[Python] 데이터 스케일링 4가지 방법
0
머신러닝을 할 때, 특성별로 데이터의 단위가 다르다면 어떻게 될까요?
변수 X1, X2, y가 존재한다고 가정합시다.
- 변수 X1은 -1부터 1까지의 범위를 가집니다.
- 변수 X2는 0부터 1000까지의 범위를 가집니다.
- 변수 y는 -1000부터 1000까지의 범위를 가집니다.
이런 경우에는, 변수 X1, X2가 y를 예측하는데 큰 영향을 주지 않는다고 생각할 수 있습니다. 또한, overflow, underflow, 발산, 수렴과 같은 문제도 발생할 수 있기에, 데이터 전처리 과정에서 데이터의 단위를 맞춰주는 데이터 스케일링 과정이 꼭 필요합니다. 데이터 스케일링을 하는 방법은 크게 4가지로 나뉩니다.
- Standard Scaler
- MinMax Scaler
- Robust Scaler
- MinAbs Sclaer
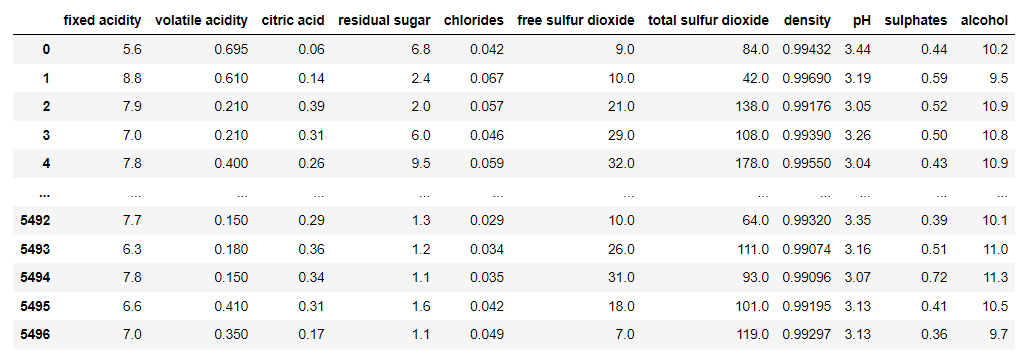
스케일링을 진행하기 전 데이터 (ordinary data)
1. Standard Scaler
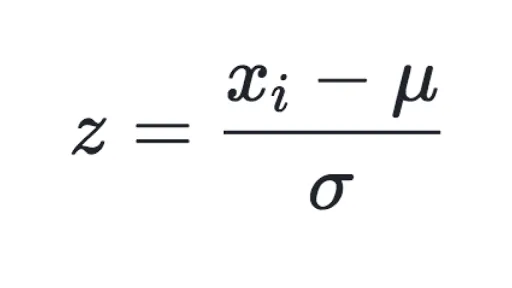
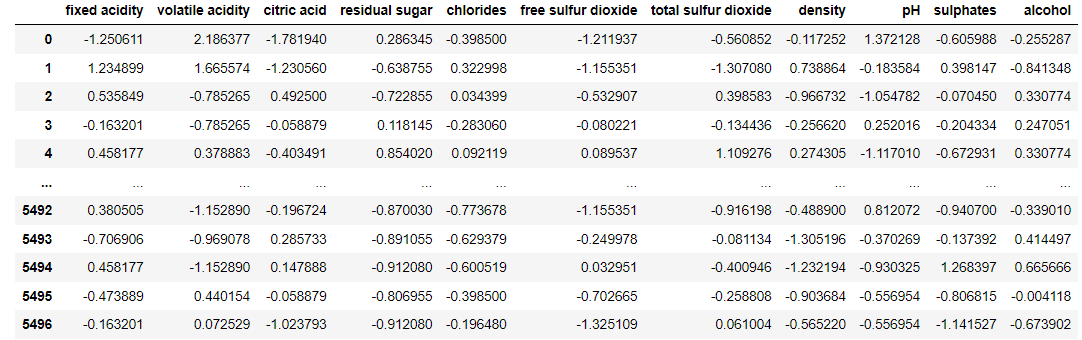
Standard Scaler는 특성들의 평균을 0, 분산을 1로 스케일링합니다.
-> 특성들을 정규분포로 변환!
- 특성의 최대값, 최소값을 제한하지 않습니다.
- 이상치가 존재한다면, 평균과 표준편차에 영향을 끼치므로 데이터의 확산이 달라지게 됩니다.
- 이상치에 민감합니다.
- 회귀보단 분류에 적합합니다.
from sklearn.preprocessing import StandardScaler
col_names = df.iloc[:, 1:-1].columns
scaler = StandardScaler()
df_standard = scaler.fit_transform(df.iloc[:, 1:-1])
standard = pd.DataFrame(df_standard, columns = col_names)
standardStandard Scaler result
2. MinMax Scaler
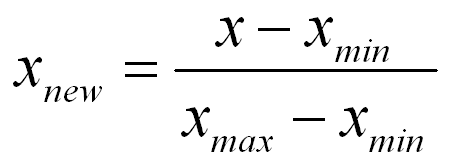
MinMax Scaler는 데이터의 범위를 0과 1사이로 스케일링합니다.
- 이상치가 있는 경우 변환된 값이 매우 작은 범위로 압축될 수 있습니다.
- 이상치에 민감합니다.
- 각 변수가 정규 분포가 아니거나, 표준편차가 작을 때 효과적입니다.
- 분류보다 회귀에 적합합니다.
from sklearn.preprocessing import MinMaxScaler
col_names = df.iloc[:,1:-1].columns
scaler = MinMaxScaler()
df_minmax = scaler.fit_transform(df.iloc[:,1:-1])
minmax = pd.DataFrame(df_minmax, columns = col_names)
minmaxMinMax Scaler result
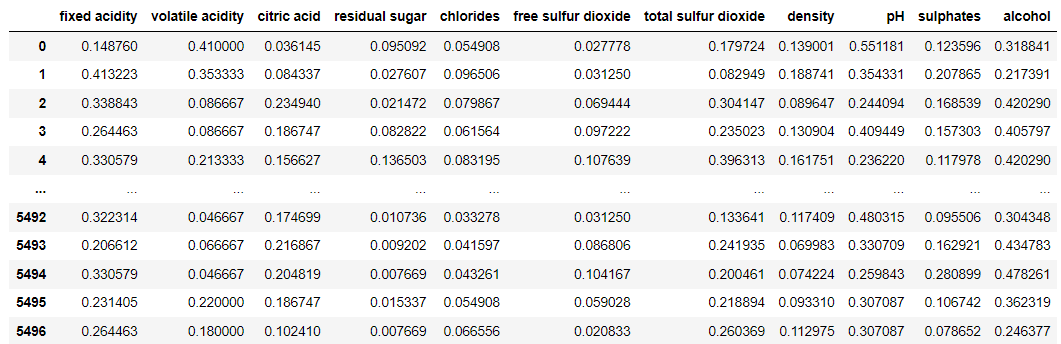
3. Robust Scaler
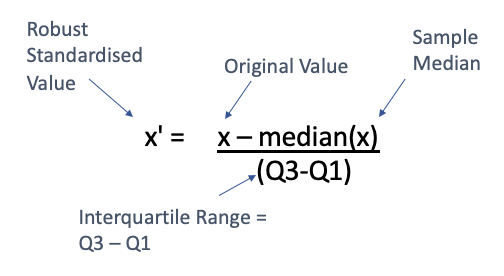
Robust Scaler는 각 feature의 median(Q2)에 해당하는 데이터를 0으로 잡고,
Q1, Q3 사분위수와의 IQR 차이 만큼을 기준으로 정규화를 진행합니다.
- Standard Scaler와 유사하지만, 평균 대신 Median을 사용하고 표준편차 대신 사분위값을 사용한다는 차이점이 있습니다.
- 이상치에 매우 강합니다.
from sklearn.preprocessing import RobustScaler
col_names = df.iloc[:,1:-1].columns
scaler = RobustScaler()
df_robust = scaler.fit_transform(df.iloc[:,1:-1])
robust = pd.DataFrame(df_robust, columns = col_names)
robustRobust Scaler Result
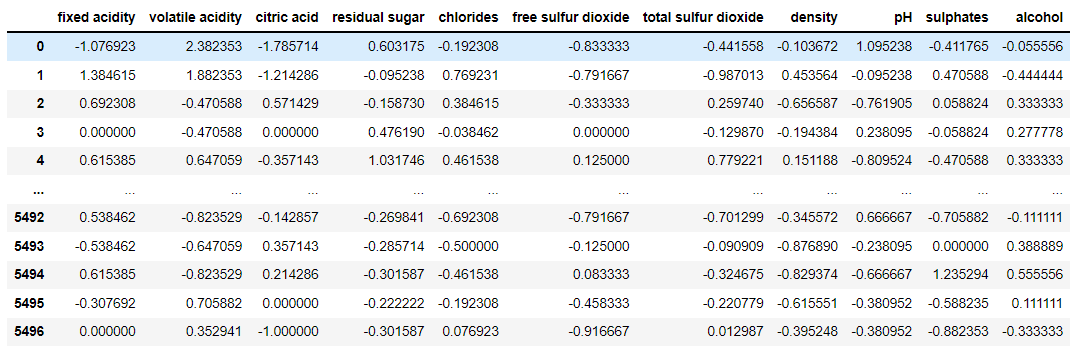
4. MaxAbs Scaler
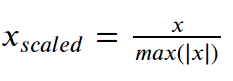
- 각 특성의 절댓값이 0과 1사이가 되도록 스케일링합니다.
- 모든 값은 -1과 1사이가 되며, 모든 데이터가 양수일 경우에는 MinMax Scaler와 같은 결과값이 됩니다.
- 이상치에 매우 민감합니다.
from sklearn.preprocessing import MaxAbsScaler
col_names = df.iloc[:,1:-1].columns
scaler = MaxAbsScaler()
df_maxabs = scaler.fit_transform(df.iloc[:,1:-1])
maxabs = pd.DataFrame(df_maxabs, columns = col_names)
maxabsMaxAbs Scaler Result

혼자 공부하는 데이터분석