MLOps 개론
모델 개발 과정
Research
- 추상적 flow: 문제 정의 -> EDA -> Feature Engineering -> Train -> Predict
- 학습된 모델을 앱, 웹 서비스에서 사용할 수 있도록 만드는 과정이 필요하다.
- Real World, Production 환경에 모델을 배포
Production
- 추상적 flow: 문제 정의 -> EDA -> Feature Engineering -> Train -> Predict -> Deploy
- Deploy: 웹, 앱 서비스에서 활용할 수 있게 만드는 과정
- "모델에게 데이터(Input)을 제공하면서, (Output)을 예측해주세요"라고 요청하는 것과 같다.
- 모델 배포 후, 모델의 결과값이 이상한 경우가 존재한다.
- 원인 파악 필요
- Input 데이터가 이상한 경우 존재 (0~100 이내여야 하는데, 200이 들어온 경우)
- Research 할 땐 outlier로 제외할 수 있지만, 실제 서비스에서는 제외가 힘든 상황 (별도 처리 필요)
- 모델의 성능이 계속 변경되는 경우가 있다.
- 모델의 성능은 어떻게 확인할 수 있을까?
- 예측 값과 실제 레이블을 알아야 한다.
- 정형(Tabular) 데이터에서는 정확히 알 수 있지만, 비정형 데이터(이미지 등)에서는 잘 모를 수 있다.
- 새로운 모델이 더 안 좋다면?
- 과거의 모델을 다시 사용해야 할까?
- Research 환경에서는 성능이 더 좋았던 모델이 Production 환경에서는 더 좋지 않을 수 있다.
- 이전 모델을 다시 사용하기 위한 작업이 필요하다.
MLOps란?
머신러닝 모델링 코드는 머신러닝 시스템 중 일부에 불과하다.
Hidden Technical Debt in Machine Learning Systems, NEURIPS, 2015
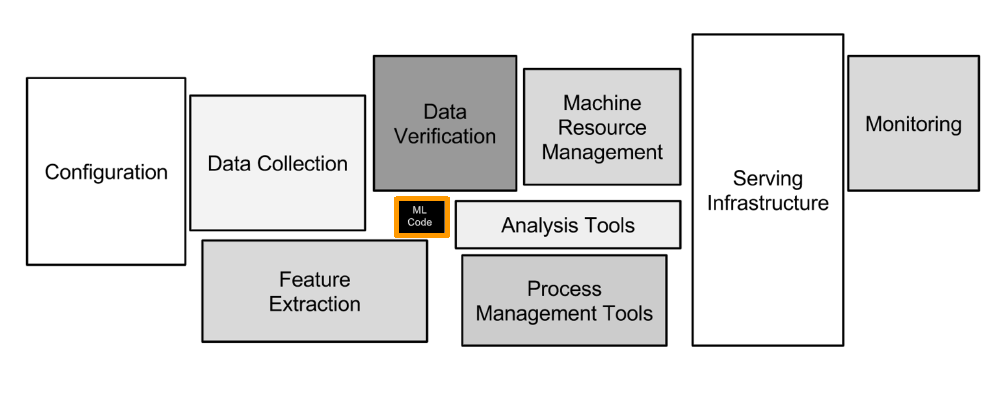
- MLOps: ML(Machine Learning) + Ops(Operations)
- 머신러닝 모델을 운영하면서 반복적으로 필요한 업무를 자동화시키는 과정이다.
- 합쳐진 분야: 머신러닝 엔지니어링 + 데이터 엔지니어링 + 클라우드 + 인프라
- 머신러닝 모델 개발(ML Dev)과 머신러닝 모델 운영(Ops)에서 사용되는 문제, 반복을 최소화하고 비즈니스 가치를 창출하는 것이 목표이다.
- 모델링에 집중할 수 있도록 관련된 인프라를 만들고, 자동으로 운영되도록 만드는 일이다.
- Production 환경에 배포하는 과정에서 Research 단계의 모델이 꼭 재현 가능해야 한다. (현실의 Risk 있는 환경에서도 잘 버틸 수 있어야 한다.)
- MLOps의 목표는 빠른 시간 내에 가장 적은 위험을 부담하며, 아이디어 단계부터 Production 단계까지 ML 프로젝트를 진행할 수 있도록 기술적 마찰을 줄이는 것이다.
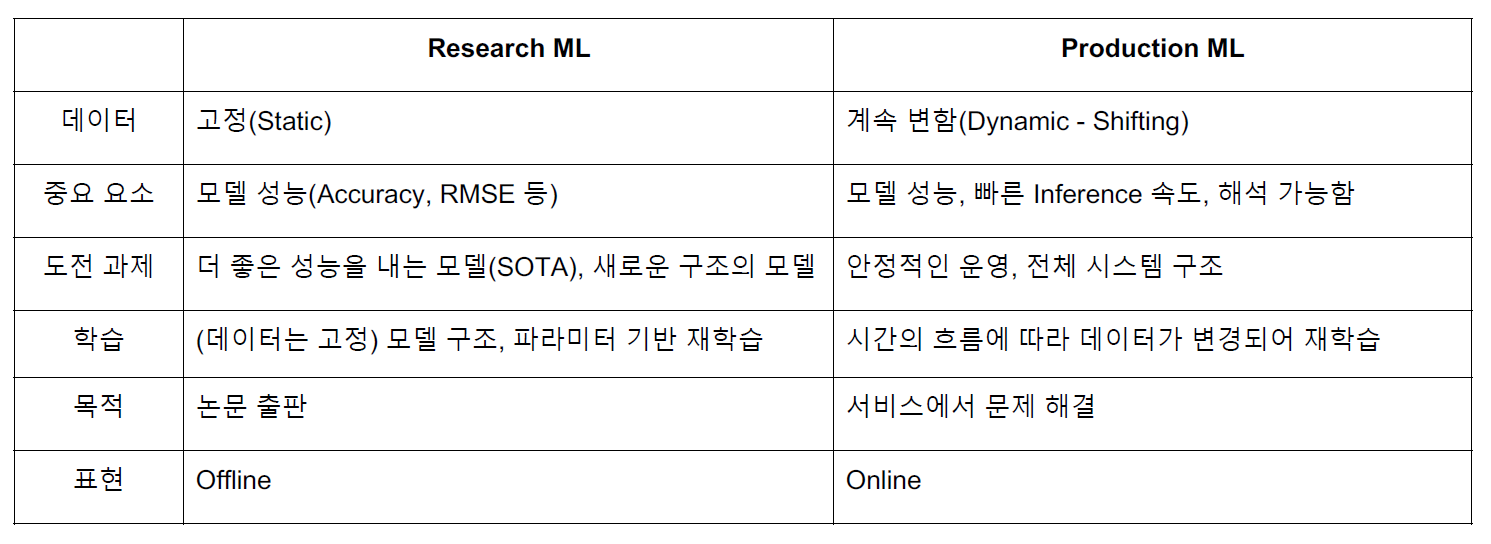
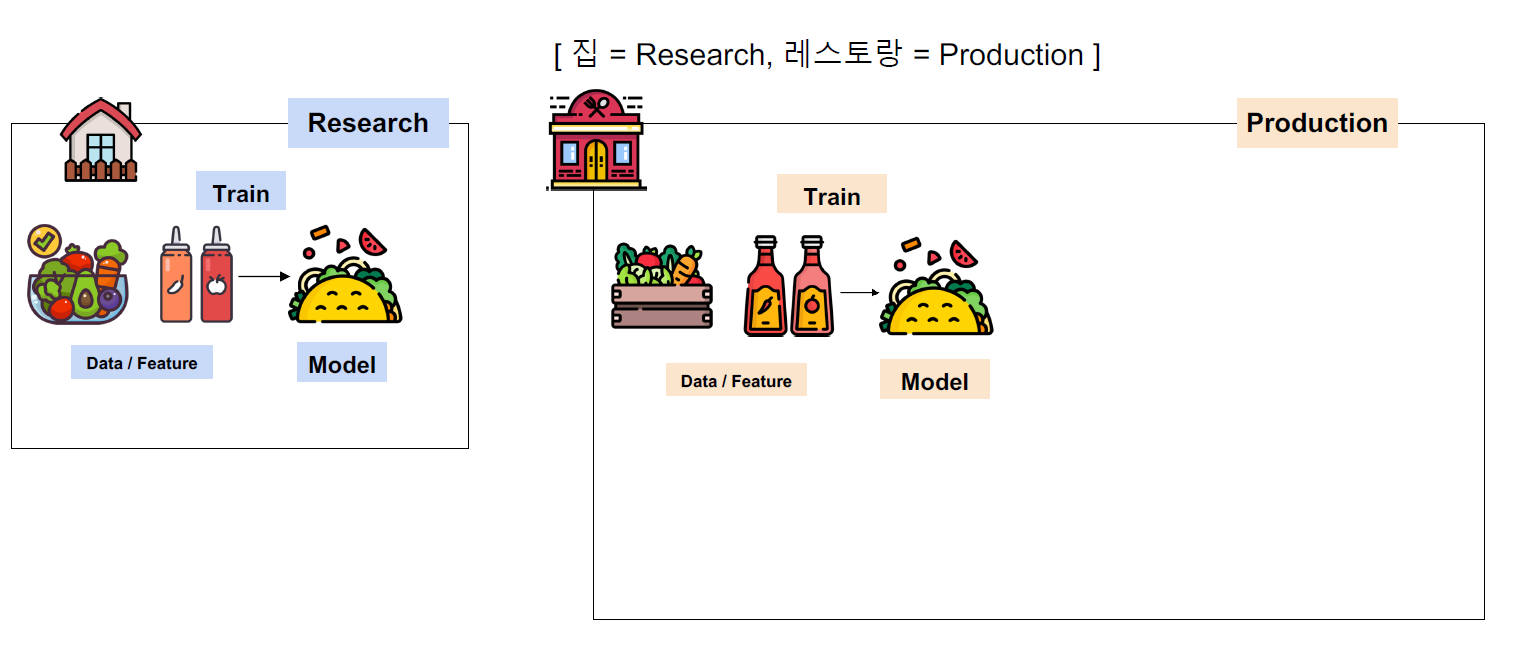
Research와 Production의 차이
MLOps Componenent
Infra
- 자체 서버 구축? 클라우드? 특정 회사는 클라우드를 사용하지 못하는 경우가 있다. (금융권 등은 규제로 인해 사용 불가) 대부분은 클라우드 서비스를 사용한다.
- 클라우드: AWS, GCP, Azure, NCP 등
- 온 프레미스: 회사나 대학원의 전산실에 서버를 직접 설치
Serving
- Batch Serving: 많은 데이터를 일정 주기로 한꺼번에 예측. (정기배송 같은 느낌)
- Online Serving: 실시간 예측. 병목이 없어야 한다. 확장 가능하도록 준비해야 한다.

Experiment, Model Management
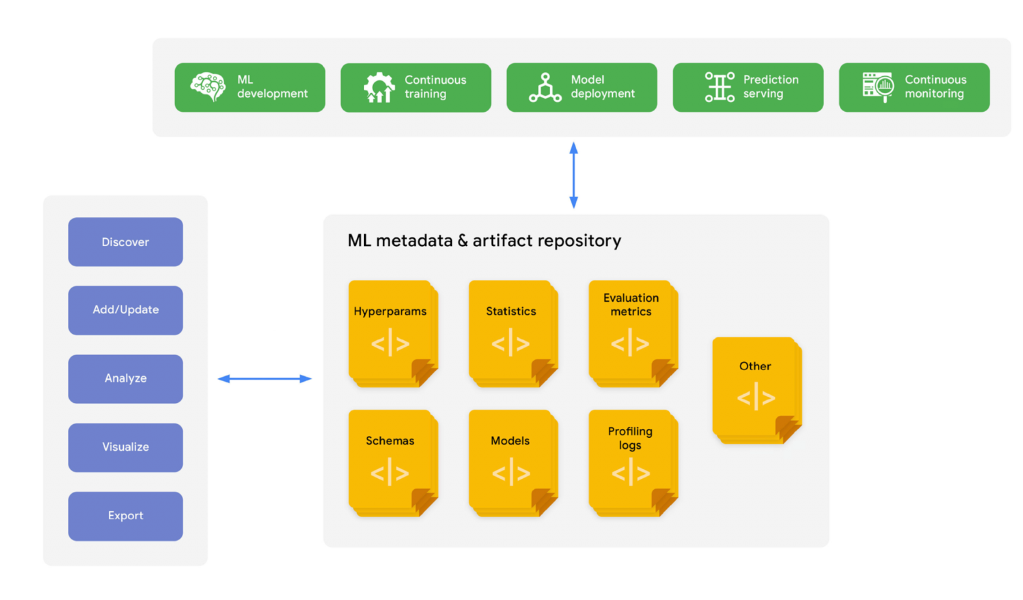
- 모델이 많아지고, 협업하다 보면 누락이 발생한다. 공통의 format을 만들어서 code 상에서 자동으로 들어가도록 하면 편리하다.
MLflow
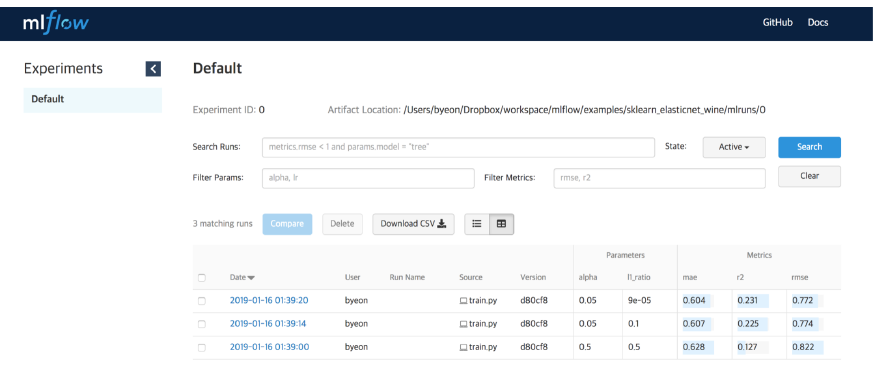
from pprint import pprint
import numpy as np
from sklearn.linear_model import LinearRegression
import mlflow
from utils import fetch_logged_data
def main():
# enable autologging
mlflow.sklearn.autolog()
# prepare training data
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
# train a model
model = LinearRegression()
with mlflow.start_run() as run:
model.fit(X, y)
print("Logged data and model in run {}".format(run.info.run_id))
# show logged data
for key, data in fetch_logged_data(run.info.run_id).items():
print("\n---------- logged {} ----------".format(key))
pprint(data)Feature Store
- 머신러닝 Feature를 집계한 Feature Store
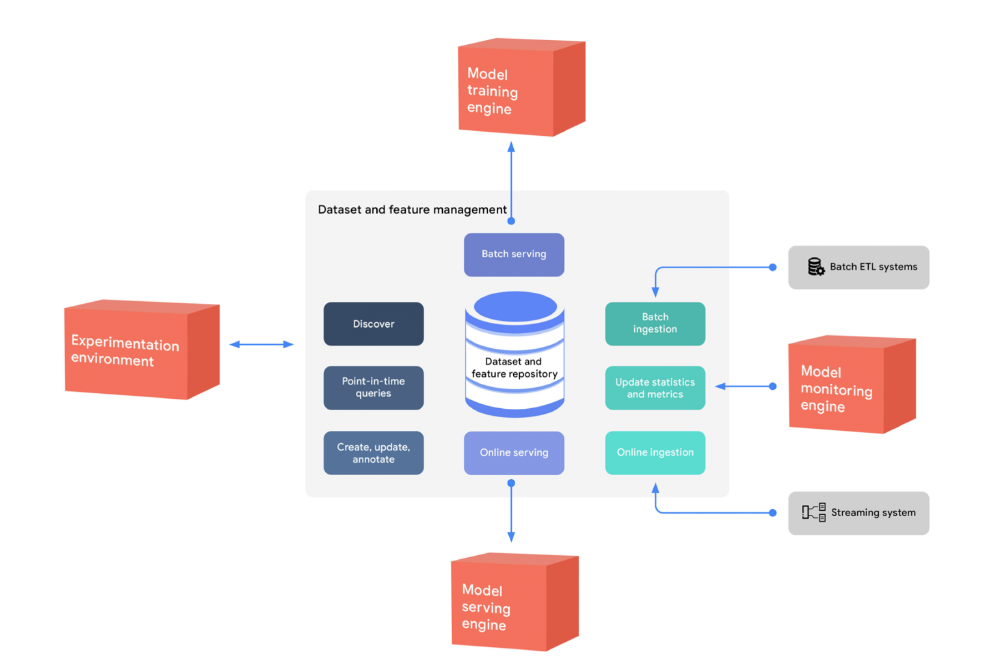
FEAST
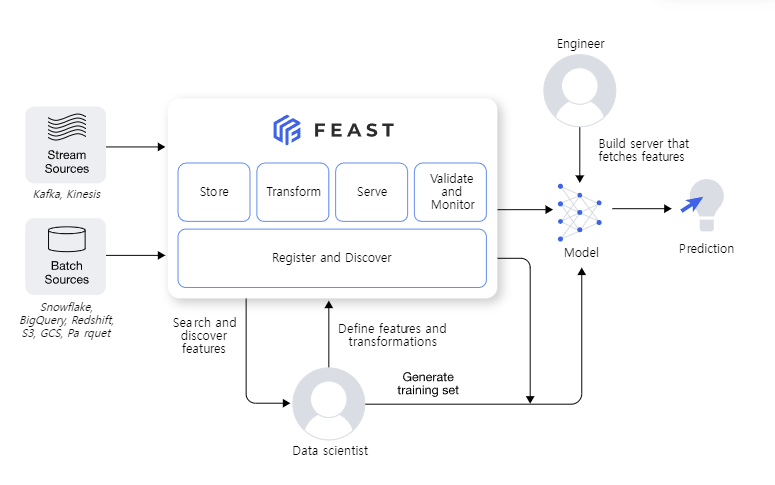
from pprint import pprint
from feast import FeatureStore
store = FeatureStore(repo_path=".")
feature_vector = store.get_online_features(
features=[
'driver_hourly_stats:conv_rate',
'driver_hourly_stats:acc_rate',
'driver_hourly_stats:avg_daily_trips'
],
entity_rows=[{"driver_id": 1001}]
).to_dict()
pprint(feature_vector)
# Make prediction
# model.predict(feature_vector)- 대부분 라이브러리 사용 보다는 직접 개발하고 있다.
Data Validation (Data Management)
- Feature의 분포 확인
- Data Drift, Model Drift, Concept Drift
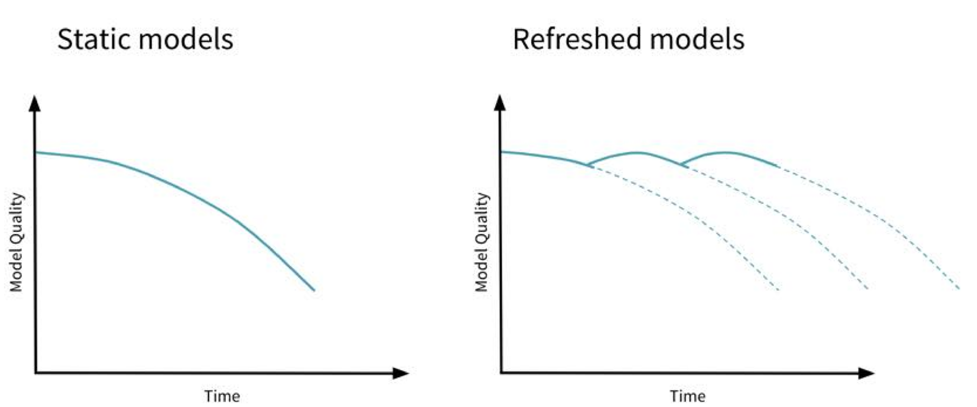
- Refreshed models: 시간이 지나고 다시 학습.
Continuous Training
- 새로운 데이터가 들어온 경우, 일정 기간, Metric 기반으로 성능이 줄어든 경우, 요청 시 등등.
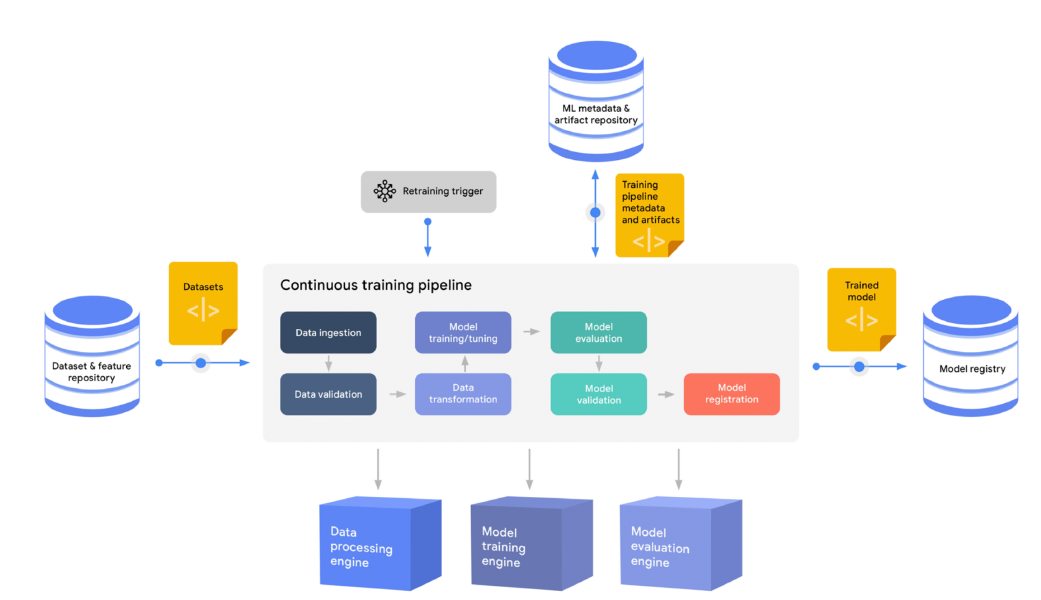
Monitoring
- 모델의 지표, 인프라의 성능 지표 등을 잘 기록해야 한다.
AutoML
- 데이터만 주면 자동으로 모델을 만들어준다.
Microsoft NNI
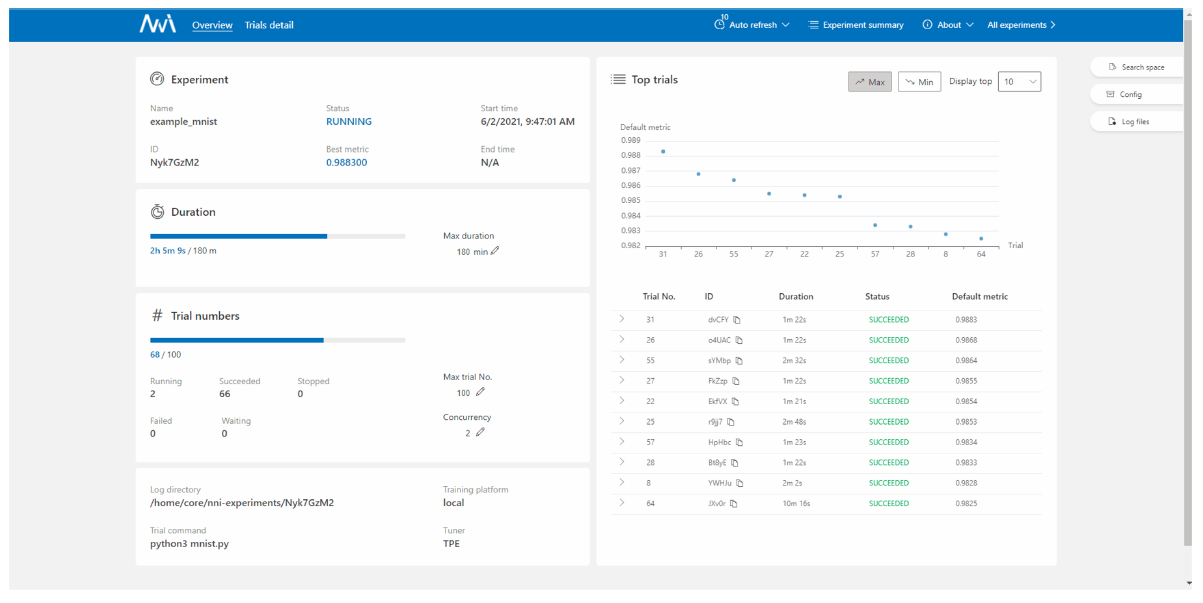
정리
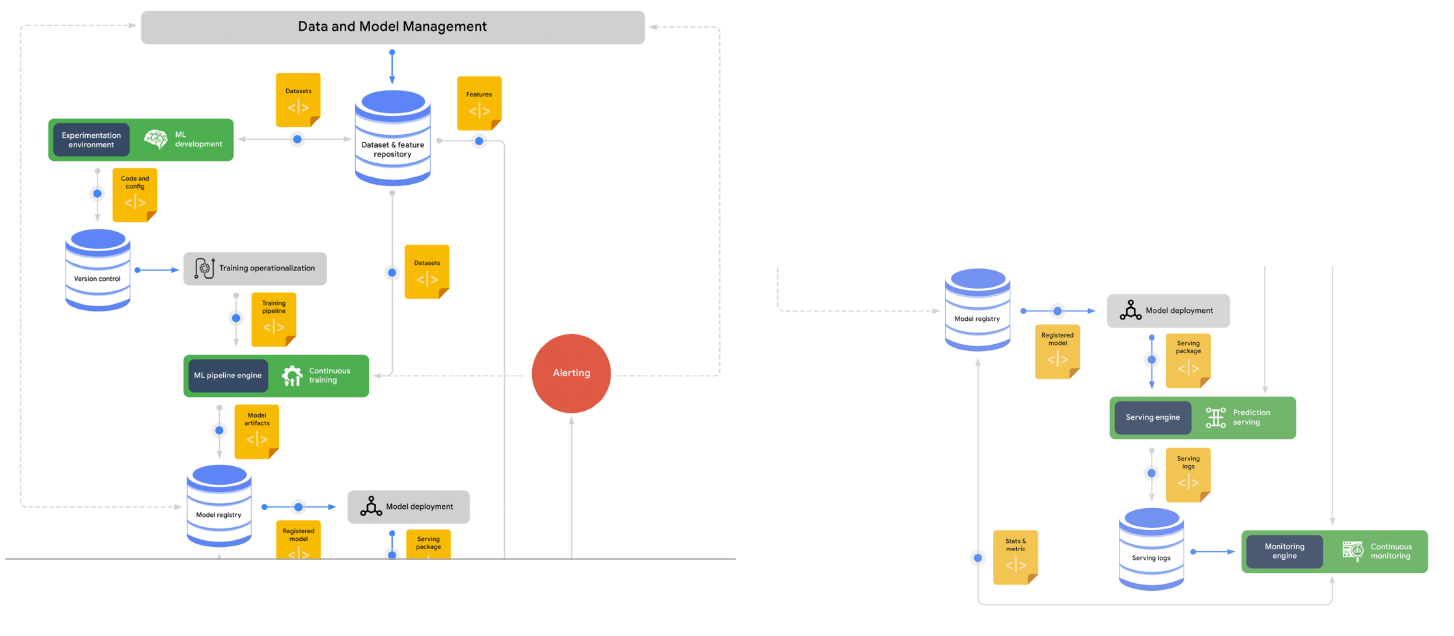
- 모든 요소가 항상 존재해야 하는 것은 아니다.
- 처음엔 작은 단위의 MVP(Minimal Value Product)로 시작해서 점점 운영 리소스가 많이 소요될 때 하나씩 구축하는 방식을 활용하자!

Keep on dreaming and dreaming