
대표적으로 파이썬에서 사용하는 데이터분석 라이브러리는 Numpy와 Pandas가 있습니다.
Numpy는 주로 수치형 데이터를 다룰 때 사용하는 라이브러리
Pandas는 데이터 분석을 할 때 n차원 행렬 자료 구조인 ndarray구조를 사용하여 배열이나 행렬 계산 등을 간편하고 빠르게 수행합니다.
- numpy reference:
https://numpy.org/doc/stable/reference/index.html
- pandas reference:
https://pandas.pydata.org/pandas-docs/stable/
1. Numpy 사용법
numpy를 활용하기 위해선 numpy 라이브러리를 불러와야합니다.
import numpy as np
# numpy data setting
a = np.array([1,2,3,4,5])
b = np.array(['대한민국', '포르투갈', '가나', '우루과이'])
c = np.array([1,2,'대한민국', '포르투갈'])
# print
print(a)
print(b)
print(c)
# numpy는 결과가 List 형태로 출력됨.
# numpy는 n차원 행렬 자료 구조인 ndarray를 사용함.- 실행결과

실행 결과가 list형태로 출력되는 것을 확인할 수 있습니다. 이처럼 Numpy에서 사용하는 ndarray구조는 list와 비슷한 형태입니다.
2. Pandas 사용법
pandas에서 사용하는 자료구조는 Series와 DataFrame이 있습니다. Series는 1차형 자료구조이고, DataFrame은 2차형 자료구조인데, DataFrame은 여러 개의 Series가 합쳐진 형태입니다.
import pandas as pd
# Series 생성
s = pd.Series(['대한민국', '포르투갈', '가나', '우루과이'],
index = ['가', '나', '다', '라'], name = "2022 카타르월드컵 H조")
# print
print(s)- 실행결과

3. 외부에서 데이터 불러오기
다음으로 DataFrame을 생성해보겠습니다. 크게 두 가지 방식으로 생성할 수 있는데 Dictionary 형태와 List 형태로 DataFrame을 생성할 수 있습니다.
# Dictionary로 Dataframe 생성
a1 = pd.DataFrame({"a":[1,2,3,], "b" : [4,5,6], "c" : [7,8,9]})
a1
# key : value의 형태
# List로 Dataframe 생성
a2 = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], ["a", "b", "c"])
a2데이터 분석 라이브러리인 numpy와 pandas의 기초적인 사용법을 배웠으니, 다음으로 데이터를 불러오는 방법을 알아보도록 하겠습니다. 데이터 분석을 할 때는 주로 csv 파일을 불러옵니다. csv파일을 불러올 때는 pandas 라이브러리의 read_csv 함수를 사용합니다. read_csv 함수는 아래와 같습니다.
변수 = pd.read_csv(filepath, encoding, ...)
이제 Kaggle의 'Flight Price Prediction' 데이터를 불러오도록 하겠습니다.
데이터 출처: https://www.kaggle.com/datasets/shubhambathwal/flight-price-prediction?resource=download
import numpy as np
import pandas as pd
# read_csv를 사용하여 데이터 불러오기
flight = pd.read_csv("/content/drive/MyDrive/AICE/data/archive/Clean_Dataset.csv", encoding="cp949")
flight
# cp949 vs utf-8
# cp949(확장완성형) -> microsoft
# utf-8(유니코드) -> mac이때 불러올 데이터의 경로를 알아야한다. 필자는 Google Colab 환경에서 데이터를 불러왔는데,
드라이브 마운트를 사용하여 클라우드 환경에서 데이터를 불러왔다. 드라이브 마운트를 사용하지 않으면 자신의 구글 드라이브를 불러올 수 없기 때문에 꼭 해줘야 한다!
4. 데이터 저장하기
데이터 분석을 하다 보면 원래의 데이터를 수정해야 하는 경우가 생긴다. 데이터 가공 후에 데이터를 저장하는 방법은 pandas의 'to_csv'함수를 사용하는 것이다.
a2 = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], ["a", "b", "c"])
a2
# to_csv를 활용하여 저장하기
a2.to_csv('./result_a2.csv')
#result_a2.csv 불러오기
result = pd.read_csv("./result_a2.csv")
result
# read_csv 함수의 파라미터를 활용하여 원하는 컬럼만 가지고 데이터프레임 만들기
flight2 = pd.read_csv("/content/drive/MyDrive/AICE/data/archive/Clean_Dataset.csv", index_col = 'stops',
usecols=['stops', 'departure_time', 'arrival_time', 'destination_city'])
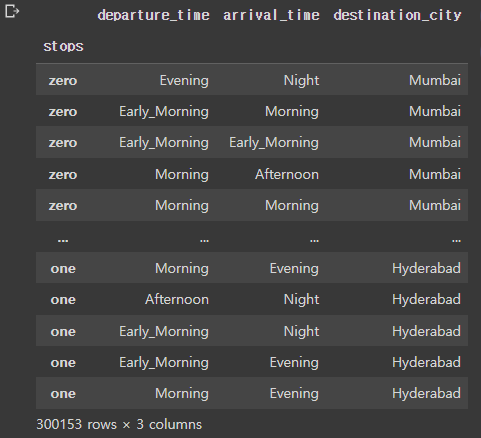
flight2index_col -> 인덱스로 사용할 column 정하기
usecols -> 실제로 데이터프레임에 불러올 column들만 정의
usecols는 반드시 index_col로 설정한 column name을 포함해야한다.
- 실행결과
pandas의 crosstab 함수는 범주형 데이터 2개를 비교분석 할 때 사용한다.
# crosstab 확인
pd.crosstab(index = flight.source_city, columns = flight.arrival_time)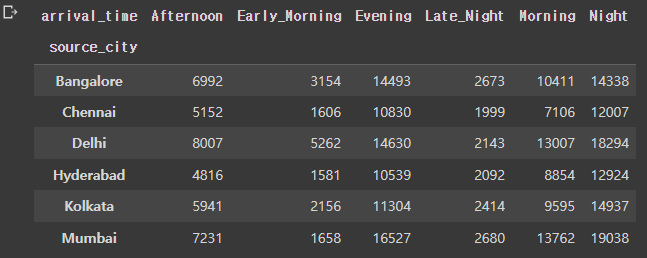
6. DataFrame 확인
우선 데이터의 기본적인 형태를 확인해야한다.
# 필요한 라이브러리 불러오기
import numpy as np
import pandas as pd
# read_csv를 사용하여 데이터 불러오기
flight = pd.read_csv("/content/drive/MyDrive/AICE/data/archive/Clean_Dataset.csv", encoding="cp949")
flight데이터의 양이 많은 경우에는 head와 tail을 확인하여 데이터의 일부만 확인한다.
# head 확인 -> 상위 5개
flight.head()
# tail 확인 -> 하위 5개
flight.tail()
# head로 상위 10개의 데이터 확인
flight.head(n=10)
# tail로 하위 3개의 데이터 확인
flight.tail(n=3)head와 tail은 값을 따로 지정하지 않으면 5개의 값을 보여준다.
데이터의 기본적인 형태를 파악했으면 데이터의 특성을 파악해봐야한다. DataFrame의 크기, column name, 데이터 유형, 각 column의 데이터 수, 요약 통계량 등을 볼 수 있다.
# shape
flight.shape
# columns name
flight.columns
# info
flight.info()
# describe
flight.describe()
# dtypes
flight.dtypes
# value_counts
flight.value_counts()
안녕하세요! 같은 학교 출신을 만나게 돼서 무척 반갑습니다 올려주신 글들을 보며 독학으로 데이터 분석의 높은 경지까지 오르신 것 같아요! 저는 기획 직무를 담당하고 있는 직장인인데 Python을 통한 데이터분석에 많은 관심이 있습니다!
저 같은 경우는 데이터 분석에 있는 지식이라곤 ADsP 자격증 정도입니다.. 혹시 데이터에 대한 지식이 없는 상태 어떻게 Python 공부를 시작하면 효과적일지 알려주실 수 있는지해서 댓글 남겨보았습니다
추천 강의나 유튜브 독학하면서 공부하신 노하우가 있다면 알려주실 수 있을까요?!