요약
- 문제: LLM 학습시키기 위해서는 양질의 데이터가 중요! 하지만 데이터 만드는 작업은 노동집약적이라 시간과 비용이 어마어마함 😳
- 제안: LLM을 활용해 데이터를 구축하는데 드는 시간과 비용을 절약해보자
- 핵심 아이디어: 간단한 질문을 시작으로 다양한 난이도와 주제의 질문 등으로 진화시키자! (포켓몬?)
- GitHub: https://github.com/nlpxucan/WizardLM
연구배경: 그 전까지 데이터는 어떻게 만들어졌나?
- 이전의 데이터셋은 특정 테스크를 정해두고 (QnA 답변하기, 요약하기 등) 데이터를 만드는 경우가 많았고, 일반화 가능성을 높이기 위해 다양한 테스크 데이터로 훈련하는 멀티 테스킹 방식을 택함.
- LLM 등장이후에는 특정 테스크에 종속되기보다 <지시문, 답변> 형태의 데이터로 파인튜닝했음. InstructGPT와 Vicuna (with SharedGPT) 모두 사람이 만든 지시문 데이터를 사용했음.
- 하지만 WizardLM은 지시문 데이터 생성 과정에서 사람의 의존도를 줄이고 + 다양한 난이도의 질문을 확보해서 LLM 성능을 높이는게 목적
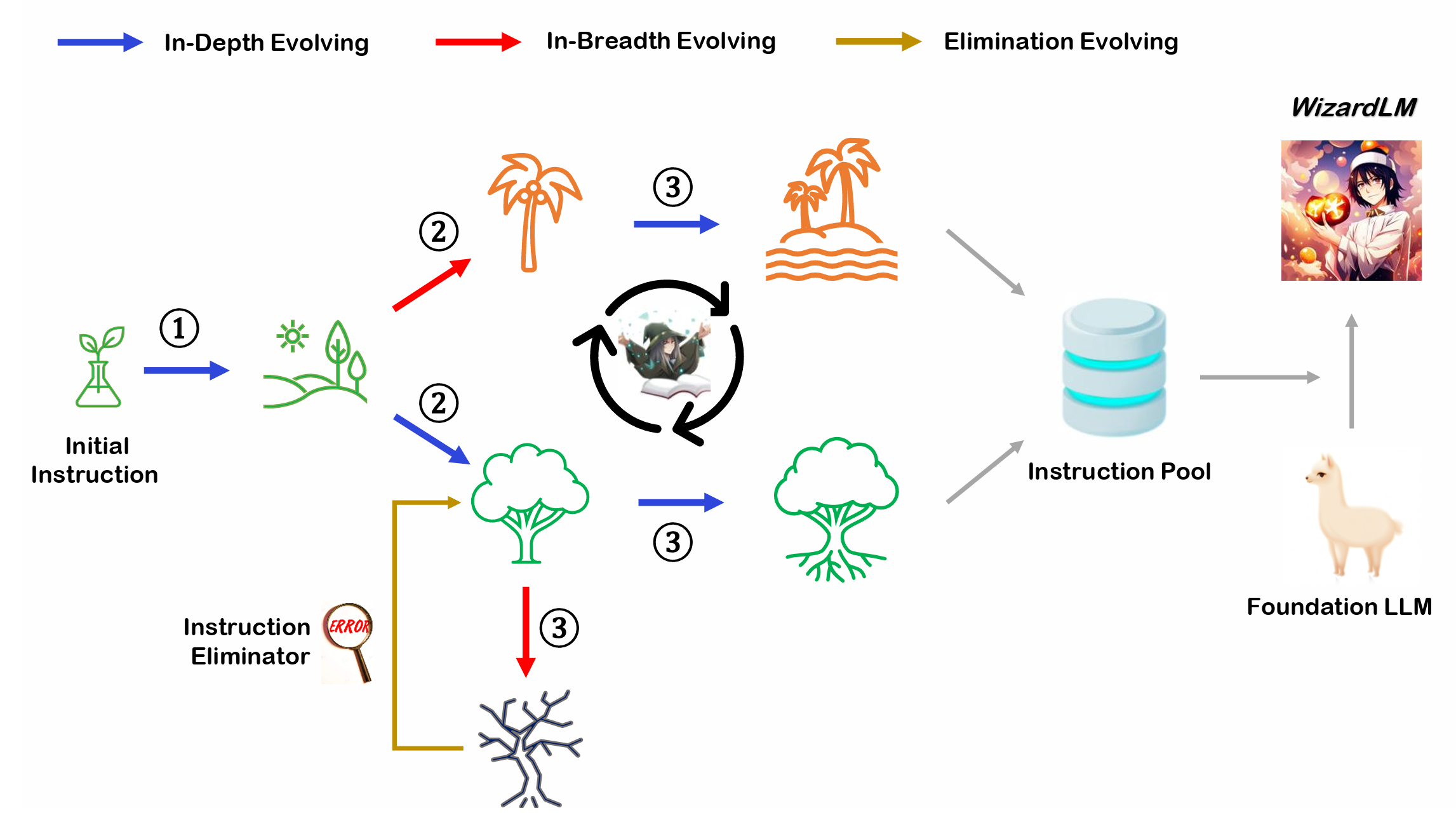
핵심 아이디어: LLM이 자동으로 지시문을 만들게하자
- 구현 과정은 크게 세 단계임
1. 초기 지시문을 준비
-
아래는 입력데이터의 예시로 다양한 스킬과 난이도를 확보하기 위해 지시문 + 스킬 + 난이도 정보가 함께 들어가는게 인상적
{ "Skill": "Writting", "Difficulty": 3, "Instruction": "As an experienced writer, (후략)" }
2. LLM을 사용해 지시문을 진화시킨다
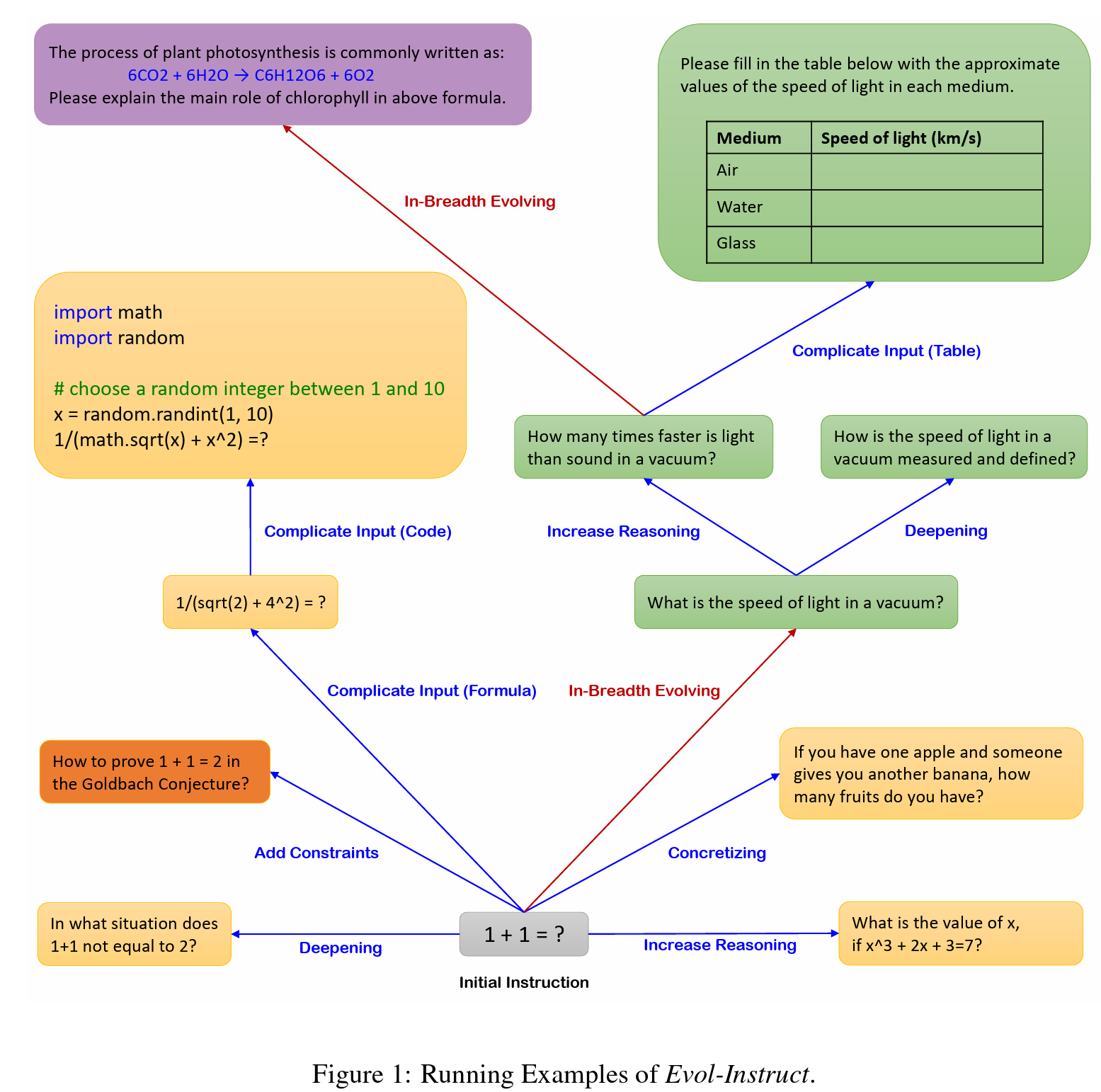
- 수직 진화 (In-Depth Evoloving): 복잡하고 어려운 질문을 만드는 것이 목표
- 조건 넣기, 심화하기, 개념화하기, 근거의 단계를 증가시키기, 복잡한 입력값 넣기 (아래 그림을 보면 이해가 쉽다) - 수평 진화 (In-Bradth Evolving): 주제, 테스크 등의 면에서 다양한 질문을 만드는 것이 목표
- 이것도 예시를 보면 이해하기가 쉽다I want you act as a Prompt Creator. Your goal is to draw inspiration from the #Given Prompt# to create a brand new prompt. This new prompt should belong to the same domain as the #Given Prompt# but be even more rare. The LENGTH and difficulty level of the #Created Prompt# should be similar to that of the #Given Prompt#. The #Created Prompt# must be reasonable and must be understood and responded by humans. ‘#Given Prompt#’, ‘#Created Prompt#’, ‘given prompt’ and ‘created prompt’ are not allowed to appear in #Created Prompt#. #Given Prompt#: <Here is instruction.> #Created Prompt#:
3. 진화시키다가 특정 조건이 성립되면 진화 중지
- (연구팀도 경험적으로 케이스를 정리한듯)
- 엔트로피가 증가하지 않는 경우
- 답변이 의미 없는 문자열들의 나열인 경우
- 답변이 지시문의 복붙이 경우
- LLM이 미안 답변이 어려워!라고 말하는 경우
예시: 초기 지시문이 "1+1?"인 경우
실험셋팅
1. 베이스라인 모델 선택
- Ours: 제안한 방법론으로 만든 데이터셋(Evol-Instruct)으로 LLaMA를 파인튜닝시킨 WizardLM 사용
- 베이스라인: ChatGPT와 더불어 오픈소스 LLaMA + 수동 생성 지시문으로 학습한 Alpaca, Vicuna를 선택
2. 훈련셋(Evol-Instruct) 구축 & WizardLM 파인튜닝
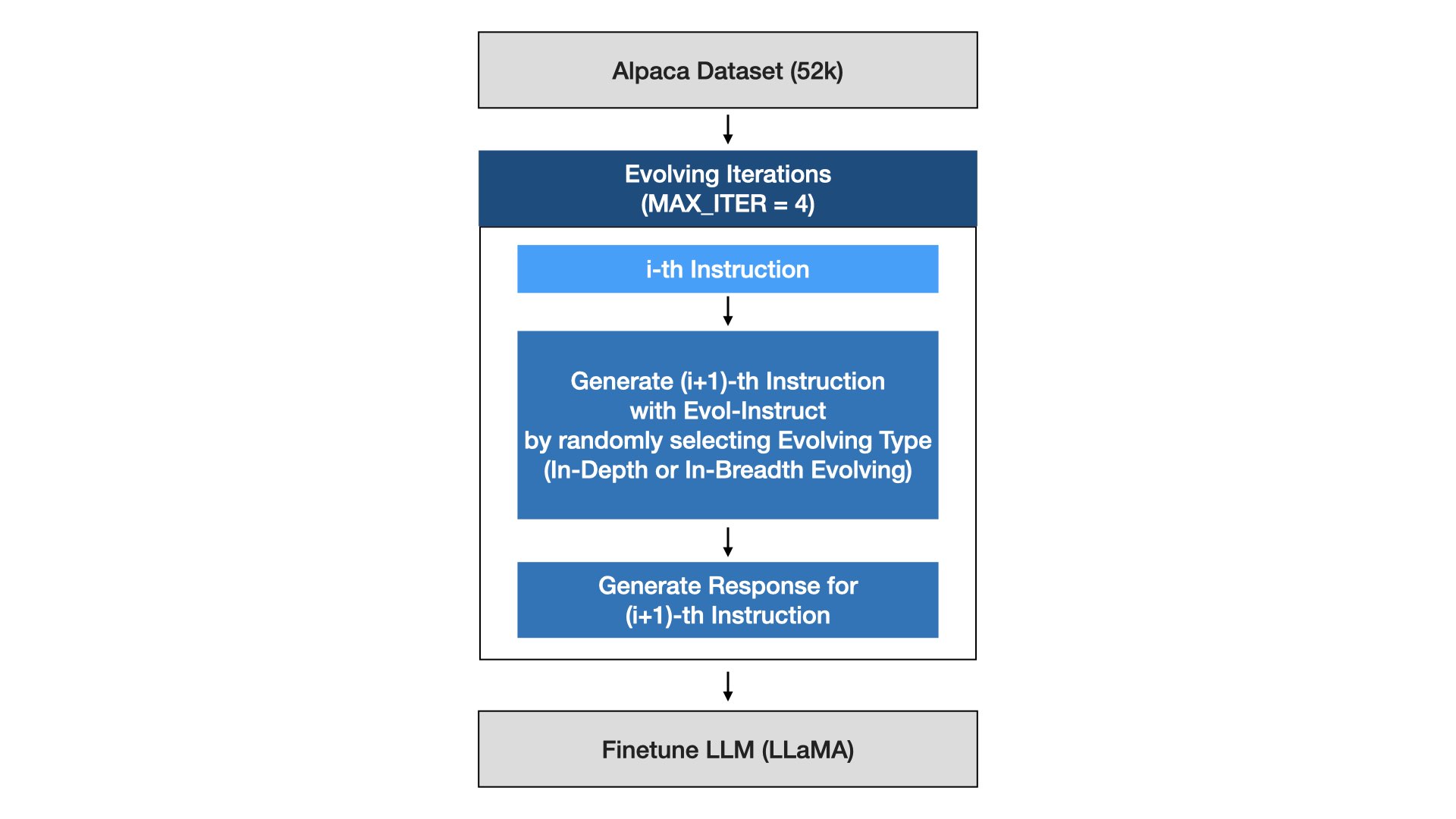
- WiardLM을 위한 훈련셋은 알파카 데이터의 지시문으로 시작해서 논문에서 제안한 지시문 진화과정을 M번 반복하는 방식으로 생성
- 이렇게 생성된 데이터셋(Evol-Instruct)은 LLaMA를 파인튜닝하는데 사용
3. 테스트셋 구축
- 테스트셋인 218개 지시문은 수동으로 구축해서 다양한 스킬, 다양한 난이도를 커버하려함
4. 사람 평가 설계
- 생성된 답변의 질적평가를 위해 총 5가지(관련성, 박식함, 정확성, 논리성, 계산능력) 기준을 설정함

- 지시문을 주고 각 베이스라인의 답변에 대해 블라인드 평가를 하는 방식으로 진행

5. 자동 평가 설계
- Vicuna에서 사용한 GPT-4를 사용한 난이도 평가 방식을 사용함
평가
- 평가 부분은 현재 작업중인 논문이라는 점을 염두하고 해석하는게 좋겠다
- 계속 바뀔거 같아서 저자들이 메인 결과라고 내세우는 것만 정리했고 아래 정리는 개인적인 코멘트와 함께 정리한다
선호도 평가 (Human Evaluation)
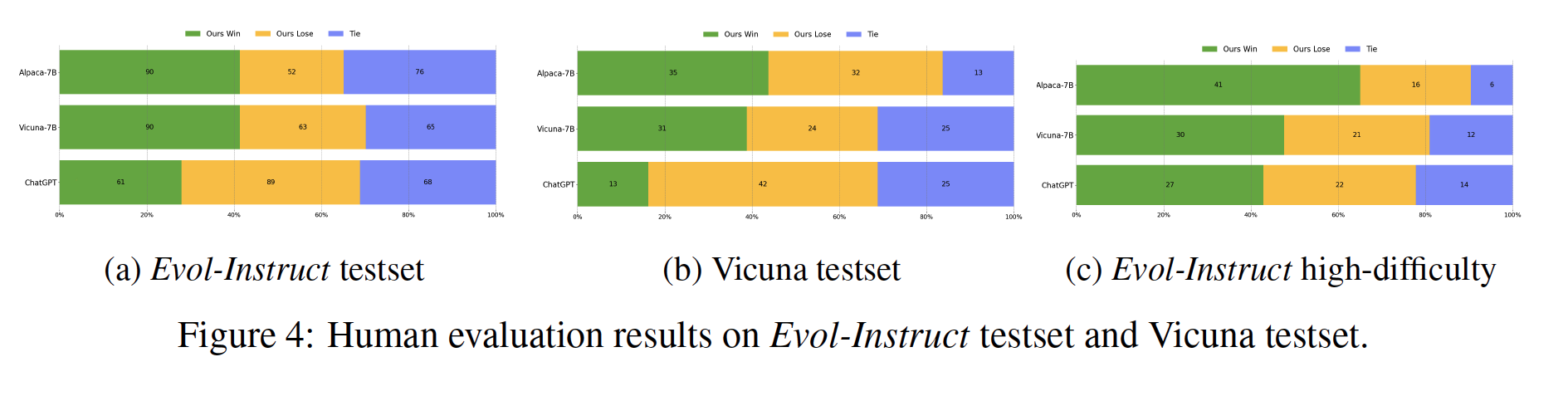
- Alpaca와 Vicuna에서 WizardLM 방식이 더 우위를 보였음
- ChatGPT는 이기지 못했지만 그래도 로컬모델 학습할때는 좋은 방법이라는 점을 보여주는 듯
GPT-4를 활용한 답변 퀄리티 평가 (Automated Evaluation)
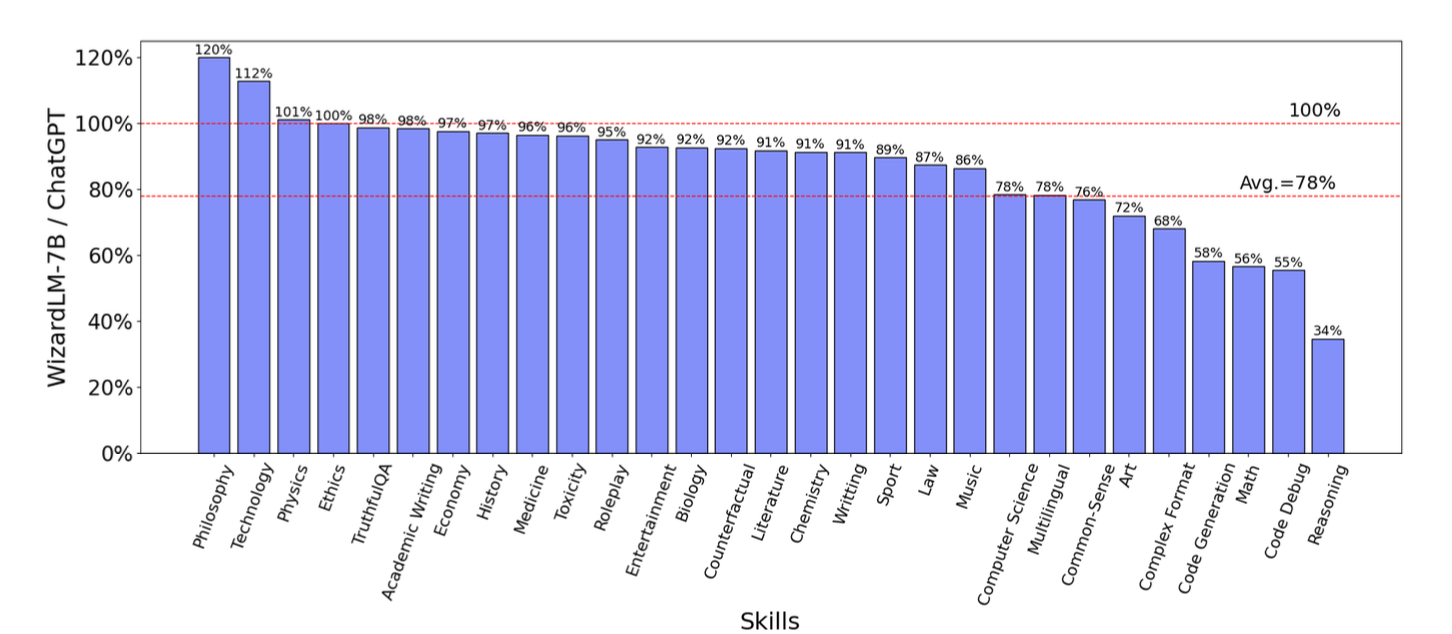
- ChatGPT에 비해서 WizardLM이 잘하는 거 못하는 걸 확인할 수 있는데 100%가 넘으면 WizardLM이 잘하는 분야
- 전반적으로 논리적으로 구성이 필요한 스킬에서 능력이 떨어지는 듯 (오른쪽에 나열된 스킬들)
- 잘하는 것들을 보면 글쓰기나 롤플레이 등 문과적인 스킬셋들에 효과적인 듯
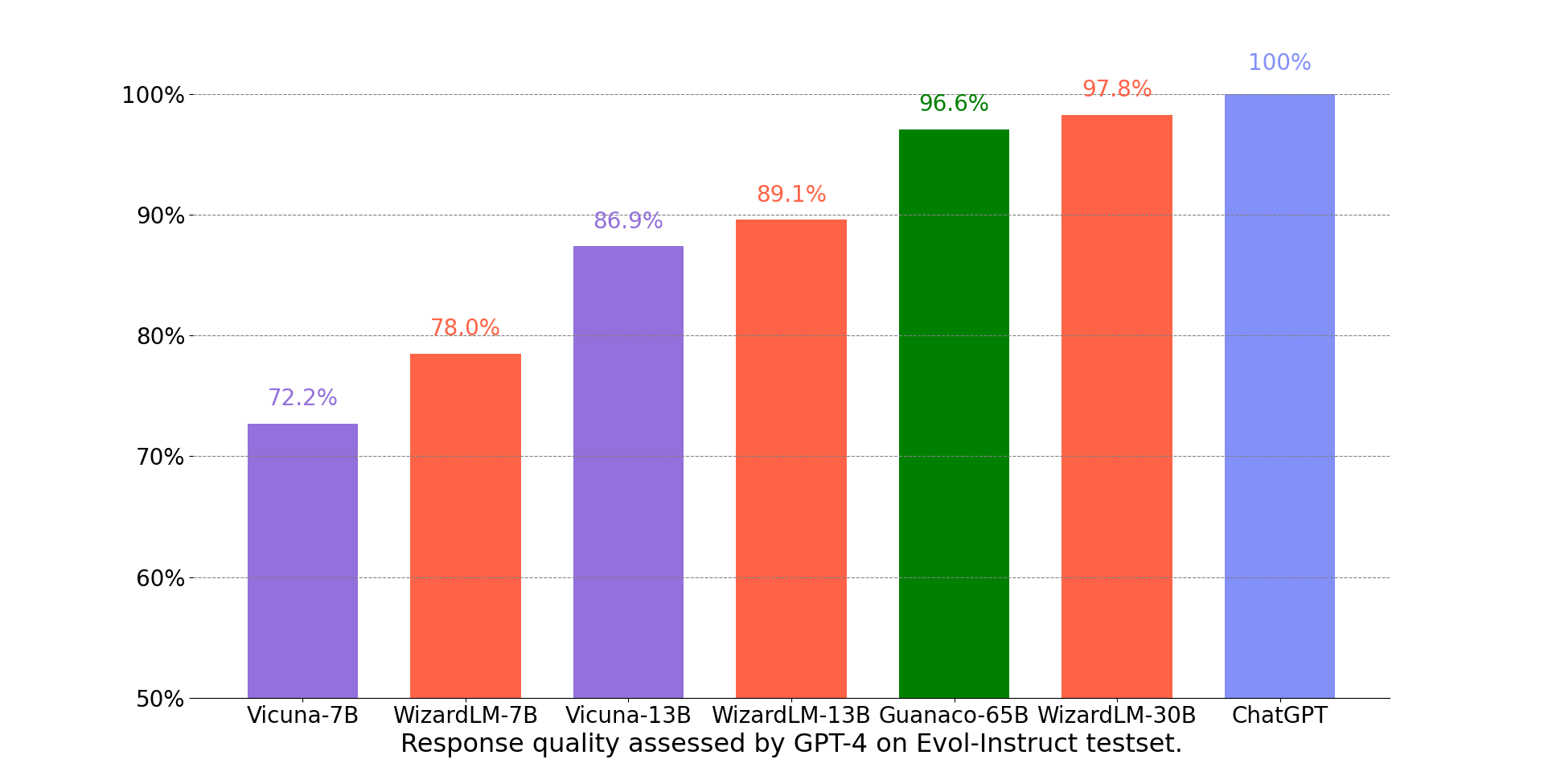
- WizardLM을 썼을 때, 적은 파라미터 (7B) 모델일 수록 WizardLM 방법으로 훈련한게 더 좋은 효과를 보이고 파라미터가 커질수록 효과가 덜한 걸로 봐서 로컬모델에 만들 때 우선적으로 고려해야할 데이터셋 구축 방법론으로 보인다
코멘트
- 사이드 프로젝트나 작은 파라미터 (7B, 13B) 모델에서 대화나 글쓰기 관련 테스크를 주로 수행하는 모델이라면 고려해볼만한 방법론. 저자들도 코드 부분이 안되는걸 파악했는지 공식 깃허브에 가보면 코드만 열심히 학습한 WizardCoder가 따로 있다
- 하지만 지시문 진화 과정이 GPT-3.5 등 API를 사용하기 때문에 진화과정에서 요구되는 비용을 먼저 계산해봐야지 요금 폭탄(...)을 막을 수 있겠다

도파민 중독