키워드
실제 데이터에 SQL을 이용해 데이터 분석 해보기
Indian Redtaurant Dataset
- 인도 내 식당들의 정보
- 식당 이름, 평점, 평균 가격, 패스트푸드 Y/N, 길거리 음식 Y/N 등
- 데이터가 숫자 타입일 땐 히스토그램이 제공됨 (캐글에서)
- 다른 사람들의 EDA(탐색적 데이터 분석)를 확인할 수 있음 → 어떤 데이터인지 분석해둔 것
- count(1)과 count(distinct name)을 비교해봄으로써 중복 데이터가 있는지 확인해볼 수 있음
- 갑자기 헷갈렸던 건데, count(*)는 NULL을 포함하며, count(컬럼명)은 NULL을 제외한다.
- 즉 중복은 distinct를 사용하면되고, NULL 값을 포함해 count하고싶다면 count(1) 혹은 count(*)를 사용하면 될 듯하다.
- count(distinct name, loc, fast_food)와 같이 사용해 여러 컬럼의 조합에서 유니크한 값만을 확인할 수도 있다.
- 행끼리 구분할 수 있는 unique한 key가 이 데이터엔 없음
- 점포 이름이 하나인 레스토랑을 단일 점포로, 2개 이상인 레스토랑을 프랜차이즈로 가정
SELECT restaurant_name, count(1) as cnt, avg(rating) as avg_rating, avg(average_price) as avg_price, avg(average_delivery_time) as avg_delivery_time
FROM restaurant
GROUP BY 1
ORDER BY 3 DESC
LIMIT 20;- 레스토랑 이름을 기준으로 분석을 진행
- 평점 상위 20개를 뽑아봤을 때 모두 지점 갯수가 하나였음 (단일 점포)
- order by desc 하고 limit을 걸어 상위 n개의 데이터를 조회함
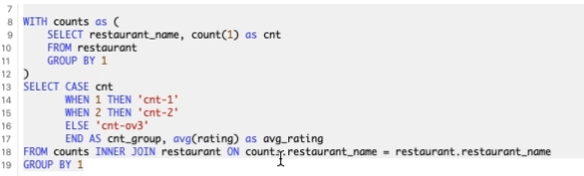
- 점포 갯수 별로 평점에 차이가 있는지 확인함
- with를 써서 레스토랑 별 카운트를 조회한 테이블을 만들어 서브쿼리를 없애고, case문을 사용해 특정 조건 별 값을 매김
- 만약 case문 대신 if문을 사용한다면 중첩으로 인해 보기 어려워지겠군… CASE를 사용하는 게 가독성이 좋겠다. 잘 기억해두자.
- 확인해보니 오히려 평균적으론 점포 갯수가 많아질 수록(프랜차이즈일 수록) 평점 높아짐
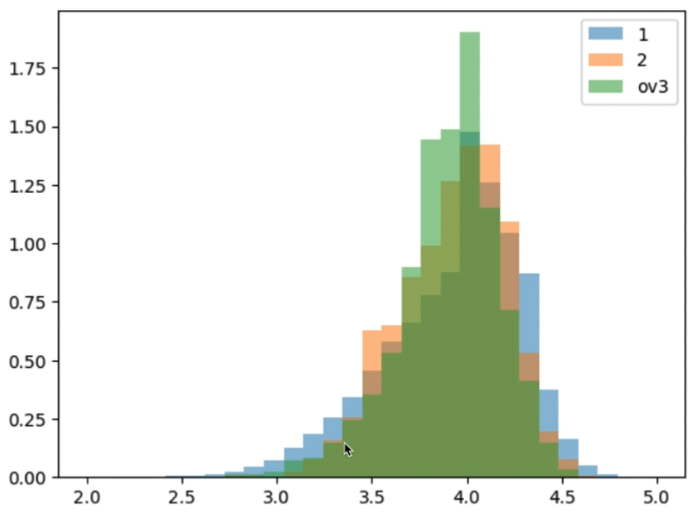
-
단일 점포는 점포마다 서비스와 품질이 달라 양 극단의 값이 더 많으며(더 퍼져있음), 프랜차이즈의 경우, 적절히 높은 품질을 제공하고 식당 간 편차가 적기 때문에 가운데로 몰려있음
-
우리가 알고있는 상식과 분석이 일치
-
수치형 계수와 별점 간의 상관계수 분석
-
상관계수만 봐서 분석은 어려울 수 있음. 복합적인 요소가 작용할 수 있기 때문에.
-
SQL로도 상관계수를 구할 수 있으나 스프레드시트 혹은 파이썬을 이용하는 게 더 쉽다.
- =CORREL()을 사용해 피어슨 상관계수를 구할 수 있음
-
|상관 계수|가 0.7 이상이어야 해당 값이 의미 있다고 봄
-
가정
- 패스트푸드점일 경우 배달 시간과 평점 사이 상관계수가 높을 것이다
- 대도시와 소도시 각각에서의 별점과 (가격/배달 시간) 간의 상관 계수가 차이가 있을 것이다.
-
꼬리에 꼬리를 무는 궁금증을 데이터 분석으로 확인해보기!
-
지역별 평균 가격, max 가격, 점포 갯수등을 확인해보기
- 평균값은 아웃라이어의 영향을 많이 받기 때문에 max값도 같이 확인해보면 좋다.
- 만약 max값이 너무 크면 평균값이 아웃라이어의 영향을 많이 받았을 것.
- 또한 갯수도 함께 확인해 평균의 의미가 있는지!도 같이 보면 좋겠다.
- max값이 엄청 높은게 아닌데 평균값이 높은 걸로 보아 실제로 평균적으로 가격이 높은 지역임을 알 수 있음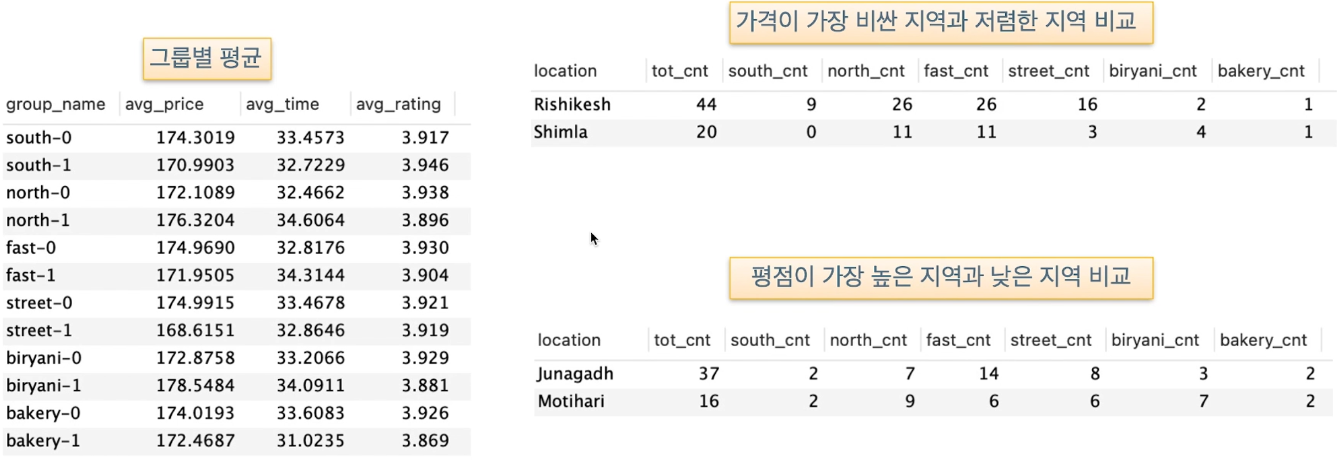
-
- 가격과 평점에 영향을 주는 변수 확인
- 상관계수 사용
- 프랜차이즈 여부에 따른 별점의 분포 확인
Global AI, ML, Data Science Salary
- 글로벌 AI, ML, Data Science 등의 직군 연봉
- 각 컬럼에 대한 설명이 나와있음
SELECT remote_ratio, AVG(salary_in_usd) as usd_salary
FROM salary
WHERE work_year in (2022, 2023) --2020, 2021 데이터가 많지 않아 필터링
GROUP BY 1
ORDER BY 2-
특정 컬럼 별 평균 연봉 확인
-
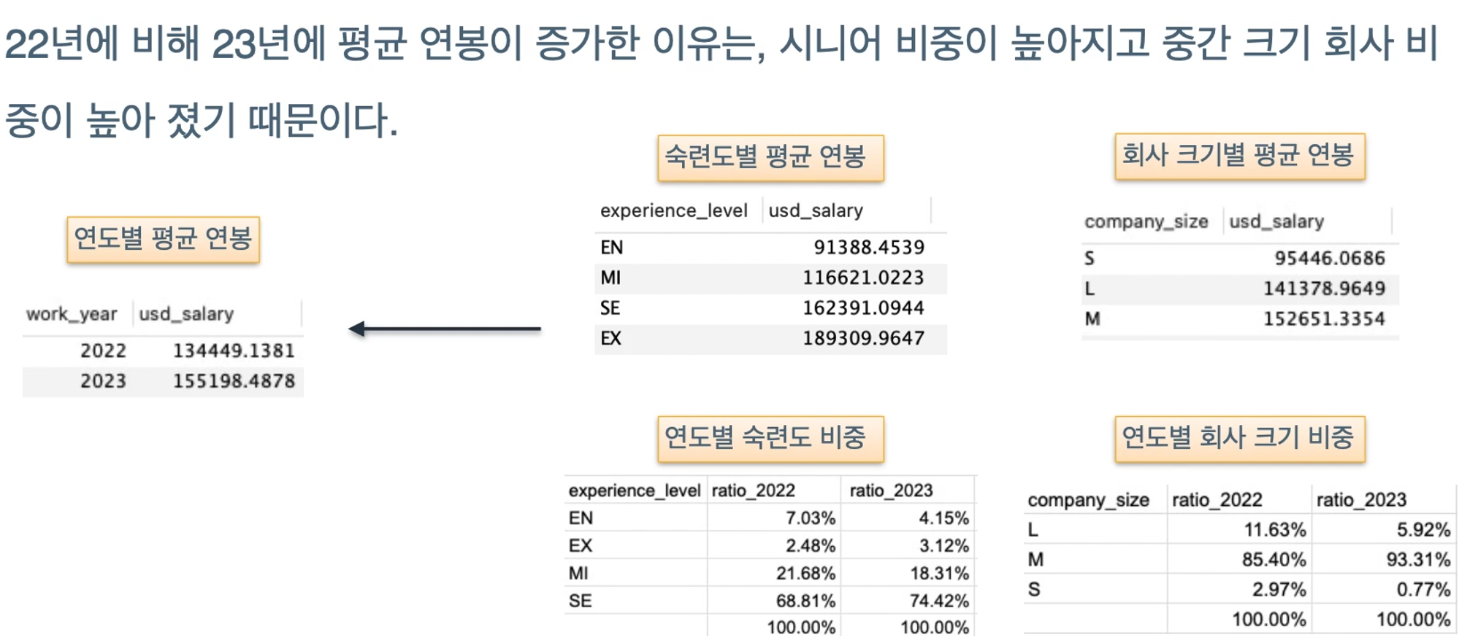
연도 별 평균 연봉의 변화 확인 → 뒤로 갈수록 연봉 오름!
-
근데 연도 별 experience level의 변화를 확인해보니 2023년도가 2022에 비해 고연봉 연차들의 비율이 높음.
-
즉, 연봉이 전체적으로 증가한 게 아닌 고연봉 연차가 늘어남으로써 평균 연봉이 늘어난 것으로 볼 수 있다.
-
또한 연봉이 가장 높은 중간 크기의 회사의 비율이 커짐
-
하나의 데이터만 보고 해석하면 안됨…
-
-
재택 근무 비율 확인
- 2022년에 비해 2023년에 재택 근무 비율이 낮아짐
- 시니어가 많아졌는데, 시니어가 재택 근무를 덜 함
- 작은 사이즈의 회사가 재택근무 비율이 높았는데 작은 사이즈의 회사 비율이 줄어듬
- 미국 바깥에서 근무하는 직원(재택근무 비율이 높음)의 비율 감소
- 2022년에 비해 2023년에 재택 근무 비율이 낮아짐
-
직군 별 평균 연봉
- CASE 문으로 각 직군을 크게 나누고 평균 연봉 확인
-
그룹별 평균 비교, 연봉에 영향을 주는 변수 확인
NBA Players
- 농구 선수에 관한 데이터
WITH base as(
SELECT season, player_name, rank() over (PARTITION BY season ORDER BY pts DESC) as rank, pts
FROM nba
)
SELECT season, AVG(pts) as pts
FROM base
WHERE rank <= 10
GROUP BY 1
GROUP BY 1- partition by를 이용해 시즌 별로 pts에 따라 랭킹을 매김
- 시즌별 랭킹 10위 이내 선수들의 평균 득점 수
- 10위 내 선수들은 1위 선수들과 비교했을 땐 평균 득점수가 낮다.
- 시간의 흐름에 따른 평균 신장, 몸무게, 게임 수와, 상위권 선수들의 지표를 확인해봄
- 드래프트 1라운드, 10순위 이내에 뽑힌 선수들의 키와 나이 추세 감소
❗ 실제 데이터분석 시
특징을 찾고 → 가설을 세우고 → 다시 데이터로 돌아가 관계와 근거를 찾음
분석을 통해 무엇을 얻어낼 수 있는지…
목표가 불분명할 땐 목표를 구체화 하며 분석하는 것도 필요
강의 요약
- 원하는 형태로 데이터를 가져오고, 간단한 데이터분석을 수행하기 위해 SQL 사용
- 관계형 DB는 행/열/테이블로 이루어진다.
- SELECT, FROM, WHERE
- GROUP BY, ORDER BY, AVG, SUM, COUNT, HAVING
- CONCAT, SUBSTR, CHAR_LENGTH, ROUND, ABS, MOD, COALESCE
- CREATE(테이블, 뷰 생성), ALTER(수정), DROP(삭제)
- SELECT, INSERT(데이터 추가), UPDATE, DELETE
- JOIN, UNION, WITH, Subquery
- 타임 스탬프 함수(데이터 타입, 추출, 날짜 형식화, 연산)
- CAST, CONVERT
- IF, CASE WHEN
- RANK → 파티션을 나눠(ex 날짜마다, 연령대마다) 랭킹을 할 수 있음
- 문자, 숫자
- JSON_EXTRACT, ARRAY
- 효율적인 SQL 쿼리 작성
- 세가지 데이터 셋 분석
여담
- 레퍼런스 (캐글, 아티클 등)
- 문제 정의, 어떤 지표로 문제의 원인을 파악하려 했는지. 분석 플로우를 참고하면 좋다.
- 프로젝트
- 통계와 머신러닝 지식 습득
