머신러닝
1.머신러닝이란?
머신러닝이란? 머신러닝(Machine Learning)은 인공지능의 분야의 하나로써 기존 컴퓨터 시스템이 미리 정해 놓은 알고리즘에 따라서 작동하는 것과 다르게 기계 스스로 패턴 및 추론을 거쳐 작업을 할 수 있는 알고리즘 및 통계 모델과 관련한 연구입니다. 예를 들어
2.k-최근접 이웃 알고리즘을 이용하여 분류하기
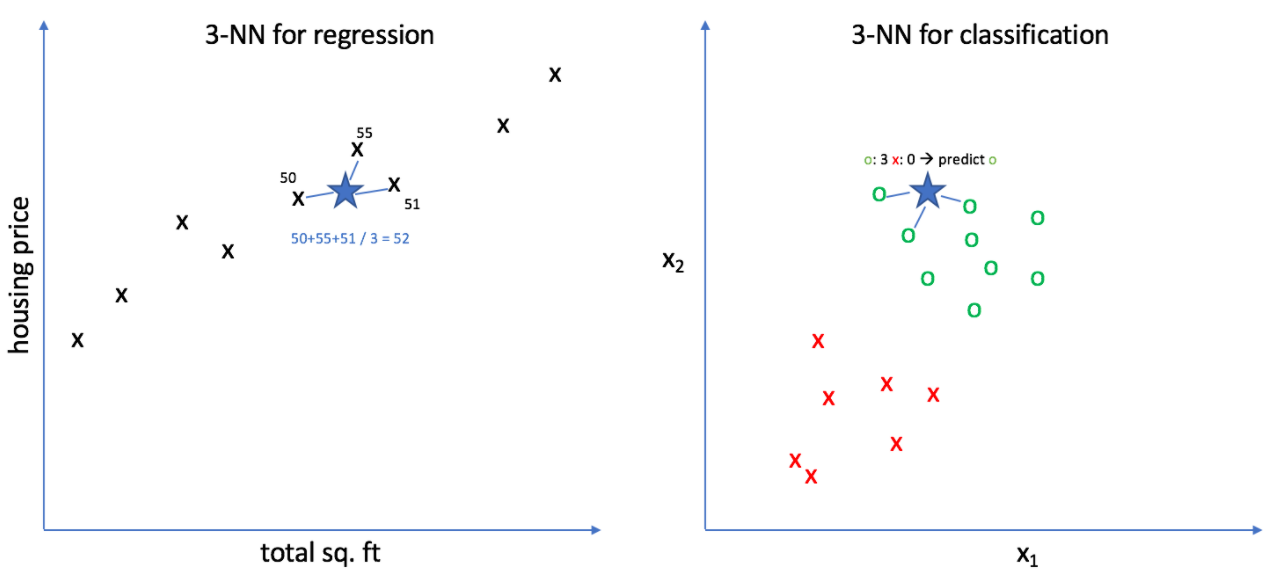
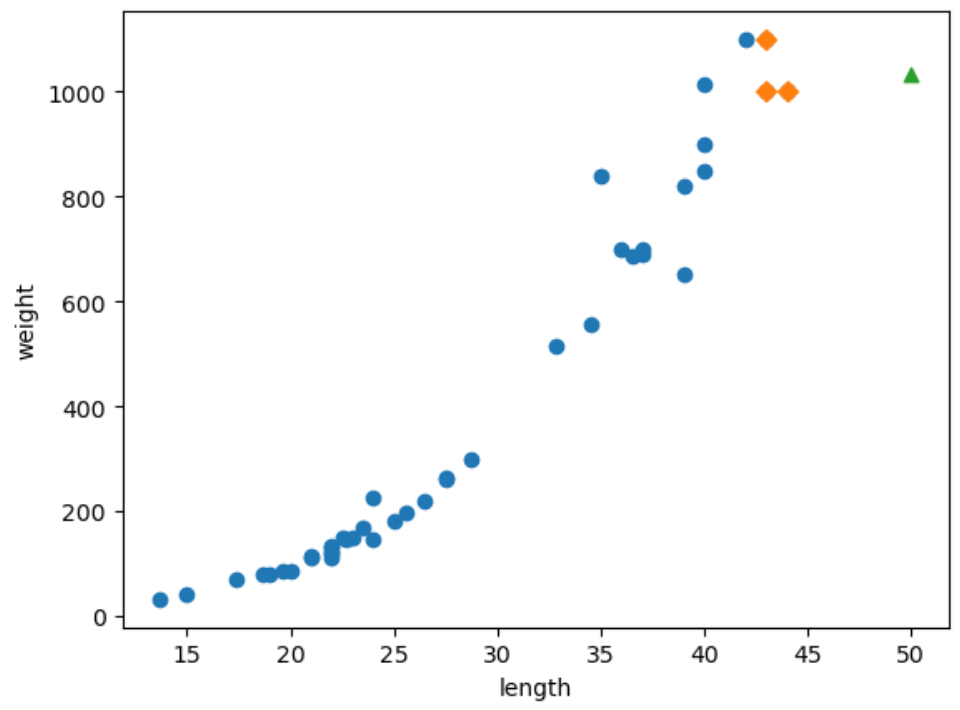
이전 블로그 내용총 49개마리의 생선의 길이와 무게에 대한 데이터가 있다.49마리의 생선 중 35마리는 도미(1), 14마리는 빙어(0)이다.해당 데이터는 Kaggle에 공개된 데이터셋이다. Kaggle의 생선 데이터셋사이킷런의 KNeighborsClassifier의
3.선형 회귀 및 다항 회귀(1)
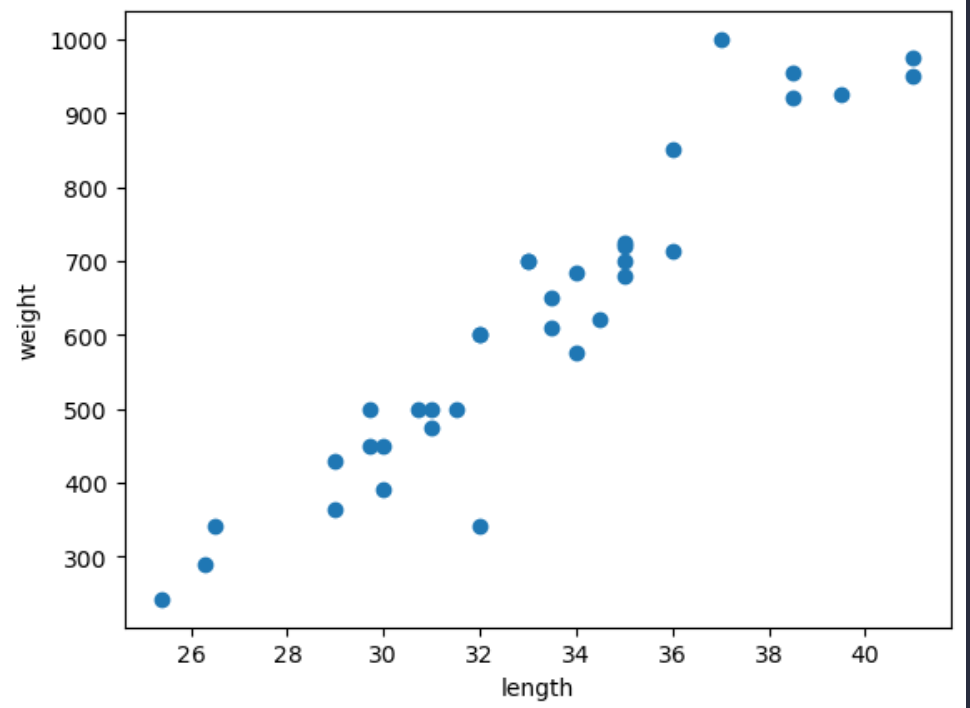
이전 글이 전에는 생선의 길이와 무게의 데이터를 k-최근접 이웃 알고리즘(k-Nearest Neighbors)에 학습시켜 해당 생선이 어떤 생선인지 분류하는 작업을 하였다.이번에는 생선의 피처(feature)를 이용하여 해당 생선의 무게를 예측하는 회귀(Regressi
4.선형 회귀 및 다항 회귀(2)
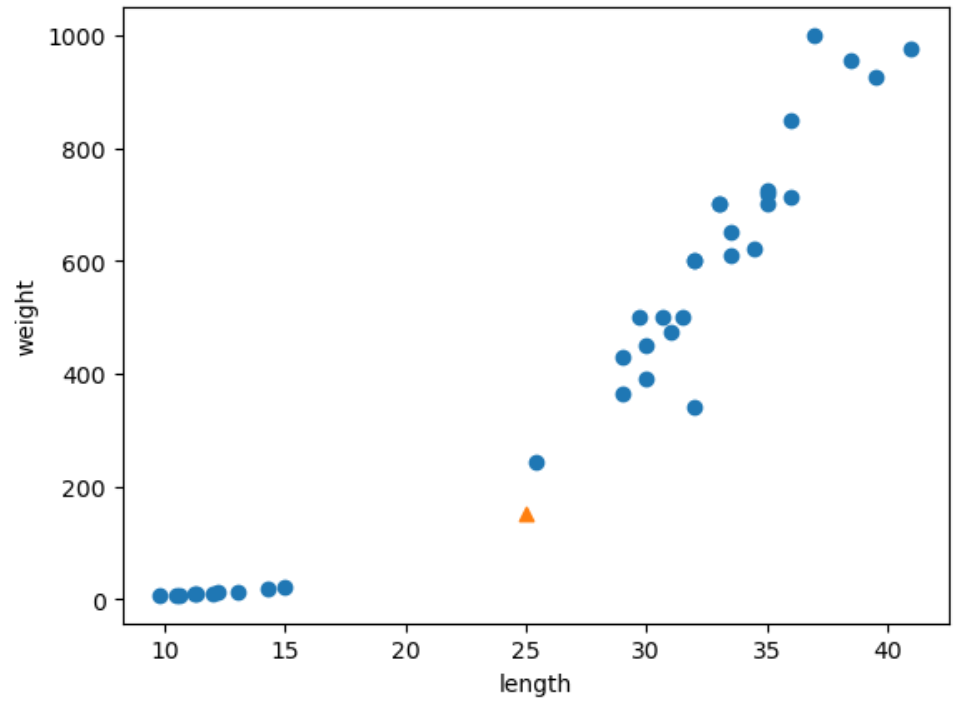
이전 글: 선형 회귀 및 다항 회귀(1)이전에는 학습용 데이터셋으로 모델 회귀모델 학습 후, 테스트용 데이터셋으로 해당 모델을 평가하였다. 이번에는 테스트용 데이터셋이 아닌 새로운 데이터셋을 모델에 넣어 무게를 예측해보자. 길이가 50cm, 무게가 1500g인 농어가
5.선형 회귀 및 다항 회귀(3)
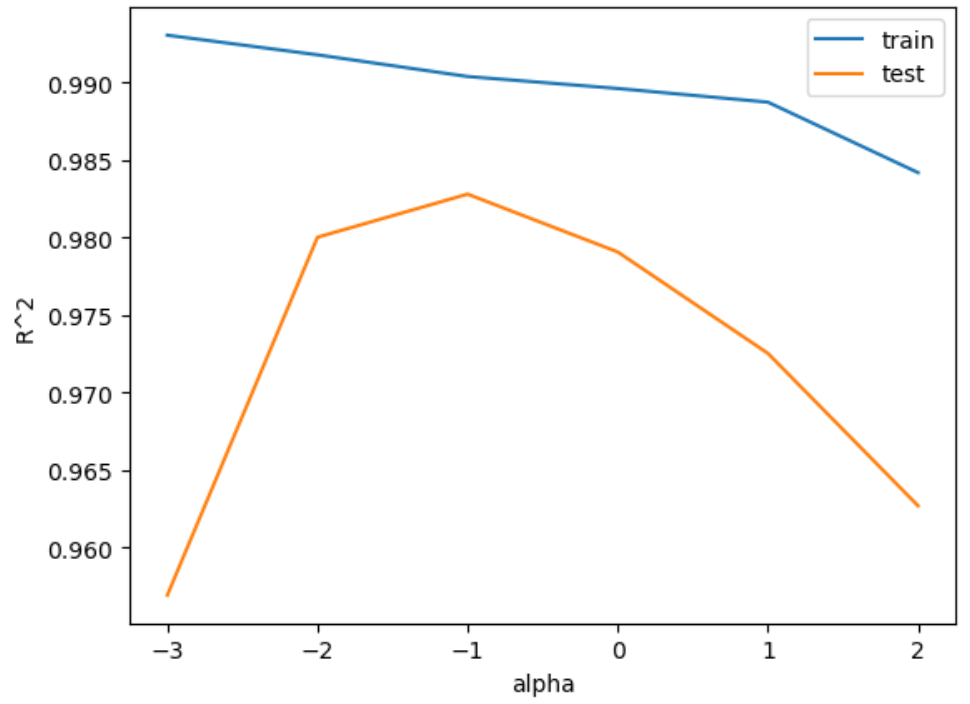
이전 글: 선형 회귀 및 다항 회귀(2)이전 글에서는 농어의 길이와 무게를 회귀 모델에 학습시킨 후, 새로운 농어의 길이 데이터를 입력한 후, 해당 농어의 무게를 예측하는 작업을 하였다.하지만 학습시키는 데이터가 다양할 수록 더욱 더 정확하지 않을까?이번에는 농어의 길
6.로지스틱 회귀
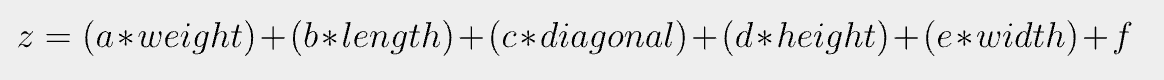
로지스틱 회귀는 이름은 회귀지만, 분류 모델이다. 이 모델은 선형 회귀(Linear Regression)과 동일하게 선형 방정식을 학습한다.이진 분류에서 선형 방정식으로 나온 값을 확률로 변환하여 0.5이상이면 양성 클래스(1), 0.5보다 작으면 음성 클래스(0)으로
7.확률적 경사 하강법
확률적 경사 하강법은 대표적인 점진적 학습 알고리즘이다.확률적 경사 하강법은 마치 산 꼭대기에서 경사를 따라 내려가는 방법이다. 모든 방법들 중 가장 빠른 길이 경사가 가장 가파른 길이다.경사를 내려올 때 가장 가파른 길을 찾아 내려오는 것도 중요하지만, 조금씩 내려오
8.결정 트리 (Decision Tree)
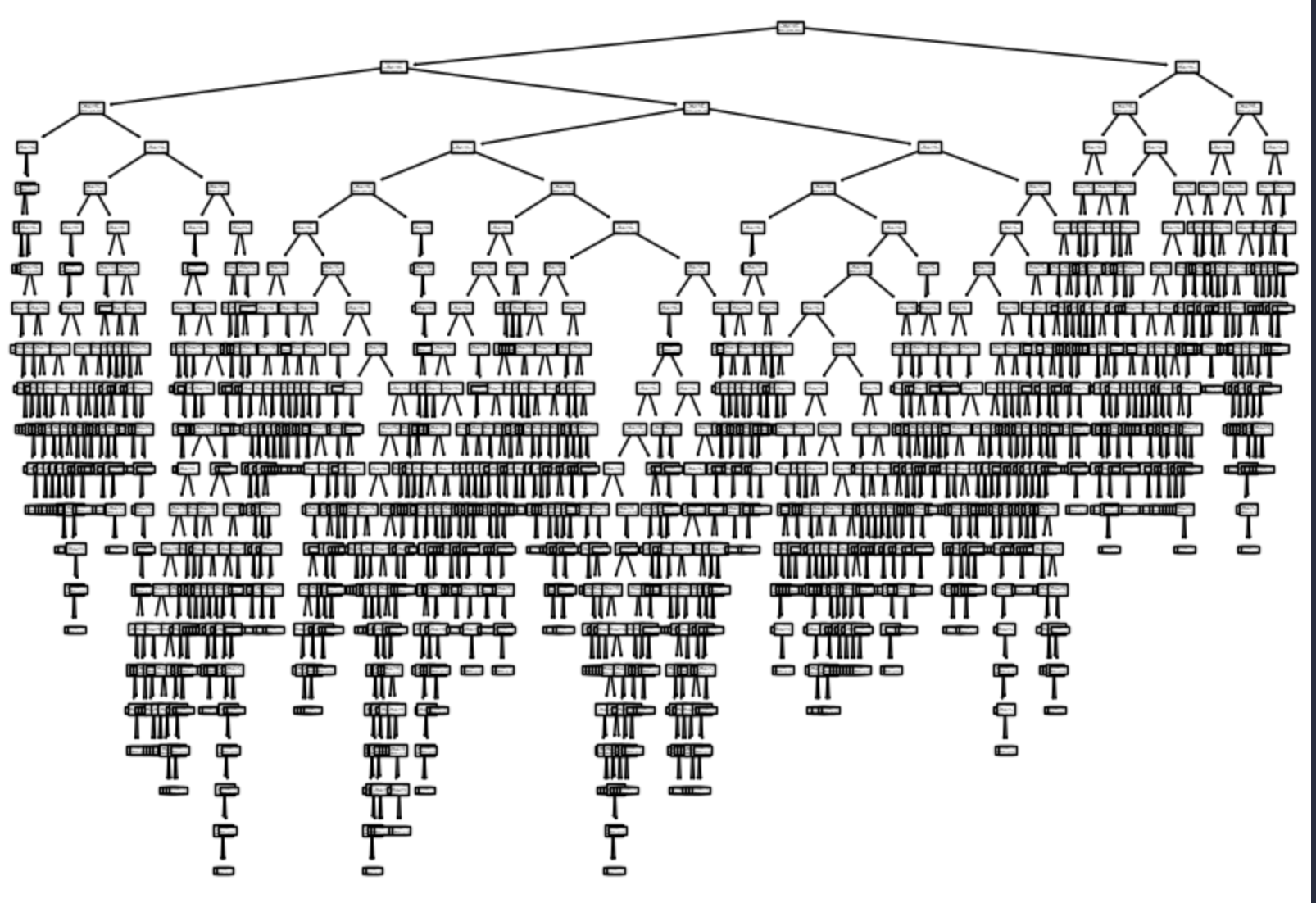
알코올 도수, 당도, PH값의 정보가 있는 총 6497개의 와인에 대한 데이터가 있다. 피처 값인 알코올 도수, 당도, PH값으로 해당 와인이 레드 와인인지, 화이트 와인인지 로지스틱 회귀(Logistic Regression)으로 예측해보자.데이터를 종속변수 X와 독
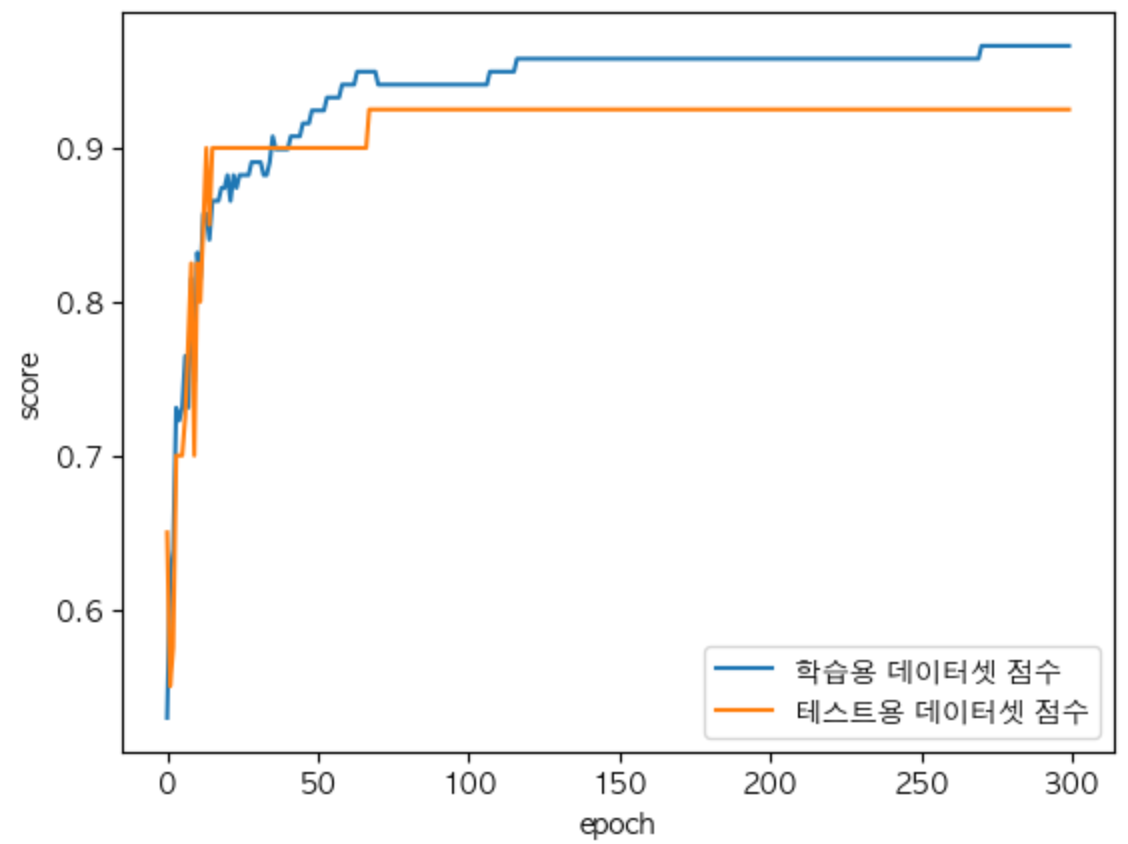
9.교차 검증과 그리드 서치
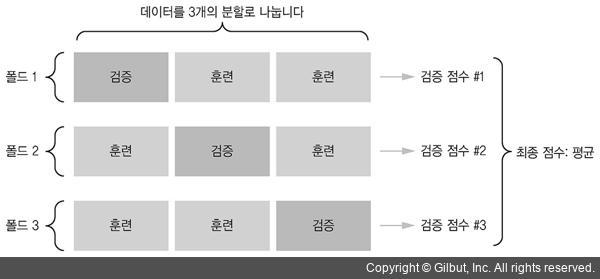
이전 글이 전에 학습용 데이터셋을 기준으로 잘 맞게 학습시켜 만든 모델을 과대적합된 모델이라 하였다. 하지만 테스트용 데이터셋으로만 평가하면 결국 테스트용 데이터셋에 잘 맞는 모델이 만들어지는 것이 아닌가?테스트용 데이터셋은 모델을 구현 후 마지막에 딱 한 번만 사용하
10.트리의 앙상블

정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이 앙상블 학습(ensemble learning)이다. 이 알고리즘은 대부분 결정 트리를 기반으로 만들어져 있다. 랜덤 포레스트(Random Forest) 랜덤 포레스트는 앙상블 학습의 대표적인 모델로 안정적인
11.트리의 앙상블
정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이 앙상블 학습(ensemble learning)이다. 이 알고리즘은 대부분 결정 트리를 기반으로 만들어져 있다.랜덤 포레스트는 앙상블 학습의 대표적인 모델로 안정적인 성능을 보인다. 이름 자체로 유추할 수 있듯
12.군집 알고리즘
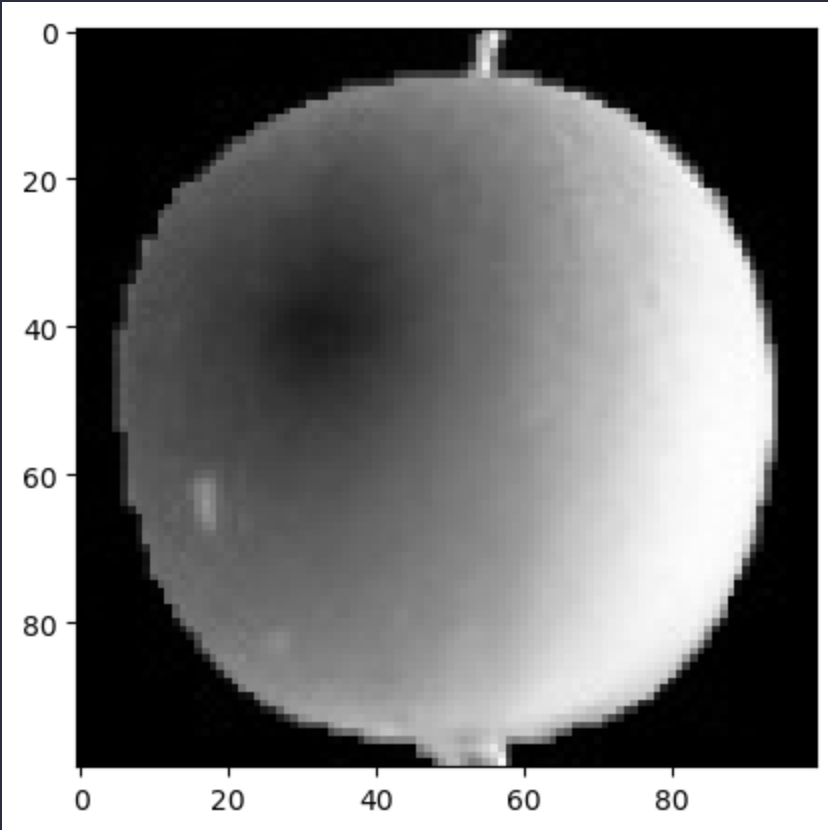
고객이 마트에서 사고싶은 과일 사진을 보내면 그 중 많이 요청하는 과일을 판매 품목으로 선정하려고 한다. 또 1위로 선정된 과일 사진을 보낸 고객 중 몇명을 뽑아 이벤트 당첨자로 선정할 것이다. 그런데 고객이 보낸 사진을 사람이 하나 하나 모두 분류하기는 어려워 보인다
13.k-평균
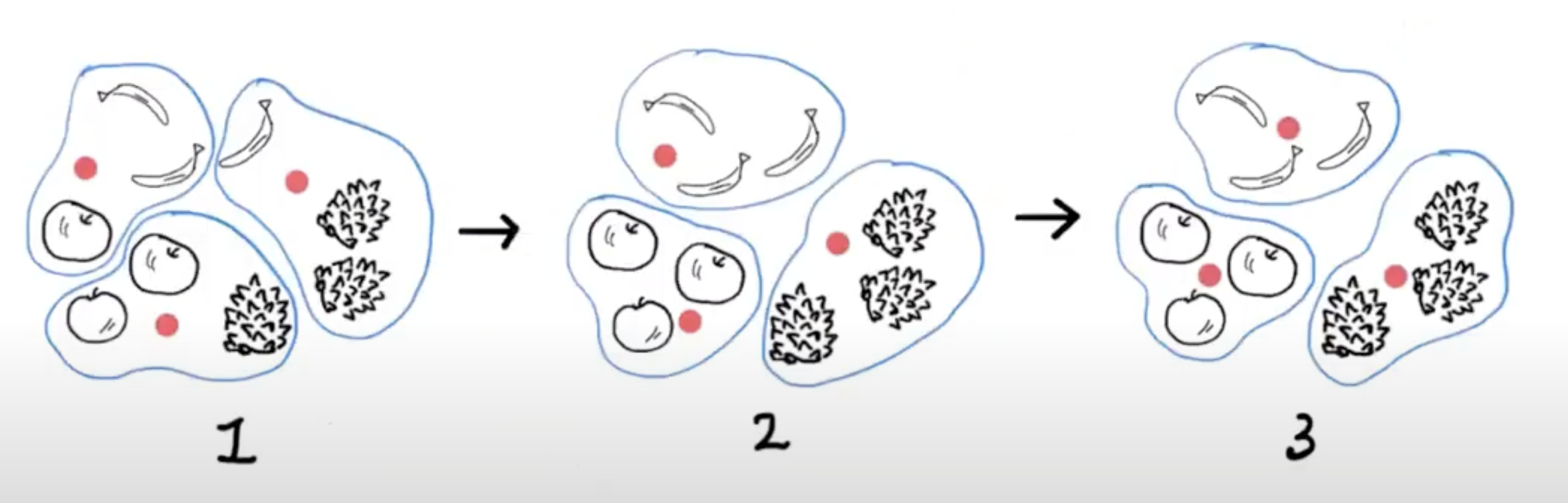
지난 글지난 글에서는 사과, 파인애플, 바나나에 있는 각 픽셀의 평균값을 구해서 가장 가까운 사진을 골랐다. 이 경우에는 사과, 파인애플, 바나나 사진임을 미리 알고 있었기 때문에 각 과일의 평균을 구할 수 있었다. 하지만 진짜 비지도 학습에서는 사진에 어떤 과일이 들
14.주성분 분석(PCA)
과일 사진 이벤트를 위하여 고객들이 보낸 여러 개의 이미지를 받아 k-평균 알고리즘으로 분류 후 폴더별로 저장한다. 그런데 너무 많은 사진이 등록되어 저장 공간이 부족하다. 나중에 군집이나 분류에 영향을 끼치지 않으면서 업로드된 사진의 용량을 줄일 수 있을까?지금까지
15.MFCC
MFCC(Mel Frequency Cepstral Coefficients)란 음성 및 오디오 신호 처리에서 대표적으로 사용하는 기술이다. MFCC는 음성데이터를 특징백터화해주는 Algorithm이다.사람은 음성을 인식할 때 달팽이관에서 각기 다른 주ㅜ파수를 감지한다.
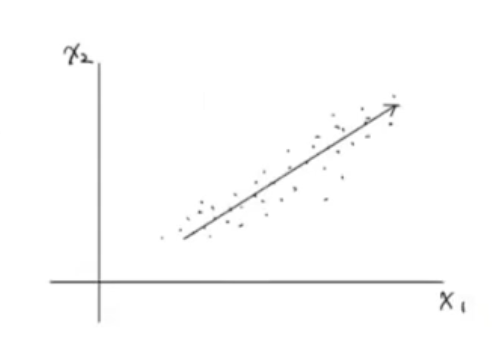
16.Support Vector Machine
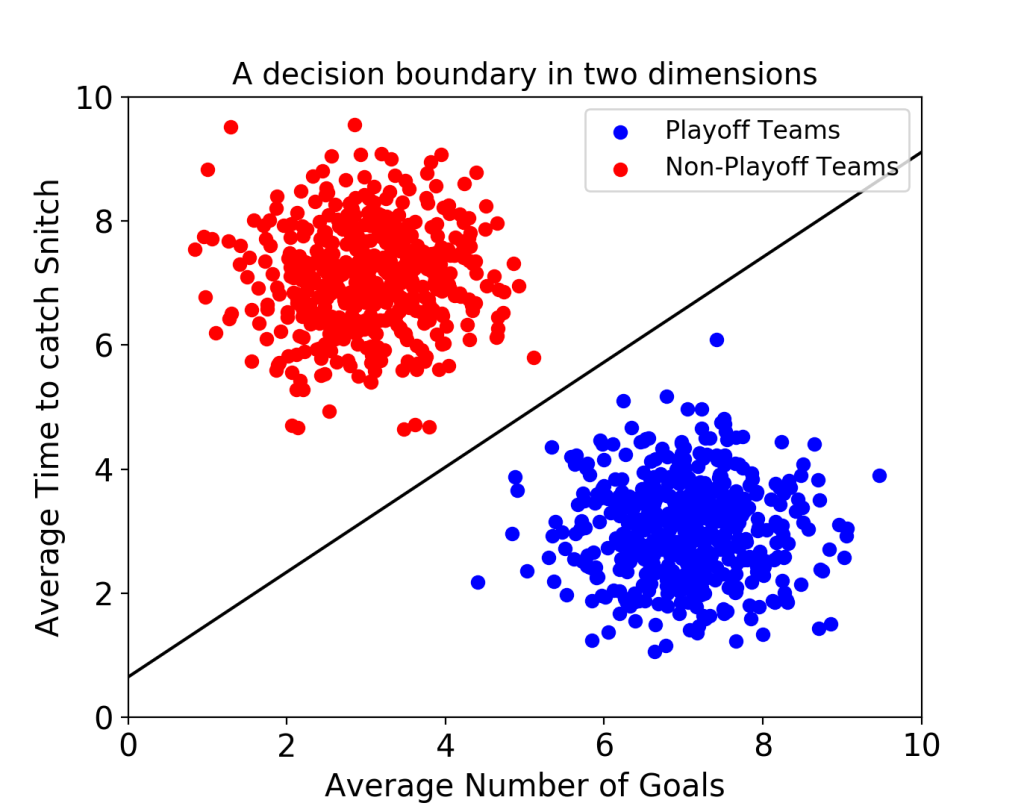
Support Vector Machie은 Classfier에서 사용할 수 있는 강력한 머신러닝 모델이다.Support Vector Machie(SVM)은 결정 경계(Decision Boundary)를 정의하는 모델이다.다음 군집을 이루고 있는 데이터의 결정 경계는 다음