[CS330] L2: Supervised multi-task learning, transfer learning
What is a task?
Task는 [ ] 로 구성되며 여기에서 와 는 데이터를 생성하는 분포이다.
즉, 두 데이터 생성 분포에서 Train, Test 데이터 셋이 샘플링되는 것이다. (IID라 가정)
예를 들어 보자.
-
Multi-task classification
-
똑같은 Loss Function을 가지는 분류 문제를 푼다고 해보자.
-
예를 들어, 각기 다른 언어의 손글씨 인식을 한다고 하자.
-
당연히 각 언어별 손글씨 데이터(X)가 주어질 것이므로 입력 분포는 언어마다 다를 것이고 해당 언어에 따라 인식될 답(y)도 다르므로 출력 분포도 다르게 된다.
-
-
Multi-label learning
-
똑같은 Loss Function을 가지면서 데이터(X)가 같은 경우이다.
-
예를 들어, 하나의 문장을 보고
긍/부정분류와어떤 도메인에 대한 문장인지에 대한 분류를 동시에 진행한다고 하자. -
그렇다면, 입력 데이터(X)는 문장 하나로 똑같을 것이지만 출력 분포는 task마다 다를 것이다.
-
+)
긍/부정분류 task는 one-hot, 도메인 분류 task는 그냥 숫자 레이블로 나타낼 수 있을 것
-
Decisions on the model, the objective and the optimization
모델, 목적 함수, 최적화에 대한 결정이 필요함.
-
Vanilla MTL objective:
-
Task Descripter : Task를 구분하기 위해 Task에 대한 정보를 네트워크에 전달하는 것. [이 값을 학습하는 식으로 설정하면 meta-learning에 가까워진다고 함]
- 기본적으로는
one-hot vector같이 전달
- 기본적으로는
MTL 구조의 극과극
파라미터를 최대한 공유하지 않는 구조
- 별개의 네트워크가 학습한 것과 같음. [태스크에 해당하는 레이블만 취하는 구조]
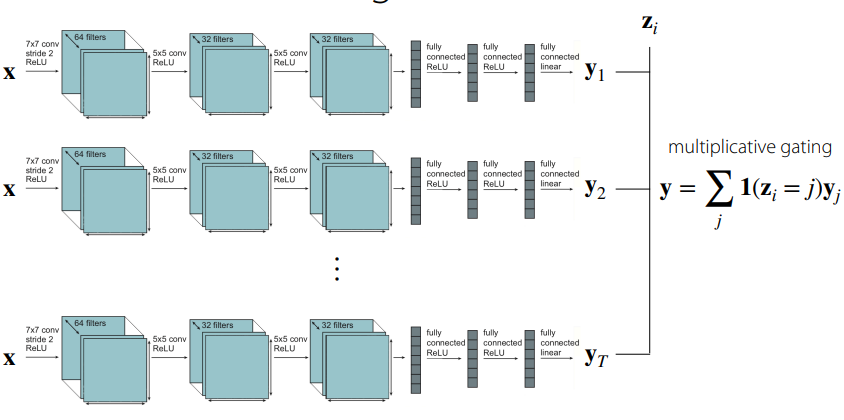
파라미터를 모두 공유하는 구조
- 와 직접적으로 연결된 파라미터를 제외하고는 공유됨.
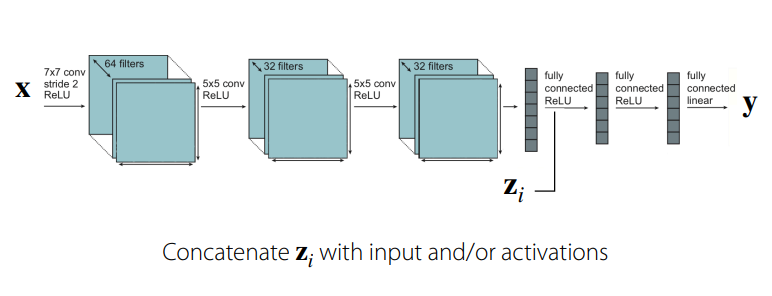
An Alternative View on the Multi-Task Architecture
-
를 공유하는 파라미터 와 task-specific 파라미터 로 나누면 목적 함수는 아래와 같다.
-
Objective:
-
각 Task에 따른 목적함수의 합을 최소화
-
목적함수는 공유하는 파라미터와 각 task-specific 파라미터에 대해 연산
-
-
에 대한 조건을 선택하는 것은
파라미터를 어디서 어떻게 공유할 것인가와 같음.
Common Choices
아래와 같은 여러 구조들이 있고 이것보다 더 복잡한 것도 있음. (정답은 없다)
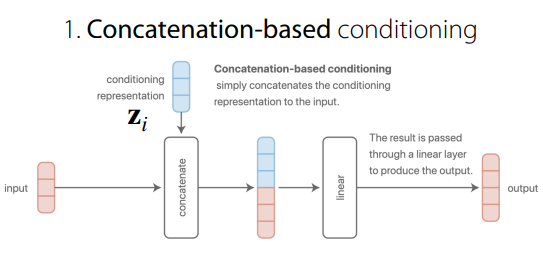
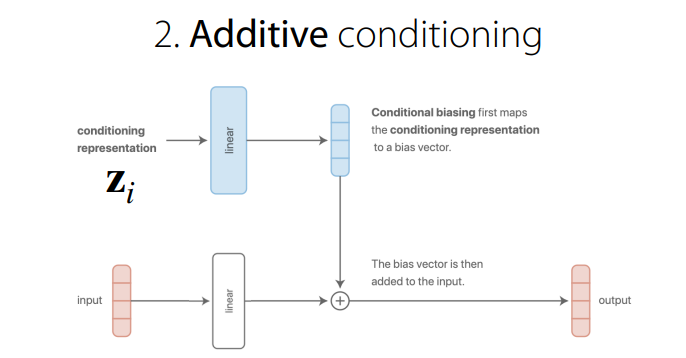
위 두 구조는 결국 똑같은 결과가 된다.
concat을 하는 경우나 linear layer를 각각거친 후 더하는 경우나 같다.
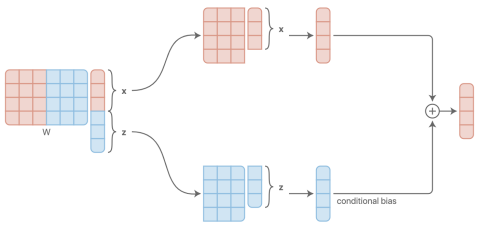
-
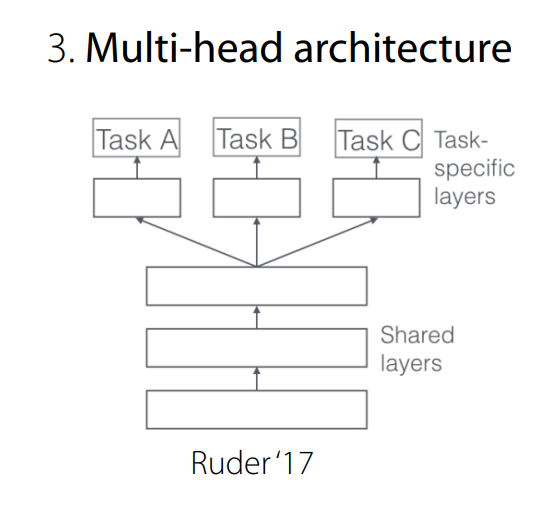
Multi-head archotecture는 다른 label space를 가질 때 유용하다.- +) 다른 레이블 출력을 가질 때
-
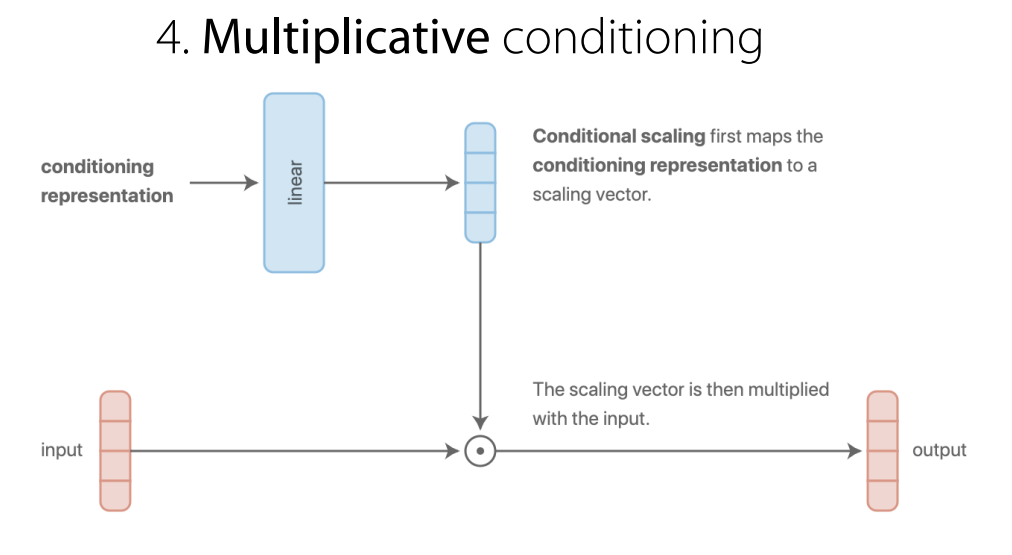
Multiplicative conditioning
-
어떤 layer를 task에 따라 더 유용하게 사용할 수 있는지를 정할 수 있음. (Gating과 유사하게) ==> 네트워크와 헤드들을 일반화
-
layer의 표현력이 좋아짐. [추가적인 정보가 생겼으므로]
-
How should the objective be formed?
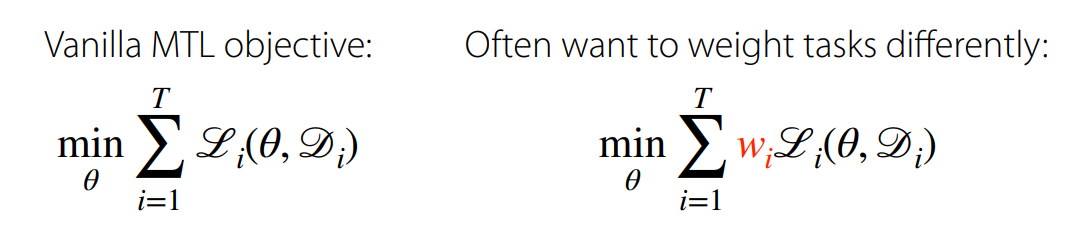
task마다 다른 가중치()를 가지도록 할 수 있다.
-
를 결정하는 방법
-
1) 중요도에 따라 수동으로 결정
-
2) 학습하는 동안 동적으로 조절
-
encourage gradients to have similar magnitudes(ICML2018)
-
optimize for the worst-case task loss =>
- 가장 큰 Loss function을 선택해 이를 최소화 시키는 것
-
-
Challenges

-
Negative transfer
-
함께 학습하는 것보다 따로 학습하는 것이 더 성능이 좋다.
-
task가 서로 악영향을 주고 있을 수 있다.-
ex) 하나의 task가 너무 쉬워서 어려운 task는 무시하고 쉬운 것에 집중하는 경우
-
여러
task를 해결하기 위한 network가 너무 작다. (표현할 수 있는 공간이 부족하다)
-
-
-
negative transfer가 일어나면,task간의 공유를 줄여야 한다.-
soft parameter sharing이란 방식이 있음. -
이는 task가 각자 모델을 가지되 가중치가 일정 범위를 넘어서지 않게 제한하는 방법 [task 별로 가지는 가중치가 비슷하도록]
-
-
Overfitting
-
해결법: task간의 공유를 늘려라.
-
multi-task Learning에서
task를 공유하는 것은 일종의 정규화이므로 공유하는 양을 늘리면 정규화의 정도를 늘리는 것으로 볼 수 있음.
-
-
Task의 양이 많다면? 어떤 task를 골라야 할까?
-
MTL에서는 optimizer, 모델의 구조, task의 종류 등 많은 요소가 있기 때문에 정답은 없다
-
하지만
task similarity를 추정하는 방법은 있다. [아래 사진]
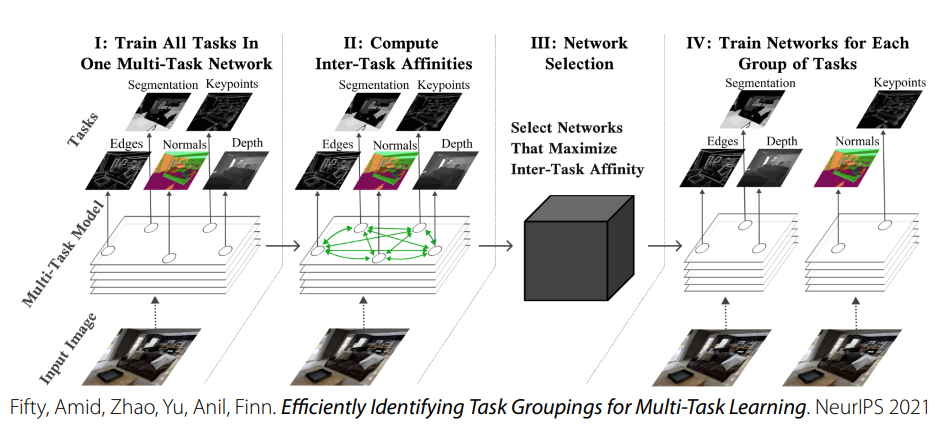
-
Case Study에서 언급한 유튜브 추천 시스템 관련 논문 리뷰는 여기에 남겼다. [Recommending What Video to Watch Next: A Multitask Ranking System]
고찰
-
How should the objective be formed?에서나soft-parameter sharing에서 왜 가중치가 비슷한 값을 가져야한다고 하는걸까-
task 마다 다른 가중치 값을 가지지만 이 값들이 서로 많이 떨어지지 않도록 제한한다.
-
가설 1.
이 값들이 서로 많이 떨어지게 되면 서로의 task가 상충되게 되어서- 이건 task 선택의 문제임.
-
가설 2.
값들이 너무 큰 차이를 가지게 되면 활성화 함수를 지날 때, 너무 극단적으로 0과 1로 쏠린다던가- 값의 크기에 대한 문제가 아님.
-
-
어떠한 task를 풀기 위해 보조 task를 이용하는 것이므로 이 보조 task에 쓰인 정보들을 잘 전달하는 것이 중요함. (목적 task를 풀기 위해)
- 따라서, 해당 목적 task를 풀기 위한 정보를 잘 전달하기 위해 가중치가 비슷한 값을 가지도록 제한함.
