
데이터프레임에서 기초 데이터를 가공하기 위해선 우선, 내가 원하는 데이터를 선택할 줄 알아야 한다. 특정 columns만 추출할 수도, index만 추출할 수도, 내가 원하는 index와 column을 선택해서 볼 수도 있다. 경우를 나눠서 알아보도록 하자.
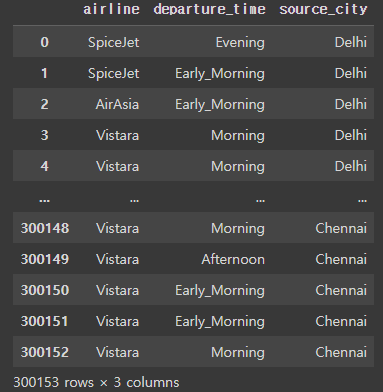
1. 특정 columns 추출하기
특정 columns를 추출하는 방법은 df['column name']의 방법을 사용하는 것이다.
# 특정 column 확인
flight[['departure_time']]
# 여러 개의 column 확인
flight[['airline', 'departure_time', 'source_city']]result:
2. Slicing을 활용하여 특정 index의 값 추출하기
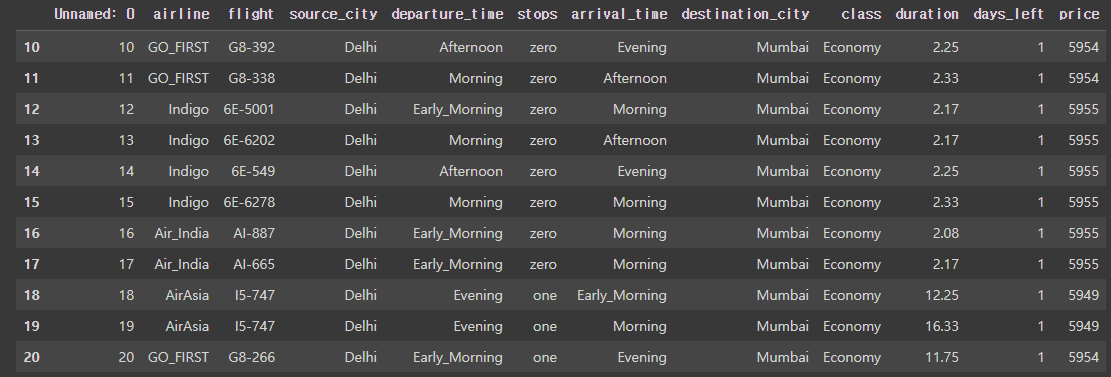
Slicing은 쉽게 범위를 설정한다고 생각하면 된다. [시작:끝]의 형식인데, 실제 범위는 [시작:끝-1]이다. 끝 값은 포함하지 않는다고 생각하면 된다. 예를 들어 df[10:21]이라면 df의 10번째부터 20번째까지의 index를 추출하는 것이다.
# Slicing
flight[10:21] # 10~20번째까지의 데이터 추출result:
3. loc와 iloc를 사용하여 특정 index와 column 추출하기.
데이터프레임의 특정 index와 column의 범위를 지정하여 데이터를 선택하는 방법으로 loc와 iloc가 있다. 이 둘의 차이점을 알아보자.
- loc(location)
- 데이터프레임의 행이나 열에 레이블로 접근
- 인덱스 및 컬럼명을 통해 지정
- 설정한 인덱스 그대로 사용
- iloc(integer location)
- 데이터프레임의 행이나 열에 인덱스 값으로 접근
- 인덱스를 활용해 지정
- 0 based index로 사용
# index 새롭게 지정하기
flight.index = np.arange(100,300253)
flight # index를 100부터 300252으로 새로 지정
# loc 사용
flight.loc[[102,202,302]] # 102, 202, 302번째 값을 추출
# iloc 사용
flight.iloc[[2,102,202]]
# 0 based index로 선택해야함.
# loc를 사용하여 행과 열의 범위 지정하기
flight.loc[[102,202,302], ['airline', 'flight', 'source_city', 'price']]
# loc를 통해 특정 열과 컬럼을 지정하여 추출
# iloc를 사용하여 행과 열의 범위 지정하기
flight.iloc[[2,102,202], [1,2,3,11]]
# index는 0 based index, column은 dataframe에서의 순서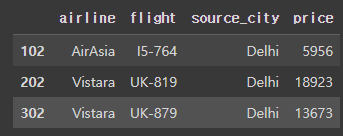
loc와 iloc를 사용할 때 df[index, column]의 순서로 이해하면 쉽게 사용할 수 있다.
4. 조건으로 데이터 선택(Boolean)
Boolean 연산을 통해 원하는 조건의 데이터만 선택하는 방법도 있다.
# condition : price가 12000 초과이고, airline이 Air_India인 항목만 추출
flight_extract = flight[(flight['price']>12000) & (flight['airline'] == 'Air_India')]
flight_extract.head()
# 조건을 각각 변수에 따로 저장 -> 수정이 용이함.
# condition 1 : price가 12000 초과
# condition 2 : airline이 air_india
# first condition
price_tag = flight['price'] > 12000
# second condition
airline_tag = flight['airline'] == 'Air_India'
flight_extract2 = flight[price_tag & airline_tag].head()
flight_extract2result:


혼자 공부하는 데이터분석