
📌 주제
📖 순서
1. 주제 정의
2. 필요성 및 목적
3. 활용 데이터 및 변수
4. 자료 분석 과정
1. 주제 정의
- 주제: 제주도 도로 교통량 예측 AI 모델 개발
- 요약: 제주도의 교통 정보를 이용하여 도로 교통량을 예측하는 모델 개발
2. 필요성 및 목적
(1) 현황 파악
- 제주도 내 주민등록인구는 2022년 기준 약 68만 명으로, 연평균 1.3% 정도 매년 증가하고 있음
- 또한 외국인과 관광객까지 고려하면 전체 상주인구는 90만 명을 넘을 것으로 추정되며, 제주도민 증가와 외국인의 증가로 현재 제주도의 교통체증이 심각한 문제로 떠오르고 있음
(2) 분석 목적
- 탐색적 데이터 분석을 통해 제주도의 도로 교통량에 영향을 미치는 요인을 알아보고, 다양한 머신러닝 기법을 활용하여 도로 교통량을 예측하는 최적의 AI 모델을 개발하고자 함
3. 활용 데이터 및 변수
(1) 활용 데이터
- train 데이터(.csv)
-2022년 8월 이전 데이터만 존재 (단, 날짜가 모두 연속적이지 않음)
-4,701,217개의 데이터
-id: 샘플별 고유 id
-target: 도로의 차량 평균 속도(km)
- test 데이터(.csv)
-2022년 8월 데이터만 존재 (단, 날짜가 모두 연속적이지 않음)
-291,241개의 데이터
(2) 활용 데이터 출처
(3) 활용 변수
| 변수명 | 변수 설명 |
|---|---|
| id | 아이디 |
| base_date | 날짜 |
| day_of_week | 요일 |
| base_hour | 시간대 |
| road_in_use | 도로사용여부 |
| lane_count | 차로수 |
| road_rating | 도로등급 |
| multi_linked | 중용구간 여부 |
| connect_code | 연결로 코드 |
| maximum_speed_limit | 최고속도제한 |
| weight_restricted | 통과제한하중 |
| height_restricted | 통과제한높이 |
| road_type | 도로유형 |
| start_latitude | 시작지점의 위도 |
| start_longitude | 시작지점의 경도 |
| start_turn_restricted | 시작 지점의 회전제한 유무 |
| end_latitude | 도착지점의 위도 |
| end_longitude | 도착지점의 경도 |
| end_turn_restricted | 도작지점의 회전제한 유무 |
| road_name | 도로명 |
| start_node_name | 시작지점명 |
| end_node_name | 도착지점명 |
| vehicle_restricted | 통과제한차량 |
| target | 평균속도(km) |
--
4. 자료 분석 과정
(1) 기본 세팅
⚡ 필요한 라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
color = sns.color_palette()
sns.set_style('darkgrid')
# 그래프 해상도 업그레이드
%config InlineBackend.figure_format = 'retina'# 코드 연산 속도 측정
from tqdm.auto import tqdm
# 경고문 무시
import warnings
warnings.filterwarnings('ignore')(2) 데이터 살펴보기
⚡ 데이터 불러오기
x_train = pd.read_csv('C:/Users/User/Desktop/dacon/제주도_도로_교통량_예측/train.csv')
x_test = pd.read_csv('C:/Users/User/Desktop/dacon/제주도_도로_교통량_예측/test.csv')⚡ 데이터 확인하기
x_train.head()
x_test.head()## 행/열 확인
print(x_train.shape)
print(x_test.shape)(4701217, 23)
(291241, 22)⚡ 데이터 요약정보 확인하기
# object형: 'day_of_week', 'road_name', 'start_node_name', 'start_turn_restricted', 'end_node_name', end_turn_restricted
print(x_train.info())
print(x_test.info())<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4701217 entries, 0 to 4701216
Data columns (total 23 columns):
# Column Dtype
--- ------ -----
0 id object
1 base_date int64
2 day_of_week object
3 base_hour int64
4 lane_count int64
5 road_rating int64
6 road_name object
7 multi_linked int64
8 connect_code int64
9 maximum_speed_limit float64
10 vehicle_restricted float64
11 weight_restricted float64
12 height_restricted float64
13 road_type int64
14 start_node_name object
15 start_latitude float64
16 start_longitude float64
17 start_turn_restricted object
18 end_node_name object
19 end_latitude float64
20 end_longitude float64
21 end_turn_restricted object
22 target float64
dtypes: float64(9), int64(7), object(7)
memory usage: 825.0+ MB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 291241 entries, 0 to 291240
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 291241 non-null object
1 base_date 291241 non-null int64
2 day_of_week 291241 non-null object
3 base_hour 291241 non-null int64
4 lane_count 291241 non-null int64
5 road_rating 291241 non-null int64
6 road_name 291241 non-null object
7 multi_linked 291241 non-null int64
8 connect_code 291241 non-null int64
9 maximum_speed_limit 291241 non-null float64
10 vehicle_restricted 291241 non-null float64
11 weight_restricted 291241 non-null float64
12 height_restricted 291241 non-null float64
13 road_type 291241 non-null int64
14 start_node_name 291241 non-null object
15 start_latitude 291241 non-null float64
16 start_longitude 291241 non-null float64
17 start_turn_restricted 291241 non-null object
18 end_node_name 291241 non-null object
19 end_latitude 291241 non-null float64
20 end_longitude 291241 non-null float64
21 end_turn_restricted 291241 non-null object
dtypes: float64(8), int64(7), object(7)
memory usage: 48.9+ MB
None⚡ 결측치 존재 여부 확인하기
## 결측치 존재 여부 확인 -> 없음
print(x_train.isnull().sum())
print(x_test.isnull().sum())⚡ 기초통계량 확인하기
x_train.describe().T⚡ object형 변수의 정보 확인하기
x_train.describe(include='object')(3) EDA
⚡ 데이터 타입 변경하기
- 대부분의 값이 int64, float64로 되어 있음
- 데이터프레임의 용량이 크므로, int64인 컬럼의 데이터 타입을 int32로 변경함
- 'maximum_speed_limit', 'vehicle_restricted', 'weight_restricted', 'height_restricted', 'target' 컬럼: float32로 변경
- 'start_latitude', 'start_longitude', 'end_latitude', 'end_longitude' 컬럼: float32로 변형할 경우 일부 정보 소실되므로, 그대로 둠
## 데이터 타입 변경
to_int32 = ["base_date", "base_hour", "lane_count", "road_rating", "multi_linked", "connect_code", "road_type"]
to_float32 = ["vehicle_restricted", "height_restricted", "maximum_speed_limit", "weight_restricted", "target"]
for i in to_int32:
x_train[i] = x_train[i].astype("int32")
for j in to_float32:
x_train[j] = x_train[j].astype("float32")
print(x_train.info())<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4701217 entries, 0 to 4701216
Data columns (total 23 columns):
# Column Dtype
--- ------ -----
0 id object
1 base_date int32
2 day_of_week object
3 base_hour int32
4 lane_count int32
5 road_rating int32
6 road_name object
7 multi_linked int32
8 connect_code int32
9 maximum_speed_limit float32
10 vehicle_restricted float32
11 weight_restricted float32
12 height_restricted float32
13 road_type int32
14 start_node_name object
15 start_latitude float64
16 start_longitude float64
17 start_turn_restricted object
18 end_node_name object
19 end_latitude float64
20 end_longitude float64
21 end_turn_restricted object
22 target float32
dtypes: float32(5), float64(4), int32(7), object(7)
memory usage: 609.7+ MB
None⚡ 변수 살펴보기
✏️ 한 가지 값만 존재하는 변수 찾기
one_value_columns = []
for i in x_train.columns[2:]:
if len(x_train[i].value_counts()) < 2:
one_value_columns.append(i)
print(len(one_value_columns))
print(one_value_columns)2
['vehicle_restricted', 'height_restricted']## 값 확인
print(x_train['vehicle_restricted'].value_counts())
print(x_train['height_restricted'].value_counts())0.0 4701217
Name: vehicle_restricted, dtype: int64
0.0 4701217
Name: height_restricted, dtype: int64## 해당 컬럼 제거
x_train = x_train.drop(['vehicle_restricted', 'height_restricted'], axis=1)
x_test = x_test.drop(['vehicle_restricted', 'height_restricted'], axis=1)✏️ 변수들의 관계 파악하기
- 상관관계 분석 (히트맵 활용)
- target 변수는 최고속도제한('maximum_speed_limit') 변수와 가장 높은 양의 상관관계를 보이고, 이외에도 'weight_restricted', 'road_type' 변수와 양의 상관관계를 보임
- 'road_rating', 'lane_count' 컬럼은 음의 상관관계를 보임
## 'base_date', 'base_hour' 컬럼 제외하고 히트맵 그리기
plt.figure(figsize=(15, 8))
sns.heatmap(x_train.drop(['base_date', 'base_hour'], axis=1).corr(), annot=True)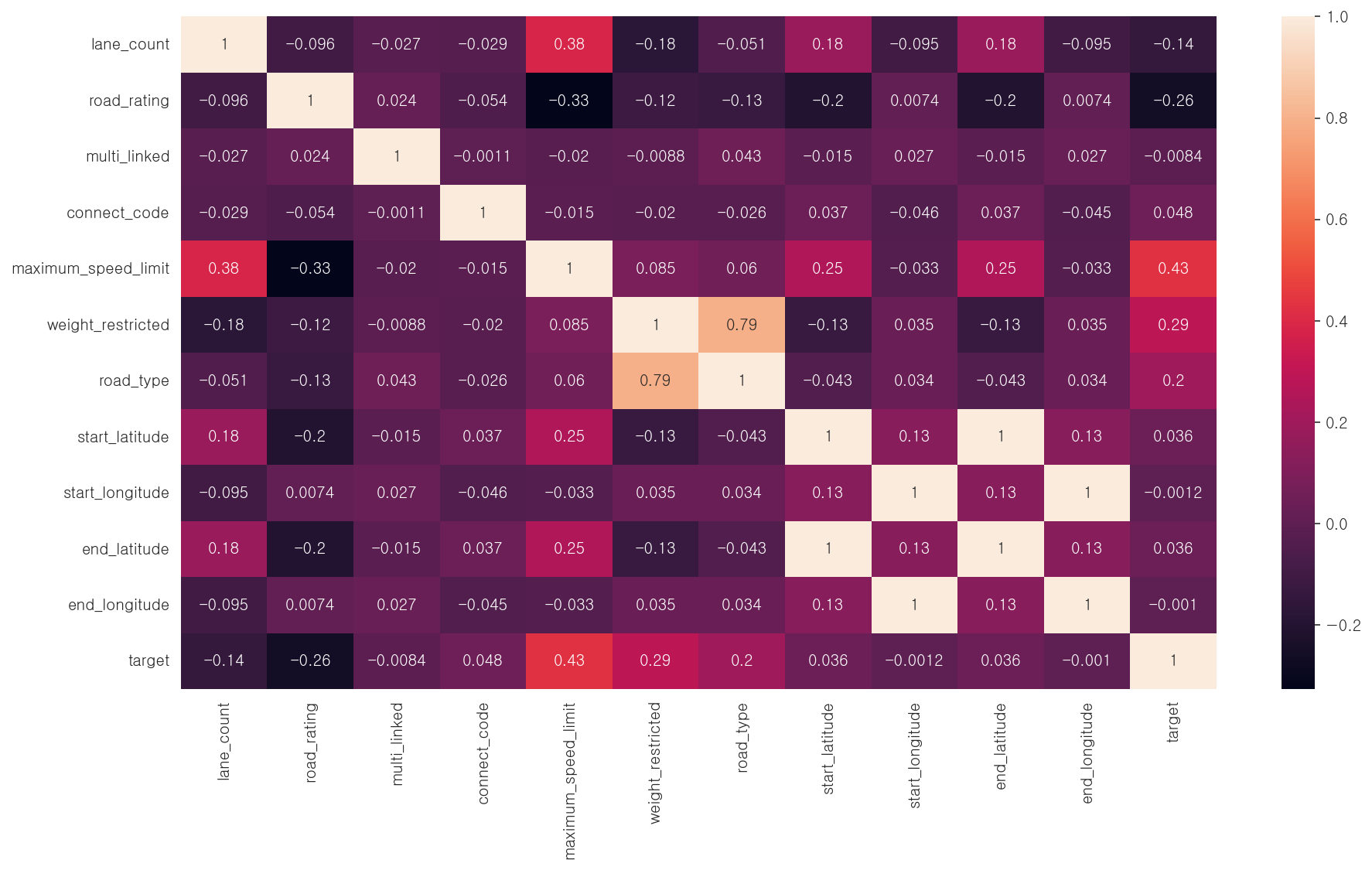
✏️ 변수별 특징 파악하기
- 최고속도제한('maximum_speed_limit') 컬럼
-범주별로 평균속도('target') 값에 차이가 있는 것으로 보임
-이상치가 존재하는 것으로 보임 (추후 제거)
print(x_train['maximum_speed_limit'].value_counts())
print(x_train.groupby('maximum_speed_limit')['target'].mean())60.0 1665573
50.0 1103682
70.0 995077
80.0 700334
30.0 229761
40.0 6790
Name: maximum_speed_limit, dtype: int64
maximum_speed_limit
30.0 32.220825
40.0 62.774078
50.0 35.492229
60.0 42.316288
70.0 41.366207
80.0 60.703697
Name: target, dtype: float32## 범주별 분포
sns.distplot(x_train['maximum_speed_limit'])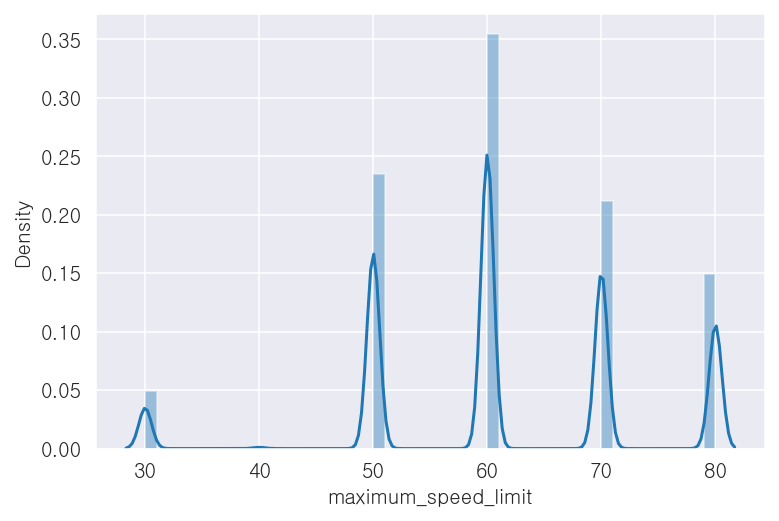
## 상자그림
sns.boxplot(x='maximum_speed_limit', y='target', data=x_train)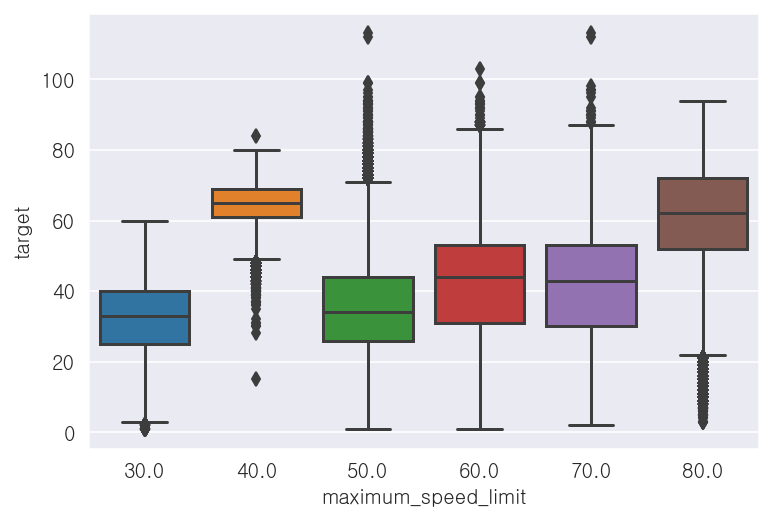
- 통과제한하중('weight_restricted') 컬럼
-통과제한하중이 없는 경우, 평균속도가 가장 낮음
print(x_train['weight_restricted'].value_counts())
print(x_train.groupby('weight_restricted')['target'].mean())0.0 4032874
43200.0 410361
32400.0 239305
50000.0 18677
Name: weight_restricted, dtype: int64
weight_restricted
0.0 40.955696
32400.0 47.453350
43200.0 57.883888
50000.0 47.088665
Name: target, dtype: float32## 상자그림
sns.boxplot(x='weight_restricted', y='target', data=x_train)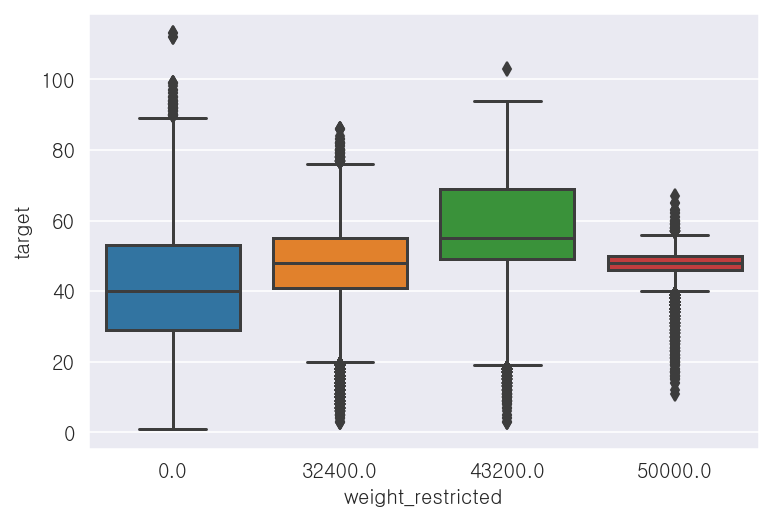
- 차로수('lane_count') 컬럼
-2차선일 때, 평균속도가 가장 높음
print(x_train['lane_count'].value_counts())
print(x_train.groupby('lane_count')['target'].mean())2 2352092
1 1558531
3 790594
Name: lane_count, dtype: int64
lane_count
1 43.570560
2 44.915714
3 34.917782
Name: target, dtype: float32## 시각화
sns.histplot(x=x_train['target'], hue=x_train['lane_count'], palette='bright')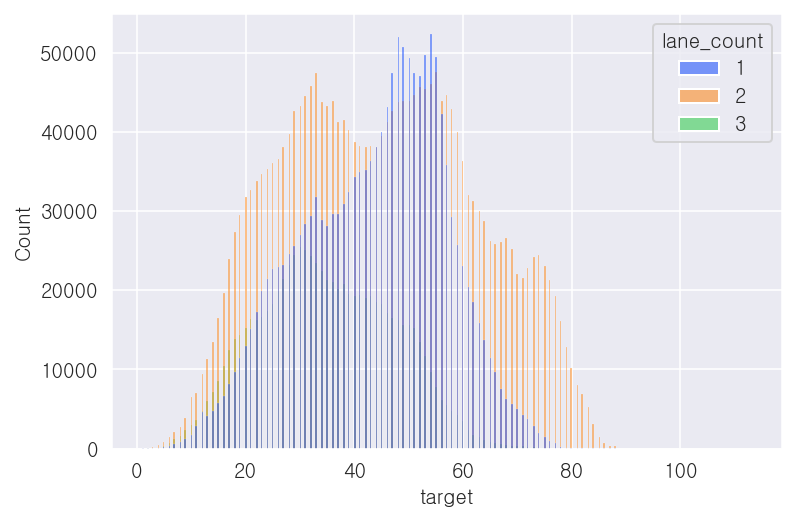
## 상자그림
sns.boxplot(x='lane_count', y='target', data=x_train)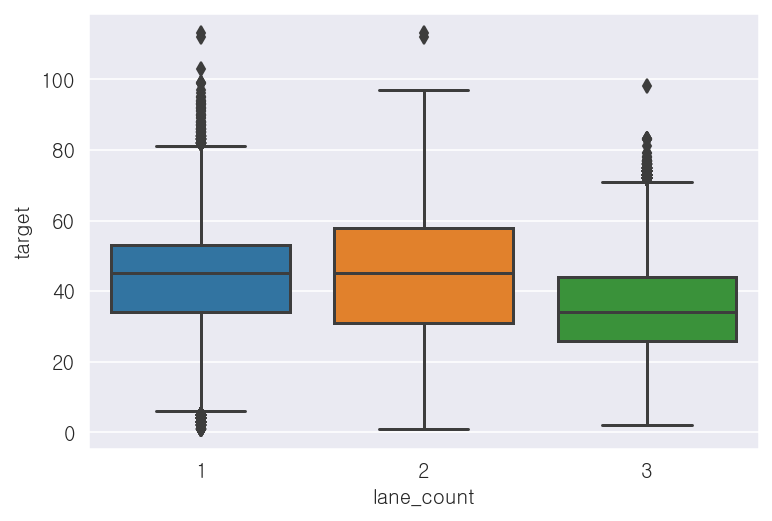
- 도로등급('road_rating') 컬럼
-103(일반국도), 106(지방도), 107(시도/군도)인 것으로 추측됨
-도로등급이 107일 때, 평균속도가 가장 낮음
print(x_train['road_rating'].value_counts())
print(x_train.groupby('road_rating')['target'].mean())103 2159511
107 1582214
106 959492
Name: road_rating, dtype: int64
road_rating
103 46.388466
106 48.021549
107 34.701408
Name: target, dtype: float32## 시각화
sns.displot(x = x_train['target'], hue = x_train['road_rating'], palette='bright')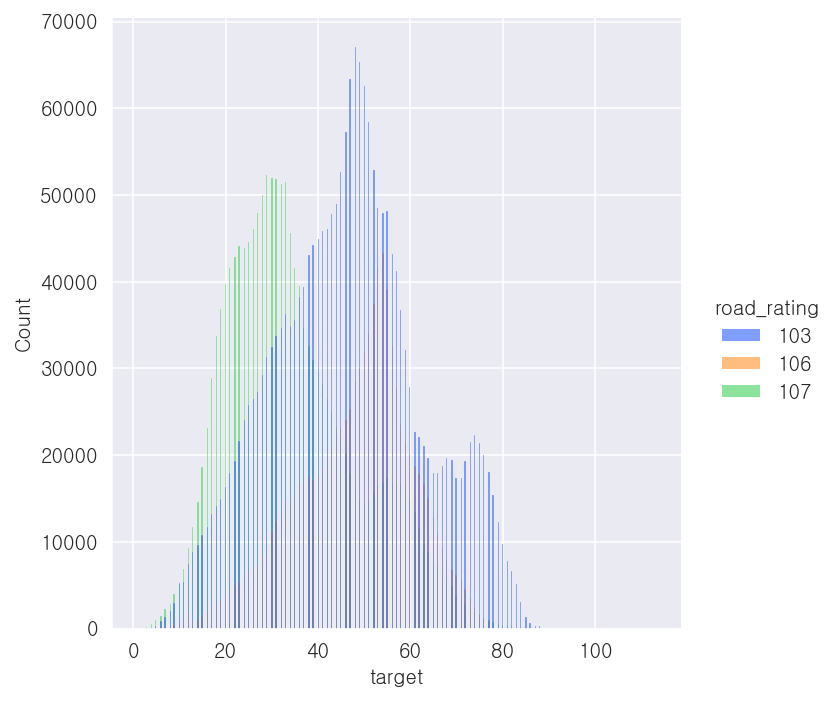
## 상자그림
sns.boxplot(x='road_rating', y='target', data=x_train)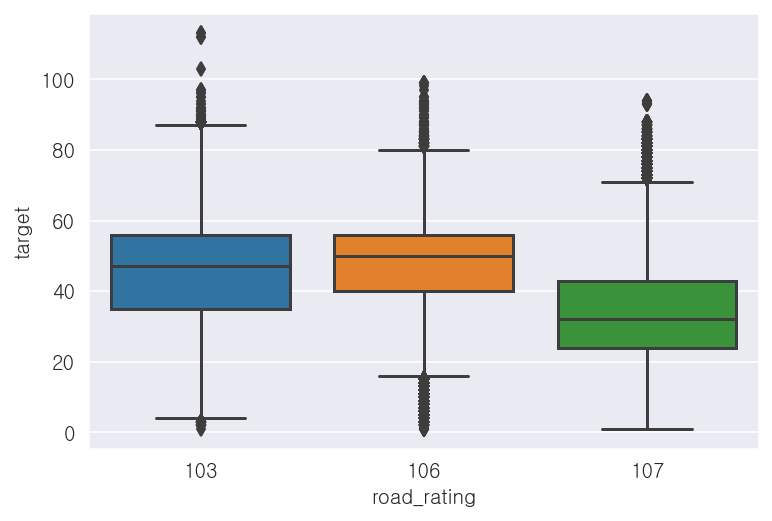
- 도로유형('road_type') 컬럼
-도로유형에 따른 평균속도에 차이가 존재함
print(x_train['road_type'].value_counts())
print(x_train.groupby('road_type')['target'].mean())0 3737117
3 964100
Name: road_type, dtype: int64
road_type
0 41.160931
3 49.097126
Name: target, dtype: float32## 시각화
x_train.groupby('road_type')['target'].hist()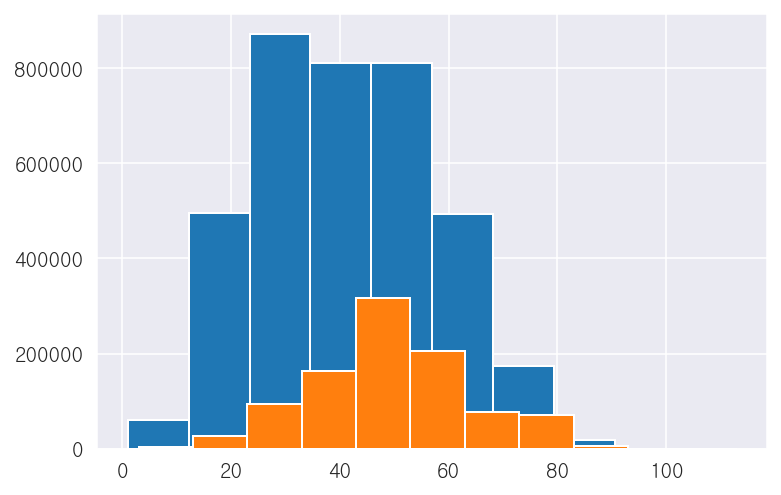
## 상자그림
sns.boxplot(x='road_type', y='target', data=x_train)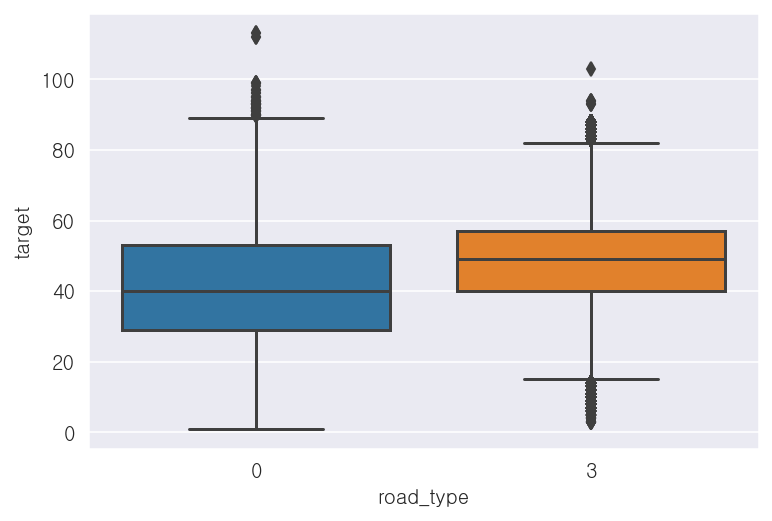
- 중용구간 여부('multi_linked') 컬럼
-multi_linked=1(중용구간인 곳)에 비해 multi_linked=0(중용구간이 아닌 곳)이 훨씬 많으므로, 해당 컬럼은 제거함
print(x_train['multi_linked'].value_counts())
print(x_train.groupby('multi_linked')['target'].mean())0 4698978
1 2239
Name: multi_linked, dtype: int64
multi_linked
0 42.791370
1 36.642696
Name: target, dtype: float32## 해당 컬럼 제거
x_train = x_train.drop('multi_linked', axis=1)
x_test = x_test.drop('multi_linked', axis=1)- 연결로 코드('connect_code') 컬럼
-0(연결로 아님), 103(일반국도 연결로)인 것으로 추측됨
-연결로 코드에 따른 평균속도에 차이가 존재하지만, 데이터의 불균형으로 인해 해당 컬럼은 제거함
print(x_train['connect_code'].value_counts())
print(x_train.groupby('connect_code')['target'].mean())0 4689075
103 12142
Name: connect_code, dtype: int64
connect_code
0 42.749191
103 57.947044
Name: target, dtype: float32## 해당 컬럼 제거
x_train = x_train.drop('connect_code', axis=1)
x_test = x_test.drop('connect_code', axis=1)- 시간대('base_hour') 컬럼
-21~23시, 0~7시에는 상대적으로 평균 속도가 높은 편임. 즉, 통행량이 적음
-반면 대략 8~9시, 10~20시에는 상대적으로 평균 속도가 낮은 편임. 특히 17~18시에 가장 낮음
-파생변수로 활용할 수 있을 것으로 판단됨
## 시간대별 평균 속도 비교
print(x_train.groupby('base_hour')['target'].mean().sort_values(ascending=False))base_hour
3 50.543255
2 50.278660
1 49.763298
4 49.747524
0 48.742199
5 47.201141
23 45.807739
6 45.549030
22 43.989861
7 43.682270
21 42.173431
8 41.656292
20 41.113808
9 40.875938
10 40.222233
19 40.104111
12 39.838539
11 39.824593
13 39.731472
14 39.561119
15 39.351700
16 39.127930
17 38.473362
18 38.241257
Name: target, dtype: float32## 시간대별 평균 target값 시각화
base_hour_mean = x_train.groupby('base_hour')['target'].mean().sort_values(ascending=False)
plt.figure(figsize=(10,5))
sns.barplot(x=base_hour_mean.index, y=base_hour_mean.values)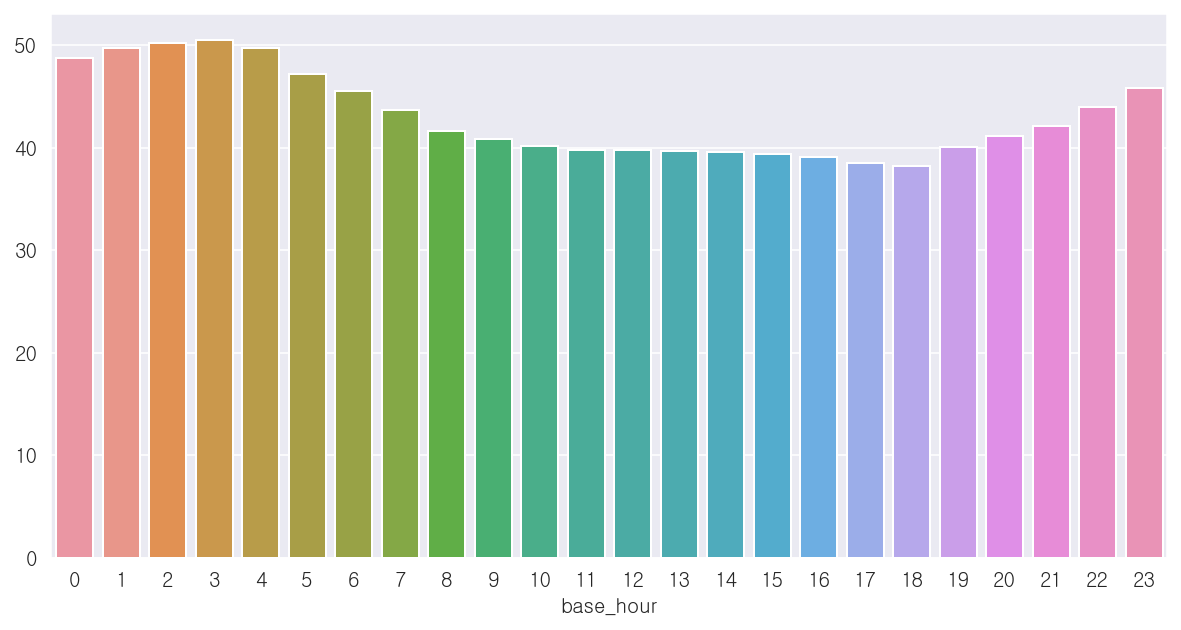
- 도로명('road_name') 컬럼
-결측치('-')가 569,463개 존재함 (추후 대체)
print(x_train['road_name'].value_counts())일반국도12호선 1046092
- 569463
일반국도16호선 554510
일반국도95호선 248181
일반국도11호선 215701
...
애원로 7718
아봉로 7342
남조로 6813
호서중앙로 2819
호근로 587
Name: road_name, Length: 61, dtype: int64✏️ target 변수 파악하기
- 첨도가 어느 정도 존재하지만, 왜도가 거의 없으므로 변환을 따로 수행하지 않아도 될 것으로 판단함
## 분포 확인
# from scipy import stats
from scipy.stats import norm, skew, kurtosis
# distplot
sns.distplot(x_train['target'] , fit=norm)
# 왜도, 첨도 확인
(skew, kurt) = skew(x_train['target']), kurtosis(x_train['target'])
print( '\n skew = {:.2f} and kurt = {:.2f}\n'.format(skew, kurt)) skew = 0.14 and kurt = -0.59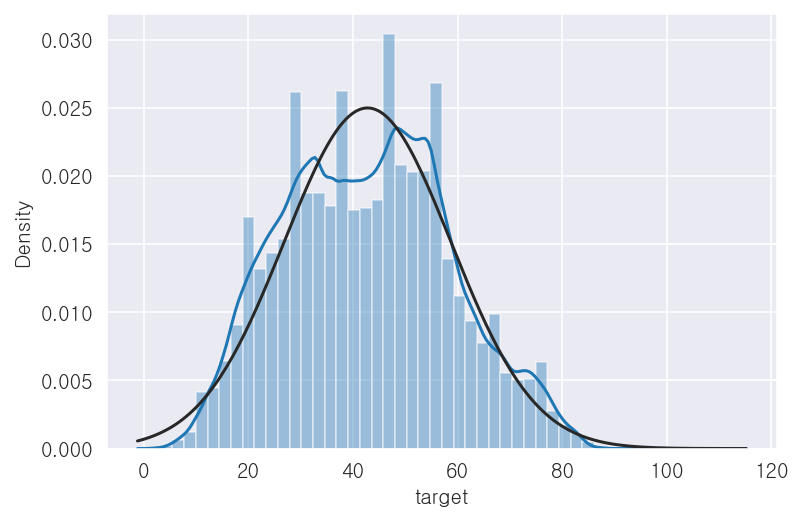
(4) 데이터 전처리
⚡ 결측치 처리하기
- 도로명('road_name') 컬럼: 결측치('-')가 569,463개 존재하므로, 최대한 대체하기로 결정함
- 도로명이 '-'인 행의 도로등급('road_rating')이 모두 107이므로, 도로등급이 107이면서 통과제한하중('weight_restricted')이 43200.0, 32400.0일 때 각각의 도로명 값으로 결측치를 대체함
## 도로명 컬럼이 결측치('-')인 행만 따로 추출
road_missing_value = x_train[x_train['road_name'] == '-']
road_missing_valueprint(road_missing_value['road_rating'].value_counts())
print(road_missing_value['weight_restricted'].value_counts())107 569463
Name: road_rating, dtype: int64
0.0 481943
43200.0 68013
32400.0 19507
Name: weight_restricted, dtype: int64print(x_train[(x_train['road_rating'] == 107) & (x_train['weight_restricted'] == 43200.0)]['road_name'].value_counts())
print(x_train[(x_train['road_rating'] == 107) & (x_train['weight_restricted'] == 32400.0)]['road_name'].value_counts())- 68013
중문로 11336
Name: road_name, dtype: int64
- 19507
산서로 7940
Name: road_name, dtype: int64## 결측치 대체
print('결측치 대체 전: ', len(x_train[x_train['road_name'] == '-']))
x_train.loc[(x_train['road_rating'] == 107) & (x_train['weight_restricted'] == 32400.0) & (x_train['road_name'] == "-"), 'road_name'] = "산서로"
x_train.loc[(x_train['road_rating'] == 107) & (x_train['weight_restricted'] == 43200.0) & (x_train['road_name'] == "-"), 'road_name'] = "중문로"
x_test.loc[(x_test['road_rating'] == 107) & (x_test['weight_restricted'] == 32400.0) & (x_test['road_name'] == "-"), 'road_name'] = "산서로"
x_test.loc[(x_test['road_rating'] == 107) & (x_test['weight_restricted'] == 43200.0) & (x_test['road_name'] == "-"), 'road_name'] = "중문로"
print('결측치 대체 후: ', len(x_train[x_train['road_name'] == '-']))결측치 대체 전: 569463
결측치 대체 후: 481943- 'start_node_name', 'road_name' 컬럼의 조합으로 결측치를 대체함
## 'start_node_name', 'road_name' 컬럼의 조합
for i in x_train['start_node_name'].unique():
if (len(x_train[(x_train['start_node_name'] == i)]['road_name'].value_counts()) != 2):
continue
if "-" in x_train[(x_train['start_node_name'] == i)]['road_name'].value_counts().index:
print("-----------", i, "--------------")
print(x_train[(x_train['start_node_name'] == i)]['road_name'].value_counts())node_name_start = ['송목교', '남수교', '하귀입구', '양계장', '난산입구', '영주교', '서중2교',
'천제이교', '하나로교', '신하교', '야영장', '월계교', '서울이용원', '김녕교차로',
'어도초등교', '광삼교', '오렌지농원', '우사', '서귀포시산림조합', '성읍삼거리']
road_name = ['중문로', '중문로', '일반국도12호선', '일반국도12호선', '지방도1119호선', '일반국도11호선', '중문로',
'산서로', '중문로', '중문로', '관광단지1로', '산서로', '태평로', '일반국도12호선',
'일반국도16호선', '중문로', '일반국도11호선', '일반국도16호선', '지방도1136호선', '일반국도16호선']
print('결측치 대체 전: ', len(x_train[x_train['road_name'] == '-']))
for i in range(len(node_name_start)):
x_train.loc[(x_train['start_node_name'] == node_name_start[i]) & (x_train['road_name'] == '-'), 'road_name'] = road_name[i]
x_test.loc[(x_test['start_node_name'] == node_name_start[i]) & (x_test['road_name'] == '-'), 'road_name'] = road_name[i]
print('결측치 대체 후: ', len(x_train[x_train['road_name'] == '-']))결측치 대체 전: 481943
결측치 대체 후: 379668- 'end_node_name', 'road_name' 컬럼의 조합으로 결측치를 대체함
## 'end_node_name', 'road_name' 컬럼의 조합
for i in x_train['end_node_name'].unique():
if (len(x_train[(x_train['end_node_name'] == i)]['road_name'].value_counts()) != 2):
continue
if "-" in x_train[(x_train['end_node_name'] == i)]['road_name'].value_counts().index:
print("-----------", i, "--------------")
print(x_train[(x_train['end_node_name'] == i)]['road_name'].value_counts())node_name_end = ['남수교', '농협주유소', '난산입구', '성읍삼거리', '김녕교차로', '한남교차로', '서울이용원',
'하귀입구', '우사', '어도초등교', '월계교', '양계장', '하나로교', '광삼교',
'수간교차로', '난산사거리', '서중2교', '서귀포시산림조합', '옹포사거리', '진은교차로']
road_name = ['중문로', '산서로', '지방도1119호선', '일반국도16호선', '일반국도12호선', '중문로', '태평로',
'일반국도12호선', '일반국도16호선', '일반국도16호선', '산서로', '일반국도12호선', '중문로', '중문로',
'일반국도12호선', '지방도1119호선', '중문로', '지방도1136호선', '산서로', '중문로']
print('결측치 대체 전: ', len(x_train[x_train['road_name'] == '-']))
for i in range(len(node_name_end)):
x_train.loc[(x_train['end_node_name'] == node_name_end[i]) & (x_train['road_name'] == '-'), 'road_name'] = road_name[i]
x_test.loc[(x_test['end_node_name'] == node_name_end[i]) & (x_test['road_name'] == '-'), 'road_name'] = road_name[i]
print('결측치 대체 후: ', len(x_train[x_train['road_name'] == '-']))결측치 대체 전: 379668
결측치 대체 후: 277900- 'start_latitude', 'road_name' 컬럼의 조합으로 결측치를 대체함
## 위도/경도 컬럼의 경우, 6번째 자리까지 반올림함 (반올림해도 train 데이터에서 고유값의 개수는 변하지 않음)
print('반올림 전: ', x_train['start_latitude'].nunique(), x_train['start_longitude'].nunique(), x_train['end_latitude'].nunique(), x_train['end_longitude'].nunique())
x_train[['start_latitude', 'start_longitude', 'end_latitude', 'end_longitude']] = x_train[['start_latitude', 'start_longitude', 'end_latitude', 'end_longitude']].apply(lambda x: round(x, 6))
x_test[['start_latitude', 'start_longitude', 'end_latitude', 'end_longitude']] = x_test[['start_latitude', 'start_longitude', 'end_latitude', 'end_longitude']].apply(lambda x: round(x, 6))
print('반올림 후', x_train['start_latitude'].nunique(), x_train['start_longitude'].nunique(), x_train['end_latitude'].nunique(), x_train['end_longitude'].nunique())## 'start_latitude', 'road_name' 컬럼의 조합
for i in x_train['start_latitude'].unique():
if (len(x_train[(x_train['start_latitude'] == i)]['road_name'].value_counts()) != 2):
continue
if "-" in x_train[(x_train['start_latitude'] == i)]['road_name'].value_counts().index:
print("-----------", i, "--------------")
print(x_train[(x_train['start_latitude'] == i)]['road_name'].value_counts())latitude_start = [33.409416, 33.402546, 33.471164, 33.411255, 33.405319,
33.322018, 33.325096, 33.408431, 33.284189, 33.47339]
road_name = ['산서로', '지방도1119호선', '일반국도12호선', '산서로', '산서로',
'중문로', '중문로', '산서로', '중문로', '일반국도12호선']
print('결측치 대체 전: ', len(x_train[x_train['road_name'] == '-']))
for i in range(len(latitude_start)):
x_train.loc[(x_train['start_latitude'] == latitude_start[i]) & (x_train['road_name'] == '-'), 'road_name'] = road_name[i]
x_test.loc[(x_test['start_latitude'] == latitude_start[i]) & (x_test['road_name'] == '-'), 'road_name'] = road_name[i]
print('결측치 대체 후: ', len(x_train[x_train['road_name'] == '-']))결측치 대체 전: 277900
결측치 대체 후: 228095- 'end_latitude', 'road_name' 컬럼의 조합으로 결측치를 대체함
## 'end_latitude', 'road_name' 컬럼의 조합
for i in x_train['end_latitude'].unique():
if (len(x_train[(x_train['end_latitude'] == i)]['road_name'].value_counts()) != 2):
continue
if "-" in x_train[(x_train['end_latitude'] == i)]['road_name'].value_counts().index:
print("-----------", i, "--------------")
print(x_train[(x_train['end_latitude'] == i)]['road_name'].value_counts())latitude_end = [33.47339, 33.411255, 33.412573, 33.244882, 33.322018]
road_name = ['일반국도12호선', '산서로', '산서로', '산서로', '중문로']
print('결측치 대체 전: ', len(x_train[x_train['road_name'] == '-']))
for i in range(len(latitude_end)):
x_train.loc[(x_train['end_latitude'] == latitude_end[i]) & (x_train['road_name'] == '-'), 'road_name'] = road_name[i]
x_test.loc[(x_test['end_latitude'] == latitude_end[i]) & (x_test['road_name'] == '-'), 'road_name'] = road_name[i]
print('결측치 대체 후: ', len(x_train[x_train['road_name'] == '-']))결측치 대체 전: 228095
결측치 대체 후: 205952- 'start_longitude', 'road_name' 컬럼의 조합으로 결측치를 대체함
## 'start_longitude', 'road_name' 컬럼의 조합
for i in x_train['start_longitude'].unique():
if (len(x_train[(x_train['start_longitude'] == i)]['road_name'].value_counts()) != 2) :
continue
if "-" in x_train[(x_train['start_longitude'] == i)]['road_name'].value_counts().index:
print("-----------", i, "--------------")
print(x_train[(x_train['start_longitude'] == i)]['road_name'].value_counts())longitude_start = [126.258674, 126.259693]
road_name = ['산서로', '산서로']
print('결측치 대체 전: ', len(x_train[x_train['road_name'] == '-']))
for i in range(len(longitude_start)):
x_train.loc[(x_train['start_longitude'] == longitude_start[i]) & (x_train['road_name'] == '-'), 'road_name'] = road_name[i]
x_test.loc[(x_test['start_longitude'] == longitude_start[i]) & (x_test['road_name'] == '-'), 'road_name'] = road_name[i]
print('결측치 대체 후: ', len(x_train[x_train['road_name'] == '-']))결측치 대체 전: 205952
결측치 대체 후: 197539- 'end_longitude', 'road_name' 컬럼의 조합으로 결측치를 대체함
## 'end_longitude', 'road_name' 컬럼의 조합
for i in x_train['end_longitude'].unique():
if (len(x_train[(x_train['end_longitude'] == i)]['road_name'].value_counts()) != 2) :
continue
if "-" in x_train[(x_train['end_longitude'] == i)]['road_name'].value_counts().index:
print("-----------", i, "--------------")
print(x_train[(x_train['end_longitude'] == i)]['road_name'].value_counts())longitude_end = [126.261797 , 126.259693]
road_name = ['산서로', '산서로']
print('결측치 대체 전: ', len(x_train[x_train['road_name'] == '-']))
for i in range(len(longitude_end)):
x_train.loc[(x_train['end_longitude'] == longitude_end[i]) & (x_train['road_name'] == '-'), 'road_name'] = road_name[i]
x_test.loc[(x_test['end_longitude'] == longitude_end[i]) & (x_test['road_name'] == '-'), 'road_name'] = road_name[i]
print('결측치 대체 후: ', len(x_train[x_train['road_name'] == '-']))결측치 대체 전: 197539
결측치 대체 후: 188647⚡ 파생변수 생성하기
- 연도('year'), 월('month'), 일('day'), 요일('weekday'), 8월과 인접한 달 여부('adjacent_august'), 시간대('시간대'), 계절('season'), 평일/주말여부('주말여부') 컬럼 생성
## 컬럼 타입 변경
x_train['base_date'] = pd.to_datetime(x_train['base_date'].astype('str'))
x_test['base_date'] = pd.to_datetime(x_test['base_date'].astype('str'))## 연도(year), 월(month) 컬럼 생성
x_train['year'] = x_train['base_date'].dt.year
x_train['month'] = x_train['base_date'].dt.month
x_train['day'] = x_train['base_date'].dt.day
x_train['weekday'] = x_train['base_date'].dt.dayofweek
x_test['year'] = x_test['base_date'].dt.year
x_test['month'] = x_test['base_date'].dt.month
x_test['day'] = x_test['base_date'].dt.day
x_test['weekday'] = x_test['base_date'].dt.dayofweek## 8월과 인접한 달인 7, 9월인지 아닌지에 따라 구분하는 컬럼 생성
x_train['adjacent_august'] = 'N'
x_test['adjacent_august'] = 'N'
x_train.loc[(x_train['month'] >= 7) & (x_train['month'] <= 9), 'adjacent_august'] = 'Y'
x_test.loc[(x_test['month'] >= 7) & (x_test['month'] <= 9), 'adjacent_august'] = 'Y'
print(x_train['adjacent_august'].value_counts())N 3855613
Y 845604
Name: adjacent_august, dtype: int64## '시간대': 8~20시(worktime), 21~7시(resttime)
x_train['시간대'] = '0'
x_test['시간대'] = '0'
x_train.loc[(x_train['base_hour'] >= 8) & (x_train['base_hour'] <= 20), '시간대'] = 'worktime'
x_train.loc[(x_train['base_hour'] <= 7) | (x_train['base_hour'] >= 21), '시간대'] = 'resttime'
x_test.loc[(x_train['base_hour'] >= 8) & (x_test['base_hour'] <= 20), '시간대'] = 'worktime'
x_test.loc[(x_train['base_hour'] <= 7) | (x_test['base_hour'] >= 21), '시간대'] = 'resttime'
print(x_train['시간대'].value_counts())worktime 2716112
resttime 1985105
Name: 시간대, dtype: int64## '계절': 봄(3~5월), 여름(6~8월), 가을(9~11월), 겨울(12~2월)
x_train['season'] = '0'
x_test['season'] = '0'
x_train.loc[(x_train['month'] >= 3) & (x_train['month'] <= 5), 'season'] = '봄'
x_train.loc[(x_train['month'] >= 6) & (x_train['month'] <= 8), 'season'] = '여름'
x_train.loc[(x_train['month'] >= 9) & (x_train['month'] <= 11), 'season'] = '가을'
x_train.loc[(x_train['month'] <= 2) | (x_train['month'] == 12), 'season'] = '겨울'
x_test.loc[(x_test['month'] >= 3) & (x_test['month'] <= 5), 'season'] = '봄'
x_test.loc[(x_test['month'] >= 6) & (x_test['month'] <= 8), 'season'] = '여름'
x_test.loc[(x_test['month'] >= 9) & (x_test['month'] <= 11), 'season'] = '가을'
x_test.loc[(x_test['month'] <= 2) | (x_test['month'] == 12), 'season'] = '겨울'
print(x_train['season'].value_counts())겨울 1737202
가을 1229803
봄 969380
여름 764832
Name: season, dtype: int64## 평일/주말 여부: 'weekday' 컬럼값이 0~4이면 평일, 5~6이면 주말
x_train['주말여부'] = 'Y'
x_test['주말여부'] = 'Y'
x_train.loc[x_train['weekday'] <= 4, '주말여부'] = 'N'
x_test.loc[x_test['weekday'] <= 4, '주말여부'] = 'N'
print(x_train['주말여부'].value_counts())N 3357818
Y 1343399
Name: 주말여부, dtype: int64- 컬럼들의 범주별 평균속도에 차이가 있는지 확인
- 범주별 평균속도에 큰 차이가 없는 'day_of_week', 'weekday', 'year', 'month', 'day', '주말여부' 컬럼 제거
- 'base_hour' 컬럼 제거
## 범주별로 평균속도(target)에 차이가 있는지 확인
category_variable = x_train[['day_of_week', 'start_turn_restricted', 'end_turn_restricted',
'year', 'month', 'day', 'weekday', 'adjacent_august', '시간대',
'season', '주말여부', 'target']]## 범주별 target 값의 평균에 차이가 있는지 확인
for i in range(len(category_variable.columns)-1):
print(category_variable.groupby(category_variable.columns[i])['target'].mean())
print('\n')⚡ 불필요한 컬럼 삭제하기
## 범주별 평균속도에 큰 차이가 없는 컬럼 모두 삭제
x_train = x_train.drop(['day_of_week', 'weekday', 'year', 'month', 'day', '주말여부'], axis=1)
x_test = x_test.drop(['day_of_week', 'weekday', 'year', 'month', 'day', '주말여부'], axis=1)
## 분석에 필요하지 않은 컬럼 모두 삭제
x_train = x_train.drop(['base_date', 'base_hour'], axis=1)
x_test = x_test.drop(['base_date', 'base_hour'], axis=1)len(x_train.columns)19⚡ 이상치 처리하기
print('이상치 처리 전: ', len(x_train))
x_train = x_train[x_train['target'] < 100]
print('이상치 처리 후: ', len(x_train))이상치 처리 전: 4701217
이상치 처리 후: 4701212⚡ 범주형 변수 인코딩하기
## 범주형 변수 라벨인코딩
# 범주형 변수만 따로 추출
category_variables = ['start_node_name', 'end_node_name', 'road_rating', 'road_name', 'maximum_speed_limit', 'weight_restricted',
'road_type', 'start_turn_restricted', 'end_turn_restricted', 'adjacent_august', '시간대', 'season']
# 라벨인코딩
from sklearn.preprocessing import LabelEncoder
for i in category_variables:
le = LabelEncoder()
le = le.fit(x_train[i])
x_train[i] = le.transform(x_train[i])
for label in np.unique(x_test[i]):
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
x_test[i] = le.transform(x_test[i])(5) 학습 및 평가
## 'index' 컬럼 따로 저장해두기
x_test_index = x_test['id']
x_train = x_train.drop('id', axis=1)
x_test = x_test.drop('id', axis=1)## target 변수 따로 저장
Y_train = x_train['target']
X_train = x_train.drop('target', axis=1)
X_test = x_test.copy()⚡ 검증을 위한 데이터 분리
from sklearn.model_selection import train_test_split
X_TRAIN, X_TEST, Y_TRAIN, Y_TEST = train_test_split(X_train, Y_train, test_size=0.2, random_state=10)
print(X_TRAIN.shape)
print(X_TEST.shape)
print(Y_TRAIN.shape)
print(Y_TEST.shape)(3760969, 17)
(940243, 17)
(3760969,)
(940243,)✏️ XGBoost
## 모형 학습
from xgboost import XGBRegressor
xgb = XGBRegressor(n_estimators=500, learning_rate=0.17,
max_depth=11, min_child_weight=1,
colsample_bytree=1, random_state=10)
xgb.fit(X_TRAIN, Y_TRAIN)## 결과 예측
pred_xgb = pd.DataFrame(xgb.predict(X_test)).rename(columns={0:'target'})
print(pred_xgb)## 모델 평가
from sklearn.metrics import mean_absolute_error
PRED_XGB = pd.DataFrame(xgb.predict(X_TEST)).rename(columns={0:'target'})
print(mean_absolute_error(Y_TEST, PRED_XGB))3.7992306✏️ LGBM
## 모형 학습
from lightgbm import LGBMRegressor
lgbm = LGBMRegressor(num_iterations=500, learning_rate=0.17,
max_depth=11, min_child_weight=1,
colsample_bytree=1, random_state=10)
lgbm.fit(X_TRAIN, Y_TRAIN)## 결과 예측
pred_lgbm = pd.DataFrame(lgbm.predict(X_test)).rename(columns={0:'target'})
print(pred_lgbm)## 모델 평가
from sklearn.metrics import mean_absolute_error
PRED_LGBM = pd.DataFrame(lgbm.predict(X_TEST)).rename(columns={0:'target'})
print(mean_absolute_error(Y_TEST, PRED_LGBM))3.8770249864529744
데이터 분석가가 되기 위한 여정