 0
- worker가 정해진 수치만큼 요청을 받으면 재시작 하게 됩니다. 기본 값일 경우 재시작이 비활성화 됩니다. worker 가 재시작하지 않으면 메모리 누수 현상을 확인 할 수 있게 됩니다. 들어오는 requests의 양을 확인하여 적절한 값을 주게 되면 OOM을 피할 수 있게 됩니다.
max-requests-jitter
defalut : 0
- 위의 max-request 와 함께 사용하게 됩니다. 많은 요청으로 인해 모든 worker가 동시에 재시작되는 되어 요청을 받을 수 없는 것을 방지하기 위해 시간차 재시작을 할 수 있게 도와줍니다.
이 외에도 공식 문서의 많은 옵션들을 통해 각자의 서비스에 맞게 사용할 수 있다. 꼭 gunicorn을 사용해야 하는 것은 아니며, ngnix만 통하여 django의 기본적인 구현되어있는 wsgi로 충분히 서비스를 배포할 수 있다. 다만 미들웨어 역할을 하는 내용은 따로 설정을 해주어야한다.
