
NoSQL의 등장 배경
모놀리틱 아키텍처
전체 애플리케이션을 하나의 통합된 패키지로 개발, 배포하는 방식
- 작은 규모의 프로젝트나 애플리케이션에서 운영 쉬움
- 서비스 규모가 확장되면서 유지보수의 복잡도 증가
- 한 개의 시스템에 문제가 발생하면 전체 시스템의 장애로 이어짐
- 하나의 모듈을 수정하면 전체 애플리케이션 다시 배포해야하며 배포 시간 길어짐
- 요구 사항 변경에 유연하게 대처하기 힘듦
- 하나의 시스템에서 리소스가 부족해 확장이 필요하면 전체 시스템을 확장할 수 밖에 없어 리소스 낭비
마이크로서비스 아키텍처
독립된 각각의 모듈을 조립해 하나의 서비스를 만드는 아키텍처
기능별로 작게 나뉘어진 서비스가 독립적으로 동작하는 서비스
- 새로운 기능을 추가해 배포하는 것이 비교적 편리해 요구사항에 민첩하게 대처 가능
- 서비스 확장이 필요할 때 원하는 서비스만 업그레이드 가능해 서비스 관리 유연
- 서비스 간의 독립성으로 인해 한 서비스에서의 문제가 다른 서비스에 영향을 주지 않아 운영의 안정성 향상
- 소규모 팀에서는 서비스 분리로 인한 관리의 복잡도와 운영 부담 증가
데이터 저장소 요구 사항의 변화
- 모놀리틱 아키텍처에서는 중앙 집약적인 관계형 데이터베이스(RDBMS)가 표준
- 최근 서비스에서 비정형 데이터(다차원적, 깊은 계층 구조) 증가 ➡️ 관계형 데이터베이스의 정형화된 테이블에서는 관리 어려움
- NoSQL의 경우 개발 팀이 바로 데이터 구조를 바꿀 수 있어 더 빠른 개발 가능
마이크로서비스 아키텍처에서 가장 중요한 것은 각 서비스가 독립적으로 동작할 수 있도록 하나의 서비스가 다른 서비스들과 밀접하게 연관되지 않아야 한다는 것!
- 마이크로서비스 아키텍처의 각각의 서비스는 스스로의 상태를 유지해야 하고, 독립된 데이터 저장소 필요
NoSQL이란?
SQL을 사용하지 않는 데이터 저장소
- 관계가 정의되어 있지 않은 데이터를 저장
NoSQL의 특징
1. 실시간 응답
- 마이크로서비스 내의 저장소에서는 빠른 응답 속도가 중요
- 각각의 개별 서비스가 빠르게 동작하지 않으면 서비스 자체가 병목 현상을 유발할 수 있음
2. 확장성
- 트랜잭션의 증가에 유연하게 확장
3. 고가용성
- 장애 상황에서 신속하게 복구되어 항상 사용할 수 있는 상태 유지
4. 클라우드 네이티브
- 클라우드 제공 업체에서 제공하는 DBaas(DataBase-as-a-service)를 사용하면 직접 설치, 운영할 필요 없이 설치된 상품을 바로 사용 가능
5. 단순성
- 마이크로서비스 아키텍처 서비스가 세분화 될수록 관리 포인트가 늘어나기 때문에 개발자와 운영자는 데이터 저장소를 간단하게 사용하고 싶어함
- 한 가지의 데이터 모델이 모든 서비스에 최적화되진 않기 때문에 서비스별로 적절한 데이터 모델(멀티 모델 데이터베이스) 사용을 원함
6. 유연성
- NoSQL은 비정형 데이터를 저장할 수 있는 방법 제공
NoSQL 데이터 저장소 유형
그래프 유형
- 엔티티 간의 관계를 효율적으로 저장하도록 설계됨
- 노드(node), 엣지(edge), 속성(properties)
- 저장되는 속성의 크기가 크거나 혹은 매우 많은 속성을 저장할 때에는 적합하지 않은 경우가 많음
- 추천 서비스, 사기 감지, 소셜미디어, 네트워크 및 IT 운영 등에 필요
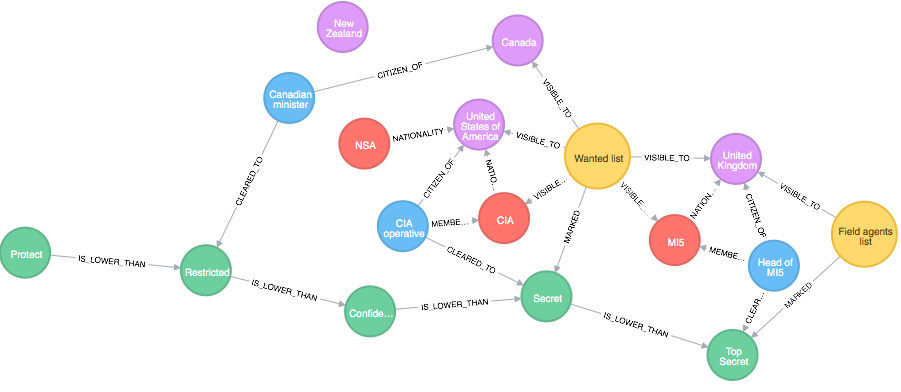
칼럼 유형
- 열(column)은 기준으로 저장
- 칼럼 지향적(column-oriented), 와이드 칼럼(wide column)
- 데이터는 하나의 열에 중첩된 키-값 형태로 저장될 수 있기 때문에 기존의 관계형 데이터베이스와 비교했을 때보다 유연한 스키마를 저장할 수 있음
- 대량의 데이터에 대한 집계 쿼리를 다른 유형보다 빠르게 처리 가능
- 기업의 BI 분석을 위한 데이터 웨어하우스, 분석, 보고, 빅데이터 처리에 적합
- Apache Cassandra, HBase 등
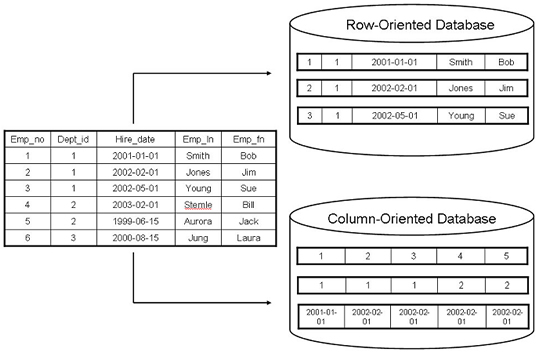
문서 유형
- JSON 형태로 데이터 저장 가능
- 스키마가 따로 정해져 있지 않기 때문에 애플리케이션에 맞게 데이터를 그대로 저장할 수 있어 유연성이 큼
- 모든 값은 항상 키와 연결되는 계층적 트리와 같은 구조를 가짐
- 데이터를 저장하거나 검색하는 데 효과적
- MongoDB, CouchDB, AWS의 DocumentDB 등
키-값 유형
- 가장 단순하고 빠름
- 모든 값은 키에 연결되어 있고, 키 자체도 유의미한 데이터
- 데이터 저장이 간단하기 때문에 수평적 확장 쉬움
- 구조의 단순성으로 인해 빠른 데이터 액세스와 처리 속도 보장
- 실시간 서비스(게임, IoT), 로그 남기는 작업, 대규모 세션 실시간 관리 등
- Redis, AWS의 ElastiCache, AWS의 DynamoDB, Oracle NoSQL Database, Memcached 등

레디스란?
Remote dictionary server
고성능 키-값 유형의 인메모리 NoSQL 데이터베이스로, 오픈 소스 기반의 데이터 저장소
레디스의 특징
1. 실시간 응답(빠른 성능)
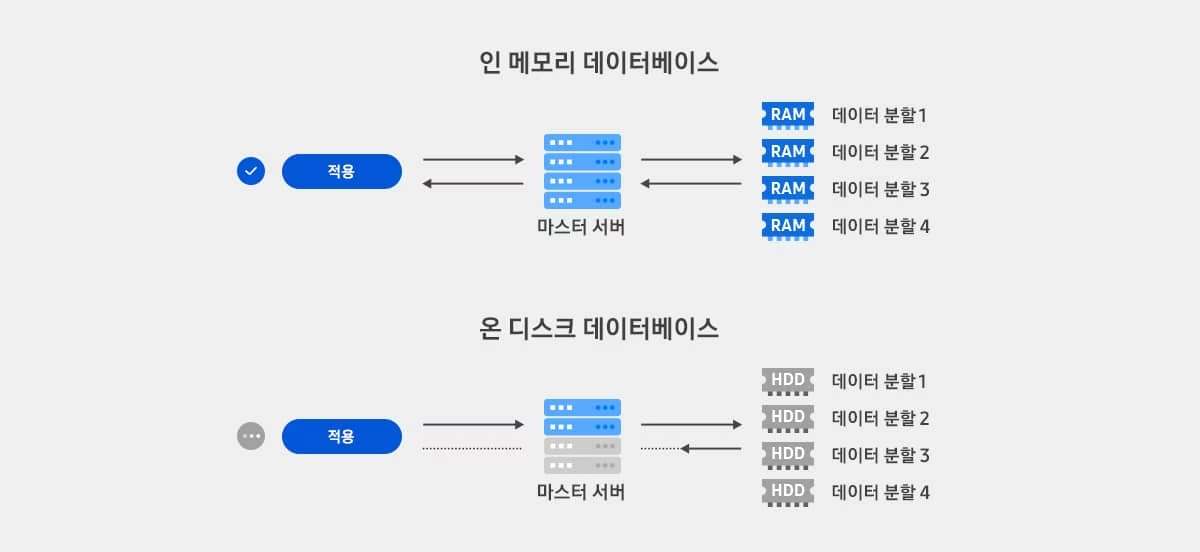
- 온디스크(disk-based) 데이터베이스: 데이터가 영구적으로 디스크에 저장됨
- 디스크에 저장된 데이터는 페이지 단위로 메모리에 올려 메모리에서 데이터를 찾고, 없는 경우 다른 페이지를 디스크에서 가져와 메모리에 올린 뒤 찾는 과정 반복
- HDD와 SSD와 같은 디스크에 접근하는 속도는 RAM과 같은 메모리에 접근하는 속도보다 현저히 느림
- 디스크에 접근하는 빈도가 증가할 수록 시스템 성능 저하
- 인메모리(in-memory) 데이터베이스: 모든 데이터가 컴퓨터의 메모리에서 관리됨
- 인메모리 데이터베이스는 디스크에 접근하는 과정이 필요 없기 때문에 데이터의 처리 성능이 빠름
2. 단순성
- 키에 매핑되는 값에는 문자열, hash, set 등 다양한 데이터 구조를 저장할 수 있도록 지원
- 문자열, hash, set과 같은 데이터 타입은 프로그래밍의 기본 자료 구조와 밀접한 관련이 있어 추가적인 데이터의 가공 없이 애플리케이션에서 쉽게 사용 가능
- 레디스는 내장된 다양한 자료구조를 통해 임피던스 불일치 해소
- 임피던스 불일치(impedance mismatches): 기존 관계형 데이터베이스의 테이블과 프로그래밍 언어 간 데이터 구조, 기능의 차이로 인해 발생하는 충돌
- 100개가 넘는 오픈 소스 클라이언트 사용 가능
- Java, Python, PHP, C, C++, JavaScript, Node.js, R, Go를 비롯한 다수의 언어 지원
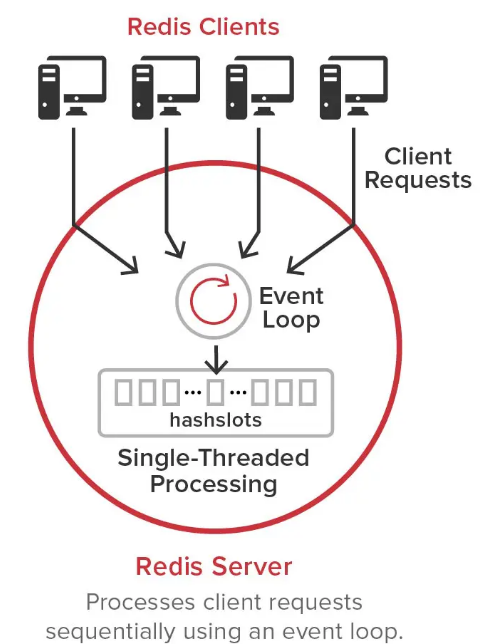
- 레디스는 싱글 스레드로 동작(메인 스레드 1개 + 별도의 스레드 3개)
- 클라이언트의 커맨드를 처리하는 부분은 이벤트 루프를 이용한 싱글 스레드로 동작
- 최소 하나의 코어만 있어도 레디스를 사용할 수 있기 때문에 배포가 쉽고, CPU가 적은 서버에서도 좋은 성능을 낼 수 있음
- 동기화나 잠금 매커니즘 없이도 안정적이고 빠르게 사용자의 요청 처리 가능
- 싱글 스레드로 동작한다는 것은 한 사용자가 오래 걸리는 커맨드를 수행한다면, 다른 사용자는 그 쿼리가 완료될 때까지 대기해야 한다는 것
- 레디스는 메모리에서 동작하기 때문에 대부분의 커맨드는 빠른 응답 시간을 갖지만 반환이 느린 특정 커맨드 존재
3. 고가용성
- 자체적으로 HA(High Availability) 기능 제공
- 복제를 통해 데이터를 여러 서버에 분산시킬 수 있음
- 센티널(sentinel)은 장애 상황을 탐지해 자동으로 페일오버(failover) 시켜줌
- 마스터에 장애가 발생하면 복제를 새로운 마스터로 승격시켜 레디스로의 엔드포인트를 변경할 필요 없이 페일오버 완료됨
4. 확장성
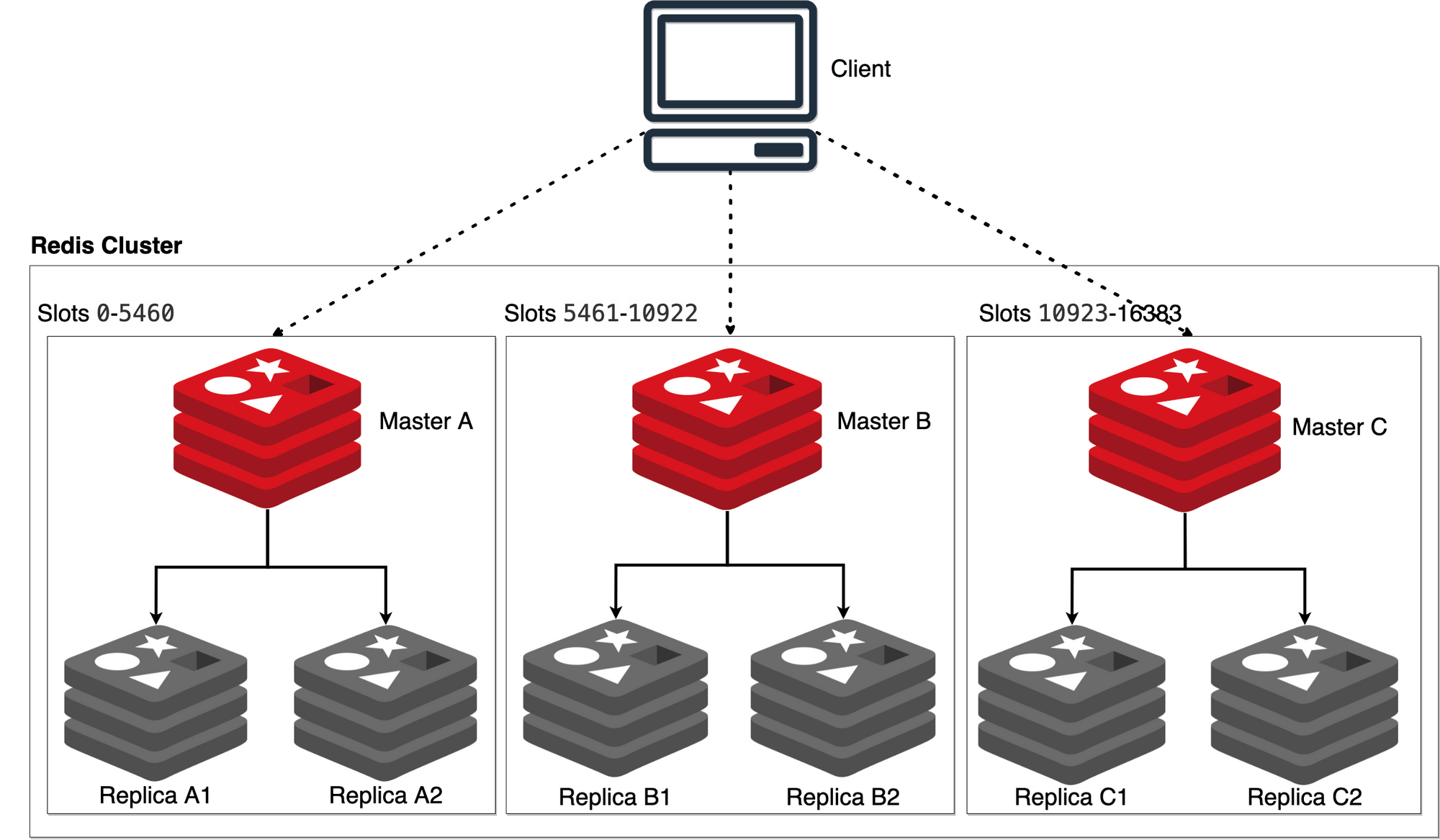
- 데이터는 레디스 클러스터 내에서 자동을 샤딩된 후 저장되며, 여러 개의 복제본이 생성될 수 있음
- 샤딩(sharding): 각 데이터를 특정 조건에 따라서 서버를 분산 저장하는 기법
- 애플리케이션에서는 대상 데이터가 어떤 샤드에 있는지 신경쓰기 않아도 됨
- 클러스터 구조에서 모든 레디스 인스턴스는 클러스터 버스를 통해 서로 감시 ➡️ 마스터 노드에 문제가 발생하면 자동을 페일오버 시켜 고가용성 유지
5. 클라우드 네이티브-멀티 클라우드
- 클라우드 네이티브
- 클라우드 환경에 특화된 애플리케이션의 개발 및 운영 방식
- 마이크로서비스, 컨테이너, 오케스트레이션, 데브옵스와 같은 현대의 개발 및 운영 패러다임 포용
- 빠른 배포와 확장성, 높은 복원력을 중심으로 한 애플리케이션 추구
- 빠른 데이터 액세스 및 처리를 지원하는 구조로 인해, 마이크로서비스 아키텍처와의 연계에서 큰 장점 지님
- 멀티 클라우드
- 여러 클라우드 제공업체의 서비스를 동시에 혹은 혼합해 활용하는 전략
- 단일 클라우드 환경의 장애나 제한된 자원에 대한 의존성을 줄이며, 각 클라우드 서비스 제공자의 강점을 활용할 수 있게 해줌
- 데이터가 특정 지역이나 국가 내에 물리적으로 위치하도록 조절할 수 있어 더 가까운 저장소에서 데이터를 처리하게 되므로 대기 시간을 줄이고 장애 상황에 더욱 강건하게 대응 가능
- 레디스는 여러 클라우드 환경에 걸쳐 일관된 성능과 기능을 제공함으로써 서비스의 연속성과 데이터의 일관성 보장
마이크로서비스 아키텍처와 레디스
데이터 저장소로서의 레디스
- 마이크로서비스 아키텍처에서 각 서비스별 개별 저장소로 사용
- 설치 간편, 최소한의 리소스로 막대한 처리량, 다양한 자료 구조 제공
- 고가용성을 위해 로드 밸러서나 프록시 등 추가적인 서비스를 설치할 필요가 없음
- 데이터의 영속성을 위해 AOF(Append Only File)와 RDB(Redis DataBase) 형식으로 디스크에 주기적으로 저장 가능
- 레디스에 있는 데이터가 유실되더라고 백업 파일을 통해 복구 가능
메시지 브로커로서의 레디스
- 마이크로서비스 아키텍처에서 각 서비스를 완전히 분리되어 있는 구조로 동작하기 때문에 서로 다른 서비스 간에 지속적인 통신 필요
- 메시징 큐 혹은 stream과 같은 메시지 브로커를 이용해 서비스 간에 비동기적으로 데이터를 전달
- 레디스의 pub/sub은 메시징 기능으로 빠르게 동작하며 간단하게 사용 가능
- 1개의 채널에 데이터를 던지면 이 채널을 듣고 있는 모든 소비자는 데이터를 빠르게 가져갈 수 있음
- pub/sub에서 모든 데이터는 전달된 뒤 삭제되는 일회성
- fire-and-forget 패턴이 필요한 간단한 알림 서비스에서는 유용
- 레디스의 list 자료 구조는 메시징 큐로 사용하기 알맞음
- 빠르게 데이터 push/pop 가능
- 애플리케이션은 매번 list에 데이터가 있는지 확인할 필요 없이 대기하다가 새로운 데이터가 들어오면 읽어갈 수 있는 블로킹 기능 사용 가능
- 레디스의 stream 자료 구조를 이용하면 레디스를 완벽한 스트림 플랫폼으로 사용할 수 있음
- 데이터는 계속해서 추가되는 방식으로 저장됨(append-only)
- 카프카처럼 저장되는 데이터를 읽을 수 있는 소비자와 소비자 그룹이 존재해 데이터의 분산 처리 가능하며 저장된 데이터를 시간대별로 검색하는 것도 가능

Backend Developer👩🏻💻