키워드
쿼리 작성 시 효율 높이는 방법
테이블을 집합으로 생각하기
- where로 테이블을 최대한 작게 만들어놓고 JOIN하기
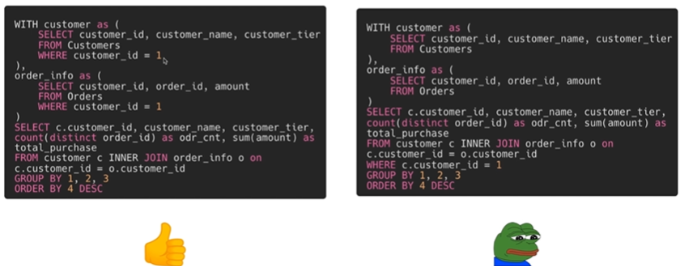
- 고객 한 명을 보려고 할 때 join전 where절을 이용해 미리 걸러놓고 join하면 비용이 훨씬 감소함
*, % 사용 지양하기
❗잘 모르는 테이블 사용시
큰 데이터를 조회하거나 연산함으로써 생길 수 있는 비용 문제를 막고자 함임.
- LIMIT 걸고 조회하기
- 행 수가 엄청난 데이터를 모두 조회하려할 때 비용이 엄청 클 것.
LIMIT 10과 같이 조회 데이터 수를 제한하고 확인하기
- 파티션이 있는 테이블인지 확인 후 파티션을 필터 조건으로 걸고 조회하기
- 날짜 기준으로 데이터를 확인한다든지..
- 파티션이 무엇인가!
- 컬럼 수가 많은 테이블을 조회할 때 * 지양하기
- 컬럼 지정해 조회
- 이 또한 비용 문제를 일으킬 수 있음
- LIKE 사용 시 % 제한적으로 사용하기
- %: 임의의 문자열을 의미한다.
- %를 하나 이용하는 것과 두개 이용하는 것 조차도 차이
- 규칙을 최대한 좁혀서 사용하기
데이터 타입 잘 확인하기
- 비교 연산자를 쓸 때 타입 확인하기
- mysql은 묵시적 형변환을 지원 (자동 타입 캐스팅)
- 형 변환에 걸리는 시간만큼 쿼리가 비효율적이어짐
- 원하는 결과를 얻지 못했을 때 문제 원인을 찾아내는 데 오랜 시간이 걸림
- 즉 데이터 타입과 동일한 타입으로 비교하면 형 변환이 일어나지 않으므로 그만큼 시간이 덜 걸리며, 데이터를 사용 전에 데이터에 대해 파악하고 있는 것은 매우 중요한 것 같다.
- WHERE 절에서 왼쪽 컬럼에 함수 적용 지양하기
- 인덱스를 사용할 수 없어짐
- 인덱스는 데이터의 읽기 속도를 빠르게 해줌
- 여기서 인덱스라는 게 뭘까… 인덱스를 사용한다는 게 어떻게 하는걸까?
- 그리고, 함수를 적용해야한다면 상대적으로 작은 테이블의 컬럼에 적용하는게 낫다.
- 왼쪽 컬럼이라는 말이 뭔지 모르겠다. 오른쪽 컬럼이랑 뭐가 다른거지?
- 인덱스를 사용할 수 없어짐
JOIN 시 유의할 점
- JOIN은 연산량이 큼
- 그렇기 때문에 join할 테이블의 양을 줄여놓고 시작하는 게 좋다.
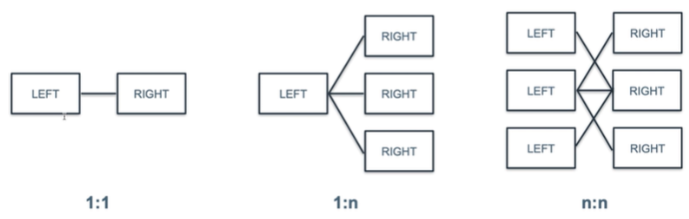
- 1:1
- 직원 테이블과 팀 별 테이블
- 두 테이블 중 더 작은 테이블 행 수 기준으로 병합됨
- 1:n
- 구매 이력, 클릭 이력 테이블
- n:n
- 대학생 테이블과 동아리 테이블
- join 시 두 테이블의 조합 수로 늘어남-
데이터 중복이 있는지 확인하기
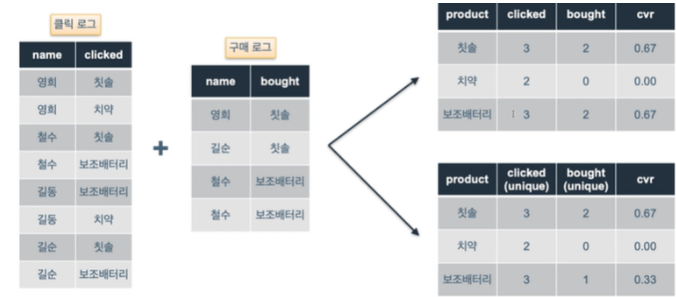
- 상품별 (구매/클릭)의 비율
- 철수가 보조배터리를 두 번에 걸쳐 구매했으므로 join 된 위 테이블은 의도와 다를 수 있음
- 즉 구매 로그에 중복 데이터가 있었기 때문에 원치 않은 결과가 나온다.
- 근데 왜 철수가 2번 구매한 걸 중복이기 때문에 무시해야하는거지?
-
여러가지 쿼리 방식을 고려하자
- 예를 들어 where절을 이용한 쿼리와 inner join을 이용한 쿼리의 결과는 같으나 시간은 굉장히 많이 차이남
가독성 높이기
- 서브 쿼리보다는 WITH 구문이 가독성이 좋다.
WITH odr_cnt AS( SELECT ~ FROM Customer GROUP BY 1 ORDER BY 1,2 ) -- 이렇게 with 이용 후 아래 쿼리 작성 시 테이블처럼 odr_cnt 이용 가능 - WITH 절을 사용할 때, 각 블록 이름을 잘 지정하자
- 쿼리가 복잡해지면 중간중간 주석을 작성하자.
궁금한 점
❓ 파티션이 무엇인가
- “테이블에 있는 특정 컬럼 값을 기준으로 데이터를 분할해 저장해 놓는 것”이라고 한다.
- 즉 한꺼번에 데이터를 몰아놓기 보다는 날짜별로 데이터를 분할해놓는다던지 함으로써 효율성을 높이고자 하는 것 같다.
❓ 왼쪽 컬럼이라는 게 뭘까
- 컬럼에 함수를 적용하지 말고 고정된 문자(우측)를 좌측 타입에 맞게 변경해야한다는 말인가?
- where절에서 컬럼은 좌측에만 올 수 있는가보다, 그래서 왼쪽 컬럼이란 말을 사용하신거고.
- 아 내가 착각하고 있는 문제가 있었다. 그래서
WHERE 'Python' in (option_1, option_2)와 같이 우측에도 컬럼명을 사용할 수 있는 줄 알고있었다. - 어찌됐든! 이 말은 where절의 좌측에 오는 컬럼에 함수를 사용하는 것을 지양할 것! 웬만해선 우측의 값을 좌측 타입에 맞출 것!
❓ where절에서 좌측의 컬럼에 함수를 사용하면 인덱스를 사용하지 못한다고 했는데, 여기서 인덱스가 무엇인지
❓ 클릭 대비 구매 비율을 구하는 과정에서 철수가 같은 상품을 두 번 구매한 이력을 한 번으로 쳐야하는 이유가 뭘까
❓ 만약에 어떤 연산을 하고(ex count) limit 10을 한다면, 모든 데이터에 대해 연산을 하고 10개만 보여주는 건가? 그러면 LIMIT을 거는게 더 효율성이 있는 게 맞을까?
